背景资料
因本人具有前端背景,以下内容只列举和 javascript 不同的地方
解释器
Python 的解释器很多,但使用最广泛的还是 CPython。如果要和 Java 或 .Net 平台交互,最好的办法不是用 Jython 或 IronPython,而是通过网络调用来交互,确保各程序之间的独立性。
直接运行 py 文件
一般是通过 python hello.py 运行,但是可以按照以下步骤在 Mac 和 Linux 上直接运行 ./hello.py
#!/usr/bin/env python3
print('hello, world')然后,通过命令给 hello.py 以执行权限,就可以直接运行
chmod a+x hello.py基础
- 解释型动态语言,运行速度慢,代码安全性差(不能加密)
#开头的是注释,语句以:结尾时,缩进的语句是为代码块,一般缩进 4 个空格- 大小写敏感
数据类型与变量
数据类型
-
整数:允许在数字中间以
_分隔,没有大小限制,//称为地板除,即只保留整数部分 -
浮点数:浮点数运算有四舍五入的误差,整数运算是精确的,没有大小限制,超过一定范围表示为
inf(无限大) -
字符串:
- 以
'或"括起来的文本,转义字符\可以用来转义 - 使用
r''表示''内部的字符串默认不转义 - 用
'''...'''表示多行内容,可以和上面的r结合使用,即r'''...'''
- 以
-
布尔值:值为
True或False,运算符为and、or、not -
空值:值为
None
变量与常量
变量可以动态赋值,常量可以用全部大写的变量名表示,但没有任何机制可以保证不改变
字符串和编码
字符编码
Unicode 把所有语言都统一到一套编码里,最常用的是 UCS-16 编码,用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要 4 个字节)。现代操作系统和大多数编程语言都直接支持 Unicode。
ASCII 编码和 Unicode 编码的区别:ASCII 编码是 1 个字节,而 Unicode 编码通常是 2 个字节。
如果统一成 Unicode 编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用 Unicode 编码比 ASCII 编码需要多一倍的存储空间,在存储和传输上就十分不划算。
于是出现了把 Unicode 编码转化为“可变长编码”的 UTF-8 编码,如下表
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 11100100 10111000 10101101 |
UTF-8 编码有一个额外的好处,就是 ASCII 编码实际上可以被看成是 UTF-8 编码的一部分,所以,大量只支持 ASCII 编码的历史遗留软件可以在 UTF-8 编码下继续工作。
总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用 Unicode 编码,当需要保存到硬盘或者需要传输的时候,就转换为 UTF-8 编码。
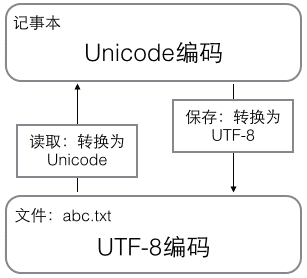
用记事本编辑的时候,从文件读取的 UTF-8 字符被转换为 Unicode 字符到内存里,编辑完成后,保存的时候再把 Unicode 转换为 UTF-8 保存到文件:
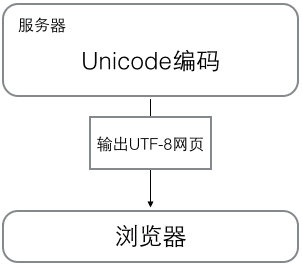
浏览网页的时候,服务器会把动态生成的 Unicode 内容转换为 UTF-8 再传输到浏览器:
Python 的字符串
对于单个字符的编码,Python 提供了 ord() 函数获取字符的整数表示,chr() 函数把编码转换为对应的字符:
>>> ord('A')
65
>>> ord('中')
20013
>>> chr(66)
'B'
>>> chr(25991)
'文'如果知道字符的整数编码,还可以用十六进制这么写 str:
>>> '\u4e2d\u6587'
'中文'两种写法完全是等价的。
由于 Python 的字符串类型是 str,在内存中以 Unicode 表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把 str 变为以字节为单位的 bytes。
Python 对 bytes 类型的数据用带 b 前缀的单引号或双引号表示:
x = b'ABC'要注意区分 'ABC' 和 b'ABC',前者是 str,后者虽然内容显示得和前者一样,但 bytes 的每个字符都只占用一个字节。
以 Unicode 表示的 str 通过 encode() 方法可以编码为指定的 bytes,例如:
>>> 'ABC'.encode('ascii')
b'ABC'
>>> '中文'.encode('utf-8')
b'\xe4\xb8\xad\xe6\x96\x87'
>>> '中文'.encode('ascii')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)纯英文的 str 可以用 ASCII 编码为 bytes,内容是一样的,含有中文的 str 可以用 UTF-8 编码为 bytes。含有中文的 str 无法用 ASCII 编码,因为中文编码的范围超过了 ASCII 编码的范围,Python 会报错。
在 bytes 中,无法显示为 ASCII 字符的字节,用 \x## 显示。
反过来,如果我们从网络或磁盘上读取了字节流,那么读到的数据就是 bytes。要把 bytes 变为 str,就需要用 decode() 方法:
>>> b'ABC'.decode('ascii')
'ABC'
>>> b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')
'中文'如果 bytes 中包含无法解码的字节,decode() 方法会报错:
>>> b'\xe4\xb8\xad\xff'.decode('utf-8')
Traceback (most recent call last):
...
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 3: invalid start byte如果 bytes 中只有一小部分无效的字节,可以传入 errors='ignore' 忽略错误的字节:
>>> b'\xe4\xb8\xad\xff'.decode('utf-8', errors='ignore')
'中'要计算 str 包含多少个字符,可以用 len() 函数:
>>> len('ABC')
3
>>> len('中文')
2len() 函数计算的是 str 的字符数,如果换成 bytes,len() 函数就计算字节数:
>>> len(b'ABC')
3
>>> len(b'\xe4\xb8\xad\xe6\x96\x87')
6
>>> len('中文'.encode('utf-8'))
6可见,1 个中文字符经过 UTF-8 编码后通常会占用 3 个字节,而 1 个英文字符只占用 1 个字节。
在操作字符串时,我们经常遇到 str 和 bytes 的互相转换。为了避免乱码问题,应当始终坚持使用 UTF-8 编码对 str 和 bytes 进行转换。
由于 Python 源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为 UTF-8 编码。当 Python 解释器读取源代码时,为了让它按 UTF-8 编码读取,我们通常在文件开头写上这两行:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-第一行注释是为了告诉 Linux/OS X 系统,这是一个 Python 可执行程序,Windows 系统会忽略这个注释;
第二行注释是为了告诉 Python 解释器,按照 UTF-8 编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
申明了 UTF-8 编码并不意味着你的 .py 文件就是 UTF-8 编码的,必须并且要确保文本编辑器正在使用 UTF-8 without BOM 编码:
如果 .py 文件本身使用 UTF-8 编码,并且也申明了 # -*- coding: utf-8 -*-,打开命令提示符测试就可以正常显示中文:
格式化
最后一个常见的问题是如何输出格式化的字符串。我们经常会输出类似’亲爱的 xxx 你好!你 xx 月的话费是 xx,余额是 xx’之类的字符串,而 xxx 的内容都是根据变量变化的,所以,需要一种简便的格式化字符串的方式。
在 Python 中,采用的格式化方式和 C 语言是一致的,用 % 实现,举例如下:
>>> 'Hello, %s' % 'world'
'Hello, world'
>>> 'Hi, %s, you have $%d.' % ('Michael', 1000000)
'Hi, Michael, you have $1000000.'你可能猜到了,% 运算符就是用来格式化字符串的。在字符串内部,%s 表示用字符串替换,%d 表示用整数替换,有几个 %? 占位符,后面就跟几个变量或者值,顺序要对应好。如果只有一个 %?,括号可以省略。
常见的占位符有:
| 占位符 | 替换内容 |
|---|---|
| %d | 整数 |
| %f | 浮点数 |
| %s | 字符串 |
| %x | 十六进制整数 |
其中,格式化整数和浮点数还可以指定是否补 0 和整数与小数的位数:
print('%2d-%02d' % (3, 1)) # 3-01
print('%.2f' % 3.1415926) # 3.14如果你不太确定应该用什么,%s 永远起作用,它会把任何数据类型转换为字符串:
>>> 'Age: %s. Gender: %s' % (25, True)
'Age: 25. Gender: True'有些时候,字符串里面的 % 是一个普通字符怎么办?这个时候就需要转义,用 %% 来表示一个 %:
>>> 'growth rate: %d %%' % 7
'growth rate: 7 %'format()
另一种格式化字符串的方法是使用字符串的 format() 方法,它会用传入的参数依次替换字符串内的占位符 {0}、{1}……,不过这种方式写起来比 % 要麻烦得多:
>>> 'Hello, {0}, 成绩提升了 {1:.1f}%'.format('小明', 17.125)
'Hello, 小明, 成绩提升了 17.1%'f-string
最后一种格式化字符串的方法是使用以 f 开头的字符串,称之为 f-string,它和普通字符串不同之处在于,字符串如果包含 {xxx},就会以对应的变量替换:
>>> r = 2.5
>>> s = 3.14 * r ** 2
>>> print(f'The area of a circle with radius {r} is {s:.2f}')
The area of a circle with radius 2.5 is 19.62上述代码中,{r} 被变量 r 的值替换,{s:.2f} 被变量 s 的值替换,并且 : 后面的 .2f 指定了格式化参数(即保留两位小数),因此,{s:.2f} 的替换结果是 19.62。
使用 list 和 tuple
list
Python 内置的一种数据类型是列表:list。list 是一种有序的集合,可以随时添加和删除其中的元素。
比如,列出班里所有同学的名字,就可以用一个 list 表示:
>>> classmates = ['Michael', 'Bob', 'Tracy']
>>> classmates
['Michael', 'Bob', 'Tracy']变量 classmates 就是一个 list。用 len() 函数可以获得 list 元素的个数:
>>> len(classmates)
3用索引来访问 list 中每一个位置的元素,记得索引是从 0 开始的:
>>> classmates[0]
'Michael'
>>> classmates[1]
'Bob'
>>> classmates[2]
'Tracy'
>>> classmates[3]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: list index out of range当索引超出了范围时,Python 会报一个 IndexError 错误,所以,要确保索引不要越界,记得最后一个元素的索引是 len(classmates) - 1。
如果要取最后一个元素,除了计算索引位置外,还可以用 -1 做索引,直接获取最后一个元素:
>>> classmates[-1]
'Tracy'以此类推,可以获取倒数第 2 个、倒数第 3 个:
>>> classmates[-2]
'Bob'
>>> classmates[-3]
'Michael'
>>> classmates[-4]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: list index out of range当然,倒数第 4 个就越界了。
list 是一个可变的有序表,所以,可以往 list 中追加元素到末尾:
>>> classmates.append('Adam')
>>> classmates
['Michael', 'Bob', 'Tracy', 'Adam']也可以把元素插入到指定的位置,比如索引号为 1 的位置:
>>> classmates.insert(1, 'Jack')
>>> classmates
['Michael', 'Jack', 'Bob', 'Tracy', 'Adam']要删除 list 末尾的元素,用 pop() 方法:
>>> classmates.pop()
'Adam'
>>> classmates
['Michael', 'Jack', 'Bob', 'Tracy']要删除指定位置的元素,用 pop(i) 方法,其中 i 是索引位置:
>>> classmates.pop(1)
'Jack'
>>> classmates
['Michael', 'Bob', 'Tracy']要把某个元素替换成别的元素,可以直接赋值给对应的索引位置:
>>> classmates[1] = 'Sarah'
>>> classmates
['Michael', 'Sarah', 'Tracy']list 里面的元素的数据类型也可以不同,比如:
>>> L = ['Apple', 123, True]list 元素也可以是另一个 list,比如:
>>> s = ['python', 'java', ['asp', 'php'], 'scheme']
>>> len(s)
4要注意 s 只有 4 个元素,其中 s[2] 又是一个 list,如果拆开写就更容易理解了:
>>> p = ['asp', 'php']
>>> s = ['python', 'java', p, 'scheme']要拿到 'php' 可以写 p[1] 或者 s[2][1],因此 s 可以看成是一个二维数组,类似的还有三维、四维……数组,不过很少用到。
如果一个 list 中一个元素也没有,就是一个空的 list,它的长度为 0:
>>> L = []
>>> len(L)
0tuple
另一种有序列表叫元组:tuple。tuple 和 list 非常类似,但是 tuple 一旦初始化就不能修改,比如同样是列出同学的名字:
>>> classmates = ('Michael', 'Bob', 'Tracy')现在,classmates 这个 tuple 不能变了,它也没有 append(),insert() 这样的方法。其他获取元素的方法和 list 是一样的,你可以正常地使用 classmates[0],classmates[-1],但不能赋值成另外的元素。
不可变的 tuple 有什么意义?因为 tuple 不可变,所以代码更安全。如果可能,能用 tuple 代替 list 就尽量用 tuple。
tuple 的陷阱:当你定义一个 tuple 时,在定义的时候,tuple 的元素就必须被确定下来,比如:
>>> t = (1, 2)
>>> t
(1, 2)如果要定义一个空的 tuple,可以写成 ():
>>> t = ()
>>> t
()但是,要定义一个只有 1 个元素的 tuple,如果你这么定义:
>>> t = (1)
>>> t
1定义的不是 tuple,是 1 这个数,这是因为括号 () 既可以表示 tuple,又可以表示数学公式中的小括号,这就产生了歧义,因此,Python 规定,这种情况下,按小括号进行计算,计算结果自然是 1。
所以,只有 1 个元素的 tuple 定义时必须加一个逗号 ,,来消除歧义:
>>> t = (1,)
>>> t
(1,)Python 在显示只有 1 个元素的 tuple 时,也会加一个逗号 ,,以免你误解成数学计算意义上的括号。
最后来看一个 “可变的” tuple:
>>> t = ('a', 'b', ['A', 'B'])
>>> t[2][0] = 'X'
>>> t[2][1] = 'Y'
>>> t
('a', 'b', ['X', 'Y'])tuple 所谓的“不变”是说,tuple 的每个元素,指向永远不变。即指向 ‘a’,就不能改成指向 ‘b’,指向一个 list,就不能改成指向其他对象,但指向的这个 list 本身是可变的!
条件判断
age = 3
if age >= 18:
print('adult')
elif age >= 6:
print('teenager')
else:
print('kid')if 判断条件还可以简写,比如写:
if x:
print('True')只要 x 是非零数值、非空字符串、非空 list 等,就判断为 True,否则为 False。
再议 input
birth = input('birth: ')
if birth < 2000:
print('00前')
else:
print('00后')输入 1982,结果报错:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unorderable types: str() > int()这是因为 input() 返回的数据类型是 str,str 不能直接和整数比较,必须先把 str 转换成整数。Python 提供了 int() 函数来完成这件事情:
s = input('birth: ')
birth = int(s)
if birth < 2000:
print('00前')
else:
print('00后')再次运行,就可以得到正确地结果。但是,如果输入 abc 呢?又会得到一个错误信息:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: invalid literal for int() with base 10: 'abc'原来 int() 函数发现一个字符串并不是合法的数字时就会报错,程序就退出了。
如何检查并捕获程序运行期的错误呢?后面的错误和调试会讲到。
循环
Python 的循环有两种,一种是 for…in 循环,依次把 list 或 tuple 中的每个元素迭代出来,看例子:
names = ['Michael', 'Bob', 'Tracy']
for name in names:
print(name)第二种循环是 while 循环,只要条件满足,就不断循环,条件不满足时退出循环。比如我们要计算 100 以内所有奇数之和,可以用 while 循环实现:
sum = 0
n = 99
while n > 0:
sum = sum + n
n = n - 2
print(sum)break 提前结束循环,continue 提前结束本轮循环,并直接开始下一轮循环。
使用 dict 和 set
dict
Python 内置了字典:dict 的支持,dict 全称 dictionary,在其他语言中也称为 map,使用键-值(key-value)存储,具有极快的查找速度。
>>> d = {'Michael': 95, 'Bob': 75, 'Tracy': 85}
>>> d['Michael']
95如果 key 不存在,dict 就会报错:
>>> d['Thomas']
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'Thomas'要避免 key 不存在的错误,有两种办法,一是通过 in 判断 key 是否存在:
>>> 'Thomas' in d
False二是通过 dict 提供的 get() 方法,如果 key 不存在,可以返回 None,或者自己指定的 value:
>>> d.get('Thomas')
>>> d.get('Thomas', -1)
-1注意:返回 None 的时候 Python 的交互环境不显示结果。
要删除一个 key,用 pop(key) 方法,对应的 value 也会从 dict 中删除:
>>> d.pop('Bob')
75
>>> d
{'Michael': 95, 'Tracy': 85}请务必注意,dict 内部存放的顺序和 key 放入的顺序是没有关系的。
和 list 比较,dict 有以下几个特点:
- 查找和插入的速度极快,不会随着 key 的增加而变慢;
- 需要占用大量的内存,内存浪费多。
而 list 相反:
- 查找和插入的时间随着元素的增加而增加;
- 占用空间小,浪费内存很少。
所以,dict 是用空间来换取时间的一种方法。
dict 可以用在需要高速查找的很多地方,在 Python 代码中几乎无处不在,正确使用 dict 非常重要,需要牢记的第一条就是 dict 的 key 必须是不可变对象。
这是因为 dict 根据 key 来计算 value 的存储位置,如果每次计算相同的 key 得出的结果不同,那 dict 内部就完全混乱了。这个通过 key 计算位置的算法称为哈希算法(Hash)。
要保证 hash 的正确性,作为 key 的对象就不能变。在 Python 中,字符串、整数等都是不可变的,因此,可以放心地作为 key。而 list 是可变的,就不能作为 key:
>>> key = [1, 2, 3]
>>> d[key] = 'a list'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'set
set 和 dict 类似,也是一组 key 的集合,但不存储 value。由于 key 不能重复,所以,在 set 中,没有重复的 key。
要创建一个 set,需要提供一个 list 作为输入集合:
>>> s = set([1, 2, 3])
>>> s
{1, 2, 3}注意,传入的参数[1, 2, 3]是一个 list,而显示的{1, 2, 3}只是告诉你这个 set 内部有 1,2,3 这 3 个元素,显示的顺序也不表示 set 是有序的。。
重复元素在 set 中自动被过滤:
>>> s = set([1, 1, 2, 2, 3, 3])
>>> s
{1, 2, 3}通过 add(key) 方法可以添加元素到 set 中,可以重复添加,但不会有效果:
>>> s.add(4)
>>> s
{1, 2, 3, 4}
>>> s.add(4)
>>> s
{1, 2, 3, 4}通过 remove(key) 方法可以删除元素:
>>> s.remove(4)
>>> s
{1, 2, 3}set 可以看成数学意义上的无序和无重复元素的集合,因此,两个 set 可以做数学意义上的交集、并集等操作:
>>> s1 = set([1, 2, 3])
>>> s2 = set([2, 3, 4])
>>> s1 & s2
{2, 3}
>>> s1 | s2
{1, 2, 3, 4}set 和 dict 的唯一区别仅在于没有存储对应的 value,但是,set 的原理和 dict 一样,所以,同样不可以放入可变对象,因为无法判断两个可变对象是否相等,也就无法保证 set 内部“不会有重复元素”。试试把 list 放入 set,看看是否会报错。
再议不可变对象
上面我们讲了,str 是不变对象,而 list 是可变对象。
对于可变对象,比如 list,对 list 进行操作,list 内部的内容是会变化的,比如:
>>> a = ['c', 'b', 'a']
>>> a.sort()
>>> a
['a', 'b', 'c']而对于不可变对象,比如 str,对 str 进行操作呢:
>>> a = 'abc'
>>> a.replace('a', 'A')
'Abc'
>>> a
'abc'虽然字符串有个 replace() 方法,也确实变出了 ‘Abc’,但变量 a 最后仍是 ‘abc’,应该怎么理解呢?
我们先把代码改成下面这样:
>>> a = 'abc'
>>> b = a.replace('a', 'A')
>>> b
'Abc'
>>> a
'abc'要始终牢记的是,a 是变量,而 ‘abc’ 才是字符串对象!有些时候,我们经常说,对象 a 的内容是 ‘abc’,但其实是指,a 本身是一个变量,它指向的对象的内容才是 ‘abc’
当我们调用 a.replace(‘a’, ‘A’) 时,实际上调用方法 replace 是作用在字符串对象 ‘abc’ 上的,而这个方法虽然名字叫 replace,但却没有改变字符串 ‘abc’ 的内容。相反,replace 方法创建了一个新字符串 ‘Abc’ 并返回,如果我们用变量 b 指向该新字符串,就容易理解了,变量 a 仍指向原有的字符串 ‘abc’,但变量 b 却指向新字符串 ‘Abc’ 了
所以,对于不变对象来说,调用对象自身的任意方法,也不会改变该对象自身的内容。相反,这些方法会创建新的对象并返回,这样,就保证了不可变对象本身永远是不可变的。
函数
调用函数
Python 内置了很多有用的函数,我们可以直接调用
可以直接从 Python 的官方网站查看文档,也可以在交互式命令行通过 help(abs) 查看 abs 函数的帮助信息
数据类型转换
Python 内置的常用函数还包括数据类型转换函数,比如 int() 函数可以把其他数据类型转换为整数:
>>> int('123')
123
>>> int(12.34)
12
>>> float('12.34')
12.34
>>> str(1.23)
'1.23'
>>> str(100)
'100'
>>> bool(1)
True
>>> bool('')
False函数名其实就是指向一个函数对象的引用,完全可以把函数名赋给一个变量,相当于给这个函数起了一个“别名”:
>>> a = abs # 变量 a 指向 abs 函数
>>> a(-1) # 所以也可以通过 a 调用 abs 函数
1定义函数
在 Python 中,定义一个函数要使用 def 语句,依次写出函数名、括号、括号中的参数和冒号 :,然后,在缩进块中编写函数体,函数的返回值用 return 语句返回。
我们以自定义一个求绝对值的 my_abs 函数为例:
def my_abs(x):
if x >= 0:
return x
else:
return -x
print(my_abs(-99))如果没有 return 语句,函数执行完毕后也会返回结果,只是结果为 None。return None 可以简写为 return。
空函数
如果想定义一个什么事也不做的空函数,可以用 pass 语句:
def nop():
passpass 语句什么都不做,那有什么用?实际上 pass 可以用来作为占位符,比如现在还没想好怎么写函数的代码,就可以先放一个 pass,让代码能运行起来。
pass 还可以用在其他语句里,比如:
if age >= 18:
pass缺少了 pass,代码运行就会有语法错误。
参数检查
调用函数时,如果参数个数不对,Python 解释器会自动检查出来,并抛出 TypeError:
>>> my_abs(1, 2)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: my_abs() takes 1 positional argument but 2 were given但是如果参数类型不对,Python 解释器就无法帮我们检查。试试 my_abs 和内置函数 abs 的差别:
>>> my_abs('A')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 2, in my_abs
TypeError: unorderable types: str() >= int()
>>> abs('A')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: bad operand type for abs(): 'str'当传入了不恰当的参数时,内置函数 abs 会检查出参数错误,而我们定义的 my_abs 没有参数检查,会导致 if 语句出错,出错信息和 abs 不一样。所以,这个函数定义不够完善。
让我们修改一下 my_abs 的定义,对参数类型做检查,只允许整数和浮点数类型的参数。数据类型检查可以用内置函数 isinstance() 实现:
def my_abs(x):
if not isinstance(x, (int, float)):
raise TypeError('bad operand type')
if x >= 0:
return x
else:
return -x添加了参数检查后,如果传入错误的参数类型,函数就可以抛出一个错误:
>>> my_abs('A')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 3, in my_abs
TypeError: bad operand type错误和异常处理将在后续讲到。
返回多个值
函数可以返回多个值吗?答案是肯定的。
比如在游戏中经常需要从一个点移动到另一个点,给出坐标、位移和角度,就可以计算出新的坐标:
import math
def move(x, y, step, angle=0):
nx = x + step * math.cos(angle)
ny = y - step * math.sin(angle)
return nx, nyimport math 语句表示导入 math 包,并允许后续代码引用 math 包里的 sin、cos 等函数。
然后,我们就可以同时获得返回值:
>>> x, y = move(100, 100, 60, math.pi / 6)
>>> print(x, y)
151.96152422706632 70.0但其实这只是一种假象,Python 函数返回的仍然是单一值:
>>> r = move(100, 100, 60, math.pi / 6)
>>> print(r)
(151.96152422706632, 70.0)原来返回值是一个 tuple!但是,在语法上,返回一个 tuple 可以省略括号,而多个变量可以同时接收一个 tuple,按位置赋给对应的值,所以,Python 的函数返回多值其实就是返回一个 tuple,但写起来更方便。
函数的参数
位置参数
power(x, n)函数有两个参数:x 和 n,这两个参数都是位置参数,调用函数时,传入的两个值按照位置顺序依次赋给参数 x 和 n。
def power(x, n):
s = 1
while n > 0:
n = n - 1
s = s * x
return s默认参数
设置默认参数时,注意点如下:
- 必选参数在前,默认参数在后,否则 Python 的解释器会报错(思考一下为什么默认参数不能放在必选参数前面)
- 当函数有多个参数时,把变化大的参数放前面,变化小的参数放后面。变化小的参数就可以作为默认参数
def enroll(name, gender, age=6, city='Beijing'):
print('name:', name)
print('gender:', gender)
print('age:', age)
print('city:', city)有多个默认参数时,调用的时候,既可以按顺序提供默认参数,比如调用 enroll('Bob', 'M', 7),意思是,除了 name,gender 这两个参数外,最后 1 个参数应用在参数 age 上,city 参数由于没有提供,仍然使用默认值。
也可以不按顺序提供部分默认参数。当不按顺序提供部分默认参数时,需要把参数名写上。比如调用 enroll('Adam', 'M', city='Tianjin'),意思是,city 参数用传进去的值,其他默认参数继续使用默认值。
默认参数很有用,但使用不当,也会掉坑里。默认参数有个最大的坑,演示如下:
先定义一个函数,传入一个 list,添加一个 END 再返回:
def add_end(L=[]):
L.append('END')
return L当你正常调用时,结果似乎不错:
>>> add_end([1, 2, 3])
[1, 2, 3, 'END']
>>> add_end(['x', 'y', 'z'])
['x', 'y', 'z', 'END']当你使用默认参数调用时,一开始结果也是对的:
>>> add_end()
['END']但是,再次调用 add_end() 时,结果就不对了:
>>> add_end()
['END', 'END']
>>> add_end()
['END', 'END', 'END']原因解释如下:
Python 函数在定义的时候,默认参数 L 的值就被计算出来了,即 [],因为默认参数 L 也是一个变量,它指向对象 [],每次调用该函数,如果改变了 L 的内容,则下次调用时,默认参数的内容就变了,不再是函数定义时的 [] 了。
定义默认参数要牢记一点:默认参数必须指向不变对象!
要修改上面的例子,我们可以用 None 这个不变对象来实现:
def add_end(L=None):
if L is None:
L = []
L.append('END')
return L现在,无论调用多少次,都不会有问题:
>>> add_end()
['END']
>>> add_end()
['END']为什么要设计 str、None 这样的不变对象呢?因为不变对象一旦创建,对象内部的数据就不能修改,这样就减少了由于修改数据导致的错误。此外,由于对象不变,多任务环境下同时读取对象不需要加锁,同时读一点问题都没有。我们在编写程序时,如果可以设计一个不变对象,那就尽量设计成不变对象。
可变参数
def calc(numbers):
sum = 0
for n in numbers:
sum = sum + n * n
return sum但是调用的时候,需要先组装出一个 list 或 tuple:
>>> calc([1, 2, 3])
14
>>> calc((1, 3, 5, 7))
84如果利用可变参数,调用函数的方式可以简化成这样:
>>> calc(1, 2, 3)
14
>>> calc(1, 3, 5, 7)
84所以,我们把函数的参数改为可变参数:
def calc(*numbers):
sum = 0
for n in numbers:
sum = sum + n * n
return sum在函数内部,参数 numbers 接收到的是一个 tuple,因此,函数代码完全不变。但是,调用该函数时,可以传入任意个参数,包括 0 个参数:
>>> calc(1, 2)
5
>>> calc()
0如果已经有一个 list 或者 tuple,要调用一个可变参数怎么办?可以这样做:
>>> nums = [1, 2, 3]
>>> calc(nums[0], nums[1], nums[2])
14这种写法当然是可行的,问题是太繁琐,所以 Python 允许你在 list 或 tuple 前面加一个 * 号,把 list 或 tuple 的元素变成可变参数传进去:
>>> nums = [1, 2, 3]
>>> calc(*nums)
14*nums 表示把 nums 这个 list 的所有元素作为可变参数传进去。这种写法相当有用,而且很常见。
关键字参数
可变参数允许你传入 0 个或任意个参数,这些可变参数在函数调用时自动组装为一个 tuple。而关键字参数允许你传入 0 个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个 dict。请看示例:
def person(name, age, **kw):
print('name:', name, 'age:', age, 'other:', kw)函数 person 除了必选参数 name 和 age 外,还接受关键字参数 kw。在调用该函数时,可以只传入必选参数:
>>> person('Michael', 30)
name: Michael age: 30 other: {}也可以传入任意个数的关键字参数:
>>> person('Bob', 35, city='Beijing')
name: Bob age: 35 other: {'city': 'Beijing'}
>>> person('Adam', 45, gender='M', job='Engineer')
name: Adam age: 45 other: {'gender': 'M', 'job': 'Engineer'}关键字参数有什么用?它可以扩展函数的功能。比如,在 person 函数里,我们保证能接收到 name 和 age 这两个参数,但是,如果调用者愿意提供更多的参数,我们也能收到。试想你正在做一个用户注册的功能,除了用户名和年龄是必填项外,其他都是可选项,利用关键字参数来定义这个函数就能满足注册的需求。
和可变参数类似,也可以先组装出一个 dict,然后,把该 dict 转换为关键字参数传进去:
>>> extra = {'city': 'Beijing', 'job': 'Engineer'}
>>> person('Jack', 24, city=extra['city'], job=extra['job'])
name: Jack age: 24 other: {'city': 'Beijing', 'job': 'Engineer'}当然,上面复杂的调用可以用简化的写法:
>>> extra = {'city': 'Beijing', 'job': 'Engineer'}
>>> person('Jack', 24, **extra)
name: Jack age: 24 other: {'city': 'Beijing', 'job': 'Engineer'}**extra 表示把 extra 这个 dict 的所有 key-value 用关键字参数传入到函数的 **kw 参数,kw 将获得一个 dict,注意 kw 获得的 dict 是 extra 的一份拷贝,对 kw 的改动不会影响到函数外的 extra。
命名关键字参数
对于关键字参数,函数的调用者可以传入任意不受限制的关键字参数。至于到底传入了哪些,就需要在函数内部通过 kw 检查。
仍以 person() 函数为例,我们希望检查是否有 city 和 job 参数:
def person(name, age, **kw):
if 'city' in kw:
# 有 city 参数
pass
if 'job' in kw:
# 有 job 参数
pass
print('name:', name, 'age:', age, 'other:', kw)但是调用者仍可以传入不受限制的关键字参数:
>>> person('Jack', 24, city='Beijing', addr='Chaoyang', zipcode=123456)如果要限制关键字参数的名字,就可以用命名关键字参数,例如,只接收 city 和 job 作为关键字参数。这种方式定义的函数如下:
def person(name, age, *, city, job):
print(name, age, city, job)和关键字参数 **kw 不同,命名关键字参数需要一个特殊分隔符 *,* 后面的参数被视为命名关键字参数。
调用方式如下:
>>> person('Jack', 24, city='Beijing', job='Engineer')
Jack 24 Beijing Engineer如果函数定义中已经有了一个可变参数,后面跟着的命名关键字参数就不再需要一个特殊分隔符 * 了:
def person(name, age, *args, city, job):
print(name, age, args, city, job)命名关键字参数必须传入参数名,这和位置参数不同。如果没有传入参数名,调用将报错:
>>> person('Jack', 24, 'Beijing', 'Engineer')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: person() missing 2 required keyword-only arguments: 'city' and 'job'由于调用时缺少参数名 city 和 job,Python 解释器把前两个参数视为位置参数,后两个参数传给 *args,但缺少命名关键字参数导致报错。
命名关键字参数可以有缺省值,从而简化调用:
def person(name, age, *, city='Beijing', job):
print(name, age, city, job)由于命名关键字参数 city 具有默认值,调用时,可不传入 city 参数:
>>> person('Jack', 24, job='Engineer')
Jack 24 Beijing Engineer使用命名关键字参数时,要特别注意,如果没有可变参数,就必须加一个 * 作为特殊分隔符。如果缺少 *,Python 解释器将无法识别位置参数和命名关键字参数:
def person(name, age, city, job):
# 缺少 *,city 和 job 被视为位置参数
pass参数组合
在 Python 中定义函数,可以用必选参数、默认参数、可变参数、关键字参数和命名关键字参数,这 5 种参数都可以组合使用。但是请注意,参数定义的顺序必须是:必选参数、默认参数、可变参数、命名关键字参数和关键字参数。
比如定义一个函数,包含上述若干种参数:
def f1(a, b, c=0, *args, **kw):
print('a =', a, 'b =', b, 'c =', c, 'args =', args, 'kw =', kw)
def f2(a, b, c=0, *, d, **kw):
print('a =', a, 'b =', b, 'c =', c, 'd =', d, 'kw =', kw)在函数调用的时候,Python 解释器自动按照参数位置和参数名把对应的参数传进去。
>>> f1(1, 2)
a = 1 b = 2 c = 0 args = () kw = {}
>>> f1(1, 2, c=3)
a = 1 b = 2 c = 3 args = () kw = {}
>>> f1(1, 2, 3, 'a', 'b')
a = 1 b = 2 c = 3 args = ('a', 'b') kw = {}
>>> f1(1, 2, 3, 'a', 'b', x=99)
a = 1 b = 2 c = 3 args = ('a', 'b') kw = {'x': 99}
>>> f2(1, 2, d=99, ext=None)
a = 1 b = 2 c = 0 d = 99 kw = {'ext': None}最神奇的是通过一个 tuple 和 dict,你也可以调用上述函数:
>>> args = (1, 2, 3, 4)
>>> kw = {'d': 99, 'x': '#'}
>>> f1(*args, **kw)
a = 1 b = 2 c = 3 args = (4,) kw = {'d': 99, 'x': '#'}
>>> args = (1, 2, 3)
>>> kw = {'d': 88, 'x': '#'}
>>> f2(*args, **kw)
a = 1 b = 2 c = 3 d = 88 kw = {'x': '#'}所以,对于任意函数,都可以通过类似 func(*args, **kw) 的形式调用它,无论它的参数是如何定义的。
虽然可以组合多达 5 种参数,但不要同时使用太多的组合,否则函数接口的可理解性很差。
小结
Python 的函数具有非常灵活的参数形态,既可以实现简单的调用,又可以传入非常复杂的参数。
默认参数一定要用不可变对象,如果是可变对象,程序运行时会有逻辑错误!
要注意定义可变参数和关键字参数的语法:
*args是可变参数,args 接收的是一个 tuple;**kw是关键字参数,kw 接收的是一个 dict。
以及调用函数时如何传入可变参数和关键字参数的语法:
- 可变参数既可以直接传入:
func(1, 2, 3),又可以先组装 list 或 tuple,再通过*args传入:func(*(1, 2, 3)); - 关键字参数既可以直接传入:
func(a=1, b=2),又可以先组装 dict,再通过**kw传入:func(**{'a': 1, 'b': 2})。
使用 *args 和 **kw 是 Python 的习惯写法,当然也可以用其他参数名,但最好使用习惯用法。
命名的关键字参数是为了限制调用者可以传入的参数名,同时可以提供默认值。
定义命名的关键字参数在没有可变参数的情况下不要忘了写分隔符 *,否则定义的将是位置参数。
递归函数
def fact(n):
return fact_iter(n, 1)
def fact_iter(num, product):
if num == 1:
return product
return fact_iter(num - 1, num * product)可以看到,return fact_iter(num - 1, num * product) 仅返回递归函数本身,num - 1 和 num * product 在函数调用前就会被计算,不影响函数调用。
fact(5) 对应的 fact_iter(5, 1) 的调用如下:
===> fact_iter(5, 1)
===> fact_iter(4, 5)
===> fact_iter(3, 20)
===> fact_iter(2, 60)
===> fact_iter(1, 120)
===> 120尾递归调用时,如果做了优化,栈不会增长,因此,无论多少次调用也不会导致栈溢出。
遗憾的是,大多数编程语言没有针对尾递归做优化,Python 解释器也没有做优化,所以,即使把上面的 fact(n) 函数改成尾递归方式,也会导致栈溢出。
小结
使用递归函数的优点是逻辑简单清晰,缺点是过深的调用会导致栈溢出。
针对尾递归优化的语言可以通过尾递归防止栈溢出。尾递归事实上和循环是等价的,没有循环语句的编程语言只能通过尾递归实现循环。
Python 标准的解释器没有针对尾递归做优化,任何递归函数都存在栈溢出的问题。
高级特性
切片
取一个 list 或 tuple 的部分元素是非常常见的操作。比如,一个 list 如下:
>>> L = ['Michael', 'Sarah', 'Tracy', 'Bob', 'Jack']取前 3 个元素,应该怎么做?
>>> L[0:3]
['Michael', 'Sarah', 'Tracy']如果第一个索引是 0,还可以省略:
>>> L[:3]
['Michael', 'Sarah', 'Tracy']也可以从索引 1 开始,取出 2 个元素出来:
>>> L[1:3]
['Sarah', 'Tracy']类似的,既然 Python 支持 L[-1] 取倒数第一个元素,那么它同样支持倒数切片,试试:
>>> L[-2:]
['Bob', 'Jack']
>>> L[-2:-1]
['Bob']记住倒数第一个元素的索引是 -1。
切片操作十分有用。我们先创建一个 0-99 的数列:
>>> L = list(range(100))
>>> L
[0, 1, 2, 3, ..., 99]可以通过切片轻松取出某一段数列。比如前 10 个数:
>>> L[:10]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]后 10 个数:
>>> L[-10:]
[90, 91, 92, 93, 94, 95, 96, 97, 98, 99]前 11-20 个数:
>>> L[10:20]
[10, 11, 12, 13, 14, 15, 16, 17, 18, 19]前 10 个数,每两个取一个:
>>> L[:10:2]
[0, 2, 4, 6, 8]所有数,每 5 个取一个:
>>> L[::5]
[0, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95]甚至什么都不写,只写 [:] 就可以原样复制一个 list:
>>> L[:]
[0, 1, 2, 3, ..., 99]tuple 也是一种 list,唯一区别是 tuple 不可变。因此,tuple 也可以用切片操作,只是操作的结果仍是 tuple:
>>> (0, 1, 2, 3, 4, 5)[:3]
(0, 1, 2)字符串 ‘xxx’ 也可以看成是一种 list,每个元素就是一个字符。因此,字符串也可以用切片操作,只是操作结果仍是字符串:
>>> 'ABCDEFG'[:3]
'ABC'
>>> 'ABCDEFG'[::2]
'ACEG'在很多编程语言中,针对字符串提供了很多各种截取函数(例如,substring),其实目的就是对字符串切片。Python 没有针对字符串的截取函数,只需要切片一个操作就可以完成,非常简单。
迭代
Python 的 for 循环不仅可以用在 list 或 tuple 上,还可以作用在其他可迭代对象上。
list 这种数据类型虽然有下标,但很多其他数据类型是没有下标的,但是,只要是可迭代对象,无论有无下标,都可以迭代,比如 dict 就可以迭代:
>>> d = {'a': 1, 'b': 2, 'c': 3}
>>> for key in d:
... print(key)
...
a
c
b因为 dict 的存储不是按照 list 的方式顺序排列,所以,迭代出的结果顺序很可能不一样。
默认情况下,dict 迭代的是 key。如果要迭代 value,可以用 for value in d.values(),如果要同时迭代 key 和 value,可以用 for k, v in d.items()。
由于字符串也是可迭代对象,因此,也可以作用于 for 循环:
>>> for ch in 'ABC':
... print(ch)
...
A
B
C所以,当我们使用 for 循环时,只要作用于一个可迭代对象,for 循环就可以正常运行,而我们不太关心该对象究竟是 list 还是其他数据类型。
那么,如何判断一个对象是可迭代对象呢?方法是通过 collections.abc 模块的 Iterable 类型判断:
>>> from collections.abc import Iterable
>>> isinstance('abc', Iterable) # str 是否可迭代
True
>>> isinstance([1,2,3], Iterable) # list 是否可迭代
True
>>> isinstance(123, Iterable) # 整数是否可迭代
False最后一个小问题,如果要对 list 实现类似 Java 那样的下标循环怎么办?Python 内置的 enumerate 函数可以把一个 list 变成索引-元素对,这样就可以在 for 循环中同时迭代索引和元素本身:
>>> for i, value in enumerate(['A', 'B', 'C']):
... print(i, value)
...
0 A
1 B
2 C上面的 for 循环里,同时引用了两个变量,在 Python 里是很常见的,比如下面的代码:
>>> for x, y in [(1, 1), (2, 4), (3, 9)]:
... print(x, y)
...
1 1
2 4
3 9小结
任何可迭代对象都可以作用于 for 循环,包括我们自定义的数据类型,只要符合迭代条件,就可以使用 for 循环。
列表生成式
列表生成式即 List Comprehensions,是 Python 内置的非常简单却强大的可以用来创建 list 的生成式。
举个例子,要生成 list [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] 可以用 list(range(1, 11)):
>>> list(range(1, 11))
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]但如果要生成 [1x1, 2x2, 3x3, ..., 10x10] 怎么做?方法一是循环:
>>> L = []
>>> for x in range(1, 11):
... L.append(x * x)
...
>>> L
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]但是循环太繁琐,而列表生成式则可以用一行语句代替循环生成上面的 list:
>>> [x * x for x in range(1, 11)]
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]写列表生成式时,把要生成的元素 x * x 放到前面,后面跟 for 循环,就可以把 list 创建出来,十分有用,多写几次,很快就可以熟悉这种语法。
for 循环后面还可以加上 if 判断,这样我们就可以筛选出仅偶数的平方:
>>> [x * x for x in range(1, 11) if x % 2 == 0]
[4, 16, 36, 64, 100]还可以使用两层循环,可以生成全排列:
>>> [m + n for m in 'ABC' for n in 'XYZ']
['AX', 'AY', 'AZ', 'BX', 'BY', 'BZ', 'CX', 'CY', 'CZ']三层和三层以上的循环就很少用到了。
运用列表生成式,可以写出非常简洁的代码。例如,列出当前目录下的所有文件和目录名,可以通过一行代码实现:
>>> import os # 导入 os 模块,模块的概念后面讲到
>>> [d for d in os.listdir('.')] # os.listdir 可以列出文件和目录
['.emacs.d', '.ssh', '.Trash', 'Adlm', 'Applications', 'Desktop', 'Documents', 'Downloads', 'Library', 'Movies', 'Music', 'Pictures', 'Public', 'VirtualBox VMs', 'Workspace', 'XCode']for 循环其实可以同时使用两个甚至多个变量,比如 dict 的 items() 可以同时迭代 key 和 value:
>>> d = {'x': 'A', 'y': 'B', 'z': 'C' }
>>> for k, v in d.items():
... print(k, '=', v)
...
y = B
x = A
z = C因此,列表生成式也可以使用两个变量来生成 list:
>>> d = {'x': 'A', 'y': 'B', 'z': 'C' }
>>> [k + '=' + v for k, v in d.items()]
['y=B', 'x=A', 'z=C']最后把一个 list 中所有的字符串变成小写:
>>> L = ['Hello', 'World', 'IBM', 'Apple']
>>> [s.lower() for s in L]
['hello', 'world', 'ibm', 'apple']在一个列表生成式中,for 前面的 if ... else 是表达式,而 for 后面的 if 是过滤条件,不能带 else。
即以下 2 种形式是错误的:
>>> [x for x in range(1, 11) if x % 2 == 0 else 0]
File "<stdin>", line 1
[x for x in range(1, 11) if x % 2 == 0 else 0]
^
SyntaxError: invalid syntax>>> [x if x % 2 == 0 for x in range(1, 11)]
File "<stdin>", line 1
[x if x % 2 == 0 for x in range(1, 11)]
^
SyntaxError: invalid syntax生成器
在 Python 中一边循环一边计算的机制,称为生成器:generator。
要创建一个 generator,有很多种方法。第一种方法很简单,只要把一个列表生成式的 [] 改成 (),就创建了一个 generator:
>>> L = [x * x for x in range(10)]
>>> L
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
>>> g = (x * x for x in range(10))
>>> g
<generator object <genexpr> at 0x1022ef630>创建 L 和 g 的区别仅在于最外层的 [] 和 (),L 是一个 list,而 g 是一个 generator。
我们可以直接打印出 list 的每一个元素,但我们怎么打印出 generator 的每一个元素呢?
如果要一个一个打印出来,可以通过 next() 函数获得 generator 的下一个返回值:
>>> next(g)
0
>>> next(g)
1
>>> next(g)
4
>>> next(g)
9
>>> next(g)
16
>>> next(g)
25
>>> next(g)
36
>>> next(g)
49
>>> next(g)
64
>>> next(g)
81
>>> next(g)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration我们讲过,generator 保存的是算法,每次调用 next(g),就计算出 g 的下一个元素的值,直到计算到最后一个元素,没有更多的元素时,抛出 StopIteration 的错误。
当然,上面这种不断调用 next(g) 实在是太变态了,正确的方法是使用 for 循环,因为 generator 也是可迭代对象:
>>> g = (x * x for x in range(10))
>>> for n in g:
... print(n)
...
0
1
4
9
16
25
36
49
64
81所以,我们创建了一个 generator 后,基本上永远不会调用 next(),而是通过 for 循环来迭代它,并且不需要关心 StopIteration 的错误。
generator 非常强大。如果推算的算法比较复杂,用类似列表生成式的 for 循环无法实现的时候,还可以用函数来实现。
比如,著名的斐波拉契数列(Fibonacci),除第一个和第二个数外,任意一个数都可由前两个数相加得到:
1, 1, 2, 3, 5, 8, 13, 21, 34, …
斐波拉契数列用列表生成式写不出来,但是,用函数把它打印出来却很容易:
def fib(max):
n, a, b = 0, 0, 1
while n < max:
print(b)
a, b = b, a + b
n = n + 1
return 'done'注意,赋值语句:
a, b = b, a + b相当于:
t = (b, a + b) # t 是一个 tuple
a = t[0]
b = t[1]但不必显式写出临时变量 t 就可以赋值。
上面的函数可以输出斐波那契数列的前 N 个数:
>>> fib(6)
1
1
2
3
5
8
'done'仔细观察,可以看出,fib 函数实际上是定义了斐波拉契数列的推算规则,可以从第一个元素开始,推算出后续任意的元素,这种逻辑其实非常类似 generator。
也就是说,上面的函数和 generator 仅一步之遥。要把 fib 函数变成 generator 函数,只需要把 print(b) 改为 yield b 就可以了:
def fib(max):
n, a, b = 0, 0, 1
while n < max:
yield b
a, b = b, a + b
n = n + 1
return 'done'这就是定义 generator 的另一种方法。如果一个函数定义中包含 yield 关键字,那么这个函数就不再是一个普通函数,而是一个 generator 函数,调用一个 generator 函数将返回一个 generator:
>>> f = fib(6)
>>> f
<generator object fib at 0x104feaaa0>这里,最难理解的就是 generator 函数和普通函数的执行流程不一样。普通函数是顺序执行,遇到 return 语句或者最后一行函数语句就返回。而变成 generator 的函数,在每次调用 next() 的时候执行,遇到 yield 语句返回,再次执行时从上次返回的 yield 语句处继续执行。
举个简单的例子,定义一个 generator 函数,依次返回数字 1,3,5:
def odd():
print('step 1')
yield 1
print('step 2')
yield(3)
print('step 3')
yield(5)调用该 generator 函数时,首先要生成一个 generator 对象,然后用 next() 函数不断获得下一个返回值:
>>> o = odd()
>>> next(o)
step 1
1
>>> next(o)
step 2
3
>>> next(o)
step 3
5
>>> next(o)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration可以看到,odd 不是普通函数,而是 generator 函数,在执行过程中,遇到 yield 就中断,下次又继续执行。执行 3 次 yield 后,已经没有 yield 可以执行了,所以,第 4 次调用 next(o) 就报错。
请务必注意:调用 generator 函数会创建一个 generator 对象,多次调用 generator 函数会创建多个相互独立的 generator。
>>> next(odd())
step 1
1
>>> next(odd())
step 1
1
>>> next(odd())
step 1
1原因在于 odd() 会创建一个新的 generator 对象,上述代码实际上创建了 3 个完全独立的 generator,对 3 个 generator 分别调用 next() 当然每个都会返回第一个值。
正确的写法是创建一个 generator 对象,然后不断对这一个 generator 对象调用 next():
>>> g = odd()
>>> next(g)
step 1
1
>>> next(g)
step 2
3
>>> next(g)
step 3
5回到 fib 的例子,我们在循环过程中不断调用 yield,就会不断中断。当然要给循环设置一个条件来退出循环,不然就会产生一个无限数列出来。
同样的,把函数改成 generator 函数后,我们基本上从来不会用 next() 来获取下一个返回值,而是直接使用 for 循环来迭代:
>>> for n in fib(6):
... print(n)
...
1
1
2
3
5
8但是用 for 循环调用 generator 时,发现拿不到 generator 的 return 语句的返回值。如果想要拿到返回值,必须捕获 StopIteration 错误,返回值包含在 StopIteration 的 value 中:
>>> g = fib(6)
>>> while True:
... try:
... x = next(g)
... print('g:', x)
... except StopIteration as e:
... print('Generator return value:', e.value)
... break
...
g: 1
g: 1
g: 2
g: 3
g: 5
g: 8
Generator return value: done关于如何捕获错误,后面的错误处理还会详细讲解。
小结
generator 是非常强大的工具,在 Python 中,可以简单地把列表生成式改成 generator,也可以通过函数实现复杂逻辑的 generator。
要理解 generator 的工作原理,它是在 for 循环的过程中不断计算出下一个元素,并在适当的条件结束 for 循环。对于函数改成的 generator 来说,遇到 return 语句或者执行到函数体最后一行语句,就是结束 generator 的指令,for 循环随之结束。
请注意区分普通函数和 generator 函数,普通函数调用直接返回结果:
>>> r = abs(6)
>>> r
6generator 函数的调用实际返回一个 generator 对象:
>>> g = fib(6)
>>> g
<generator object fib at 0x1022ef948>迭代器
我们已经知道,可以直接作用于 for 循环的数据类型有以下几种:
一类是集合数据类型,如 list、tuple、dict、set、str 等;
一类是 generator,包括生成器和带 yield 的 generator function。
这些可以直接作用于 for 循环的对象统称为可迭代对象:Iterable。
可以使用 isinstance() 判断一个对象是否是 Iterable 对象:
>>> from collections.abc import Iterable
>>> isinstance([], Iterable)
True
>>> isinstance({}, Iterable)
True
>>> isinstance('abc', Iterable)
True
>>> isinstance((x for x in range(10)), Iterable)
True
>>> isinstance(100, Iterable)
False而生成器不但可以作用于 for 循环,还可以被 next() 函数不断调用并返回下一个值,直到最后抛出 StopIteration 错误表示无法继续返回下一个值了。
可以被 next() 函数调用并不断返回下一个值的对象称为迭代器:Iterator。
可以使用 isinstance() 判断一个对象是否是 Iterator 对象:
>>> from collections.abc import Iterator
>>> isinstance((x for x in range(10)), Iterator)
True
>>> isinstance([], Iterator)
False
>>> isinstance({}, Iterator)
False
>>> isinstance('abc', Iterator)
False生成器都是 Iterator 对象,但 list、dict、str 虽然是 Iterable,却不是 Iterator。
把 list、dict、str 等 Iterable 变成 Iterator 可以使用 iter() 函数:
>>> isinstance(iter([]), Iterator)
True
>>> isinstance(iter('abc'), Iterator)
True你可能会问,为什么 list、dict、str 等数据类型不是 Iterator?
这是因为 Python 的 Iterator 对象表示的是一个数据流,Iterator 对象可以被 next() 函数调用并不断返回下一个数据,直到没有数据时抛出 StopIteration 错误。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过 next() 函数实现按需计算下一个数据,所以 Iterator 的计算是惰性的,只有在需要返回下一个数据时它才会计算。
Iterator 甚至可以表示一个无限大的数据流,例如全体自然数。而使用 list 是永远不可能存储全体自然数的。
小结
凡是可作用于 for 循环的对象都是 Iterable 类型;
凡是可作用于 next() 函数的对象都是 Iterator 类型,它们表示一个惰性计算的序列;
集合数据类型如 list、dict、str 等是 Iterable 但不是 Iterator,不过可以通过 iter() 函数获得一个 Iterator 对象。
Python 的 for 循环本质上就是通过不断调用 next() 函数实现的,例如:
for x in [1, 2, 3, 4, 5]:
pass实际上完全等价于:
# 首先获得 Iterator 对象:
it = iter([1, 2, 3, 4, 5])
# 循环:
while True:
try:
# 获得下一个值:
x = next(it)
except StopIteration:
# 遇到 StopIteration 就退出循环
break函数式编程
高阶函数
变量可以指向函数
>>> f = abs
>>> f(-10)
10函数名也是变量
>>> abs = 10
>>> abs(-10)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'int' object is not callable由于 abs 函数实际上是定义在
import builtins模块中的,所以要让修改 abs 变量的指向在其它模块也生效,要用import builtins; builtins.abs = 10。
传入函数
一个函数就可以接收另一个函数作为参数,这种函数就称之为高阶函数
def add(x, y, f):
return f(x) + f(y)
print(add(-5, 6, abs))map
>>> def f(x):
... return x * x
...
>>> r = map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> list(r)
[1, 4, 9, 16, 25, 36, 49, 64, 81]
>>> list(map(str, [1, 2, 3, 4, 5, 6, 7, 8, 9]))
['1', '2', '3', '4', '5', '6', '7', '8', '9']reduce
reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4)from functools import reduce
DIGITS = {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9}
def str2int(s):
def fn(x, y):
return x * 10 + y
def char2num(s):
return DIGITS[s]
return reduce(fn, map(char2num, s))还可以用 lambda 函数进一步简化成:
from functools import reduce
DIGITS = {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9}
def char2num(s):
return DIGITS[s]
def str2int(s):
return reduce(lambda x, y: x * 10 + y, map(char2num, s))filter
def is_odd(n):
return n % 2 == 1
list(filter(is_odd, [1, 2, 4, 5, 6, 9, 10, 15]))
# 结果: [1, 5, 9, 15]注意到 filter() 函数返回的是一个 Iterator,也就是一个惰性序列,所以要强迫 filter() 完成计算结果,需要用 list() 函数获得所有结果并返回 list。
用 filter 求素数
def _odd_iter():
n = 1
while True:
n = n + 2
yield n
def _not_divisible(n):
# def _can_be_devided(x):
# return x % n > 0
return lambda x: x % n > 0
def primes():
yield 2
it = _odd_iter() # 初始序列
while True:
n = next(it) # 返回序列的第一个数
yield n
it = filter(_not_divisible(n), it) # 构造新序列
# 打印 1000 以内的素数:
for n in primes():
if n < 1000:
print(n)
else:
breaksort
>>> sorted([36, 5, -12, 9, -21])
[-21, -12, 5, 9, 36]
>>> sorted([36, 5, -12, 9, -21], key=abs) # 自定义排序
[5, 9, -12, -21, 36]
>>> sorted(['bob', 'about', 'Zoo', 'Credit']) # 按照 ASCII 的大小比较
['Credit', 'Zoo', 'about', 'bob']
>>> sorted(['bob', 'about', 'Zoo', 'Credit'], key=str.lower) # 忽略大小写的排序
['about', 'bob', 'Credit', 'Zoo']
>>> sorted(['bob', 'about', 'Zoo', 'Credit'], key=str.lower, reverse=True) # 倒序
['Zoo', 'Credit', 'bob', 'about']返回函数
函数作为返回值
高阶函数除了可以接受函数作为参数外,还可以把函数作为结果值返回。
def lazy_sum(*args):
def sum():
ax = 0
for n in args:
ax = ax + n
return ax
return sum
>>> f = lazy_sum(1, 3, 5, 7, 9)
>>> f
<function lazy_sum.<locals>.sum at 0x101c6ed90>
>>> f()
25每次调用都会返回一个新的函数,即使传入相同的参数,f1() 和 f2() 的调用结果互不影响。
>>> f1 = lazy_sum(1, 3, 5, 7, 9)
>>> f2 = lazy_sum(1, 3, 5, 7, 9)
>>> f1==f2
False闭包
def count():
fs = []
for i in range(1, 4):
def f():
return i*i
fs.append(f)
return fs
f1, f2, f3 = count()
>>> f1()
9
>>> f2()
9
>>> f3()
9类似于 js,python 也有闭包,解决方式同 js
def count():
def f(j):
def g():
return j*j
return g
fs = []
for i in range(1, 4):
fs.append(f(i)) # f(i) 立刻被执行,因此 i 的当前值被传入 f()
return fs
>>> f1, f2, f3 = count()
>>> f1()
1
>>> f2()
4
>>> f3()
9nonlocal
使用闭包,就是内层函数引用了外层函数的局部变量。如果只是读外层变量的值,我们会发现返回的闭包函数调用一切正常:
def inc():
x = 0
def fn():
# 仅读取 x 的值:
return x + 1
return fn
f = inc()
print(f()) # 1
print(f()) # 1但是,如果对外层变量赋值,由于 Python 解释器会把 x 当作函数 fn() 的局部变量,它会报错:
def inc():
x = 0
def fn():
# nonlocal x # 去掉注释可以正常运行
x = x + 1 # 不加 nonlocal,这里会报错,会被当成 fn 的局部变量
return x
return fn
f = inc()
print(f()) # 1
print(f()) # 2原因是 x 作为局部变量并没有初始化,直接计算 x+1 是不行的。但我们其实是想引用 inc() 函数内部的 x,所以需要在 fn() 函数内部加一个 nonlocal x 的声明。加上这个声明后,解释器把 fn() 的 x 看作外层函数的局部变量,它已经被初始化了,可以正确计算 x+1。
匿名函数
>>> list(map(lambda x: x * x, [1, 2, 3, 4, 5, 6, 7, 8, 9]))
[1, 4, 9, 16, 25, 36, 49, 64, 81]匿名函数类似于
def f(x):
return x * x匿名函数有个限制,就是只能有一个表达式,不用写 return,返回值就是该表达式的结果。
用匿名函数有个好处,因为函数没有名字,不必担心函数名冲突。此外,匿名函数也是一个函数对象,也可以把匿名函数赋值给一个变量,再利用变量来调用该函数:
>>> f = lambda x: x * x
>>> f
<function <lambda> at 0x101c6ef28>
>>> f(5)
25同样,也可以把匿名函数作为返回值返回,比如:
def build(x, y):
return lambda: x * x + y * y装饰器
由于函数也是一个对象,而且函数对象可以被赋值给变量,所以,通过变量也能调用该函数。
>>> def now():
... print('2015-3-25')
...
>>> f = now
>>> f()
2015-3-25函数对象有一个 __name__ 属性,可以拿到函数的名字:
>>> now.__name__
'now'
>>> f.__name__
'now'假设我们要增强 now() 函数的功能,比如,在函数调用前后自动打印日志,但又不希望修改 now() 函数的定义,这种在代码运行期间动态增加功能的方式,称之为“装饰器”(Decorator)。
def log(func):
def wrapper(*args, **kw):
print('call %s():' % func.__name__)
return func(*args, **kw)
return wrapper观察上面的 log,因为它是一个 decorator,所以接受一个函数作为参数,并返回一个函数。我们要借助 Python 的 @ 语法,把 decorator 置于函数的定义处:
@log
def now():
print('2015-3-25')调用 now() 函数,不仅会运行 now() 函数本身,还会在运行 now() 函数前打印一行日志:
>>> now()
call now():
2015-3-25把 @log 放到 now() 函数的定义处,相当于执行了语句:
now = log(now)如果 decorator 本身需要传入参数,那就需要编写一个返回 decorator 的高阶函数,写出来会更复杂。比如,要自定义 log 的文本:
def log(text):
def decorator(func):
def wrapper(*args, **kw):
print('%s %s():' % (text, func.__name__))
return func(*args, **kw)
return wrapper
return decorator这个 3 层嵌套的 decorator 用法如下:
@log('execute')
def now():
print('2015-3-25')
>>> now()
execute now():
2015-3-25和两层嵌套的 decorator 相比,3 层嵌套的效果是这样的:
>>> now = log('execute')(now)我们来剖析上面的语句,首先执行 log('execute'),返回的是 decorator 函数,再调用返回的函数,参数是 now 函数,返回值最终是 wrapper 函数。
以上两种 decorator 的定义都没有问题,但还差最后一步。因为我们讲了函数也是对象,它有 __name__ 等属性,但你去看经过 decorator 装饰之后的函数,它们的 __name__ 已经从原来的 now 变成了 wrapper:
>>> now.__name__
'wrapper'因为返回的那个 wrapper() 函数名字就是 wrapper,所以,需要把原始函数的 __name__ 等属性复制到 wrapper() 函数中,否则,有些依赖函数签名的代码执行就会出错。
不需要编写 wrapper.__name__ = func.__name__ 这样的代码,Python 内置的 functools.wraps 就是干这个事的,所以,一个完整的 decorator 的写法如下:
import functools
def log(func):
@functools.wraps(func)
def wrapper(*args, **kw):
print('call %s():' % func.__name__)
return func(*args, **kw)
return wrapper或者针对带参数的 decorator:
import functools
def log(text):
def decorator(func):
@functools.wraps(func)
def wrapper(*args, **kw):
print('%s %s():' % (text, func.__name__))
return func(*args, **kw)
return wrapper
return decorator偏函数
>>> import functools
>>> int2 = functools.partial(int, base=2)
>>> int2('1000000')
64
>>> int2('1010101')
85所以,简单总结 functools.partial 的作用就是,把一个函数的某些参数给固定住(也就是设置默认值),返回一个新的函数,调用这个新函数会更简单。
注意到上面的新的 int2 函数,仅仅是把 base 参数重新设定默认值为 2,但也可以在函数调用时传入其他值:
>>> int2('1000000', base=10)
1000000最后,创建偏函数时,实际上可以接收函数对象、*args 和 **kw 这 3 个参数,当传入:
int2 = functools.partial(int, base=2)实际上固定了 int() 函数的关键字参数 base,也就是:
int2('10010')相当于:
kw = { 'base': 2 }
int('10010', **kw)模块
使用模块有什么好处?
最大的好处是大大提高了代码的可维护性。其次,编写代码不必从零开始。当一个模块编写完毕,就可以被其他地方引用。我们在编写程序的时候,也经常引用其他模块,包括 Python 内置的模块和来自第三方的模块。
使用模块还可以避免函数名和变量名冲突。相同名字的函数和变量完全可以分别存在不同的模块中,因此,我们自己在编写模块时,不必考虑名字会与其他模块冲突。但是也要注意,尽量不要与内置函数名字冲突。点这里查看 Python 的所有内置函数。
如果不同的人编写的模块名相同怎么办?为了避免模块名冲突,Python 又引入了按目录来组织模块的方法,称为包(Package)。
举个例子,一个 abc.py 的文件就是一个名字叫 abc 的模块,一个 xyz.py 的文件就是一个名字叫 xyz 的模块。
现在,假设我们的 abc 和 xyz 这两个模块名字与其他模块冲突了,于是我们可以通过包来组织模块,避免冲突。方法是选择一个顶层包名,比如 mycompany,按照如下目录存放:
mycompany
├─ __init__.py
├─ abc.py
└─ xyz.py引入了包以后,只要顶层的包名不与别人冲突,那所有模块都不会与别人冲突。现在,abc.py 模块的名字就变成了 mycompany.abc,类似的,xyz.py 的模块名变成了 mycompany.xyz。
请注意,每一个包目录下面都会有一个 __init__.py 的文件,这个文件是必须存在的,否则,Python 就把这个目录当成普通目录,而不是一个包。__init__.py 可以是空文件,也可以有 Python 代码,因为 __init__.py 本身就是一个模块,而它的模块名就是 mycompany。
类似的,可以有多级目录,组成多级层次的包结构。比如如下的目录结构:
mycompany
├─ web
│ ├─ __init__.py
│ ├─ utils.py
│ └─ www.py
├─ __init__.py
├─ abc.py
└─ utils.py文件 www.py 的模块名就是 mycompany.web.www,两个文件 utils.py 的模块名分别是 mycompany.utils 和 mycompany.web.utils
自己创建模块时要注意命名,不能和 Python 自带的模块名称冲突。例如,系统自带了 sys 模块,自己的模块就不可命名为 sys.py,否则将无法导入系统自带的 sys 模块。
使用模块
Python 本身就内置了很多非常有用的模块,只要安装完毕,这些模块就可以立刻使用。
我们以内建的 sys 模块为例,编写一个 hello 的模块:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
' a test module '
__author__ = 'Michael Liao'
import sys
def test():
args = sys.argv
if len(args)==1:
print('Hello, world!')
elif len(args)==2:
print('Hello, %s!' % args[1])
else:
print('Too many arguments!')
if __name__=='__main__':
test()第 1 行和第 2 行是标准注释,第 1 行注释可以让这个 hello.py 文件直接在 Unix/Linux/Mac 上运行,第 2 行注释表示 .py 文件本身使用标准 UTF-8 编码;
第 4 行是一个字符串,表示模块的文档注释,任何模块代码的第一个字符串都被视为模块的文档注释;
第 6 行使用 __author__ 变量把作者写进去,这样当你公开源代码后别人就可以瞻仰你的大名;
以上就是 Python 模块的标准文件模板,当然也可以全部删掉不写,但是,按标准办事肯定没错。
后面开始就是真正的代码部分。
你可能注意到了,使用 sys 模块的第一步,就是导入该模块:
import sys导入 sys 模块后,我们就有了变量 sys 指向该模块,利用 sys 这个变量,就可以访问 sys 模块的所有功能。
sys 模块有一个 argv 变量,用 list 存储了命令行的所有参数。argv 至少有一个元素,因为第一个参数永远是该 .py 文件的名称,例如:
运行 python3 hello.py 获得的 sys.argv 就是 ['hello.py'];
运行 python3 hello.py Michael 获得的 sys.argv 就是 ['hello.py', 'Michael']。
最后,注意到这两行代码:
if __name__=='__main__':
test()当我们在命令行运行 hello 模块文件时,Python 解释器把一个特殊变量 __name__ 置为 __main__,而如果在其他地方导入该 hello 模块时,if 判断将失败,因此,这种 if 测试可以让一个模块通过命令行运行时执行一些额外的代码,最常见的就是运行测试。
我们可以用命令行运行 hello.py 看看效果:
$ python3 hello.py
Hello, world!
$ python3 hello.py Michael
Hello, Michael!如果启动 Python 交互环境,再导入 hello 模块:
$ python3
Python 3.4.3 (v3.4.3:9b73f1c3e601, Feb 23 2015, 02:52:03)
[GCC 4.2.1 (Apple Inc. build 5666) (dot 3)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import hello
>>>导入时,没有打印 Hello, word!,因为没有执行 test() 函数。
调用 hello.test() 时,才能打印出 Hello, word!:
>>> hello.test()
Hello, world!作用域
在一个模块中,我们可能会定义很多函数和变量,但有的函数和变量我们希望给别人使用,有的函数和变量我们希望仅仅在模块内部使用。在 Python 中,是通过 _ 前缀来实现的。
正常的函数和变量名是公开的(public),可以被直接引用,比如:abc,x123,PI 等;
类似 __xxx__ 这样的变量是特殊变量,可以被直接引用,但是有特殊用途,比如上面的 __author__,__name__ 就是特殊变量,hello 模块定义的文档注释也可以用特殊变量 __doc__ 访问,我们自己的变量一般不要用这种变量名;
类似 _xxx 和 __xxx 这样的函数或变量就是非公开的(private),不应该被直接引用,比如 _abc,__abc 等;
之所以我们说,private 函数和变量“不应该”被直接引用,而不是“不能”被直接引用,是因为 Python 并没有一种方法可以完全限制访问 private 函数或变量,但是,从编程习惯上不应该引用 private 函数或变量。
private 函数或变量不应该被别人引用,那它们有什么用呢?请看例子:
def _private_1(name):
return 'Hello, %s' % name
def _private_2(name):
return 'Hi, %s' % name
def greeting(name):
if len(name) > 3:
return _private_1(name)
else:
return _private_2(name)我们在模块里公开 greeting() 函数,而把内部逻辑用 private 函数隐藏起来了,这样,调用 greeting() 函数不用关心内部的 private 函数细节,这也是一种非常有用的代码封装和抽象的方法,即:
外部不需要引用的函数全部定义成 private,只有外部需要引用的函数才定义为 public。
安装第三方模块
安装 Pillow 的命令就是
pip install Pillow安装常用模块
推荐直接使用 Anaconda,内置了许多非常有用的第三方库
模块搜索路径
当我们试图加载一个模块时,Python 会在指定的路径下搜索对应的 .py 文件,如果找不到,就会报错:
>>> import mymodule
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ImportError: No module named mymodule默认情况下,Python 解释器会搜索当前目录、所有已安装的内置模块和第三方模块,搜索路径存放在 sys 模块的 path 变量中:
>>> import sys
>>> sys.path
['', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python36.zip', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6', ..., '/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages']如果我们要添加自己的搜索目录,有两种方法:
-
直接修改 sys.path,添加要搜索的目录,但是运行结束后失效。
>>> import sys >>> sys.path.append('/Users/michael/my_py_scripts') -
设置环境变量 PYTHONPATH,该环境变量的内容会被自动添加到模块搜索路径中。设置方式与设置 Path 环境变量类似。注意只需要添加你自己的搜索路径,Python 自己本身的搜索路径不受影响。
面向对象编程
在 Python 中,所有数据类型都可以视为对象,当然也可以自定义对象。自定义的对象数据类型就是面向对象中的类(Class)的概念。
我们以一个例子来说明面向过程和面向对象在程序流程上的不同之处。
假设我们要处理学生的成绩表,为了表示一个学生的成绩,面向过程的程序可以用一个 dict 表示:
std1 = { 'name': 'Michael', 'score': 98 }
std2 = { 'name': 'Bob', 'score': 81 }而处理学生成绩可以通过函数实现,比如打印学生的成绩:
def print_score(std):
print('%s: %s' % (std['name'], std['score']))如果采用面向对象的程序设计思想,我们首选思考的不是程序的执行流程,而是 Student 这种数据类型应该被视为一个对象,这个对象拥有 name 和 score 这两个属性(Property)。如果要打印一个学生的成绩,首先必须创建出这个学生对应的对象,然后,给对象发一个 print_score 消息,让对象自己把自己的数据打印出来。
class Student(object):
def __init__(self, name, score):
self.name = name
self.score = score
def print_score(self):
print('%s: %s' % (self.name, self.score))给对象发消息实际上就是调用对象对应的关联函数,我们称之为对象的方法(Method)。面向对象的程序写出来就像这样:
bart = Student('Bart Simpson', 59)
lisa = Student('Lisa Simpson', 87)
bart.print_score()
lisa.print_score()数据封装、继承和多态是面向对象的三大特点
类和实例
在 Python 中,定义类是通过 class 关键字:
class Student(object):
passclass 后面紧接着是类名,即 Student,类名通常是大写开头的单词,紧接着是(object),表示该类是从哪个类继承下来的,继承的概念我们后面再讲,通常,如果没有合适的继承类,就使用 object 类,这是所有类最终都会继承的类。
定义好了 Student 类,就可以根据 Student 类创建出 Student 的实例,创建实例是通过 类名() 实现的:
>>> bart = Student()
>>> bart
<__main__.Student object at 0x10a67a590>
>>> Student
<class '__main__.Student'>可以看到,变量 bart 指向的就是一个 Student 的实例,后面的 0x10a67a590 是内存地址,每个 object 的地址都不一样,而 Student 本身则是一个类。
可以自由地给一个实例变量绑定属性,比如,给实例 bart 绑定一个 name 属性:
>>> bart.name = 'Bart Simpson'
>>> bart.name
'Bart Simpson'由于类可以起到模板的作用,因此,可以在创建实例的时候,把一些我们认为必须绑定的属性强制填写进去。通过定义一个特殊的 __init__ 方法,在创建实例的时候,就把 name,score 等属性绑上去:
class Student(object):
def __init__(self, name, score):
self.name = name
self.score = score注意:特殊方法
__init__前后分别有两个下划线!!!
注意到 __init__ 方法的第一个参数永远是 self,表示创建的实例本身,因此,在 __init__ 方法内部,就可以把各种属性绑定到 self,因为 self 就指向创建的实例本身。
有了 __init__ 方法,在创建实例的时候,就不能传入空的参数了,必须传入与 __init__ 方法匹配的参数,但 self 不需要传,Python 解释器自己会把实例变量传进去:
>>> bart = Student('Bart Simpson', 59)
>>> bart.name
'Bart Simpson'
>>> bart.score
59和普通的函数相比,在类中定义的函数只有一点不同,就是第一个参数永远是实例变量 self,并且,调用时,不用传递该参数。除此之外,类的方法和普通函数没有什么区别,所以,你仍然可以用默认参数、可变参数、关键字参数和命名关键字参数。
数据封装
面向对象编程的一个重要特点就是数据封装。在上面的 Student 类中,每个实例就拥有各自的 name 和 score 这些数据。我们可以通过函数来访问这些数据,比如打印一个学生的成绩:
>>> def print_score(std):
... print('%s: %s' % (std.name, std.score))
...
>>> print_score(bart)
Bart Simpson: 59但是,既然 Student 实例本身就拥有这些数据,要访问这些数据,就没有必要从外面的函数去访问,可以直接在 Student 类的内部定义访问数据的函数,这样,就把“数据”给封装起来了。这些封装数据的函数是和 Student 类本身是关联起来的,我们称之为类的方法:
class Student(object):
def __init__(self, name, score):
self.name = name
self.score = score
def print_score(self):
print('%s: %s' % (self.name, self.score))要定义一个方法,除了第一个参数是 self 外,其他和普通函数一样。要调用一个方法,只需要在实例变量上直接调用,除了 self 不用传递,其他参数正常传入:
>>> bart.print_score()
Bart Simpson: 59这样一来,我们从外部看 Student 类,就只需要知道,创建实例需要给出 name 和 score,而如何打印,都是在 Student 类的内部定义的,这些数据和逻辑被“封装”起来了,调用很容易,但却不用知道内部实现的细节。
封装的另一个好处是可以给 Student 类增加新的方法,比如 get_grade:
class Student(object):
...
def get_grade(self):
if self.score >= 90:
return 'A'
elif self.score >= 60:
return 'B'
else:
return 'C'同样的,get_grade 方法可以直接在实例变量上调用,不需要知道内部实现细节:
class Student(object):
def __init__(self, name, score):
self.name = name
self.score = score
def get_grade(self):
if self.score >= 90:
return 'A'
elif self.score >= 60:
return 'B'
else:
return 'C'
lisa = Student('Lisa', 99)
bart = Student('Bart', 59)
print(lisa.name, lisa.get_grade()) # Lisa A
print(bart.name, bart.get_grade()) # Bart C小结
类是创建实例的模板,而实例则是一个一个具体的对象,各个实例拥有的数据都互相独立,互不影响;
方法就是与实例绑定的函数,和普通函数不同,方法可以直接访问实例的数据;
通过在实例上调用方法,我们就直接操作了对象内部的数据,但无需知道方法内部的实现细节。
和静态语言不同,Python 允许对实例变量绑定任何数据,也就是说,对于两个实例变量,虽然它们都是同一个类的不同实例,但拥有的变量名称都可能不同:
>>> bart = Student('Bart Simpson', 59)
>>> lisa = Student('Lisa Simpson', 87)
>>> bart.age = 8
>>> bart.age
8
>>> lisa.age
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'Student' object has no attribute 'age'访问限制
在 Class 内部,可以有属性和方法,而外部代码可以通过直接调用实例变量的方法来操作数据,这样,就隐藏了内部的复杂逻辑。
但是,从前面 Student 类的定义来看,外部代码还是可以自由地修改一个实例的 name、score 属性:
>>> bart = Student('Bart Simpson', 59)
>>> bart.score
59
>>> bart.score = 99
>>> bart.score
99如果要让内部属性不被外部访问,可以把属性的名称前加上两个下划线 __,在 Python 中,实例的变量名如果以 __ 开头,就变成了一个私有变量(private),只有内部可以访问,外部不能访问,所以,我们把 Student 类改一改:
class Student(object):
def __init__(self, name, score):
self.__name = name
self.__score = score
def print_score(self):
print('%s: %s' % (self.__name, self.__score))改完后,对于外部代码来说,没什么变动,但是已经无法从外部访问 实例变量.__name 和 实例变量.__score 了:
>>> bart = Student('Bart Simpson', 59)
>>> bart.__name
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'Student' object has no attribute '__name'这样就确保了外部代码不能随意修改对象内部的状态,这样通过访问限制的保护,代码更加健壮。
但是如果外部代码要获取 name 和 score 怎么办?可以给 Student 类增加 get_name 和 get_score 这样的方法:
class Student(object):
...
def get_name(self):
return self.__name
def get_score(self):
return self.__score如果又要允许外部代码修改 score 怎么办?可以再给 Student 类增加 set_score 方法:
class Student(object):
...
def set_score(self, score):
self.__score = score你也许会问,原先那种直接通过 bart.score = 99 也可以修改啊,为什么要定义一个方法大费周折?因为在方法中,可以对参数做检查,避免传入无效的参数:
class Student(object):
...
def set_score(self, score):
if 0 <= score <= 100:
self.__score = score
else:
raise ValueError('bad score')需要注意的是,在 Python 中,变量名类似 __xxx__ 的,也就是以双下划线开头,并且以双下划线结尾的,是特殊变量,特殊变量是可以直接访问的,不是 private 变量,所以,不能用 __name__、 __score__ 这样的变量名。
有些时候,你会看到以一个下划线开头的实例变量名,比如 _name,这样的实例变量外部是可以访问的,但是,按照约定俗成的规定,当你看到这样的变量时,意思就是,“虽然我可以被访问,但是,请把我视为私有变量,不要随意访问”。
双下划线开头的实例变量是不是一定不能从外部访问呢?其实也不是。不能直接访问 __name 是因为 Python 解释器对外把 __name 变量改成了 _Student__name,所以,仍然可以通过 _Student__name 来访问 __name 变量:
>>> bart._Student__name
'Bart Simpson'但是强烈建议你不要这么干,因为不同版本的 Python 解释器可能会把 __name 改成不同的变量名。
总的来说就是,Python 本身没有任何机制阻止你干坏事,一切全靠自觉。
最后注意下面的这种错误写法:
>>> bart = Student('Bart Simpson', 59)
>>> bart.get_name()
'Bart Simpson'
>>> bart.__name = 'New Name' # 设置 __name 变量!
>>> bart.__name
'New Name'表面上看,外部代码“成功”地设置了 __name 变量,但实际上这个 __name 变量和 class 内部的 __name 变量不是一个变量!内部的 __name 变量已经被 Python 解释器自动改成了 _Student__name,而外部代码给 bart 新增了一个 __name 变量。不信试试:
>>> bart.get_name() # get_name() 内部返回 self.__name
'Bart Simpson'继承和多态
在 OOP 程序设计中,当我们定义一个 class 的时候,可以从某个现有的 class 继承,新的 class 称为子类(Subclass),而被继承的 class 称为基类、父类或超类(Base class、Super class)。
比如,我们已经编写了一个名为 Animal 的 class,有一个 run() 方法可以直接打印:
class Animal(object):
def run(self):
print('Animal is running...')当我们需要编写 Dog 和 Cat 类时,就可以直接从 Animal 类继承:
class Dog(Animal):
pass
class Cat(Animal):
pass对于 Dog 来说,Animal 就是它的父类,对于 Animal 来说,Dog 就是它的子类。Cat 和 Dog 类似。
继承有什么好处?最大的好处是子类获得了父类的全部功能。由于 Animial 实现了 run() 方法,因此,Dog 和 Cat 作为它的子类,什么事也没干,就自动拥有了 run() 方法:
dog = Dog()
dog.run()
cat = Cat()
cat.run()运行结果如下:
Animal is running...
Animal is running...当然,也可以对子类增加一些方法,比如 Dog 类:
class Dog(Animal):
def run(self):
print('Dog is running...')
def eat(self):
print('Eating meat...')继承的第二个好处需要我们对代码做一点改进。你看到了,无论是 Dog 还是 Cat,它们 run() 的时候,显示的都是 Animal is running…,符合逻辑的做法是分别显示 Dog is running… 和 Cat is running…,因此,对 Dog 和 Cat 类改进如下:
class Dog(Animal):
def run(self):
print('Dog is running...')
class Cat(Animal):
def run(self):
print('Cat is running...')再次运行,结果如下:
Dog is running...
Cat is running...当子类和父类都存在相同的 run() 方法时,我们说,子类的 run() 覆盖了父类的 run(),在代码运行的时候,总是会调用子类的 run()。这样,我们就获得了继承的另一个好处:多态。
要理解什么是多态,我们首先要对数据类型再作一点说明。当我们定义一个 class 的时候,我们实际上就定义了一种数据类型。我们定义的数据类型和 Python 自带的数据类型,比如 str、list、dict 没什么两样:
a = list() # a 是 list 类型
b = Animal() # b 是 Animal 类型
c = Dog() # c 是 Dog 类型判断一个变量是否是某个类型可以用 isinstance() 判断:
>>> isinstance(a, list)
True
>>> isinstance(b, Animal)
True
>>> isinstance(c, Dog)
True看来 a、b、c 确实对应着 list、Animal、Dog 这 3 种类型。
但是等等,试试:
>>> isinstance(c, Animal)
True看来 c 不仅仅是 Dog,c 还是 Animal!
不过仔细想想,这是有道理的,因为 Dog 是从 Animal 继承下来的,当我们创建了一个 Dog 的实例 c 时,我们认为 c 的数据类型是 Dog 没错,但 c 同时也是 Animal 也没错,Dog 本来就是 Animal 的一种!
所以,在继承关系中,如果一个实例的数据类型是某个子类,那它的数据类型也可以被看做是父类。但是,反过来就不行:
>>> b = Animal()
>>> isinstance(b, Dog)
FalseDog 可以看成 Animal,但 Animal 不可以看成 Dog。
要理解多态的好处,我们还需要再编写一个函数,这个函数接受一个 Animal 类型的变量:
def run_twice(animal):
animal.run()
animal.run()当我们传入 Animal 的实例时,run_twice() 就打印出:
>>> run_twice(Animal())
Animal is running...
Animal is running...当我们传入 Dog 的实例时,run_twice() 就打印出:
>>> run_twice(Dog())
Dog is running...
Dog is running...当我们传入 Cat 的实例时,run_twice() 就打印出:
>>> run_twice(Cat())
Cat is running...
Cat is running...看上去没啥意思,但是仔细想想,现在,如果我们再定义一个 Tortoise 类型,也从 Animal 派生:
class Tortoise(Animal):
def run(self):
print('Tortoise is running slowly...')当我们调用 run_twice() 时,传入 Tortoise 的实例:
>>> run_twice(Tortoise())
Tortoise is running slowly...
Tortoise is running slowly...你会发现,新增一个 Animal 的子类,不必对 run_twice() 做任何修改,实际上,任何依赖 Animal 作为参数的函数或者方法都可以不加修改地正常运行,原因就在于多态。
多态的好处就是,当我们需要传入 Dog、Cat、Tortoise…… 时,我们只需要接收 Animal 类型就可以了,因为 Dog、Cat、Tortoise…… 都是 Animal 类型,然后,按照 Animal 类型进行操作即可。由于 Animal 类型有 run() 方法,因此,传入的任意类型,只要是 Animal 类或者子类,就会自动调用实际类型的 run() 方法,这就是多态的意思:
对于一个变量,我们只需要知道它是 Animal 类型,无需确切地知道它的子类型,就可以放心地调用 run() 方法,而具体调用的 run() 方法是作用在 Animal、Dog、Cat 还是 Tortoise 对象上,由运行时该对象的确切类型决定,这就是多态真正的威力:调用方只管调用,不管细节,而当我们新增一种 Animal 的子类时,只要确保 run() 方法编写正确,不用管原来的代码是如何调用的。这就是著名的“开闭”原则:
- 对扩展开放:允许新增 Animal 子类;
- 对修改封闭:不需要修改依赖 Animal 类型的 run_twice() 等函数。
继承还可以一级一级地继承下来,就好比从爷爷到爸爸、再到儿子这样的关系。而任何类,最终都可以追溯到根类 object,这些继承关系看上去就像一颗倒着的树。
静态语言 vs 动态语言
对于静态语言(例如 Java)来说,如果需要传入 Animal 类型,则传入的对象必须是 Animal 类型或者它的子类,否则,将无法调用 run() 方法。
对于 Python 这样的动态语言来说,则不一定需要传入 Animal 类型。我们只需要保证传入的对象有一个 run() 方法就可以了:
class Timer(object):
def run(self):
print('Start...')这就是动态语言的“鸭子类型”,它并不要求严格的继承体系,一个对象只要“看起来像鸭子,走起路来像鸭子”,那它就可以被看做是鸭子。
Python 的 file-like object 就是一种鸭子类型。对真正的文件对象,它有一个 read() 方法,返回其内容。但是,许多对象,只要有 read() 方法,都被视为“file-like object“。许多函数接收的参数就是 file-like object,你不一定要传入真正的文件对象,完全可以传入任何实现了 read() 方法的对象。
小结
继承可以把父类的所有功能都直接拿过来,这样就不必重零做起,子类只需要新增自己特有的方法,也可以把父类不适合的方法覆盖重写。
动态语言的鸭子类型特点决定了继承不像静态语言那样是必须的。
获取对象信息
使用 type()
首先,我们来判断对象类型,使用 type() 函数:
基本类型都可以用 type() 判断:
>>> type(123)
<class 'int'>
>>> type('str')
<class 'str'>
>>> type(None)
<type(None) 'NoneType'>如果一个变量指向函数或者类,也可以用 type() 判断:
>>> type(abs)
<class 'builtin_function_or_method'>
>>> type(a)
<class '__main__.Animal'>但是 type() 函数返回的是什么类型呢?它返回对应的 Class 类型。如果我们要在 if 语句中判断,就需要比较两个变量的 type 类型是否相同:
>>> type(123)==type(456)
True
>>> type(123)==int
True
>>> type('abc')==type('123')
True
>>> type('abc')==str
True
>>> type('abc')==type(123)
False判断基本数据类型可以直接写 int,str 等,但如果要判断一个对象是否是函数怎么办?可以使用 types 模块中定义的常量:
>>> import types
>>> def fn():
... pass
...
>>> type(fn)==types.FunctionType
True
>>> type(abs)==types.BuiltinFunctionType
True
>>> type(lambda x: x)==types.LambdaType
True
>>> type((x for x in range(10)))==types.GeneratorType
True使用 isinstance()
对于 class 的继承关系来说,使用 type() 就很不方便。我们要判断 class 的类型,可以使用 isinstance() 函数。
我们回顾上次的例子,如果继承关系是:
object -> Animal -> Dog -> Husky那么,isinstance() 就可以告诉我们,一个对象是否是某种类型。先创建 3 种类型的对象:
>>> a = Animal()
>>> d = Dog()
>>> h = Husky()然后,判断:
>>> isinstance(h, Husky)
True没有问题,因为 h 变量指向的就是 Husky 对象。
再判断:
>>> isinstance(h, Dog)
Trueh 虽然自身是 Husky 类型,但由于 Husky 是从 Dog 继承下来的,所以,h 也还是 Dog 类型。换句话说,isinstance() 判断的是一个对象是否是该类型本身,或者位于该类型的父继承链上。
因此,我们可以确信,h 还是 Animal 类型:
>>> isinstance(h, Animal)
True同理,实际类型是 Dog 的 d 也是 Animal 类型:
>>> isinstance(d, Dog) and isinstance(d, Animal)
True但是,d 不是 Husky 类型:
>>> isinstance(d, Husky)
False能用 type() 判断的基本类型也可以用 isinstance() 判断:
>>> isinstance('a', str)
True
>>> isinstance(123, int)
True
>>> isinstance(b'a', bytes)
True并且还可以判断一个变量是否是某些类型中的一种,比如下面的代码就可以判断是否是 list 或者 tuple:
>>> isinstance([1, 2, 3], (list, tuple))
True
>>> isinstance((1, 2, 3), (list, tuple))
True总是优先使用 isinstance() 判断类型,可以将指定类型及其子类“一网打尽”。
使用 dir()
如果要获得一个对象的所有属性和方法,可以使用 dir() 函数,它返回一个包含字符串的 list,比如,获得一个 str 对象的所有属性和方法:
>>> dir('ABC')
['__add__', '__class__',..., '__subclasshook__', 'capitalize', 'casefold',..., 'zfill']类似 __xxx__ 的属性和方法在 Python 中都是有特殊用途的,比如 __len__ 方法返回长度。在 Python 中,如果你调用 len() 函数试图获取一个对象的长度,实际上,在 len() 函数内部,它自动去调用该对象的 __len__() 方法,所以,下面的代码是等价的:
>>> len('ABC')
3
>>> 'ABC'.__len__()
3我们自己写的类,如果也想用 len(myObj) 的话,就自己写一个 __len__() 方法:
>>> class MyDog(object):
... def __len__(self):
... return 100
...
>>> dog = MyDog()
>>> len(dog)
100剩下的都是普通属性或方法,比如 lower() 返回小写的字符串:
>>> 'ABC'.lower()
'abc'仅仅把属性和方法列出来是不够的,配合 getattr()、setattr() 以及 hasattr(),我们可以直接操作一个对象的状态:
>>> class MyObject(object):
... def __init__(self):
... self.x = 9
... def power(self):
... return self.x * self.x
...
>>> obj = MyObject()紧接着,可以测试该对象的属性:
>>> hasattr(obj, 'x') # 有属性 'x' 吗?
True
>>> obj.x
9
>>> hasattr(obj, 'y') # 有属性 'y' 吗?
False
>>> setattr(obj, 'y', 19) # 设置一个属性 'y'
>>> hasattr(obj, 'y') # 有属性 'y' 吗?
True
>>> getattr(obj, 'y') # 获取属性 'y'
19
>>> obj.y # 获取属性 'y'
19如果试图获取不存在的属性,会抛出 AttributeError 的错误:
>>> getattr(obj, 'z') # 获取属性 'z'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'MyObject' object has no attribute 'z'可以传入一个 default 参数,如果属性不存在,就返回默认值:
>>> getattr(obj, 'z', 404) # 获取属性 'z',如果不存在,返回默认值 404
404也可以获得对象的方法:
>>> hasattr(obj, 'power') # 有属性 'power' 吗?
True
>>> getattr(obj, 'power') # 获取属性 'power'
<bound method MyObject.power of <__main__.MyObject object at 0x10077a6a0>>
>>> fn = getattr(obj, 'power') # 获取属性 'power' 并赋值到变量 fn
>>> fn # fn 指向 obj.power
<bound method MyObject.power of <__main__.MyObject object at 0x10077a6a0>>
>>> fn() # 调用 fn() 与调用 obj.power() 是一样的
81小结
通过内置的一系列函数,我们可以对任意一个 Python 对象进行剖析,拿到其内部的数据。要注意的是,只有在不知道对象信息的时候,我们才会去获取对象信息。如果可以直接写:
sum = obj.x + obj.y就不要写:
sum = getattr(obj, 'x') + getattr(obj, 'y')一个正确的用法的例子如下:
def readImage(fp):
if hasattr(fp, 'read'):
return readData(fp)
return None假设我们希望从文件流 fp 中读取图像,我们首先要判断该 fp 对象是否存在 read 方法,如果存在,则该对象是一个流,如果不存在,则无法读取。hasattr() 就派上了用场。
请注意,在 Python 这类动态语言中,根据鸭子类型,有 read() 方法,不代表该 fp 对象就是一个文件流,它也可能是网络流,也可能是内存中的一个字节流,但只要 read() 方法返回的是有效的图像数据,就不影响读取图像的功能。
实例属性和类属性
由于 Python 是动态语言,根据类创建的实例可以任意绑定属性。
给实例绑定属性的方法是通过实例变量,或者通过 self 变量:
class Student(object):
def __init__(self, name):
self.name = name
s = Student('Bob')
s.score = 90但是,如果 Student 类本身需要绑定一个属性呢?可以直接在 class 中定义属性,这种属性是类属性,归 Student 类所有:
class Student(object):
name = 'Student'当我们定义了一个类属性后,这个属性虽然归类所有,但类的所有实例都可以访问到。来测试一下:
>>> class Student(object):
... name = 'Student'
...
>>> s = Student() # 创建实例 s
>>> print(s.name) # 打印 name 属性,因为实例并没有 name 属性,所以会继续查找 class 的 name 属性
Student
>>> print(Student.name) # 打印类的 name 属性
Student
>>> s.name = 'Michael' # 给实例绑定 name 属性
>>> print(s.name) # 由于实例属性优先级比类属性高,因此,它会屏蔽掉类的 name 属性
Michael
>>> print(Student.name) # 但是类属性并未消失,用 Student.name 仍然可以访问
Student
>>> del s.name # 如果删除实例的 name 属性
>>> print(s.name) # 再次调用 s.name,由于实例的 name 属性没有找到,类的 name 属性就显示出来了
Student从上面的例子可以看出,在编写程序的时候,千万不要对实例属性和类属性使用相同的名字,因为相同名称的实例属性将屏蔽掉类属性,但是当你删除实例属性后,再使用相同的名称,访问到的将是类属性。
小结
实例属性属于各个实例所有,互不干扰;
类属性属于类所有,所有实例共享一个属性;
不要对实例属性和类属性使用相同的名字,否则将产生难以发现的错误。
面向对象高级编程
使用 __slots__
正常情况下,当我们定义了一个 class,创建了一个 class 的实例后,我们可以给该实例绑定任何属性和方法,这就是动态语言的灵活性。先定义 class:
class Student(object):
pass然后,尝试给实例绑定一个属性:
>>> s = Student()
>>> s.name = 'Michael' # 动态给实例绑定一个属性
>>> print(s.name)
Michael还可以尝试给实例绑定一个方法:
>>> def set_age(self, age): # 定义一个函数作为实例方法
... self.age = age
...
>>> from types import MethodType
>>> s.set_age = MethodType(set_age, s) # 给实例绑定一个方法, 第二个参数作为 self 传入方法
>>> s.set_age(25) # 调用实例方法
>>> s.age # 测试结果
25但是,给一个实例绑定的方法,对另一个实例是不起作用的:
>>> s2 = Student() # 创建新的实例
>>> s2.set_age(25) # 尝试调用方法
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'Student' object has no attribute 'set_age'为了给所有实例都绑定方法,可以给 class 绑定方法:
>>> def set_score(self, score):
... self.score = score
...
>>> Student.set_score = set_score给 class 绑定方法后,所有实例均可调用:
>>> s.set_score(100)
>>> s.score
100
>>> s2.set_score(99)
>>> s2.score
99通常情况下,上面的 set_score 方法可以直接定义在 class 中,但动态绑定允许我们在程序运行的过程中动态给 class 加上功能,这在静态语言中很难实现。
使用 __slots__
但是,如果我们想要限制实例的属性怎么办?比如,只允许对 Student 实例添加 name 和 age 属性。
为了达到限制的目的,Python 允许在定义 class 的时候,定义一个特殊的 __slots__ 变量,来限制该 class 实例能添加的属性:
class Student(object):
__slots__ = ('name', 'age') # 用 tuple 定义允许绑定的属性名称然后,我们试试:
>>> s = Student() # 创建新的实例
>>> s.name = 'Michael' # 绑定属性 'name'
>>> s.age = 25 # 绑定属性 'age'
>>> s.score = 99 # 绑定属性 'score'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'Student' object has no attribute 'score'由于 score 没有被放到 __slots__ 中,所以不能绑定 score 属性,试图绑定 score 将得到 AttributeError 的错误。
使用 __slots__ 要注意,__slots__ 定义的属性仅对当前类实例起作用,对继承的子类是不起作用的:
>>> class GraduateStudent(Student):
... pass
...
>>> g = GraduateStudent()
>>> g.score = 9999除非在子类中也定义 __slots__,这样,子类实例允许定义的属性就是自身的 __slots__ 加上父类的 __slots__。
使用 @property
在绑定属性时,如果我们直接把属性暴露出去,虽然写起来很简单,但是,没办法检查参数,导致可以把成绩随便改:
s = Student()
s.score = 9999这显然不合逻辑。为了限制 score 的范围,可以通过一个 set_score() 方法来设置成绩,再通过一个 get_score() 来获取成绩,这样,在 set_score() 方法里,就可以检查参数:
class Student(object):
def get_score(self):
return self._score
def set_score(self, value):
if not isinstance(value, int):
raise ValueError('score must be an integer!')
if value < 0 or value > 100:
raise ValueError('score must between 0 ~ 100!')
self._score = value现在,对任意的 Student 实例进行操作,就不能随心所欲地设置 score 了:
>>> s = Student()
>>> s.set_score(60) # ok!
>>> s.get_score()
60
>>> s.set_score(9999)
Traceback (most recent call last):
...
ValueError: score must between 0 ~ 100!但是,上面的调用方法又略显复杂,没有直接用属性这么直接简单。
有没有既能检查参数,又可以用类似属性这样简单的方式来访问类的变量呢?对于追求完美的 Python 程序员来说,这是必须要做到的!
还记得装饰器(decorator)可以给函数动态加上功能吗?对于类的方法,装饰器一样起作用。Python 内置的 @property 装饰器就是负责把一个方法变成属性调用的:
class Student(object):
@property
def score(self):
return self._score
@score.setter
def score(self, value):
if not isinstance(value, int):
raise ValueError('score must be an integer!')
if value < 0 or value > 100:
raise ValueError('score must between 0 ~ 100!')
self._score = value@property 的实现比较复杂,我们先考察如何使用。把一个 getter 方法变成属性,只需要加上 @property 就可以了,此时,@property 本身又创建了另一个装饰器 @score.setter,负责把一个 setter 方法变成属性赋值,于是,我们就拥有一个可控的属性操作:
>>> s = Student()
>>> s.score = 60 # OK,实际转化为 s.set_score(60)
>>> s.score # OK,实际转化为 s.get_score()
60
>>> s.score = 9999
Traceback (most recent call last):
...
ValueError: score must between 0 ~ 100!注意到这个神奇的 @property,我们在对实例属性操作的时候,就知道该属性很可能不是直接暴露的,而是通过 getter 和 setter 方法来实现的。
还可以定义只读属性,只定义 getter 方法,不定义 setter 方法就是一个只读属性:
class Student(object):
@property
def birth(self):
return self._birth
@birth.setter
def birth(self, value):
self._birth = value
@property
def age(self):
return 2015 - self._birth上面的 birth 是可读写属性,而 age 就是一个只读属性,因为 age 可以根据 birth 和当前时间计算出来。
要特别注意:属性的方法名不要和实例变量重名。例如,以下的代码是错误的:
class Student(object):
# 方法名称和实例变量均为 birth:
@property
def birth(self):
return self.birth这是因为调用 s.birth 时,首先转换为方法调用,在执行 return self.birth 时,又视为访问 self 的属性,于是又转换为方法调用,造成无限递归,最终导致栈溢出报错 RecursionError。
小结
@property 广泛应用在类的定义中,可以让调用者写出简短的代码,同时保证对参数进行必要的检查,这样,程序运行时就减少了出错的可能性。
多重继承
class Animal(object):
pass
# 大类:
class Mammal(Animal):
pass
class Bird(Animal):
pass
# 各种动物:
class Dog(Mammal):
pass
class Bat(Mammal):
pass
class Parrot(Bird):
pass
class Ostrich(Bird):
pass现在,我们要给动物再加上 Runnable 和 Flyable 的功能,只需要先定义好 Runnable 和 Flyable 的类:
class Runnable(object):
def run(self):
print('Running...')
class Flyable(object):
def fly(self):
print('Flying...')对于需要 Runnable 功能的动物,就多继承一个 Runnable,例如 Dog:
class Dog(Mammal, Runnable):
pass对于需要 Flyable 功能的动物,就多继承一个 Flyable,例如 Bat:
class Bat(Mammal, Flyable):
pass通过多重继承,一个子类就可以同时获得多个父类的所有功能。
MixIn
在设计类的继承关系时,通常,主线都是单一继承下来的,例如,Ostrich 继承自 Bird。但是,如果需要“混入”额外的功能,通过多重继承就可以实现,比如,让 Ostrich 除了继承自 Bird 外,再同时继承 Runnable。这种设计通常称之为 MixIn。
为了更好地看出继承关系,我们把 Runnable 和 Flyable 改为 RunnableMixIn 和 FlyableMixIn。类似的,你还可以定义出肉食动物 CarnivorousMixIn 和植食动物 HerbivoresMixIn,让某个动物同时拥有好几个 MixIn:
class Dog(Mammal, RunnableMixIn, CarnivorousMixIn):
passMixIn 的目的就是给一个类增加多个功能,这样,在设计类的时候,我们优先考虑通过多重继承来组合多个 MixIn 的功能,而不是设计多层次的复杂的继承关系。
Python 自带的很多库也使用了 MixIn。举个例子,Python 自带了 TCPServer 和 UDPServer 这两类网络服务,而要同时服务多个用户就必须使用多进程或多线程模型,这两种模型由 ForkingMixIn 和 ThreadingMixIn 提供。通过组合,我们就可以创造出合适的服务来。
比如,编写一个多进程模式的 TCP 服务,定义如下:
class MyTCPServer(TCPServer, ForkingMixIn):
pass编写一个多线程模式的 UDP 服务,定义如下:
class MyUDPServer(UDPServer, ThreadingMixIn):
pass如果你打算搞一个更先进的协程模型,可以编写一个 CoroutineMixIn:
class MyTCPServer(TCPServer, CoroutineMixIn):
pass这样一来,我们不需要复杂而庞大的继承链,只要选择组合不同的类的功能,就可以快速构造出所需的子类。
小结
由于 Python 允许使用多重继承,因此,MixIn 就是一种常见的设计。
只允许单一继承的语言(如 Java)不能使用 MixIn 的设计。
定制类
看到类似 __slots__ 这种形如 __xxx__ 的变量或者函数名就要注意,这些在 Python 中是有特殊用途的。
__slots__ 我们已经知道怎么用了,__len__() 方法我们也知道是为了能让 class 作用于 len() 函数。
除此之外,Python 的 class 中还有许多这样有特殊用途的函数,可以帮助我们定制类。
__str__
我们先定义一个 Student 类,打印一个实例:
>>> class Student(object):
... def __init__(self, name):
... self.name = name
...
>>> print(Student('Michael'))
<__main__.Student object at 0x109afb190>打印出一堆 <__main__.Student object at 0x109afb190>,不好看。
怎么才能打印得好看呢?只需要定义好 __str__() 方法,返回一个好看的字符串就可以了:
>>> class Student(object):
... def __init__(self, name):
... self.name = name
... def __str__(self):
... return 'Student object (name: %s)' % self.name
...
>>> print(Student('Michael'))
Student object (name: Michael)这样打印出来的实例,不但好看,而且容易看出实例内部重要的数据。
但是细心的朋友会发现直接敲变量不用 print,打印出来的实例还是不好看:
>>> s = Student('Michael')
>>> s
<__main__.Student object at 0x109afb310>这是因为直接显示变量调用的不是 __str__(),而是 __repr__(),两者的区别是 __str__() 返回用户看到的字符串,而 __repr__() 返回程序开发者看到的字符串,也就是说,__repr__() 是为调试服务的。
解决办法是再定义一个 __repr__()。但是通常 __str__() 和 __repr__() 代码都是一样的,所以,有个偷懒的写法:
class Student(object):
def __init__(self, name):
self.name = name
def __str__(self):
return 'Student object (name=%s)' % self.name
__repr__ = __str____iter__
如果一个类想被用于 for … in 循环,类似 list 或 tuple 那样,就必须实现一个 __iter__() 方法,该方法返回一个迭代对象,然后,Python 的 for 循环就会不断调用该迭代对象的 __next__() 方法拿到循环的下一个值,直到遇到 StopIteration 错误时退出循环。
我们以斐波那契数列为例,写一个 Fib 类,可以作用于 for 循环:
class Fib(object):
def __init__(self):
self.a, self.b = 0, 1 # 初始化两个计数器 a,b
def __iter__(self):
return self # 实例本身就是迭代对象,故返回自己
def __next__(self):
self.a, self.b = self.b, self.a + self.b # 计算下一个值
if self.a > 100000: # 退出循环的条件
raise StopIteration()
return self.a # 返回下一个值现在,试试把 Fib 实例作用于 for 循环:
>>> for n in Fib():
... print(n)
...
1
1
2
3
5
...
46368
75025__getitem__
Fib 实例虽然能作用于 for 循环,看起来和 list 有点像,但是,把它当成 list 来使用还是不行,比如,取第 5 个元素:
>>> Fib()[5]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'Fib' object does not support indexing要表现得像 list 那样按照下标取出元素,需要实现 __getitem__() 方法:
class Fib(object):
def __getitem__(self, n):
a, b = 1, 1
for x in range(n):
a, b = b, a + b
return a现在,就可以按下标访问数列的任意一项了:
>>> f = Fib()
>>> f[0]
1
>>> f[1]
1
>>> f[2]
2
>>> f[3]
3
>>> f[10]
89
>>> f[100]
573147844013817084101但是 list 有个神奇的切片方法:
>>> list(range(100))[5:10]
[5, 6, 7, 8, 9]对于 Fib 却报错。原因是 __getitem__() 传入的参数可能是一个 int,也可能是一个切片对象 slice,所以要做判断:
class Fib(object):
def __getitem__(self, n):
if isinstance(n, int): # n 是索引
a, b = 1, 1
for x in range(n):
a, b = b, a + b
return a
if isinstance(n, slice): # n 是切片
start = n.start
stop = n.stop
if start is None:
start = 0
a, b = 1, 1
L = []
for x in range(stop):
if x >= start:
L.append(a)
a, b = b, a + b
return L现在试试 Fib 的切片:
>>> f = Fib()
>>> f[0:5]
[1, 1, 2, 3, 5]
>>> f[:10]
[1, 1, 2, 3, 5, 8, 13, 21, 34, 55]但是没有对 step 参数作处理:
>>> f[:10:2]
[1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89]也没有对负数作处理,所以,要正确实现一个 __getitem__() 还是有很多工作要做的。
此外,如果把对象看成 dict,__getitem__() 的参数也可能是一个可以作 key 的 object,例如 str。
与之对应的是 __setitem__() 方法,把对象视作 list 或 dict 来对集合赋值。最后,还有一个 __delitem__() 方法,用于删除某个元素。
总之,通过上面的方法,我们自己定义的类表现得和 Python 自带的 list、tuple、dict 没什么区别,这完全归功于动态语言的“鸭子类型”,不需要强制继承某个接口。
__getattr__
正常情况下,当我们调用类的方法或属性时,如果不存在,就会报错。比如定义 Student 类:
class Student(object):
def __init__(self):
self.name = 'Michael'调用 name 属性,没问题,但是,调用不存在的 score 属性,就有问题了:
>>> s = Student()
>>> print(s.name)
Michael
>>> print(s.score)
Traceback (most recent call last):
...
AttributeError: 'Student' object has no attribute 'score'错误信息很清楚地告诉我们,没有找到 score 这个 attribute。
要避免这个错误,除了可以加上一个 score 属性外,Python 还有另一个机制,那就是写一个 __getattr__() 方法,动态返回一个属性。修改如下:
class Student(object):
def __init__(self):
self.name = 'Michael'
def __getattr__(self, attr):
if attr=='score':
return 99当调用不存在的属性时,比如 score,Python 解释器会试图调用 __getattr__(self, 'score') 来尝试获得属性,这样,我们就有机会返回 score 的值:
class Student(object):
def __init__(self):
self.name = 'Michael'
def __getattr__(self, attr):
if attr=='score':
return 99当调用不存在的属性时,比如 score,Python 解释器会试图调用 __getattr__(self, 'score') 来尝试获得属性,这样,我们就有机会返回 score 的值:
>>> s = Student()
>>> s.name
'Michael'
>>> s.score
99返回函数也是完全可以的:
class Student(object):
def __getattr__(self, attr):
if attr=='age':
return lambda: 25只是调用方式要变为:
>>> s.age()
25注意,只有在没有找到属性的情况下,才调用 __getattr__,已有的属性,比如 name,不会在 __getattr__ 中查找。
此外,注意到任意调用如 s.abc 都会返回 None,这是因为我们定义的 __getattr__ 默认返回就是 None。要让 class 只响应特定的几个属性,我们就要按照约定,抛出 AttributeError 的错误:
class Student(object):
def __getattr__(self, attr):
if attr=='age':
return lambda: 25
raise AttributeError('\'Student\' object has no attribute \'%s\'' % attr)这实际上可以把一个类的所有属性和方法调用全部动态化处理了,不需要任何特殊手段。
这种完全动态调用的特性有什么实际作用呢?作用就是,可以针对完全动态的情况作调用。
举个例子:
现在很多网站都搞 REST API,比如新浪微博、豆瓣啥的,调用 API 的 URL 类似:
http://api.server/user/friendshttp://api.server/user/timeline/list
如果要写 SDK,给每个 URL 对应的 API 都写一个方法,那得累死,而且,API 一旦改动,SDK 也要改。
利用完全动态的 __getattr__,我们可以写出一个链式调用:
class Chain(object):
def __init__(self, path=''):
self._path = path
def __getattr__(self, path):
return Chain('%s/%s' % (self._path, path))
def __str__(self):
return self._path
__repr__ = __str__试试:
>>> Chain().status.user.timeline.list
'/status/user/timeline/list'这样,无论 API 怎么变,SDK 都可以根据 URL 实现完全动态的调用,而且,不随 API 的增加而改变!
还有些 REST API 会把参数放到 URL 中,比如 GitHub 的 API:
GET /users/:user/repos调用时,需要把 :user 替换为实际用户名。如果我们能写出这样的链式调用:
Chain().users('michael').repos就可以非常方便地调用 API 了。
class Chain(object):
def __init__(self, path=''):
self.__path = path
def __getattr__(self, path):
return Chain('%s/%s' % (self.__path, path))
def __call__(self, path):
return Chain('%s/%s' % (self.__path, path))
def __str__(self):
return self.__path
__repr__ = __str__
print(Chain().users('michael').repos) # /users/michael/repos__call__
一个对象实例可以有自己的属性和方法,当我们调用实例方法时,我们用 instance.method() 来调用。能不能直接在实例本身上调用呢?在 Python 中,答案是肯定的。
任何类,只需要定义一个 __call__() 方法,就可以直接对实例进行调用。请看示例:
class Student(object):
def __init__(self, name):
self.name = name
def __call__(self):
print('My name is %s.' % self.name)调用方式如下:
>>> s = Student('Michael')
>>> s() # self 参数不要传入
My name is Michael.__call__() 还可以定义参数。对实例进行直接调用就好比对一个函数进行调用一样,所以你完全可以把对象看成函数,把函数看成对象,因为这两者之间本来就没啥根本的区别。
如果你把对象看成函数,那么函数本身其实也可以在运行期动态创建出来,因为类的实例都是运行期创建出来的,这么一来,我们就模糊了对象和函数的界限。
那么,怎么判断一个变量是对象还是函数呢?其实,更多的时候,我们需要判断一个对象是否能被调用,能被调用的对象就是一个 Callable 对象,比如函数和我们上面定义的带有 __call__() 的类实例:
>>> callable(Student())
True
>>> callable(max)
True
>>> callable([1, 2, 3])
False
>>> callable(None)
False
>>> callable('str')
False通过 callable() 函数,我们就可以判断一个对象是否是“可调用”对象。
小结
Python 的 class 允许定义许多定制方法,可以让我们非常方便地生成特定的类。
使用元类
type()
动态语言和静态语言最大的不同,就是函数和类的定义,不是编译时定义的,而是运行时动态创建的。
比方说我们要定义一个 Hello 的 class,就写一个 hello.py 模块:
class Hello(object):
def hello(self, name='world'):
print('Hello, %s.' % name)当 Python 解释器载入 hello 模块时,就会依次执行该模块的所有语句,执行结果就是动态创建出一个 Hello 的 class 对象,测试如下:
>>> from hello import Hello
>>> h = Hello()
>>> h.hello()
Hello, world.
>>> print(type(Hello))
<class 'type'>
>>> print(type(h))
<class 'hello.Hello'>type() 函数可以查看一个类型或变量的类型,Hello 是一个 class,它的类型就是 type,而 h 是一个实例,它的类型就是 class Hello。
我们说 class 的定义是运行时动态创建的,而创建 class 的方法就是使用 type() 函数。
type() 函数既可以返回一个对象的类型,又可以创建出新的类型,比如,我们可以通过 type() 函数创建出 Hello 类,而无需通过 class Hello(object)… 的定义:
>>> def fn(self, name='world'): # 先定义函数
... print('Hello, %s.' % name)
...
>>> Hello = type('Hello', (object,), dict(hello=fn)) # 创建 Hello class
>>> h = Hello()
>>> h.hello()
Hello, world.
>>> print(type(Hello))
<class 'type'>
>>> print(type(h))
<class '__main__.Hello'>要创建一个 class 对象,type() 函数依次传入 3 个参数:
- class 的名称;
- 继承的父类集合,注意 Python 支持多重继承,如果只有一个父类,别忘了 tuple 的单元素写法;
- class 的方法名称与函数绑定,这里我们把函数 fn 绑定到方法名 hello 上。
通过 type() 函数创建的类和直接写 class 是完全一样的,因为 Python 解释器遇到 class 定义时,仅仅是扫描一下 class 定义的语法,然后调用 type() 函数创建出 class。
正常情况下,我们都用 class Xxx… 来定义类,但是,type() 函数也允许我们动态创建出类来,也就是说,动态语言本身支持运行期动态创建类,这和静态语言有非常大的不同,要在静态语言运行期创建类,必须构造源代码字符串再调用编译器,或者借助一些工具生成字节码实现,本质上都是动态编译,会非常复杂。
metaclass
除了使用 type() 动态创建类以外,要控制类的创建行为,还可以使用 metaclass。
metaclass,直译为元类,简单的解释就是:
当我们定义了类以后,就可以根据这个类创建出实例,所以先定义类,然后创建实例。
但是如果我们想创建出类呢?那就必须根据 metaclass 创建出类,所以先定义 metaclass,然后创建类。
连接起来就是:先定义 metaclass,就可以创建类,最后创建实例。
所以,metaclass 允许你创建类或者修改类。换句话说,你可以把类看成是 metaclass 创建出来的“实例”。
metaclass 是 Python 面向对象里最难理解,也是最难使用的魔术代码。正常情况下,你不会碰到需要使用 metaclass 的情况,所以,以下内容看不懂也没关系,因为基本上你不会用到。
我们先看一个简单的例子,这个 metaclass 可以给我们自定义的 MyList 增加一个 add 方法:
定义 ListMetaclass,按照默认习惯,metaclass 的类名总是以 Metaclass 结尾,以便清楚地表示这是一个 metaclass:
# metaclass 是类的模板,所以必须从 `type` 类型派生:
class ListMetaclass(type):
def __new__(cls, name, bases, attrs):
attrs['add'] = lambda self, value: self.append(value)
return type.__new__(cls, name, bases, attrs)有了 ListMetaclass,我们在定义类的时候还要指示使用 ListMetaclass 来定制类,传入关键字参数 metaclass:
class MyList(list, metaclass=ListMetaclass):
pass当我们传入关键字参数 metaclass 时,魔术就生效了,它指示 Python 解释器在创建 MyList 时,要通过 ListMetaclass.__new__() 来创建,在此,我们可以修改类的定义,比如,加上新的方法,然后,返回修改后的定义。
__new__() 方法接收到的参数依次是:
- 当前准备创建的类的对象;
- 类的名字;
- 类继承的父类集合;
- 类的方法集合。
测试一下 MyList 是否可以调用 add() 方法:
>>> L = MyList()
>>> L.add(1)
>> L
[1]而普通的 list 没有 add() 方法:
>>> L2 = list()
>>> L2.add(1)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'list' object has no attribute 'add'动态修改有什么意义?直接在 MyList 定义中写上 add() 方法不是更简单吗?正常情况下,确实应该直接写,通过 metaclass 修改纯属变态。
但是,总会遇到需要通过 metaclass 修改类定义的。ORM 就是一个典型的例子。
ORM 全称 “Object Relational Mapping”,即对象-关系映射,就是把关系数据库的一行映射为一个对象,也就是一个类对应一个表,这样,写代码更简单,不用直接操作 SQL 语句。
要编写一个 ORM 框架,所有的类都只能动态定义,因为只有使用者才能根据表的结构定义出对应的类来。
让我们来尝试编写一个 ORM 框架。
编写底层模块的第一步,就是先把调用接口写出来。比如,使用者如果使用这个 ORM 框架,想定义一个 User 类来操作对应的数据库表 User,我们期待他写出这样的代码:
class User(Model):
# 定义类的属性到列的映射:
id = IntegerField('id')
name = StringField('username')
email = StringField('email')
password = StringField('password')
# 创建一个实例:
u = User(id=12345, name='Michael', email='test@orm.org', password='my-pwd')
# 保存到数据库:
u.save()其中,父类 Model 和属性类型 StringField、IntegerField 是由 ORM 框架提供的,剩下的魔术方法比如 save() 全部由父类 Model 自动完成。虽然 metaclass 的编写会比较复杂,但 ORM 的使用者用起来却异常简单。
现在,我们就按上面的接口来实现该 ORM。
首先来定义 Field 类,它负责保存数据库表的字段名和字段类型:
class Field(object):
def __init__(self, name, column_type):
self.name = name
self.column_type = column_type
def __str__(self):
return '<%s:%s>' % (self.__class__.__name__, self.name)在 Field 的基础上,进一步定义各种类型的 Field,比如 StringField,IntegerField 等等:
class StringField(Field):
def __init__(self, name):
super(StringField, self).__init__(name, 'varchar(100)')
class IntegerField(Field):
def __init__(self, name):
super(IntegerField, self).__init__(name, 'bigint')下一步,就是编写最复杂的 ModelMetaclass 了:
class ModelMetaclass(type):
def __new__(cls, name, bases, attrs):
if name=='Model':
return type.__new__(cls, name, bases, attrs)
print('Found model: %s' % name)
mappings = dict()
for k, v in attrs.items():
if isinstance(v, Field):
print('Found mapping: %s ==> %s' % (k, v))
mappings[k] = v
for k in mappings.keys():
attrs.pop(k)
attrs['__mappings__'] = mappings # 保存属性和列的映射关系
attrs['__table__'] = name # 假设表名和类名一致
return type.__new__(cls, name, bases, attrs)以及基类 Model:
class Model(dict, metaclass=ModelMetaclass):
def __init__(self, **kw):
super(Model, self).__init__(**kw)
def __getattr__(self, key):
try:
return self[key]
except KeyError:
raise AttributeError(r"'Model' object has no attribute '%s'" % key)
def __setattr__(self, key, value):
self[key] = value
def save(self):
fields = []
params = []
args = []
for k, v in self.__mappings__.items():
fields.append(v.name)
params.append('?')
args.append(getattr(self, k, None))
sql = 'insert into %s (%s) values (%s)' % (self.__table__, ','.join(fields), ','.join(params))
print('SQL: %s' % sql)
print('ARGS: %s' % str(args))当用户定义一个 class User(Model) 时,Python 解释器首先在当前类 User 的定义中查找 metaclass,如果没有找到,就继续在父类 Model 中查找 metaclass,找到了,就使用 Model 中定义的 metaclass 的 ModelMetaclass 来创建 User 类,也就是说,metaclass 可以隐式地继承到子类,但子类自己却感觉不到。
在 ModelMetaclass 中,一共做了几件事情:
- 排除掉对 Model 类的修改;
- 在当前类(比如 User)中查找定义的类的所有属性,如果找到一个 Field 属性,就把它保存到一个
__mappings__的 dict 中,同时从类属性中删除该 Field 属性,否则,容易造成运行时错误(实例的属性会遮盖类的同名属性); - 把表名保存到
__table__中,这里简化为表名默认为类名。
在 Model 类中,就可以定义各种操作数据库的方法,比如 save(),delete(),find(),update() 等等。
我们实现了 save() 方法,把一个实例保存到数据库中。因为有表名,属性到字段的映射和属性值的集合,就可以构造出 INSERT 语句。
编写代码试试:
u = User(id=12345, name='Michael', email='test@orm.org', password='my-pwd')
u.save()输出如下:
Found model: User
Found mapping: email ==> <StringField:email>
Found mapping: password ==> <StringField:password>
Found mapping: id ==> <IntegerField:uid>
Found mapping: name ==> <StringField:username>
SQL: insert into User (password,email,username,id) values (?,?,?,?)
ARGS: ['my-pwd', 'test@orm.org', 'Michael', 12345]可以看到,save() 方法已经打印出了可执行的 SQL 语句,以及参数列表,只需要真正连接到数据库,执行该 SQL 语句,就可以完成真正的功能。
不到 100 行代码,我们就通过 metaclass 实现了一个精简的 ORM 框架,是不是非常简单?
小结
metaclass 是 Python 中非常具有魔术性的对象,它可以改变类创建时的行为。这种强大的功能使用起来务必小心。
错误、调试和测试
错误处理
try
try:
print('try...')
r = 10 / 0
print('result:', r)
except ZeroDivisionError as e:
print('except:', e)
finally:
print('finally...')
print('END')当我们认为某些代码可能会出错时,就可以用 try 来运行这段代码,如果执行出错,则后续代码不会继续执行,而是直接跳转至错误处理代码,即 except 语句块,执行完 except 后,如果有 finally 语句块,则执行 finally 语句块,至此,执行完毕。
上面的代码在计算 10 / 0 时会产生一个除法运算错误:
try...
except: division by zero
finally...
END从输出可以看到,当错误发生时,后续语句 print('result:', r) 不会被执行,except 由于捕获到 ZeroDivisionError,因此被执行。最后,finally 语句被执行。然后,程序继续按照流程往下走。
如果把除数 0 改成 2,则执行结果如下:
try...
result: 5
finally...
END由于没有错误发生,所以 except 语句块不会被执行,但是 finally 如果有,则一定会被执行(可以没有 finally 语句)。
你还可以猜测,错误应该有很多种类,如果发生了不同类型的错误,应该由不同的 except 语句块处理。没错,可以有多个 except 来捕获不同类型的错误:
try:
print('try...')
r = 10 / int('a')
print('result:', r)
except ValueError as e:
print('ValueError:', e)
except ZeroDivisionError as e:
print('ZeroDivisionError:', e)
finally:
print('finally...')
print('END')int() 函数可能会抛出 ValueError,所以我们用一个 except 捕获 ValueError,用另一个 except 捕获 ZeroDivisionError。
此外,如果没有错误发生,可以在 except 语句块后面加一个 else,当没有错误发生时,会自动执行 else 语句:
try:
print('try...')
r = 10 / int('2')
print('result:', r)
except ValueError as e:
print('ValueError:', e)
except ZeroDivisionError as e:
print('ZeroDivisionError:', e)
else:
print('no error!')
finally:
print('finally...')
print('END')Python 的错误其实也是 class,所有的错误类型都继承自 BaseException,所以在使用 except 时需要注意的是,它不但捕获该类型的错误,还把其子类也“一网打尽”。比如:
try:
foo()
except ValueError as e:
print('ValueError')
except UnicodeError as e:
print('UnicodeError')第二个 except 永远也捕获不到 UnicodeError,因为 UnicodeError 是 ValueError 的子类,如果有,也被第一个 except 给捕获了。
Python 所有的错误都是从 BaseException 类派生的,常见的错误类型和继承关系看这里
使用 try…except 捕获错误还有一个巨大的好处,就是可以跨越多层调用,比如函数 main() 调用 bar(),bar() 调用 foo(),结果 foo() 出错了,这时,只要 main() 捕获到了,就可以处理:
def foo(s):
return 10 / int(s)
def bar(s):
return foo(s) * 2
def main():
try:
bar('0')
except Exception as e:
print('Error:', e)
finally:
print('finally...')也就是说,不需要在每个可能出错的地方去捕获错误,只要在合适的层次去捕获错误就可以了。这样一来,就大大减少了写 try…except…finally 的麻烦。
调用栈
如果错误没有被捕获,它就会一直往上抛,最后被 Python 解释器捕获,打印一个错误信息,然后程序退出。来看看 err.py:
# err.py:
def foo(s):
return 10 / int(s)
def bar(s):
return foo(s) * 2
def main():
bar('0')
main()执行,结果如下:
$ python3 err.py
Traceback (most recent call last): # 错误的跟踪信息
File "err.py", line 11, in <module> # 调用 main() 出错了,在代码文件 err.py 的第 11 行代码,但原因是第 9 行
main()
File "err.py", line 9, in main # 调用 bar('0') 出错了,在代码文件 err.py 的第 9 行代码,但原因是第 6 行
bar('0')
File "err.py", line 6, in bar # 原因是 return foo(s) * 2 这个语句出错了,但这还不是最终原因,继续往下看
return foo(s) * 2
File "err.py", line 3, in foo # 原因是 return 10 / int(s) 这个语句出错了,这是错误产生的源头,因为下面打印了:ZeroDivisionError: division by zero
return 10 / int(s)
ZeroDivisionError: division by zero出错并不可怕,可怕的是不知道哪里出错了。解读错误信息是定位错误的关键,如上面的代码注释
记录错误
如果不捕获错误,自然可以让 Python 解释器来打印出错误堆栈,但程序也被结束了。既然我们能捕获错误,就可以把错误堆栈打印出来,然后分析错误原因,同时,让程序继续执行下去。
Python 内置的 logging 模块可以非常容易地记录错误信息:
# err_logging.py
import logging
def foo(s):
return 10 / int(s)
def bar(s):
return foo(s) * 2
def main():
try:
bar('0')
except Exception as e:
logging.exception(e)
main()
print('END')同样是出错,但程序打印完错误信息后会继续执行,并正常退出:
$ python3 err_logging.py
ERROR:root:division by zero
Traceback (most recent call last):
File "err_logging.py", line 13, in main
bar('0')
File "err_logging.py", line 9, in bar
return foo(s) * 2
File "err_logging.py", line 6, in foo
return 10 / int(s)
ZeroDivisionError: division by zero
END通过配置,logging 还可以把错误记录到日志文件里,方便事后排查。
抛出错误
因为错误是 class,捕获一个错误就是捕获到该 class 的一个实例。因此,错误并不是凭空产生的,而是有意创建并抛出的。Python 的内置函数会抛出很多类型的错误,我们自己编写的函数也可以抛出错误。
如果要抛出错误,首先根据需要,可以定义一个错误的 class,选择好继承关系,然后,用 raise 语句抛出一个错误的实例:
# err_raise.py
class FooError(ValueError):
pass
def foo(s):
n = int(s)
if n==0:
raise FooError('invalid value: %s' % s)
return 10 / n
foo('0')执行,可以最后跟踪到我们自己定义的错误:
$ python3 err_raise.py
Traceback (most recent call last):
File "err_throw.py", line 11, in <module>
foo('0')
File "err_throw.py", line 8, in foo
raise FooError('invalid value: %s' % s)
__main__.FooError: invalid value: 0只有在必要的时候才定义我们自己的错误类型。如果可以选择 Python 已有的内置的错误类型(比如 ValueError,TypeError),尽量使用 Python 内置的错误类型。
最后,我们来看另一种错误处理的方式:
# err_reraise.py
def foo(s):
n = int(s)
if n==0:
raise ValueError('invalid value: %s' % s)
return 10 / n
def bar():
try:
foo('0')
except ValueError as e:
print('ValueError!')
raise
bar()在 bar() 函数中,我们明明已经捕获了错误,但是,打印一个 ValueError! 后,又把错误通过 raise 语句抛出去了,这不有病么?
其实这种错误处理方式不但没病,而且相当常见。捕获错误目的只是记录一下,便于后续追踪。但是,由于当前函数不知道应该怎么处理该错误,所以,最恰当的方式是继续往上抛,让顶层调用者去处理。好比一个员工处理不了一个问题时,就把问题抛给他的老板,如果他的老板也处理不了,就一直往上抛,最终会抛给 CEO 去处理。
raise 语句如果不带参数,就会把当前错误原样抛出。此外,在 except 中 raise 一个 Error,还可以把一种类型的错误转化成另一种类型:
try:
10 / 0
except ZeroDivisionError:
raise ValueError('input error!')只要是合理的转换逻辑就可以,但是,决不应该把一个 IOError 转换成毫不相干的 ValueError。
小结
Python 内置的 try…except…finally 用来处理错误十分方便。出错时,会分析错误信息并定位错误发生的代码位置才是最关键的。
程序也可以主动抛出错误,让调用者来处理相应的错误。但是,应该在文档中写清楚可能会抛出哪些错误,以及错误产生的原因。
调试
第一种方法简单直接粗暴有效,就是用 print() 把可能有问题的变量打印出来看看:
def foo(s):
n = int(s)
print('>>> n = %d' % n)
return 10 / n
def main():
foo('0')
main()执行后在输出中查找打印的变量值:
$ python err.py
>>> n = 0
Traceback (most recent call last):
...
ZeroDivisionError: integer division or modulo by zero用 print() 最大的坏处是将来还得删掉它,想想程序里到处都是 print(),运行结果也会包含很多垃圾信息。所以,我们又有第二种方法。
断言
凡是用 print() 来辅助查看的地方,都可以用断言(assert)来替代:
def foo(s):
n = int(s)
assert n != 0, 'n is zero!'
return 10 / n
def main():
foo('0')assert 的意思是,表达式 n != 0 应该是 True,否则,根据程序运行的逻辑,后面的代码肯定会出错。
如果断言失败,assert 语句本身就会抛出 AssertionError:
$ python err.py
Traceback (most recent call last):
...
AssertionError: n is zero!程序中如果到处充斥着 assert,和 print() 相比也好不到哪去。不过,启动 Python 解释器时可以用 -O 参数来关闭 assert:
$ python -O err.py
Traceback (most recent call last):
...
ZeroDivisionError: division by zero注意:断言的开关“-O”是英文大写字母 O,不是数字 0。
关闭后,你可以把所有的 assert 语句当成 pass 来看。
logging
把 print() 替换为 logging 是第 3 种方式,和 assert 比,logging 不会抛出错误,而且可以输出到文件:
import logging
s = '0'
n = int(s)
logging.info('n = %d' % n)
print(10 / n)logging.info() 就可以输出一段文本。运行,发现除了 ZeroDivisionError,没有任何信息。怎么回事?
别急,在 import logging 之后添加一行配置再试试:
import logging
logging.basicConfig(level=logging.INFO)看到输出了:
$ python err.py
INFO:root:n = 0
Traceback (most recent call last):
File "err.py", line 8, in <module>
print(10 / n)
ZeroDivisionError: division by zero这就是 logging 的好处,它允许你指定记录信息的级别,有 debug,info,warning,error 等几个级别,当我们指定 level=INFO 时,logging.debug 就不起作用了。同理,指定 level=WARNING 后,debug 和 info 就不起作用了。这样一来,你可以放心地输出不同级别的信息,也不用删除,最后统一控制输出哪个级别的信息。
logging 的另一个好处是通过简单的配置,一条语句可以同时输出到不同的地方,比如 console 和文件。
pdb
第 4 种方式是启动 Python 的调试器 pdb,让程序以单步方式运行,可以随时查看运行状态。我们先准备好程序:
# err.py
s = '0'
n = int(s)
print(10 / n)然后启动:
$ python -m pdb err.py
> /Users/michael/Github/learn-python3/samples/debug/err.py(2)<module>()
-> s = '0'以参数 -m pdb 启动后,pdb 定位到下一步要执行的代码 -> s = '0'。输入命令 l 来查看代码:
(Pdb) l
1 # err.py
2 -> s = '0'
3 n = int(s)
4 print(10 / n)输入命令 n 可以单步执行代码:
(Pdb) n
> /Users/michael/Github/learn-python3/samples/debug/err.py(3)<module>()
-> n = int(s)
(Pdb) n
> /Users/michael/Github/learn-python3/samples/debug/err.py(4)<module>()
-> print(10 / n)任何时候都可以输入命令 p 变量名来查看变量:
(Pdb) p s
'0'
(Pdb) p n
0输入命令 q 结束调试,退出程序:
(Pdb) q这种通过 pdb 在命令行调试的方法理论上是万能的,但实在是太麻烦了,如果有一千行代码,要运行到第 999 行得敲多少命令啊。还好,我们还有另一种调试方法。
pdb.set_trace()
这个方法也是用 pdb,但是不需要单步执行,我们只需要 import pdb,然后,在可能出错的地方放一个 pdb.set_trace(),就可以设置一个断点:
# err.py
import pdb
s = '0'
n = int(s)
pdb.set_trace() # 运行到这里会自动暂停
print(10 / n)运行代码,程序会自动在 pdb.set_trace() 暂停并进入 pdb 调试环境,可以用命令 p 查看变量,或者用命令 c 继续运行:
$ python err.py
> /Users/michael/Github/learn-python3/samples/debug/err.py(7)<module>()
-> print(10 / n)
(Pdb) p n
0
(Pdb) c
Traceback (most recent call last):
File "err.py", line 7, in <module>
print(10 / n)
ZeroDivisionError: division by zero这个方式比直接启动 pdb 单步调试效率要高很多,但也高不到哪去。
IDE
如果要比较爽地设置断点、单步执行,就需要一个支持调试功能的 IDE。
小结
写程序最痛苦的事情莫过于调试,程序往往会以你意想不到的流程来运行,你期待执行的语句其实根本没有执行,这时候,就需要调试了。
虽然用 IDE 调试起来比较方便,但是最后你会发现,logging 才是终极武器。
单元测试
文档测试
IO 编程
注意,本章的 IO 编程都是同步模式,异步 IO 由于复杂度太高,后续涉及到服务器端程序开发时我们再讨论。
文件读写
读写文件是最常见的 IO 操作。Python 内置了读写文件的函数,用法和 C 是兼容的。
读文件
要以读文件的模式打开一个文件对象,使用 Python 内置的 open() 函数,传入文件名和标示符:
>>> f = open('/Users/michael/test.txt', 'r')标示符 ‘r’ 表示读,这样,我们就成功地打开了一个文件。
如果文件不存在,open() 函数就会抛出一个 IOError 的错误,并且给出错误码和详细的信息告诉你文件不存在:
>>> f=open('/Users/michael/notfound.txt', 'r')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
FileNotFoundError: [Errno 2] No such file or directory: '/Users/michael/notfound.txt'如果文件打开成功,接下来,调用 read() 方法可以一次读取文件的全部内容,Python 把内容读到内存,用一个 str 对象表示:
>>> f.read()
'Hello, world!'最后一步是调用 close() 方法关闭文件。文件使用完毕后必须关闭,因为文件对象会占用操作系统的资源,并且操作系统同一时间能打开的文件数量也是有限的:
>>> f.close()由于文件读写时都有可能产生 IOError,一旦出错,后面的 f.close() 就不会调用。所以,为了保证无论是否出错都能正确地关闭文件,我们可以使用 try … finally 来实现:
try:
f = open('/path/to/file', 'r')
print(f.read())
finally:
if f:
f.close()但是每次都这么写实在太繁琐,所以,Python 引入了 with 语句来自动帮我们调用 close() 方法:
with open('/path/to/file', 'r') as f:
print(f.read())这和前面的 try … finally 是一样的,但是代码更加简洁,并且不必调用 f.close() 方法。
调用 read() 会一次性读取文件的全部内容,如果文件有 10G,内存就爆了,所以,要保险起见,可以反复调用 read(size) 方法,每次最多读取 size 个字节的内容。另外,调用 readline() 可以每次读取一行内容,调用 readlines() 一次读取所有内容并按行返回 list。因此,要根据需要决定怎么调用。
如果文件很小,read() 一次性读取最方便;如果不能确定文件大小,反复调用 read(size) 比较保险;如果是配置文件,调用 readlines() 最方便:
for line in f.readlines():
print(line.strip()) # 把末尾的 '\n' 删掉file-like Object
像 open() 函数返回的这种有个 read() 方法的对象,在 Python 中统称为 file-like Object。除了 file 外,还可以是内存的字节流,网络流,自定义流等等。file-like Object 不要求从特定类继承,只要写个 read() 方法就行。
StringIO 就是在内存中创建的 file-like Object,常用作临时缓冲。
二进制文件
前面讲的默认都是读取文本文件,并且是 UTF-8 编码的文本文件。要读取二进制文件,比如图片、视频等等,用 ‘rb’ 模式打开文件即可:
>>> f = open('/Users/michael/test.jpg', 'rb')
>>> f.read()
b'\xff\xd8\xff\xe1\x00\x18Exif\x00\x00...' # 十六进制表示的字节字符编码
要读取非 UTF-8 编码的文本文件,需要给 open() 函数传入 encoding 参数,例如,读取 GBK 编码的文件:
>>> f = open('/Users/michael/gbk.txt', 'r', encoding='gbk')
>>> f.read()
'测试'遇到有些编码不规范的文件,你可能会遇到 UnicodeDecodeError,因为在文本文件中可能夹杂了一些非法编码的字符。遇到这种情况,open() 函数还接收一个 errors 参数,表示如果遇到编码错误后如何处理。最简单的方式是直接忽略:
>>> f = open('/Users/michael/gbk.txt', 'r', encoding='gbk', errors='ignore')写文件
写文件和读文件是一样的,唯一区别是调用 open() 函数时,传入标识符 ‘w’ 或者 ‘wb’ 表示写文本文件或写二进制文件:
>>> f = open('/Users/michael/test.txt', 'w')
>>> f.write('Hello, world!')
>>> f.close()你可以反复调用 write() 来写入文件,但是务必要调用 f.close() 来关闭文件。当我们写文件时,操作系统往往不会立刻把数据写入磁盘,而是放到内存缓存起来,空闲的时候再慢慢写入。只有调用 close() 方法时,操作系统才保证把没有写入的数据全部写入磁盘。忘记调用 close() 的后果是数据可能只写了一部分到磁盘,剩下的丢失了。所以,还是用 with 语句来得保险:
with open('/Users/michael/test.txt', 'w') as f:
f.write('Hello, world!')要写入特定编码的文本文件,请给 open() 函数传入 encoding 参数,将字符串自动转换成指定编码。
细心的童鞋会发现,以 ‘w’ 模式写入文件时,如果文件已存在,会直接覆盖(相当于删掉后新写入一个文件)。如果我们希望追加到文件末尾怎么办?可以传入 ‘a’ 以追加(append)模式写入。
所有模式的定义及含义可以参考 Python 的官方文档。
小结
在 Python 中,文件读写是通过 open() 函数打开的文件对象完成的。使用 with 语句操作文件 IO 是个好习惯。
StringIO 和 BytesIO
StringIO
很多时候,数据读写不一定是文件,也可以在内存中读写。
StringIO 顾名思义就是在内存中读写 str。
要把 str 写入 StringIO,我们需要先创建一个 StringIO,然后,像文件一样写入即可:
>>> from io import StringIO
>>> f = StringIO()
>>> f.write('hello')
5
>>> f.write(' ')
1
>>> f.write('world!')
6
>>> print(f.getvalue())
hello world!getvalue() 方法用于获得写入后的 str。
要读取 StringIO,可以用一个 str 初始化 StringIO,然后,像读文件一样读取:
>>> from io import StringIO
>>> f = StringIO('Hello!\nHi!\nGoodbye!')
>>> while True:
... s = f.readline()
... if s == '':
... break
... print(s.strip())
...
Hello!
Hi!
Goodbye!BytesIO
StringIO 操作的只能是 str,如果要操作二进制数据,就需要使用 BytesIO。
BytesIO 实现了在内存中读写 bytes,我们创建一个 BytesIO,然后写入一些 bytes:
>>> from io import BytesIO
>>> f = BytesIO()
>>> f.write('中文'.encode('utf-8'))
6
>>> print(f.getvalue())
b'\xe4\xb8\xad\xe6\x96\x87'请注意,写入的不是 str,而是经过 UTF-8 编码的 bytes。
和 StringIO 类似,可以用一个 bytes 初始化 BytesIO,然后,像读文件一样读取:
>>> from io import BytesIO
>>> f = BytesIO(b'\xe4\xb8\xad\xe6\x96\x87')
>>> f.read()
b'\xe4\xb8\xad\xe6\x96\x87'小结
StringIO 和 BytesIO 是在内存中操作 str 和 bytes 的方法,使得和读写文件具有一致的接口。
操作文件和目录
>>> import os
>>> os.name # 操作系统类型
'posix'如果是 posix,说明系统是 Linux、Unix 或 Mac OS X,如果是 nt,就是 Windows 系统。
要获取详细的系统信息,可以调用 uname() 函数:
>>> os.uname()
posix.uname_result(sysname='Darwin', nodename='MichaelMacPro.local', release='14.3.0', version='Darwin Kernel Version 14.3.0: Mon Mar 23 11:59:05 PDT 2015; root:xnu-2782.20.48~5/RELEASE_X86_64', machine='x86_64')注意 uname() 函数在 Windows 上不提供,也就是说,os 模块的某些函数是跟操作系统相关的。
环境变量
在操作系统中定义的环境变量,全部保存在 os.environ 这个变量中,可以直接查看:
>>> os.environ
environ({'VERSIONER_PYTHON_PREFER_32_BIT': 'no', 'TERM_PROGRAM_VERSION': '326', 'LOGNAME': 'michael', 'USER': 'michael', 'PATH': '/usr/bin:/bin:/usr/sbin:/sbin:/usr/local/bin:/opt/X11/bin:/usr/local/mysql/bin', ...})要获取某个环境变量的值,可以调用 os.environ.get(‘key’):
>>> os.environ.get('PATH')
'/usr/bin:/bin:/usr/sbin:/sbin:/usr/local/bin:/opt/X11/bin:/usr/local/mysql/bin'
>>> os.environ.get('x', 'default')
'default'操作文件和目录
操作文件和目录的函数一部分放在 os 模块中,一部分放在 os.path 模块中,这一点要注意一下。查看、创建和删除目录可以这么调用:
# 查看当前目录的绝对路径:
>>> os.path.abspath('.')
'/Users/michael'
# 在某个目录下创建一个新目录,首先把新目录的完整路径表示出来:
>>> os.path.join('/Users/michael', 'testdir')
'/Users/michael/testdir'
# 然后创建一个目录:
>>> os.mkdir('/Users/michael/testdir')
# 删掉一个目录:
>>> os.rmdir('/Users/michael/testdir')把两个路径合成一个时,不要直接拼字符串,而要通过 os.path.join() 函数,这样可以正确处理不同操作系统的路径分隔符。在 Linux/Unix/Mac 下,os.path.join() 返回这样的字符串:
part-1/part-2而 Windows 下会返回这样的字符串:
part-1\part-2同样的道理,要拆分路径时,也不要直接去拆字符串,而要通过 os.path.split() 函数,这样可以把一个路径拆分为两部分,后一部分总是最后级别的目录或文件名:
>>> os.path.split('/Users/michael/testdir/file.txt')
('/Users/michael/testdir', 'file.txt')os.path.splitext() 可以直接让你得到文件扩展名,很多时候非常方便:
>>> os.path.splitext('/path/to/file.txt')
('/path/to/file', '.txt')这些合并、拆分路径的函数并不要求目录和文件要真实存在,它们只对字符串进行操作。
文件操作使用下面的函数。假定当前目录下有一个 test.txt 文件:
# 对文件重命名:
>>> os.rename('test.txt', 'test.py')
# 删掉文件:
>>> os.remove('test.py')但是复制文件的函数居然在 os 模块中不存在!原因是复制文件并非由操作系统提供的系统调用。理论上讲,我们通过上一节的读写文件可以完成文件复制,只不过要多写很多代码。
幸运的是 shutil 模块提供了 copyfile() 的函数,你还可以在 shutil 模块中找到很多实用函数,它们可以看做是 os 模块的补充。
最后看看如何利用 Python 的特性来过滤文件。比如我们要列出当前目录下的所有目录,只需要一行代码:
>>> [x for x in os.listdir('.') if os.path.isdir(x)]
['.lein', '.local', '.m2', '.npm', '.ssh', '.Trash', '.vim', 'Applications', 'Desktop', ...]要列出所有的 .py 文件,也只需一行代码:
>>> [x for x in os.listdir('.') if os.path.isfile(x) and os.path.splitext(x)[1]=='.py']
['apis.py', 'config.py', 'models.py', 'pymonitor.py', 'test_db.py', 'urls.py', 'wsgiapp.py']是不是非常简洁?
小结
Python 的 os 模块封装了操作系统的目录和文件操作,要注意这些函数有的在 os 模块中,有的在 os.path 模块中。
序列化
在程序运行的过程中,所有的变量都是在内存中,比如,定义一个 dict:
d = dict(name='Bob', age=20, score=88)可以随时修改变量,比如把 name 改成 ‘Bill’,但是一旦程序结束,变量所占用的内存就被操作系统全部回收。如果没有把修改后的 ‘Bill’ 存储到磁盘上,下次重新运行程序,变量又被初始化为 ‘Bob’。
我们把变量从内存中变成可存储或传输的过程称之为序列化,在 Python 中叫 pickling,在其他语言中也被称之为 serialization,marshalling,flattening 等等,都是一个意思。
序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即 unpickling。
Python 提供了 pickle 模块来实现序列化。
首先,我们尝试把一个对象序列化并写入文件:
>>> import pickle
>>> d = dict(name='Bob', age=20, score=88)
>>> pickle.dumps(d)
b'\x80\x03}q\x00(X\x03\x00\x00\x00ageq\x01K\x14X\x05\x00\x00\x00scoreq\x02KXX\x04\x00\x00\x00nameq\x03X\x03\x00\x00\x00Bobq\x04u.'pickle.dumps() 方法把任意对象序列化成一个 bytes,然后,就可以把这个 bytes 写入文件。或者用另一个方法 pickle.dump() 直接把对象序列化后写入一个 file-like Object:
>>> f = open('dump.txt', 'wb')
>>> pickle.dump(d, f)
>>> f.close()看看写入的 dump.txt 文件,一堆乱七八糟的内容,这些都是 Python 保存的对象内部信息。
当我们要把对象从磁盘读到内存时,可以先把内容读到一个 bytes,然后用 pickle.loads() 方法反序列化出对象,也可以直接用 pickle.load() 方法从一个 file-like Object 中直接反序列化出对象。我们打开另一个 Python 命令行来反序列化刚才保存的对象:
>>> f = open('dump.txt', 'rb')
>>> d = pickle.load(f)
>>> f.close()
>>> d
{'age': 20, 'score': 88, 'name': 'Bob'}变量的内容又回来了!
当然,这个变量和原来的变量是完全不相干的对象,它们只是内容相同而已。
Pickle 的问题和所有其他编程语言特有的序列化问题一样,就是它只能用于 Python,并且可能不同版本的 Python 彼此都不兼容,因此,只能用 Pickle 保存那些不重要的数据,不能成功地反序列化也没关系。
JSON
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如 XML,但更好的方法是序列化为 JSON,因为 JSON 表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON 不仅是标准格式,并且比 XML 更快,而且可以直接在 Web 页面中读取,非常方便。
JSON 表示的对象就是标准的 JavaScript 语言的对象,JSON 和 Python 内置的数据类型对应如下:
| JSON 类型 | Python 类型 |
|---|---|
| {} | dict |
| [] | list |
| “string” | str |
| 1234.56 | int 或 float |
| true/false | True/False |
| null | None |
Python 内置的 json 模块提供了非常完善的 Python 对象到 JSON 格式的转换。我们先看看如何把 Python 对象变成一个 JSON:
>>> import json
>>> d = dict(name='Bob', age=20, score=88)
>>> json.dumps(d)
'{"age": 20, "score": 88, "name": "Bob"}'dumps() 方法返回一个 str,内容就是标准的 JSON。类似的,dump() 方法可以直接把 JSON 写入一个 file-like Object。
要把 JSON 反序列化为 Python 对象,用 loads() 或者对应的 load() 方法,前者把 JSON 的字符串反序列化,后者从 file-like Object 中读取字符串并反序列化:
>>> json_str = '{"age": 20, "score": 88, "name": "Bob"}'
>>> json.loads(json_str)
{'age': 20, 'score': 88, 'name': 'Bob'}由于 JSON 标准规定 JSON 编码是 UTF-8,所以我们总是能正确地在 Python 的 str 与 JSON 的字符串之间转换。
JSON 进阶
Python 的 dict 对象可以直接序列化为 JSON 的 {},不过,很多时候,我们更喜欢用 class 表示对象,比如定义 Student 类,然后序列化:
import json
class Student(object):
def __init__(self, name, age, score):
self.name = name
self.age = age
self.score = score
s = Student('Bob', 20, 88)
print(json.dumps(s))运行代码,毫不留情地得到一个 TypeError:
Traceback (most recent call last):
...
TypeError: <__main__.Student object at 0x10603cc50> is not JSON serializable错误的原因是 Student 对象不是一个可序列化为 JSON 的对象。
如果连 class 的实例对象都无法序列化为 JSON,这肯定不合理!
别急,我们仔细看看 dumps() 方法的参数列表,可以发现,除了第一个必须的 obj 参数外,dumps() 方法还提供了一大堆的可选参数
这些可选参数就是让我们来定制 JSON 序列化。前面的代码之所以无法把 Student 类实例序列化为 JSON,是因为默认情况下,dumps() 方法不知道如何将 Student 实例变为一个 JSON 的 {} 对象。
可选参数 default 就是把任意一个对象变成一个可序列为 JSON 的对象,我们只需要为 Student 专门写一个转换函数,再把函数传进去即可:
def student2dict(std):
return {
'name': std.name,
'age': std.age,
'score': std.score
}这样,Student 实例首先被 student2dict() 函数转换成 dict,然后再被顺利序列化为 JSON:
>>> print(json.dumps(s, default=student2dict))
{"age": 20, "name": "Bob", "score": 88}不过,下次如果遇到一个 Teacher 类的实例,照样无法序列化为 JSON。我们可以偷个懒,把任意 class 的实例变为 dict:
print(json.dumps(s, default=lambda obj: obj.__dict__))因为通常 class 的实例都有一个 __dict__ 属性,它就是一个 dict,用来存储实例变量。也有少数例外,比如定义了 __slots__ 的 class。
同样的道理,如果我们要把 JSON 反序列化为一个 Student 对象实例,loads() 方法首先转换出一个 dict 对象,然后,我们传入的 object_hook 函数负责把 dict 转换为 Student 实例:
def dict2student(d):
return Student(d['name'], d['age'], d['score'])运行结果如下:
>>> json_str = '{"age": 20, "score": 88, "name": "Bob"}'
>>> print(json.loads(json_str, object_hook=dict2student))
<__main__.Student object at 0x10cd3c190>打印出的是反序列化的 Student 实例对象。
小结
Python 语言特定的序列化模块是 pickle,但如果要把序列化搞得更通用、更符合 Web 标准,就可以使用 json 模块。
json 模块的 dumps() 和 loads() 函数是定义得非常好的接口的典范。当我们使用时,只需要传入一个必须的参数。但是,当默认的序列化或反序列机制不满足我们的要求时,我们又可以传入更多的参数来定制序列化或反序列化的规则,既做到了接口简单易用,又做到了充分的扩展性和灵活性。
进程和线程
多进程
要让 Python 程序实现多进程(multiprocessing),我们先了解操作系统的相关知识。
Unix/Linux 操作系统提供了一个 fork() 系统调用,它非常特殊。普通的函数调用,调用一次,返回一次,但是 fork() 调用一次,返回两次,因为操作系统自动把当前进程(称为父进程)复制了一份(称为子进程),然后,分别在父进程和子进程内返回。
子进程永远返回 0,而父进程返回子进程的 ID。这样做的理由是,一个父进程可以 fork 出很多子进程,所以,父进程要记下每个子进程的 ID,而子进程只需要调用 getppid() 就可以拿到父进程的 ID。
Python 的 os 模块封装了常见的系统调用,其中就包括 fork,可以在 Python 程序中轻松创建子进程:
import os
print('Process (%s) start...' % os.getpid())
# Only works on Unix/Linux/Mac:
pid = os.fork()
if pid == 0:
print('I am child process (%s) and my parent is %s.' % (os.getpid(), os.getppid()))
else:
print('I (%s) just created a child process (%s).' % (os.getpid(), pid))运行结果如下:
Process (876) start...
I (876) just created a child process (877).
I am child process (877) and my parent is 876.由于 Windows 没有 fork 调用,上面的代码在 Windows 上无法运行。
有了 fork 调用,一个进程在接到新任务时就可以复制出一个子进程来处理新任务,常见的 Apache 服务器就是由父进程监听端口,每当有新的 http 请求时,就 fork 出子进程来处理新的 http 请求。
multiprocessing
如果你打算编写多进程的服务程序,Unix/Linux 无疑是正确的选择。由于 Windows 没有 fork 调用,难道在 Windows 上无法用 Python 编写多进程的程序?
由于 Python 是跨平台的,自然也应该提供一个跨平台的多进程支持。multiprocessing 模块就是跨平台版本的多进程模块。
multiprocessing 模块提供了一个 Process 类来代表一个进程对象,下面的例子演示了启动一个子进程并等待其结束:
from multiprocessing import Process
import os
# 子进程要执行的代码
def run_proc(name):
print('Run child process %s (%s)...' % (name, os.getpid()))
if __name__=='__main__':
print('Parent process %s.' % os.getpid())
p = Process(target=run_proc, args=('test',))
print('Child process will start.')
p.start()
p.join()
print('Child process end.')执行结果如下:
Parent process 928.
Child process will start.
Run child process test (929)...
Process end.创建子进程时,只需要传入一个执行函数和函数的参数,创建一个 Process 实例,用 start() 方法启动,这样创建进程比 fork() 还要简单。
join() 方法可以等待子进程结束后再继续往下运行,通常用于进程间的同步。
Pool
如果要启动大量的子进程,可以用进程池的方式批量创建子进程:
from multiprocessing import Pool
import os, time, random
def long_time_task(name):
print('Run task %s (%s)...' % (name, os.getpid()))
start = time.time()
time.sleep(random.random() * 3)
end = time.time()
print('Task %s runs %0.2f seconds.' % (name, (end - start)))
if __name__=='__main__':
print('Parent process %s.' % os.getpid())
p = Pool(4)
for i in range(5):
p.apply_async(long_time_task, args=(i,))
print('Waiting for all subprocesses done...')
p.close()
p.join()
print('All subprocesses done.')执行结果如下:
Parent process 669.
Waiting for all subprocesses done...
Run task 0 (671)...
Run task 1 (672)...
Run task 2 (673)...
Run task 3 (674)...
Task 2 runs 0.14 seconds.
Run task 4 (673)...
Task 1 runs 0.27 seconds.
Task 3 runs 0.86 seconds.
Task 0 runs 1.41 seconds.
Task 4 runs 1.91 seconds.
All subprocesses done.代码解读:
对 Pool 对象调用 join() 方法会等待所有子进程执行完毕,调用 join() 之前必须先调用 close(),调用 close() 之后就不能继续添加新的 Process 了。
请注意输出的结果,task 0,1,2,3 是立刻执行的,而 task 4 要等待前面某个 task 完成后才执行,这是因为 Pool 的默认大小在我的电脑上是 4,因此,最多同时执行 4 个进程。这是 Pool 有意设计的限制,并不是操作系统的限制。如果改成:
p = Pool(5)就可以同时跑 5 个进程。
由于 Pool 的默认大小是 CPU 的核数,如果你不幸拥有 8 核 CPU,你要提交至少 9 个子进程才能看到上面的等待效果。
子进程
很多时候,子进程并不是自身,而是一个外部进程。我们创建了子进程后,还需要控制子进程的输入和输出。
subprocess 模块可以让我们非常方便地启动一个子进程,然后控制其输入和输出。
下面的例子演示了如何在 Python 代码中运行命令 nslookup www.python.org,这和命令行直接运行的效果是一样的:
import subprocess
print('$ nslookup www.python.org')
r = subprocess.call(['nslookup', 'www.python.org'])
print('Exit code:', r)运行结果:
$ nslookup www.python.org
Server: 192.168.19.4
Address: 192.168.19.4#53
Non-authoritative answer:
www.python.org canonical name = python.map.fastly.net.
Name: python.map.fastly.net
Address: 199.27.79.223
Exit code: 0如果子进程还需要输入,则可以通过 communicate() 方法输入:
import subprocess
print('$ nslookup')
p = subprocess.Popen(['nslookup'], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
output, err = p.communicate(b'set q=mx\npython.org\nexit\n')
print(output.decode('utf-8'))
print('Exit code:', p.returncode)上面的代码相当于在命令行执行命令 nslookup,然后手动输入:
set q=mx
python.org
exit运行结果如下:
$ nslookup
Server: 192.168.19.4
Address: 192.168.19.4#53
Non-authoritative answer:
python.org mail exchanger = 50 mail.python.org.
Authoritative answers can be found from:
mail.python.org internet address = 82.94.164.166
mail.python.org has AAAA address 2001:888:2000:d::a6
Exit code: 0进程间通信
Process 之间肯定是需要通信的,操作系统提供了很多机制来实现进程间的通信。Python 的 multiprocessing 模块包装了底层的机制,提供了 Queue、Pipes 等多种方式来交换数据。
我们以 Queue 为例,在父进程中创建两个子进程,一个往 Queue 里写数据,一个从 Queue 里读数据:
from multiprocessing import Process, Queue
import os, time, random
# 写数据进程执行的代码:
def write(q):
print('Process to write: %s' % os.getpid())
for value in ['A', 'B', 'C']:
print('Put %s to queue...' % value)
q.put(value)
time.sleep(random.random())
# 读数据进程执行的代码:
def read(q):
print('Process to read: %s' % os.getpid())
while True:
value = q.get(True)
print('Get %s from queue.' % value)
if __name__=='__main__':
# 父进程创建 Queue,并传给各个子进程:
q = Queue()
pw = Process(target=write, args=(q,))
pr = Process(target=read, args=(q,))
# 启动子进程 pw,写入:
pw.start()
# 启动子进程 pr,读取:
pr.start()
# 等待 pw 结束:
pw.join()
# pr 进程里是死循环,无法等待其结束,只能强行终止:
pr.terminate()运行结果如下:
Process to write: 50563
Put A to queue...
Process to read: 50564
Get A from queue.
Put B to queue...
Get B from queue.
Put C to queue...
Get C from queue.在 Unix/Linux 下,multiprocessing 模块封装了 fork() 调用,使我们不需要关注 fork() 的细节。由于 Windows 没有 fork 调用,因此,multiprocessing 需要“模拟”出 fork 的效果,父进程所有 Python 对象都必须通过 pickle 序列化再传到子进程去,所以,如果 multiprocessing 在 Windows 下调用失败了,要先考虑是不是 pickle 失败了。
小结
在 Unix/Linux 下,可以使用 fork() 调用实现多进程。
要实现跨平台的多进程,可以使用 multiprocessing 模块。
进程间通信是通过 Queue、Pipes 等实现的。
多线程
多任务可以由多进程完成,也可以由一个进程内的多线程完成。
由于线程是操作系统直接支持的执行单元,因此,高级语言通常都内置多线程的支持,Python 也不例外,并且,Python 的线程是真正的 Posix Thread,而不是模拟出来的线程。
Python 的标准库提供了两个模块:_thread 和 threading,_thread 是低级模块,threading 是高级模块,对 _thread 进行了封装。绝大多数情况下,我们只需要使用 threading 这个高级模块。
启动一个线程就是把一个函数传入并创建 Thread 实例,然后调用 start() 开始执行:
import time, threading
# 新线程执行的代码:
def loop():
print('thread %s is running...' % threading.current_thread().name)
n = 0
while n < 5:
n = n + 1
print('thread %s >>> %s' % (threading.current_thread().name, n))
time.sleep(1)
print('thread %s ended.' % threading.current_thread().name)
print('thread %s is running...' % threading.current_thread().name)
t = threading.Thread(target=loop, name='LoopThread')
t.start()
t.join()
print('thread %s ended.' % threading.current_thread().name)由于任何进程默认就会启动一个线程,我们把该线程称为主线程,主线程又可以启动新的线程,Python 的 threading 模块有个 current_thread() 函数,它永远返回当前线程的实例。主线程实例的名字叫 MainThread,子线程的名字在创建时指定,我们用 LoopThread 命名子线程。名字仅仅在打印时用来显示,完全没有其他意义,如果不起名字 Python 就自动给线程命名为 Thread-1,Thread-2……
Lock
多线程和多进程最大的不同在于,多进程中,同一个变量,各自有一份拷贝存在于每个进程中,互不影响,而多线程中,所有变量都由所有线程共享,所以,任何一个变量都可以被任何一个线程修改,因此,线程之间共享数据最大的危险在于多个线程同时改一个变量,把内容给改乱了。
来看看多个线程同时操作一个变量怎么把内容给改乱了:
import time, threading
# 假定这是你的银行存款:
balance = 0
def change_it(n):
# 先存后取,结果应该为 0:
global balance
balance = balance + n
balance = balance - n
def run_thread(n):
for i in range(2000000):
change_it(n)
t1 = threading.Thread(target=run_thread, args=(5,))
t2 = threading.Thread(target=run_thread, args=(8,))
t1.start()
t2.start()
t1.join()
t2.join()
print(balance)我们定义了一个共享变量 balance,初始值为 0,并且启动两个线程,先存后取,理论上结果应该为 0,但是,由于线程的调度是由操作系统决定的,当 t1、t2 交替执行时,只要循环次数足够多,balance 的结果就不一定是 0 了。
原因是因为高级语言的一条语句在 CPU 执行时是若干条语句,即使一个简单的计算:
balance = balance + n也分两步:
- 计算 balance + n,存入临时变量中;
- 将临时变量的值赋给 balance。
也就是可以看成:
x = balance + n
balance = x由于 x 是局部变量,两个线程各自都有自己的 x,当代码正常执行时:
初始值 balance = 0
t1: x1 = balance + 5 # x1 = 0 + 5 = 5
t1: balance = x1 # balance = 5
t1: x1 = balance - 5 # x1 = 5 - 5 = 0
t1: balance = x1 # balance = 0
t2: x2 = balance + 8 # x2 = 0 + 8 = 8
t2: balance = x2 # balance = 8
t2: x2 = balance - 8 # x2 = 8 - 8 = 0
t2: balance = x2 # balance = 0
结果 balance = 0但是 t1 和 t2 是交替运行的,如果操作系统以下面的顺序执行 t1、t2:
初始值 balance = 0
t1: x1 = balance + 5 # x1 = 0 + 5 = 5
t2: x2 = balance + 8 # x2 = 0 + 8 = 8
t2: balance = x2 # balance = 8
t1: balance = x1 # balance = 5
t1: x1 = balance - 5 # x1 = 5 - 5 = 0
t1: balance = x1 # balance = 0
t2: x2 = balance - 8 # x2 = 0 - 8 = -8
t2: balance = x2 # balance = -8
结果 balance = -8究其原因,是因为修改 balance 需要多条语句,而执行这几条语句时,线程可能中断,从而导致多个线程把同一个对象的内容改乱了。
两个线程同时一存一取,就可能导致余额不对,你肯定不希望你的银行存款莫名其妙地变成了负数,所以,我们必须确保一个线程在修改 balance 的时候,别的线程一定不能改。
如果我们要确保 balance 计算正确,就要给 change_it() 上一把锁,当某个线程开始执行 change_it() 时,我们说,该线程因为获得了锁,因此其他线程不能同时执行 change_it(),只能等待,直到锁被释放后,获得该锁以后才能改。由于锁只有一个,无论多少线程,同一时刻最多只有一个线程持有该锁,所以,不会造成修改的冲突。创建一个锁就是通过 threading.Lock() 来实现:
balance = 0
lock = threading.Lock()
def run_thread(n):
for i in range(100000):
# 先要获取锁:
lock.acquire()
try:
# 放心地改吧:
change_it(n)
finally:
# 改完了一定要释放锁:
lock.release()当多个线程同时执行 lock.acquire() 时,只有一个线程能成功地获取锁,然后继续执行代码,其他线程就继续等待直到获得锁为止。
获得锁的线程用完后一定要释放锁,否则那些苦苦等待锁的线程将永远等待下去,成为死线程。所以我们用 try…finally 来确保锁一定会被释放。
锁的好处就是确保了某段关键代码只能由一个线程从头到尾完整地执行,坏处当然也很多,首先是阻止了多线程并发执行,包含锁的某段代码实际上只能以单线程模式执行,效率就大大地下降了。其次,由于可以存在多个锁,不同的线程持有不同的锁,并试图获取对方持有的锁时,可能会造成死锁,导致多个线程全部挂起,既不能执行,也无法结束,只能靠操作系统强制终止。
多核 CPU
如果你不幸拥有一个多核 CPU,你肯定在想,多核应该可以同时执行多个线程。
如果写一个死循环的话,会出现什么情况呢?
打开 Mac OS X 的 Activity Monitor,或者 Windows 的 Task Manager,都可以监控某个进程的 CPU 使用率。
我们可以监控到一个死循环线程会 100% 占用一个 CPU。
如果有两个死循环线程,在多核 CPU 中,可以监控到会占用 200% 的 CPU,也就是占用两个 CPU 核心。
要想把 N 核 CPU 的核心全部跑满,就必须启动 N 个死循环线程。
试试用 Python 写个死循环:
import threading, multiprocessing
def loop():
x = 0
while True:
x = x ^ 1
for i in range(multiprocessing.cpu_count()):
t = threading.Thread(target=loop)
t.start()启动与 CPU 核心数量相同的 N 个线程,在 4 核 CPU 上可以监控到 CPU 占用率仅有 102%,也就是仅使用了一核。
但是用 C、C++或 Java 来改写相同的死循环,直接可以把全部核心跑满,4 核就跑到 400%,8 核就跑到 800%,为什么 Python 不行呢?
因为 Python 的线程虽然是真正的线程,但解释器执行代码时,有一个 GIL 锁:Global Interpreter Lock,任何 Python 线程执行前,必须先获得 GIL 锁,然后,每执行 100 条字节码,解释器就自动释放 GIL 锁,让别的线程有机会执行。这个 GIL 全局锁实际上把所有线程的执行代码都给上了锁,所以,多线程在 Python 中只能交替执行,即使 100 个线程跑在 100 核 CPU 上,也只能用到 1 个核。
GIL 是 Python 解释器设计的历史遗留问题,通常我们用的解释器是官方实现的 CPython,要真正利用多核,除非重写一个不带 GIL 的解释器。
所以,在 Python 中,可以使用多线程,但不要指望能有效利用多核。如果一定要通过多线程利用多核,那只能通过 C 扩展来实现,不过这样就失去了 Python 简单易用的特点。
不过,也不用过于担心,Python 虽然不能利用多线程实现多核任务,但可以通过多进程实现多核任务。多个 Python 进程有各自独立的 GIL 锁,互不影响。
小结
多线程编程,模型复杂,容易发生冲突,必须用锁加以隔离,同时,又要小心死锁的发生。
Python 解释器由于设计时有 GIL 全局锁,导致了多线程无法利用多核。多线程的并发在 Python 中就是一个美丽的梦。
ThreadLocal
在多线程环境下,每个线程都有自己的数据。一个线程使用自己的局部变量比使用全局变量好,因为局部变量只有线程自己能看见,不会影响其他线程,而全局变量的修改必须加锁。
但是局部变量也有问题,就是在函数调用的时候,传递起来很麻烦:
def process_student(name):
std = Student(name)
# std 是局部变量,但是每个函数都要用它,因此必须传进去:
do_task_1(std)
do_task_2(std)
def do_task_1(std):
do_subtask_1(std)
do_subtask_2(std)
def do_task_2(std):
do_subtask_2(std)
do_subtask_2(std)每个函数一层一层调用都这么传参数那还得了?用全局变量?也不行,因为每个线程处理不同的 Student 对象,不能共享。
如果用一个全局 dict 存放所有的 Student 对象,然后以 thread 自身作为 key 获得线程对应的 Student 对象如何?
global_dict = {}
def std_thread(name):
std = Student(name)
# 把 std 放到全局变量 global_dict 中:
global_dict[threading.current_thread()] = std
do_task_1()
do_task_2()
def do_task_1():
# 不传入 std,而是根据当前线程查找:
std = global_dict[threading.current_thread()]
...
def do_task_2():
# 任何函数都可以查找出当前线程的 std 变量:
std = global_dict[threading.current_thread()]
...这种方式理论上是可行的,它最大的优点是消除了 std 对象在每层函数中的传递问题,但是,每个函数获取 std 的代码有点丑。
有没有更简单的方式?
ThreadLocal 应运而生,不用查找 dict,ThreadLocal 帮你自动做这件事:
import threading
# 创建全局 ThreadLocal 对象:
local_school = threading.local()
def process_student():
# 获取当前线程关联的 student:
std = local_school.student
print('Hello, %s (in %s)' % (std, threading.current_thread().name))
def process_thread(name):
# 绑定 ThreadLocal 的 student:
local_school.student = name
process_student()
t1 = threading.Thread(target=process_thread, args=('Alice',), name='Thread-A')
t2 = threading.Thread(target=process_thread, args=('Bob',), name='Thread-B')
t1.start()
t2.start()
t1.join()
t2.join()执行结果:
Hello, Alice (in Thread-A)
Hello, Bob (in Thread-B)全局变量 local_school 就是一个 ThreadLocal 对象,每个 Thread 对它都可以读写 student 属性,但互不影响。你可以把 local_school 看成全局变量,但每个属性如 local_school.student 都是线程的局部变量,可以任意读写而互不干扰,也不用管理锁的问题,ThreadLocal 内部会处理。
可以理解为全局变量 local_school 是一个 dict,不但可以用 local_school.student,还可以绑定其他变量,如 local_school.teacher 等等。
ThreadLocal 最常用的地方就是为每个线程绑定一个数据库连接,HTTP 请求,用户身份信息等,这样一个线程的所有调用到的处理函数都可以非常方便地访问这些资源。
小结
一个 ThreadLocal 变量虽然是全局变量,但每个线程都只能读写自己线程的独立副本,互不干扰。ThreadLocal 解决了参数在一个线程中各个函数之间互相传递的问题。
进程 vs 线程
首先,要实现多任务,通常我们会设计 Master-Worker 模式,Master 负责分配任务,Worker 负责执行任务,因此,多任务环境下,通常是一个 Master,多个 Worker。
- 如果用多进程实现 Master-Worker,主进程就是 Master,其他进程就是 Worker。
- 如果用多线程实现 Master-Worker,主线程就是 Master,其他线程就是 Worker。
多进程模式最大的优点就是稳定性高,因为一个子进程崩溃了,不会影响主进程和其他子进程。(当然主进程挂了所有进程就全挂了,但是 Master 进程只负责分配任务,挂掉的概率低)著名的 Apache 最早就是采用多进程模式。
多进程模式的缺点是创建进程的代价大,在 Unix/Linux 系统下,用 fork 调用还行,在 Windows 下创建进程开销巨大。另外,操作系统能同时运行的进程数也是有限的,在内存和 CPU 的限制下,如果有几千个进程同时运行,操作系统连调度都会成问题。
多线程模式通常比多进程快一点,但是也快不到哪去,而且,多线程模式致命的缺点就是任何一个线程挂掉都可能直接造成整个进程崩溃,因为所有线程共享进程的内存。在 Windows 上,如果一个线程执行的代码出了问题,你经常可以看到这样的提示:“该程序执行了非法操作,即将关闭”,其实往往是某个线程出了问题,但是操作系统会强制结束整个进程。
在 Windows 下,多线程的效率比多进程要高,所以微软的 IIS 服务器默认采用多线程模式。由于多线程存在稳定性的问题,IIS 的稳定性就不如 Apache。为了缓解这个问题,IIS 和 Apache 现在又有多进程+多线程的混合模式,真是把问题越搞越复杂。
线程切换
无论是多进程还是多线程,只要数量一多,效率肯定上不去,为什么呢?
我们打个比方,假设你不幸正在准备中考,每天晚上需要做语文、数学、英语、物理、化学这 5 科的作业,每项作业耗时 1 小时。
如果你先花 1 小时做语文作业,做完了,再花 1 小时做数学作业,这样,依次全部做完,一共花 5 小时,这种方式称为单任务模型,或者批处理任务模型。
假设你打算切换到多任务模型,可以先做 1 分钟语文,再切换到数学作业,做 1 分钟,再切换到英语,以此类推,只要切换速度足够快,这种方式就和单核 CPU 执行多任务是一样的了,以幼儿园小朋友的眼光来看,你就正在同时写 5 科作业。
但是,切换作业是有代价的,比如从语文切到数学,要先收拾桌子上的语文书本、钢笔(这叫保存现场),然后,打开数学课本、找出圆规直尺(这叫准备新环境),才能开始做数学作业。操作系统在切换进程或者线程时也是一样的,它需要先保存当前执行的现场环境(CPU 寄存器状态、内存页等),然后,把新任务的执行环境准备好(恢复上次的寄存器状态,切换内存页等),才能开始执行。这个切换过程虽然很快,但是也需要耗费时间。如果有几千个任务同时进行,操作系统可能就主要忙着切换任务,根本没有多少时间去执行任务了,这种情况最常见的就是硬盘狂响,点窗口无反应,系统处于假死状态。
所以,多任务一旦多到一个限度,就会消耗掉系统所有的资源,结果效率急剧下降,所有任务都做不好。
计算密集型 vs IO 密集型
是否采用多任务的第二个考虑是任务的类型。我们可以把任务分为计算密集型和 IO 密集型。
计算密集型任务的特点是要进行大量的计算,消耗 CPU 资源,比如计算圆周率、对视频进行高清解码等等,全靠 CPU 的运算能力。这种计算密集型任务虽然也可以用多任务完成,但是任务越多,花在任务切换的时间就越多,CPU 执行任务的效率就越低,所以,要最高效地利用 CPU,计算密集型任务同时进行的数量应当等于 CPU 的核心数。
计算密集型任务由于主要消耗 CPU 资源,因此,代码运行效率至关重要。Python 这样的脚本语言运行效率很低,完全不适合计算密集型任务。对于计算密集型任务,最好用 C 语言编写。
第二种任务的类型是 IO 密集型,涉及到网络、磁盘 IO 的任务都是 IO 密集型任务,这类任务的特点是 CPU 消耗很少,任务的大部分时间都在等待 IO 操作完成(因为 IO 的速度远远低于 CPU 和内存的速度)。对于 IO 密集型任务,任务越多,CPU 效率越高,但也有一个限度。常见的大部分任务都是 IO 密集型任务,比如 Web 应用。
IO 密集型任务执行期间,99% 的时间都花在 IO 上,花在 CPU 上的时间很少,因此,用运行速度极快的 C 语言替换用 Python 这样运行速度极低的脚本语言,完全无法提升运行效率。对于 IO 密集型任务,最合适的语言就是开发效率最高(代码量最少)的语言,脚本语言是首选,C 语言最差。
异步 IO
考虑到 CPU 和 IO 之间巨大的速度差异,一个任务在执行的过程中大部分时间都在等待 IO 操作,单进程单线程模型会导致别的任务无法并行执行,因此,我们才需要多进程模型或者多线程模型来支持多任务并发执行。
现代操作系统对 IO 操作已经做了巨大的改进,最大的特点就是支持异步 IO。如果充分利用操作系统提供的异步 IO 支持,就可以用单进程单线程模型来执行多任务,这种全新的模型称为事件驱动模型,Nginx 就是支持异步 IO 的 Web 服务器,它在单核 CPU 上采用单进程模型就可以高效地支持多任务。在多核 CPU 上,可以运行多个进程(数量与 CPU 核心数相同),充分利用多核 CPU。由于系统总的进程数量十分有限,因此操作系统调度非常高效。用异步 IO 编程模型来实现多任务是一个主要的趋势。
对应到 Python 语言,单线程的异步编程模型称为协程,有了协程的支持,就可以基于事件驱动编写高效的多任务程序。我们会在后面讨论如何编写协程。
分布式进程
在 Thread 和 Process 中,应当优选 Process,因为 Process 更稳定,而且,Process 可以分布到多台机器上,而 Thread 最多只能分布到同一台机器的多个 CPU 上。
Python 的 multiprocessing 模块不但支持多进程,其中 managers 子模块还支持把多进程分布到多台机器上。一个服务进程可以作为调度者,将任务分布到其他多个进程中,依靠网络通信。由于 managers 模块封装很好,不必了解网络通信的细节,就可以很容易地编写分布式多进程程序。
举个例子:如果我们已经有一个通过 Queue 通信的多进程程序在同一台机器上运行,现在,由于处理任务的进程任务繁重,希望把发送任务的进程和处理任务的进程分布到两台机器上。怎么用分布式进程实现?
原有的 Queue 可以继续使用,但是,通过 managers 模块把 Queue 通过网络暴露出去,就可以让其他机器的进程访问 Queue 了。
我们先看服务进程,服务进程负责启动 Queue,把 Queue 注册到网络上,然后往 Queue 里面写入任务:
# task_master.py
import random, time, queue
from multiprocessing.managers import BaseManager
# 发送任务的队列:
task_queue = queue.Queue()
# 接收结果的队列:
result_queue = queue.Queue()
# 从 BaseManager 继承的 QueueManager:
class QueueManager(BaseManager):
pass
# 把两个 Queue 都注册到网络上, callable 参数关联了 Queue 对象:
QueueManager.register('get_task_queue', callable=lambda: task_queue)
QueueManager.register('get_result_queue', callable=lambda: result_queue)
# 绑定端口 5000, 设置验证码 'abc':
manager = QueueManager(address=('', 5000), authkey=b'abc')
# 启动 Queue:
manager.start()
# 获得通过网络访问的 Queue 对象:
task = manager.get_task_queue()
result = manager.get_result_queue()
# 放几个任务进去:
for i in range(10):
n = random.randint(0, 10000)
print('Put task %d...' % n)
task.put(n)
# 从 result 队列读取结果:
print('Try get results...')
for i in range(10):
r = result.get(timeout=10)
print('Result: %s' % r)
# 关闭:
manager.shutdown()
print('master exit.')请注意,当我们在一台机器上写多进程程序时,创建的 Queue 可以直接拿来用,但是,在分布式多进程环境下,添加任务到 Queue 不可以直接对原始的 task_queue 进行操作,那样就绕过了 QueueManager 的封装,必须通过 manager.get_task_queue() 获得的 Queue 接口添加。
然后,在另一台机器上启动任务进程(本机上启动也可以):
# task_worker.py
import time, sys, queue
from multiprocessing.managers import BaseManager
# 创建类似的 QueueManager:
class QueueManager(BaseManager):
pass
# 由于这个 QueueManager 只从网络上获取 Queue,所以注册时只提供名字:
QueueManager.register('get_task_queue')
QueueManager.register('get_result_queue')
# 连接到服务器,也就是运行 task_master.py 的机器:
server_addr = '127.0.0.1'
print('Connect to server %s...' % server_addr)
# 端口和验证码注意保持与 task_master.py 设置的完全一致:
m = QueueManager(address=(server_addr, 5000), authkey=b'abc')
# 从网络连接:
m.connect()
# 获取 Queue 的对象:
task = m.get_task_queue()
result = m.get_result_queue()
# 从 task 队列取任务,并把结果写入 result 队列:
for i in range(10):
try:
n = task.get(timeout=1)
print('run task %d * %d...' % (n, n))
r = '%d * %d = %d' % (n, n, n*n)
time.sleep(1)
result.put(r)
except Queue.Empty:
print('task queue is empty.')
# 处理结束:
print('worker exit.')任务进程要通过网络连接到服务进程,所以要指定服务进程的 IP。
现在,可以试试分布式进程的工作效果了。先启动 task_master.py 服务进程:
$ python3 task_master.py
Put task 3411...
Put task 1605...
Put task 1398...
Put task 4729...
Put task 5300...
Put task 7471...
Put task 68...
Put task 4219...
Put task 339...
Put task 7866...
Try get results...task_master.py 进程发送完任务后,开始等待 result 队列的结果。现在启动 task_worker.py 进程:
$ python3 task_worker.py
Connect to server 127.0.0.1...
run task 3411 * 3411...
run task 1605 * 1605...
run task 1398 * 1398...
run task 4729 * 4729...
run task 5300 * 5300...
run task 7471 * 7471...
run task 68 * 68...
run task 4219 * 4219...
run task 339 * 339...
run task 7866 * 7866...
worker exit.task_worker.py 进程结束,在 task_master.py 进程中会继续打印出结果:
Result: 3411 * 3411 = 11634921
Result: 1605 * 1605 = 2576025
Result: 1398 * 1398 = 1954404
Result: 4729 * 4729 = 22363441
Result: 5300 * 5300 = 28090000
Result: 7471 * 7471 = 55815841
Result: 68 * 68 = 4624
Result: 4219 * 4219 = 17799961
Result: 339 * 339 = 114921
Result: 7866 * 7866 = 61873956这个简单的 Master/Worker 模型有什么用?其实这就是一个简单但真正的分布式计算,把代码稍加改造,启动多个 worker,就可以把任务分布到几台甚至几十台机器上,比如把计算 n*n 的代码换成发送邮件,就实现了邮件队列的异步发送。
Queue 对象存储在哪?注意到 task_worker.py 中根本没有创建 Queue 的代码,所以,Queue 对象存储在 task_master.py 进程中:
│
┌─────────────────────────────────────────┐ ┌──────────────────────────────────────┐
│task_master.py │ │ │task_worker.py │
│ │ │ │
│ task = manager.get_task_queue() │ │ │ task = manager.get_task_queue() │
│ result = manager.get_result_queue() │ │ result = manager.get_result_queue() │
│ │ │ │ │ │ │
│ │ │ │ │ │
│ ▼ │ │ │ │ │
│ ┌─────────────────────────────────┐ │ │ │ │
│ │QueueManager │ │ │ │ │ │
│ │ ┌────────────┐ ┌──────────────┐ │ │ │ │ │
│ │ │ task_queue │ │ result_queue │ │<───┼──┼──┼──────────────┘ │
│ │ └────────────┘ └──────────────┘ │ │ │ │
│ └─────────────────────────────────┘ │ │ │ │
└─────────────────────────────────────────┘ └──────────────────────────────────────┘
│
Network而 Queue 之所以能通过网络访问,就是通过 QueueManager 实现的。由于 QueueManager 管理的不止一个 Queue,所以,要给每个 Queue 的网络调用接口起个名字,比如 get_task_queue。
authkey 有什么用?这是为了保证两台机器正常通信,不被其他机器恶意干扰。如果 task_worker.py 的 authkey 和 task_master.py 的 authkey 不一致,肯定连接不上。
小结
Python 的分布式进程接口简单,封装良好,适合需要把繁重任务分布到多台机器的环境下。
注意 Queue 的作用是用来传递任务和接收结果,每个任务的描述数据量要尽量小。比如发送一个处理日志文件的任务,就不要发送几百兆的日志文件本身,而是发送日志文件存放的完整路径,由 Worker 进程再去共享的磁盘上读取文件。
正则表达式
re 模块
Python 提供 re 模块,包含所有正则表达式的功能。由于 Python 的字符串本身也用 \ 转义,所以要特别注意:
s = 'ABC\\-001' # Python 的字符串
# 对应的正则表达式字符串变成:
# 'ABC\-001'因此我们强烈建议使用 Python 的 r 前缀,就不用考虑转义的问题了:
s = r'ABC\-001' # Python 的字符串
# 对应的正则表达式字符串不变:
# 'ABC\-001'先看看如何判断正则表达式是否匹配:
>>> import re
>>> re.match(r'^\d{3}\-\d{3,8}$', '010-12345')
<_sre.SRE_Match object; span=(0, 9), match='010-12345'>
>>> re.match(r'^\d{3}\-\d{3,8}$', '010 12345')
>>>match() 方法判断是否匹配,如果匹配成功,返回一个 Match 对象,否则返回 None。常见的判断方法就是:
test = '用户输入的字符串'
if re.match(r'正则表达式', test):
print('ok')
else:
print('failed')切分字符串
用正则表达式切分字符串比用固定的字符更灵活,请看正常的切分代码:
>>> 'a b c'.split(' ')
['a', 'b', '', '', 'c']嗯,无法识别连续的空格,用正则表达式试试:
>>> re.split(r'\s+', 'a b c')
['a', 'b', 'c']无论多少个空格都可以正常分割。加入 , 试试:
>>> re.split(r'[\s\,]+', 'a,b, c d')
['a', 'b', 'c', 'd']再加入 ; 试试:
>>> re.split(r'[\s\,\;]+', 'a,b;; c d')
['a', 'b', 'c', 'd']如果用户输入了一组标签,下次记得用正则表达式来把不规范的输入转化成正确的数组。
分组
除了简单地判断是否匹配之外,正则表达式还有提取子串的强大功能。用 () 表示的就是要提取的分组(Group)。比如:
^(\d{3})-(\d{3,8})$ 分别定义了两个组,可以直接从匹配的字符串中提取出区号和本地号码:
>>> m = re.match(r'^(\d{3})-(\d{3,8})$', '010-12345')
>>> m
<_sre.SRE_Match object; span=(0, 9), match='010-12345'>
>>> m.group(0)
'010-12345'
>>> m.group(1)
'010'
>>> m.group(2)
'12345'如果正则表达式中定义了组,就可以在 Match 对象上用 group() 方法提取出子串来。
注意到 group(0) 永远是与整个正则表达式相匹配的字符串,group(1)、group(2)…… 表示第 1、2、…… 个子串。
提取子串非常有用。来看一个更凶残的例子:
>>> t = '19:05:30'
>>> m = re.match(r'^(0[0-9]|1[0-9]|2[0-3]|[0-9])\:(0[0-9]|1[0-9]|2[0-9]|3[0-9]|4[0-9]|5[0-9]|[0-9])\:(0[0-9]|1[0-9]|2[0-9]|3[0-9]|4[0-9]|5[0-9]|[0-9])$', t)
>>> m.groups()
('19', '05', '30')这个正则表达式可以直接识别合法的时间。但是有些时候,用正则表达式也无法做到完全验证,比如识别日期:
'^(0[1-9]|1[0-2]|[0-9])-(0[1-9]|1[0-9]|2[0-9]|3[0-1]|[0-9])$'对于 ‘2-30’,‘4-31’ 这样的非法日期,用正则还是识别不了,或者说写出来非常困难,这时就需要程序配合识别了。
贪婪匹配
最后需要特别指出的是,正则匹配默认是贪婪匹配,也就是匹配尽可能多的字符。举例如下,匹配出数字后面的 0:
>>> re.match(r'^(\d+)(0*)$', '102300').groups()
('102300', '')由于 \d+ 采用贪婪匹配,直接把后面的 0 全部匹配了,结果 0* 只能匹配空字符串了。
必须让 \d+ 采用非贪婪匹配(也就是尽可能少匹配),才能把后面的 0 匹配出来,加个 ? 就可以让 \d+ 采用非贪婪匹配:
>>> re.match(r'^(\d+?)(0*)$', '102300').groups()
('1023', '00')编译
当我们在 Python 中使用正则表达式时,re 模块内部会干两件事情:
- 编译正则表达式,如果正则表达式的字符串本身不合法,会报错;
- 用编译后的正则表达式去匹配字符串。
如果一个正则表达式要重复使用几千次,出于效率的考虑,我们可以预编译该正则表达式,接下来重复使用时就不需要编译这个步骤了,直接匹配:
>>> import re
# 编译:
>>> re_telephone = re.compile(r'^(\d{3})-(\d{3,8})$')
# 使用:
>>> re_telephone.match('010-12345').groups()
('010', '12345')
>>> re_telephone.match('010-8086').groups()
('010', '8086')编译后生成 Regular Expression 对象,由于该对象自己包含了正则表达式,所以调用对应的方法时不用给出正则字符串。
小结
正则表达式非常强大,要在短短的一节里讲完是不可能的。要讲清楚正则的所有内容,可以写一本厚厚的书了。如果你经常遇到正则表达式的问题,你可能需要一本正则表达式的参考书。
virtualenv
virtualenv 就是用来为一个应用创建一套“隔离”的 Python 运行环境。
首先,我们用 pip 安装 virtualenv:
$ pip3 install virtualenv然后,假定我们要开发一个新的项目,需要一套独立的 Python 运行环境,可以这么做:
第一步,创建目录:
Mac:~ michael$ mkdir myproject
Mac:~ michael$ cd myproject/
Mac:myproject michael$第二步,创建一个独立的 Python 运行环境,命名为 venv:
Mac:myproject michael$ virtualenv --no-site-packages venv
Using base prefix '/usr/local/.../Python.framework/Versions/3.4'
New python executable in venv/bin/python3.4
Also creating executable in venv/bin/python
Installing setuptools, pip, wheel...done.命令 virtualenv 就可以创建一个独立的 Python 运行环境,我们还加上了参数 —no-site-packages,这样,已经安装到系统 Python 环境中的所有第三方包都不会复制过来,这样,我们就得到了一个不带任何第三方包的“干净”的 Python 运行环境。
新建的 Python 环境被放到当前目录下的 venv 目录。有了 venv 这个 Python 环境,可以用 source 进入该环境:
Mac:myproject michael$ source venv/bin/activate
(venv)Mac:myproject michael$注意到命令提示符变了,有个 (venv) 前缀,表示当前环境是一个名为 venv 的 Python 环境。
下面正常安装各种第三方包,并运行 python 命令:
(venv)Mac:myproject michael$ pip install jinja2
...
Successfully installed jinja2-2.7.3 markupsafe-0.23
(venv)Mac:myproject michael$ python myapp.py
...在 venv 环境下,用 pip 安装的包都被安装到 venv 这个环境下,系统 Python 环境不受任何影响。也就是说,venv 环境是专门针对 myproject 这个应用创建的。
退出当前的 venv 环境,使用 deactivate 命令:
(venv)Mac:myproject michael$ deactivate
Mac:myproject michael$此时就回到了正常的环境,现在 pip 或 python 均是在系统 Python 环境下执行。
完全可以针对每个应用创建独立的 Python 运行环境,这样就可以对每个应用的 Python 环境进行隔离。
virtualenv 是如何创建“独立”的 Python 运行环境的呢?原理很简单,就是把系统 Python 复制一份到 virtualenv 的环境,用命令 source venv/bin/activate 进入一个 virtualenv 环境时,virtualenv 会修改相关环境变量,让命令 python 和 pip 均指向当前的 virtualenv 环境。
小结
virtualenv 为应用提供了隔离的 Python 运行环境,解决了不同应用间多版本的冲突问题。
异步 IO
在 IO 编程一节中,我们已经知道,CPU 的速度远远快于磁盘、网络等 IO。在一个线程中,CPU 执行代码的速度极快,然而,一旦遇到 IO 操作,如读写文件、发送网络数据时,就需要等待 IO 操作完成,才能继续进行下一步操作。这种情况称为同步 IO。
在 IO 操作的过程中,当前线程被挂起,而其他需要 CPU 执行的代码就无法被当前线程执行了。
因为一个 IO 操作就阻塞了当前线程,导致其他代码无法执行,所以我们必须使用多线程或者多进程来并发执行代码,为多个用户服务。每个用户都会分配一个线程,如果遇到 IO 导致线程被挂起,其他用户的线程不受影响。
多线程和多进程的模型虽然解决了并发问题,但是系统不能无上限地增加线程。由于系统切换线程的开销也很大,所以,一旦线程数量过多,CPU 的时间就花在线程切换上了,真正运行代码的时间就少了,结果导致性能严重下降。
由于我们要解决的问题是 CPU 高速执行能力和 IO 设备的龟速严重不匹配,多线程和多进程只是解决这一问题的一种方法。
另一种解决 IO 问题的方法是异步 IO。当代码需要执行一个耗时的 IO 操作时,它只发出 IO 指令,并不等待 IO 结果,然后就去执行其他代码了。一段时间后,当 IO 返回结果时,再通知 CPU 进行处理。
可以想象如果按普通顺序写出的代码实际上是没法完成异步 IO 的:
do_some_code()
f = open('/path/to/file', 'r')
r = f.read() # <== 线程停在此处等待 IO 操作结果
# IO 操作完成后线程才能继续执行:
do_some_code(r)所以,同步 IO 模型的代码是无法实现异步 IO 模型的。
异步 IO 模型需要一个消息循环,在消息循环中,主线程不断地重复“读取消息-处理消息”这一过程:
loop = get_event_loop()
while True:
event = loop.get_event()
process_event(event)消息模型其实早在应用在桌面应用程序中了。一个 GUI 程序的主线程就负责不停地读取消息并处理消息。所有的键盘、鼠标等消息都被发送到 GUI 程序的消息队列中,然后由 GUI 程序的主线程处理。
由于 GUI 线程处理键盘、鼠标等消息的速度非常快,所以用户感觉不到延迟。某些时候,GUI 线程在一个消息处理的过程中遇到问题导致一次消息处理时间过长,此时,用户会感觉到整个 GUI 程序停止响应了,敲键盘、点鼠标都没有反应。这种情况说明在消息模型中,处理一个消息必须非常迅速,否则,主线程将无法及时处理消息队列中的其他消息,导致程序看上去停止响应。
消息模型是如何解决同步 IO 必须等待 IO 操作这一问题的呢?当遇到 IO 操作时,代码只负责发出 IO 请求,不等待 IO 结果,然后直接结束本轮消息处理,进入下一轮消息处理过程。当 IO 操作完成后,将收到一条“IO 完成”的消息,处理该消息时就可以直接获取 IO 操作结果。
在“发出 IO 请求”到收到“IO 完成”的这段时间里,同步 IO 模型下,主线程只能挂起,但异步 IO 模型下,主线程并没有休息,而是在消息循环中继续处理其他消息。这样,在异步 IO 模型下,一个线程就可以同时处理多个 IO 请求,并且没有切换线程的操作。对于大多数 IO 密集型的应用程序,使用异步 IO 将大大提升系统的多任务处理能力。
协程
在学习异步 IO 模型前,我们先来了解协程。
协程,又称微线程,纤程。英文名 Coroutine。
协程的概念很早就提出来了,但直到最近几年才在某些语言(如 Lua)中得到广泛应用。
子程序,或者称为函数,在所有语言中都是层级调用,比如 A 调用 B,B 在执行过程中又调用了 C,C 执行完毕返回,B 执行完毕返回,最后是 A 执行完毕。
所以子程序调用是通过栈实现的,一个线程就是执行一个子程序。
子程序调用总是一个入口,一次返回,调用顺序是明确的。而协程的调用和子程序不同。
协程看上去也是子程序,但执行过程中,在子程序内部可中断,然后转而执行别的子程序,在适当的时候再返回来接着执行。
注意,在一个子程序中中断,去执行其他子程序,不是函数调用,有点类似 CPU 的中断。比如子程序 A、B:
def A():
print('1')
print('2')
print('3')
def B():
print('x')
print('y')
print('z')假设由协程执行,在执行 A 的过程中,可以随时中断,去执行 B,B 也可能在执行过程中中断再去执行 A,结果可能是:
1
2
x
y
3
z但是在 A 中是没有调用 B 的,所以协程的调用比函数调用理解起来要难一些。
看起来 A、B 的执行有点像多线程,但协程的特点在于是一个线程执行,那和多线程比,协程有何优势?
- 最大的优势就是协程极高的执行效率。因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显。
- 第二大优势就是不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。
因为协程是一个线程执行,那怎么利用多核 CPU 呢?最简单的方法是多进程+协程,既充分利用多核,又充分发挥协程的高效率,可获得极高的性能。
Python 对协程的支持是通过 generator 实现的。
在 generator 中,我们不但可以通过 for 循环来迭代,还可以不断调用 next() 函数获取由 yield 语句返回的下一个值。
但是 Python 的 yield 不但可以返回一个值,它还可以接收调用者发出的参数。
来看例子:
传统的生产者-消费者模型是一个线程写消息,一个线程取消息,通过锁机制控制队列和等待,但一不小心就可能死锁。
如果改用协程,生产者生产消息后,直接通过 yield 跳转到消费者开始执行,待消费者执行完毕后,切换回生产者继续生产,效率极高:
def consumer():
r = ''
while True:
n = yield r
if not n:
return
print('[CONSUMER] Consuming %s...' % n)
r = '200 OK'
def produce(c):
c.send(None)
n = 0
while n < 5:
n = n + 1
print('[PRODUCER] Producing %s...' % n)
r = c.send(n)
print('[PRODUCER] Consumer return: %s' % r)
c.close()
c = consumer()
produce(c)执行结果:
[PRODUCER] Producing 1...
[CONSUMER] Consuming 1...
[PRODUCER] Consumer return: 200 OK
[PRODUCER] Producing 2...
[CONSUMER] Consuming 2...
[PRODUCER] Consumer return: 200 OK
[PRODUCER] Producing 3...
[CONSUMER] Consuming 3...
[PRODUCER] Consumer return: 200 OK
[PRODUCER] Producing 4...
[CONSUMER] Consuming 4...
[PRODUCER] Consumer return: 200 OK
[PRODUCER] Producing 5...
[CONSUMER] Consuming 5...
[PRODUCER] Consumer return: 200 OK注意到 consumer 函数是一个 generator,把一个 consumer 传入 produce 后:
- 首先调用 c.send(None) 启动生成器;
- 然后,一旦生产了东西,通过 c.send(n) 切换到 consumer 执行;
- consumer 通过 yield 拿到消息处理,又通过 yield 把结果传回;
- produce 拿到 consumer 处理的结果,继续生产下一条消息;
- produce 决定不生产了,通过 c.close() 关闭 consumer,整个过程结束。
整个流程无锁,由一个线程执行,produce 和 consumer 协作完成任务,所以称为“协程”,而非线程的抢占式多任务。
最后套用 Donald Knuth 的一句话总结协程的特点:
“子程序就是协程的一种特例。”
asyncio
asyncio 是 Python 3.4 版本引入的标准库,直接内置了对异步 IO 的支持。
asyncio 的编程模型就是一个消息循环。我们从 asyncio 模块中直接获取一个 EventLoop 的引用,然后把需要执行的协程扔到 EventLoop 中执行,就实现了异步 IO。
用 asyncio 实现 Hello world 代码如下:
import asyncio
@asyncio.coroutine
def hello():
print("Hello world!")
# 异步调用 asyncio.sleep(1):
r = yield from asyncio.sleep(1)
print("Hello again!")
# 获取 EventLoop:
loop = asyncio.get_event_loop()
# 执行 coroutine
loop.run_until_complete(hello())
loop.close()@asyncio.coroutine 把一个 generator 标记为 coroutine 类型,然后,我们就把这个 coroutine 扔到 EventLoop 中执行。
hello() 会首先打印出 Hello world!,然后,yield from 语法可以让我们方便地调用另一个 generator。由于 asyncio.sleep() 也是一个 coroutine,所以线程不会等待 asyncio.sleep(),而是直接中断并执行下一个消息循环。当 asyncio.sleep() 返回时,线程就可以从 yield from 拿到返回值(此处是 None),然后接着执行下一行语句。
把 asyncio.sleep(1) 看成是一个耗时 1 秒的 IO 操作,在此期间,主线程并未等待,而是去执行 EventLoop 中其他可以执行的 coroutine 了,因此可以实现并发执行。
我们用 Task 封装两个 coroutine 试试:
import threading
import asyncio
@asyncio.coroutine
def hello():
print('Hello world! (%s)' % threading.currentThread())
yield from asyncio.sleep(1)
print('Hello again! (%s)' % threading.currentThread())
loop = asyncio.get_event_loop()
tasks = [hello(), hello()]
loop.run_until_complete(asyncio.wait(tasks))
loop.close()观察执行过程:
Hello world! (<_MainThread(MainThread, started 140735195337472)>)
Hello world! (<_MainThread(MainThread, started 140735195337472)>)
(暂停约1秒)
Hello again! (<_MainThread(MainThread, started 140735195337472)>)
Hello again! (<_MainThread(MainThread, started 140735195337472)>)由打印的当前线程名称可以看出,两个 coroutine 是由同一个线程并发执行的。
如果把 asyncio.sleep() 换成真正的 IO 操作,则多个 coroutine 就可以由一个线程并发执行。
我们用 asyncio 的异步网络连接来获取 sina、sohu 和 163 的网站首页:
import asyncio
@asyncio.coroutine
def wget(host):
print('wget %s...' % host)
connect = asyncio.open_connection(host, 80)
reader, writer = yield from connect
header = 'GET / HTTP/1.0\r\nHost: %s\r\n\r\n' % host
writer.write(header.encode('utf-8'))
yield from writer.drain()
while True:
line = yield from reader.readline()
if line == b'\r\n':
break
print('%s header > %s' % (host, line.decode('utf-8').rstrip()))
# Ignore the body, close the socket
writer.close()
loop = asyncio.get_event_loop()
tasks = [wget(host) for host in ['www.sina.com.cn', 'www.sohu.com', 'www.163.com']]
loop.run_until_complete(asyncio.wait(tasks))
loop.close()执行结果如下:
wget www.sohu.com...
wget www.sina.com.cn...
wget www.163.com...
(等待一段时间)
(打印出sohu的header)
www.sohu.com header > HTTP/1.1 200 OK
www.sohu.com header > Content-Type: text/html
...
(打印出sina的header)
www.sina.com.cn header > HTTP/1.1 200 OK
www.sina.com.cn header > Date: Wed, 20 May 2015 04:56:33 GMT
...
(打印出163的header)
www.163.com header > HTTP/1.0 302 Moved Temporarily
www.163.com header > Server: Cdn Cache Server V2.0
...可见 3 个连接由一个线程通过 coroutine 并发完成。
小结
asyncio 提供了完善的异步 IO 支持;
异步操作需要在 coroutine 中通过 yield from 完成;
多个 coroutine 可以封装成一组 Task 然后并发执行。
async / await
用 asyncio 提供的 @asyncio.coroutine 可以把一个 generator 标记为 coroutine 类型,然后在 coroutine 内部用 yield from 调用另一个 coroutine 实现异步操作。
为了简化并更好地标识异步 IO,从 Python 3.5 开始引入了新的语法 async 和 await,可以让 coroutine 的代码更简洁易读。
请注意,async 和 await 是针对 coroutine 的新语法,要使用新的语法,只需要做两步简单的替换:
- 把
@asyncio.coroutine替换为 async; - 把 yield from 替换为 await。
让我们对比一下上一节的代码:
@asyncio.coroutine
def hello():
print("Hello world!")
r = yield from asyncio.sleep(1)
print("Hello again!")用新语法重新编写如下:
async def hello():
print("Hello world!")
r = await asyncio.sleep(1)
print("Hello again!")剩下的代码保持不变。
小结
Python 从 3.5 版本开始为 asyncio 提供了 async 和 await 的新语法;
注意新语法只能用在 Python 3.5 以及后续版本,如果使用 3.4 版本,则仍需使用上一节的方案。
aiohttp
asyncio 可以实现单线程并发 IO 操作。如果仅用在客户端,发挥的威力不大。如果把 asyncio 用在服务器端,例如 Web 服务器,由于 HTTP 连接就是 IO 操作,因此可以用单线程 + coroutine 实现多用户的高并发支持。
asyncio 实现了 TCP、UDP、SSL 等协议,aiohttp 则是基于 asyncio 实现的 HTTP 框架。
我们先安装 aiohttp:
pip install aiohttp然后编写一个 HTTP 服务器,分别处理以下 URL:
/- 首页返回b'<h1>Index</h1>';/hello/{name}- 根据 URL 参数返回文本hello, %s!。
代码如下:
import asyncio
from aiohttp import web
async def index(request):
await asyncio.sleep(0.5)
return web.Response(body=b'<h1>Index</h1>')
async def hello(request):
await asyncio.sleep(0.5)
text = '<h1>hello, %s!</h1>' % request.match_info['name']
return web.Response(body=text.encode('utf-8'))
async def init(loop):
app = web.Application(loop=loop)
app.router.add_route('GET', '/', index)
app.router.add_route('GET', '/hello/{name}', hello)
srv = await loop.create_server(app.make_handler(), '127.0.0.1', 8000)
print('Server started at http://127.0.0.1:8000...')
return srv
loop = asyncio.get_event_loop()
loop.run_until_complete(init(loop))
loop.run_forever()注意 aiohttp 的初始化函数 init() 也是一个 coroutine,loop.create_server() 则利用 asyncio 创建 TCP 服务。
// TODO Python 入门学习待完成