JS 基础问题
简述
与前端 Js 不同, 后端方面除了 SSR/爬虫之外很少会接触 DOM, 所以关于 DOM 方面的各种知识基本不会讨论.浏览器端除了图形业务外很少碰到内存问题, 但是后端几乎是直面服务器内存的, 更加偏向内存方面, 对于一些更基础的问题也会更加关注.
类型判断
看 lodash
作用域
看《你不知道的 js》
引用传递
js 中什么类型是引用传递, 什么类型是值传递? 如何将值类型的变量以引用的方式传递?
简单点说, 对象是引用传递, 基础类型是值传递, 通过将基础类型包装 (boxing) 可以以引用的方式传递.
引用传递和值传递是一个非常简单的问题, 也是理解 JavaScript 中的内存方面问题的一个基础. 如果不了解引用可能很难去看很多问题.
面试写代码的话, 可以通过 如何编写一个 json 对象的拷贝函数 等类似的问题来考察对引用的了解. 不过笔者偶尔会有恶趣味, 喜欢先问应聘者对于 == 的 === 的区别的了解. 然后再问 [1] == [1] 是 true 还是 false. 如果基础不好的同学可能会被自己对于 == 和 === 的结论影响然后得出错误的结论.
对于技术好的, 希望能直接反驳这个问题本身是有问题的, 比如讲清楚 JavaScript 中没有引用传递只是传递引用. 参见 Is JavaScript a pass-by-reference or pass-by-value language?. 虽然说是复杂版, 但是这些知识对于 3 年经验的同学真的应该是很简单的问题了.
另外如果简历中有写 C++, 则必问 指针与引用的区别.
内存释放
JavaScript 中不同类型以及不同环境下变量的内存都是何时释放?
引用类型是在没有引用之后, 通过 v8 的 GC 自动回收, 值类型如果是处于闭包的情况下, 要等闭包没有引用才会被 GC 回收, 非闭包的情况下等待 v8 的新生代 (new space) 切换的时候回收.
与前端 Js 不同, 2 年以上经验的 Node.js 一定要开始注意内存了, 不说对 v8 的 GC 有多了解, 基础的内存释放一定有概念了, 并且要开始注意内存泄漏的问题了.
你需要了解哪些操作一定会导致内存泄漏, 或者可以崩掉内存. 比如如下代码能否爆掉 V8 的内存?
let arr = [];
while (true) arr.push(1);然后上述代码与下方的情况有什么区别?
let arr = [];
while (true) arr.push();如果 push 的是 Buffer 情况又会有什么区别?
let arr = [];
while (true) arr.push(new Buffer(1000));思考完之后可以尝试找找别的情况如何爆掉 V8 的内存. 以及来聊聊内存泄漏?
function out() {
const bigData = new Buffer(100);
inner = function() {
void bigData;
};
}闭包会引用到父级函数中的变量,如果闭包未释放,就会导致内存泄漏。上面例子是 inner 直接挂在了 root 上,从而导致内存泄漏(bigData 不会释放)。详见 如何分析 Node.js 中的内存泄漏
对于一些高水平的同学, 要求能清楚的了解 V8 内存 GC 的机制, 懂得内存快照等 (之后会在调试/优化的小结中讨论) 了. 比如 V8 中不同类型的数据存储的位置, 在内存释放的时候不同区域的不同策略等等.
ES6 新特性
看阮一峰的 ECMAScript 6 入门
比较简单的会问 let 与 var 的区别, 以及 箭头函数 与 function 的区别等等.
深入的话, es6 有太多细节可以深入了. 比如结合 引用 的知识点来询问 const 方面的知识. 结合 {} 的使用与缺点来谈 Set, Map 等. 比如私有化的问题与 symbol 等等.
其他像是闭包是什么? 这种问烂了问题已经感觉没必要问了, 取而代之的是询问闭包应用的场景更加合理. 比如说, 如果回答者通常使用闭包实现数据的私有, 那么可以接着问 es6 的一些新特性 (例如 class, symbol) 能否实现私有, 如果能的话那为什么要用闭包? 亦或者是什么闭包中的数据/私有化的数据的内存什么时候释放? 等等.
... 的使用上, 如何实现一个数组的去重 (使用 Set 可以加分).
const 定义的 Array 中间元素能否被修改? 如果可以, 那 const 修饰对象有什么意义?
其中的值可以被修改. 意义上, 主要保护引用不被修改 (如用 Map 等接口对引用的变化很敏感, 使用 const 保护引用始终如一是有意义的), 也适合用在 immutable 的场景.
模块
常见问题
如何在不重启 node 进程的情况下热更新一个 js/json 文件? 这个问题本身是否有问题?
可以清除掉 require.cache 的缓存重新 require(xxx), 视具体情况还可以用 VM 模块重新执行.
当然这个问题可能是典型的 X-Y Problem, 使用 js 实现热更新很容易碰到 v8 优化之后各地拿到缓存的引用导致热更新 js 没意义. 当然热更新 json 还是可以简单一点比如用读取文件的方式来热更新, 但是这样也不如从 redis 之类的数据库中读取比较合理.
简述
其他还有很多内容也是属于很 ‘基础’ 的 Node.js 问题 (例如异步/线程等等), 但是由于归类的问题并没有放在这个分类中. 所以这里只简单讲几个之后没归类的基础问题.
模块机制
node 的基础中毫无疑问的应该是有关于模块机制的方面的, 也即 require 这个内置功能的一些原理的问题.
关于模块互相引用之类的, 不了解的推荐先好好读读官方文档.
其实官方文档已经说得很清楚了, 每个 node 进程只有一个 VM 的上下文, 不会跟浏览器相差多少, 模块机制在文档中也描述的非常清楚了:
function require(...) {
var module = { exports: {} };
((module, exports) => {
// Your module code here. In this example, define a function.
function some_func() {};
exports = some_func;
// At this point, exports is no longer a shortcut to module.exports, and
// this module will still export an empty default object.
module.exports = some_func;
// At this point, the module will now export some_func, instead of the
// default object.
})(module, module.exports);
return module.exports;
}如果 a.js require 了 b.js, 那么在 b 中定义全局变量 t = 111 能否在 a 中直接打印出来?
每个 .js 能独立一个环境只是因为 node 帮你在外层包了一圈自执行, 所以你使用 t = 111 定义全局变量在其他地方当然能拿到. 情况如下:
// b.js
(function(exports, require, module, __filename, __dirname) {
t = 111;
})();
// a.js
(function(exports, require, module, __filename, __dirname) {
// ...
console.log(t); // 111
})();a.js 和 b.js 两个文件互相 require 是否会死循环? 双方是否能导出变量? 如何从设计上避免这种问题?
不会, 先执行的导出其未完成的副本, 通过导出工厂函数让对方从函数去拿比较好避免. 模块在导出的只是 var module = { exports: {…} }; 中的 exports, 以从 a.js 启动为例, a.js 还没执行完会返回一个 a.js 的 exports 对象的未完成的副本给 b.js 模块。 然后 b.js 完成加载,并将 exports 对象提供给 a.js 模块。
另外还有非常基础和常见的问题, 比如 module.exports 和 exports 的区别这里也能一并解决了 exports 只是 module.exports 的一个引用.
再晋级一点, 众所周知, node 的模块机制是基于 CommonJS 规范的. 对于从前端转 node 的同学, 如果面试官想问的难一点会考查关于 CommonJS 的一些问题. 比如比较 AMD(提前执行、依赖前置), CMD(延迟执行、依赖就近), CommonJS 三者的区别, 包括询问关于 node 中 require 的实现原理等.
node 中 require 的实现原理
require 命令是 CommonJS 规范之中,用来加载其他模块的命令。它其实不是一个全局命令,而是指向当前模块的 module.require 命令,而后者又调用 Node 的内部命令 Module._load。
Module._load = function(request, parent, isMain) {
// 1. 检查 Module._cache,是否缓存之中有指定模块
// 2. 如果缓存之中没有,就创建一个新的 Module 实例
// 3. 将它保存到缓存
// 4. 使用 module.load() 加载指定的模块文件,
// 读取文件内容之后,使用 module.compile() 执行文件代码
// 5. 如果加载/解析过程报错,就从缓存删除该模块
// 6. 返回该模块的 module.exports
};上面的第 4 步,采用 module.compile() 执行指定模块的脚本,逻辑如下。
Module.prototype._compile = function(content, filename) {
// 1. 生成一个 require 函数,指向 module.require
// 2. 加载其他辅助方法到 require
// 3. 将文件内容放到一个函数之中,该函数可调用 require
// 4. 执行该函数
};上面的第 1 步和第 2 步,require 函数及其辅助方法主要如下。
- require(): 加载外部模块
- require.resolve():将模块名解析到一个绝对路径
- require.main:指向主模块
- require.cache:指向所有缓存的模块
- require.extensions:根据文件的后缀名,调用不同的执行函数
一旦 require 函数准备完毕,整个所要加载的脚本内容,就被放到一个新的函数之中,这样可以避免污染全局环境。该函数的参数包括 require、module、exports,以及其他一些参数。
(function(exports, require, module, __filename, __dirname) {
// YOUR CODE INJECTED HERE!
});Module._compile 方法是同步执行的,所以 Module._load 要等它执行完成,才会向用户返回 module.exports 的值。
热更新
从面试官的角度看, 热更新是很多程序常见的问题. 对客户端而言, 热更新意味着不用换包, 当然也包含着 md5 校验/差异更新等复杂问题; 对服务端而言, 热更新意味着服务不用重启, 这样可用性较高同时也优雅和有逼格. 问的过程中可以一定程度的暴露应聘程序员的水平.
从 PHP 转 node 的同学可能会有些想法, 比如 PHP 的代码直接刷上去就好了, 并没有所谓的重启. 而 node 重启看起来动作还挺大. 当然这里面的区别, 主要是与同时有 PHP 与 node 开发经验的同学可以讨论, 也是很好的切入点.
在 Node.js 中做热更新代码, 牵扯到的知识点可能主要是 require 会有一个 cache, 有这个 cache 在, 即使你更新了 .js 文件, 在代码中再次 require 还是会拿到之前的编译好缓存在 v8 内存 (code space) 中的的旧代码. 但是如果只是单纯的清除掉 require 中的 cache, 再次 require 确实能拿到新的代码, 但是这时候很容易碰到各地维持旧的引用依旧跑的旧的代码的问题. 如果还要继续推行这种热更新代码的话, 可能要推翻当前的架构, 从头开始重新设计一下目前的框架.
不过热更新 json 之类的配置文件的话, 还是可以简单的实现的, 更新 require 的 cache 可以实现, 不会有持有旧引用的问题, 可以参见我 2 年前写着玩的例子, 但是如果旧的引用一直被持有很容易出现内存泄漏, 而要热更新配置的话, 为什么不存数据库? 或者用 zookeeper 之类的服务? 通过更新文件还要再发布一次, 但是存数据库直接写个接口配个界面多爽你说是不是?
所以这个问题其实本身其实是值得商榷的, 可能是典型的 X-Y Problem, 不过聊起来确实是可以暴露水平.
上下文
对于 Node.js 而言, 正常情况下只有一个上下文, 甚至于内置的很多方面例如 require 的实现只是在启动的时候运行了内置的函数.
每个单独的 .js 文件并不意味着单独的上下文, 在某个 .js 文件中污染了全局的作用域一样能影响到其他的地方.
而目前的 Node.js 将 VM 的接口暴露了出来, 可以让你自己创建一个新的 js 上下文, 这一点上跟前端 js 还是区别挺大的. 在执行外部代码的时候, 通过创建新的上下文沙盒 (sandbox) 可以避免上下文被污染:
'use strict';
const vm = require('vm');
let code = `(function(require) {
const http = require('http');
http.createServer( (request, response) => {
response.writeHead(200, {'Content-Type': 'text/plain'});
response.end('Hello World\\n');
}).listen(8124);
console.log('Server running at http://127.0.0.1:8124/');
})`;
vm.runInThisContext(code)(require);这种执行方式与 eval 和 Function 有明显的区别. 关于 VM 更多的一些接口可以先阅读官方文档 VM (虚拟机)
讲完这个知识点, 这里留下一个简单的问题, 既然可以通过新的上下文来避免污染, 那么为什么 Node.js 不给每一个 .js 文件以独立的上下文来避免作用域被污染?
为什么 Node.js 不给每一个 .js 文件以独立的上下文来避免作用域被污染?
node 中 require 的实现原理里面有说明,_compile 函数有调用 vm.runInThisContext 函数,即 Node.js 模块正常情况对作用域不会造成污染,意外创建全局变量是一种例外
事件/异步
Promise
相信很多同学在面试的时候都碰到过这样一个问题, 如何处理 Callback Hell. 在早些年的时候, 大家会看到有很多的解决方案例如 Q, async, EventProxy 等等. 最后从流行程度来看 Promise 当之无愧的独领风骚, 并且是在 ES6 的 JavaScript 标准上赢得了支持.
关于它的基础知识/概念推荐看阮一峰的 Promise 对象 这里就不多不赘述.
Promise 中 .then 的第二参数与 .catch 有什么区别?
somePromise()
.then(function() {
throw new Error('oh noes');
})
.catch(function(err) {
// I caught your error! :)
});
somePromise().then(
function() {
throw new Error('oh noes');
},
function(err) {
// I didn't catch your error! :(
}
);建议使用 catch
另外关于同步与异步, 有个问题希望大家看一下, 这是很简单的 Promise 的使用例子:
let doSth = new Promise((resolve, reject) => {
console.log('hello');
resolve();
});
doSth.then(() => {
console.log('over');
});毫无疑问的可以得到以下输出结果:
hello
over但是首先的问题是, 该 Promise 封装的代码肯定是同步的, 那么这个 then 的执行是异步的吗?(异步)
其次的问题是, 如下代码, setTimeout 到 10s 之后再 .then 调用, 那么 hello 是会在 10s 之后在打印吗, 还是一开始就打印?(hello 是会在 10s 之后在打印)
let doSth = new Promise((resolve, reject) => {
console.log('hello');
resolve();
});
setTimeout(() => {
doSth.then(() => {
console.log('over');
});
}, 10000);以及理解如下代码的执行顺序
setTimeout(function() {
console.log(1);
}, 0);
new Promise(function executor(resolve) {
console.log(2);
for (var i = 0; i < 10000; i++) {
i == 9999 && resolve();
}
console.log(3);
}).then(function() {
console.log(4);
});
console.log(5);2
3
5
4
1Events
Events 是 Node.js 中一个非常重要的 core 模块, 在 node 中有许多重要的 core API 都是依赖其建立的. 比如 Stream 是基于 Events 实现的, 而 fs, net, http 等模块都依赖 Stream, 所以 Events 模块的重要性可见一斑.
通过继承 EventEmitter 来使得一个类具有 node 提供的基本的 event 方法, 这样的对象可以称作 emitter, 而触发(emit)事件的 cb 则称作 listener. 与前端 DOM 树上的事件并不相同, emitter 的触发不存在冒泡, 逐层捕获等事件行为, 也没有处理事件传递的方法.
Eventemitter 的 emit 是同步还是异步?
Node.js 中 Eventemitter 的 emit 是同步的.
另外, 可以讨论如下的执行结果是输出 hi 1 还是 hi 2?
const EventEmitter = require('events');
let emitter = new EventEmitter();
emitter.on('myEvent', () => {
console.log('hi 1');
});
emitter.on('myEvent', () => {
console.log('hi 2');
});
emitter.emit('myEvent');hi 1
hi 2或者如下情况是否会死循环?(会出现)
const EventEmitter = require('events');
let emitter = new EventEmitter();
emitter.on('myEvent', () => {
console.log('hi');
emitter.emit('myEvent');
});
emitter.emit('myEvent');以及这样会不会死循环?(不会出现,只是多了一个监听)
const EventEmitter = require('events');
let emitter = new EventEmitter();
emitter.on('myEvent', function sth() {
emitter.on('myEvent', sth);
console.log('hi');
});
emitter.emit('myEvent');使用 emitter 处理问题可以处理比较复杂的状态场景, 比如 TCP 的复杂状态机, 做多项异步操作的时候每一步都可能报错, 这个时候 .emit 错误并且执行某些 .once 的操作可以将你从泥沼中拯救出来.
另外可以注意一下的是, 有些同学喜欢用 emitter 来监控某些类的状态, 但是在这些类释放的时候可能会忘记释放 emitter, 而这些类的内部可能持有该 emitter 的 listener 的引用从而导致内存泄漏.
阻塞/异步
如何判断接口是否异步? 是否只要有回调函数就是异步?
开放性问题, 每个写 node 的人都有一套自己的判断方式.
- 看文档
- console.log 打印看看
- 看是否有 IO 操作
单纯使用回调函数并不会异步, IO 操作才可能会异步, 除此之外还有使用 setTimeout 等方式实现异步.
有这样一个场景, 你在线上使用 koa 搭建了一个网站, 这个网站项目中有一个你同事写的接口 A, 而 A 接口中在特殊情况下会变成死循环. 那么首先问题是, 如果触发了这个死循环, 会对网站造成什么影响?
Node.js 中执行 js 代码的过程是单线程的. 只有当前代码都执行完, 才会切入事件循环, 然后从事件队列中 pop 出下一个回调函数开始执行代码. 所以实现一个 sleep 函数, 只要通过一个死循环就可以阻塞整个 js 的执行流程. (关于如何避免坑爹的同事写出死循环, 在后面的测试环节有写到.)
如何实现一个 sleep 函数?
function sleep(ms) {
var start = Date.now(),
expire = start + ms;
while (Date.now() < expire);
return;
}而异步, 是使用 libuv 来实现的 (C/C++的同学可以参见 libev 和 libevent) 另一个线程里的事件队列.
如果在线上的网站中出现了死循环的逻辑被触发, 整个进程就会一直卡在死循环中, 如果没有多进程部署的话, 之后的网站请求全部会超时, js 代码没有结束那么事件队列就会停下等待不会执行异步, 整个网站无法响应.
如何实现一个异步的 reduce? (注:不是异步完了之后同步 reduce)
需要了解 reduce 的情况, 是第 n 个与 n + 1 的结果异步处理完之后, 在用新的结果与第 n + 2 个元素继续依次异步下去.
// 当 await memo 不是最先出现时,所有的 sleep 并行执行,因为 await memo 使得函数等待上一个函数完成后执行
// utility function for sleeping
const sleep = (n) => new Promise((res) => setTimeout(res, n));
const arr = [1, 2, 3];
const startTime = new Date().getTime();
const asyncRes = await arr.reduce(async (memo, e) => {
await sleep(2000);
console.log(e);
return (await memo) + e;
}, 0);
console.log(asyncRes, `Took ${new Date().getTime() - startTime} ms`);1
2
3
6 "Took 2001 ms"// 当 await memo 最先出现时,这些函数按顺序运行,所有的 sleep 串行执行
const sleep = (n) => new Promise((res) => setTimeout(res, n));
const arr = [1, 2, 3];
const startTime = new Date().getTime();
const asyncRes = await arr.reduce(async (memo, e) => {
await memo;
await sleep(2000);
console.log(e);
return (await memo) + e;
}, 0);
console.log(asyncRes, `Took ${new Date().getTime() - startTime} ms`);1
2
3
6 "Took 6003 ms"Timers
在笔者这里将 Node.js 中的异步简单的划分为两种, 硬异步和软异步.
硬异步是指由于 IO 操作或者外部调用走 libuv 而需要异步的情况. 当然, 也存在 readFileSync, execSync 等例外情况, 不过 node 由于是单线程的, 所以如果常规业务在普通时段执行可能比较耗时同步的 IO 操作会使得其执行过程中其他的所有操作都不能响应, 有点作死的感觉. 不过在启动/初始化以及一些工具脚本的应用场景下是完全没问题的. 而一般的场景下 IO 操作都是需要异步的.
软异步是指, 通过 setTimeout 等方式来实现的异步.
关于 nextTick, setTimeout 以及 setImmediate 三者的区别
setImmediate vs process.nextTick
- setImmediate() 属于 check 观察者,其设置的回调函数,会插入到下次事件循环的末尾。
- process.nextTick() 设置的回调函数,会在代码运行完成后立即执行,会在下次事件循环之前被调用,原文是 “the callback will fire as soon as the code runs to completion, but before going back to the event loop.”
- process.nextTick() 所设置的回调函数会存放到数组中,一次性执行所有回调函数。
- setImmediate() 所设置的回调函数会存到到链表中,每次事件循环只执行链表中的一个回调函数。
setTimeout(fn, 0) vs setImmediate
执行 setTimeout(fn, 0) 其实就是在执行 setTimeout(fn, 1),也就是说 setImmediate() 是有可能先于 setTimeout(fn, 0) 执行的。
Event loop 示例
┌───────────────────────┐
┌─>│ timers │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
│ │ I/O callbacks │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
│ │ idle, prepare │
│ └──────────┬────────────┘ ┌───────────────┐
│ ┌──────────┴────────────┐ │ incoming: │
│ │ poll │<─────┤ connections, │
│ └──────────┬────────────┘ │ data, etc. │
│ ┌──────────┴────────────┐ └───────────────┘
│ │ check │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
└──┤ close callbacks │
└───────────────────────┘关于事件循环, Timers 以及 nextTick 的关系详见官方文档 The Node.js Event Loop, Timers, and process.nextTick(),论坛中文讨论
并行/并发
并行 (Parallel) 与并发 (Concurrent) 是两个很常见的概念.
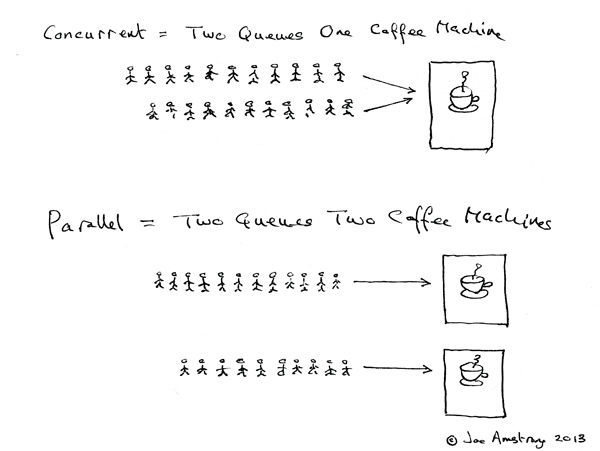
并发 (Concurrent) = 2 队列对应 1 咖啡机.
并行 (Parallel) = 2 队列对应 2 咖啡机.
Node.js 通过事件循环来挨个抽取事件队列中的一个个 Task 执行, 从而避免了传统的多线程情况下 2个队列对应 1个咖啡机 的时候上下文切换以及资源争抢/同步的问题, 所以获得了高并发的成就.
至于在 node 中并行, 你可以通过 cluster 来再添加一个咖啡机.
进程
简述
关于 Process, 我们需要讨论的是两个概念:操作系统的进程、Node.js 中的 Process 对象. 操作进程对于服务端而言, 好比 html 之于前端一样基础. 想做服务端编程是不可能绕过 Unix/Linux 的. 在 Linux/Unix/Mac 系统中运行 ps -ef 命令可以看到当前系统中运行的进程. 各个参数如下:
| 列名称 | 意义 |
|---|---|
| UID | 执行该进程的用户 ID |
| PID | 进程编号 |
| PPID | 该进程的父进程编号 |
| C | 该进程所在的 CPU 利用率 |
| STIME | 进程执行时间 |
| TTY | 进程相关的终端类型 |
| TIME | 进程所占用的 CPU 时间 |
| CMD | 创建该进程的指令 |
关于进程以及操作系统一些更深入的细节推荐阅读 APUE, 即《Unix 高级编程》等书籍来了解.
Process
这里来讨论 Node.js 中的 process 对象. 直接在代码中通过 console.log(process) 即可打印出来. 可以看到 process 对象暴露了非常多有用的属性以及方法, 具体的细节见官方文档, 已经说的挺详细了. 其中包括但不限于:
- 进程基础信息
- 进程 Usage
- 进程级事件
- 依赖模块/版本信息
- OS 基础信息
- 账户信息
- 信号收发
- 三个标准流
process.nextTick
上一节已经提到过 process.nextTick 了, 这是一个你需要了解的, 重要的, 基础方法.
┌───────────────────────┐
┌─>│ timers │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
│ │ I/O callbacks │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
│ │ idle, prepare │
│ └──────────┬────────────┘ ┌───────────────┐
│ ┌──────────┴────────────┐ │ incoming: │
│ │ poll │<─────┤ connections, │
│ └──────────┬────────────┘ │ data, etc. │
│ ┌──────────┴────────────┐ └───────────────┘
│ │ check │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
└──┤ close callbacks │
└───────────────────────┘process.nextTick 并不属于 Event loop 中的某一个阶段, 而是在 Event loop 的每一个阶段结束后, 直接执行 nextTickQueue 中插入的 “Tick”, 并且直到整个 Queue 处理完. 所以面试时又有可以问的问题了, 递归调用 process.nextTick 会怎么样?
function test() {
process.nextTick(() => test());
}超过 1000 次会提示调用栈过多
这种情况与以下情况, 有什么区别? 为什么?
function test() {
setTimeout(() => test(), 0);
}- process.nextTick 是将异步回调放到当前帧的末尾、io 回调之前,如果 nextTick 过多,会导致 io 回调不断延后,最后 callback 堆积太多.
- setImmediate 是将异步回调放到下一帧,不影响 io 回调,不会造成 callback 堆积.
- process.nextTick() 所设置的回调函数会存放到数组中,一次性执行所有回调函数。
- setImmediate() 所设置的回调函数会存到到链表中,每次事件循环只执行链表中的一个回调函数。
配置
配置是开发部署中一个很常见的问题,普通的配置有两种方式,一是定义配置文件,二是使用环境变量
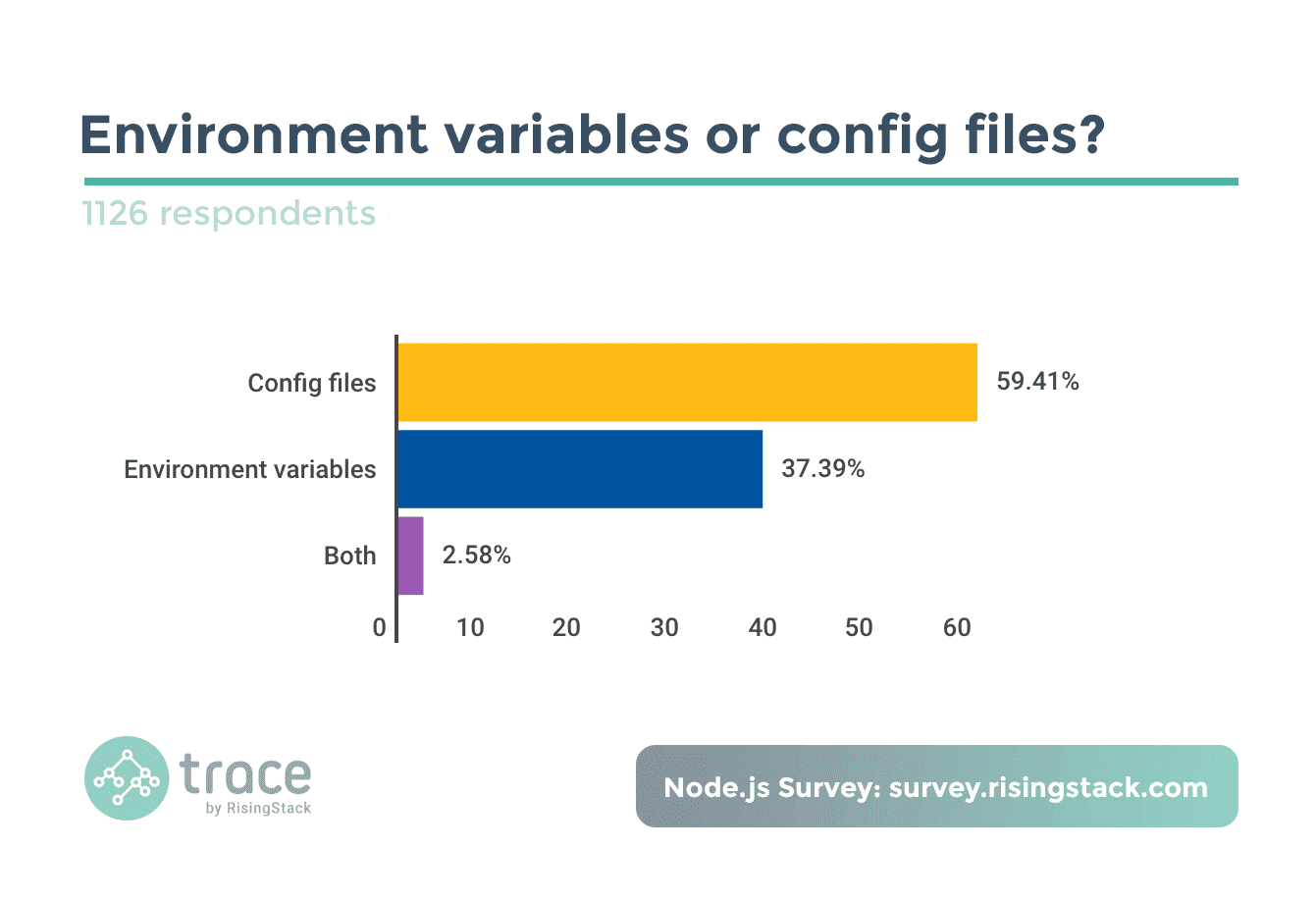
你可以通过设置环境变量来指定配置, 然后通过 process.env 来获取配置项. 另外也可以通过读取定义好的配置文件来获取, 在这方面有很多不错的库例如 dotenv, node-config 等, 而在使用这些库来加载配置文件的时候, 通常都会碰到一个当前工作目录的问题
进程的当前工作目录是什么? 有什么作用?
当前进程启动的目录, 通过 process.cwd() 获取当前工作目录 (current working directory), 通常是命令行启动的时候所在的目录 (也可以在启动时指定), 文件操作等使用相对路径的时候会相对当前工作目录来获取文件.
一些获取配置的第三方模块就是通过你的当前目录来找配置文件的. 所以如果你错误的目录启动脚本, 可能没法得到正确的结果. 在程序中可以通过 process.chdir() 来改变当前的工作目录.
标准流
在 process 对象上还暴露了 process.stderr, process.stdout 以及 process.stdin 三个标准流, 熟悉 C/C++/Java 的同学应该对此比较熟悉. 关于这几个流, 常见的面试问题是问 console.log 是同步还是异步? 如何实现一个 console.log?
如果简历中有出现 C/C++ 关键字, 一般都会问到如何实现一个同步的输入 (类似实现 C 语言的 scanf, C++ 的 cin, Python 的 raw_input 等).
维护方面
熟悉与进程有关的基础命令, 如 top, ps, pstree 等命令
Child Process
子进程 (Child Process) 是进程中一个重要的概念. 你可以通过 Node.js 的 child_process 模块来执行可执行文件, 调用命令行命令, 比如其他语言的程序等. 也可以通过该模块来将 .js 代码以子进程的方式启动. 比较有名的网易的分布式架构 pomelo 就是基于该模块 (而不是 cluster) 来实现多进程分布式架构的.
child_process.fork 与 POSIX 的 fork 有什么区别?
Node.js 的 childprocess.fork() 在 Unix 上的实现最终调用了 POSIX fork(2), 而 POSIX 的 fork 需要手动管理子进程的资源释放 (waitpid), childprocess.fork 则不用关心这个问题, Node.js 会自动释放, 并且可以在 option 中选择父进程死后是否允许子进程存活.
-
spawn() 启动一个子进程来执行命令
- options.detached 父进程死后是否允许子进程存活
- options.stdio 指定子进程的三个标准流
- spawnSync() 同步版的 spawn, 可指定超时, 返回的对象可获得子进程的情况
- exec() 启动一个子进程来执行命令, 带回调参数获知子进程的情况, 可指定进程运行的超时时间
- execSync() 同步版的 exec(), 可指定超时, 返回子进程的输出 (stdout)
- execFile() 启动一个子进程来执行一个可执行文件, 可指定进程运行的超时时间
- execFileSync() 同步版的 execFile(), 返回子进程的输出, 如何超时或者 exit code 不为 0, 会直接 throw Error
- fork() 加强版的 spawn(), 返回值是 ChildProcess 对象可以与子进程交互
其中 exec/execSync 方法会直接调用 bash 来解释命令, 所以如果有命令有外部参数, 则需要注意被注入的情况.
child.kill 与 child.send
常见会问的面试题, 如 child.kill 与 child.send 的区别. 二者一个是基于信号系统, 一个是基于 IPC.
父进程或子进程的死亡是否会影响对方? 什么是孤儿进程?
子进程死亡不会影响父进程, 不过子进程死亡时(线程组的最后一个线程,通常是“领头”线程死亡时),会向它的父进程发送死亡信号. 反之父进程死亡, 一般情况下子进程也会随之死亡, 但如果此时子进程处于可运行态、僵死状态等等的话, 子进程将被进程 1(init 进程)收养,从而成为孤儿进程. 另外, 子进程死亡的时候(处于“终止状态”),父进程没有及时调用 wait() 或 waitpid() 来返回死亡进程的相关信息,此时子进程还有一个 PCB 残留在进程表中,被称作僵尸进程.
Cluster
Cluster 是常见的 Node.js 利用多核的办法. 它是基于 child_process.fork() 实现的, 所以 cluster 产生的进程之间是通过 IPC 来通信的, 并且它也没有拷贝父进程的空间, 而是通过加入 cluster.isMaster 这个标识, 来区分父进程以及子进程, 达到类似 POSIX 的 fork 的效果.
const cluster = require('cluster'); // | |
const http = require('http'); // | |
const numCPUs = require('os').cpus().length; // | | 都执行了
// | |
if (cluster.isMaster) {
// |-|-----------------
// Fork workers. // |
for (var i = 0; i < numCPUs; i++) {
// |
cluster.fork(); // |
} // | 仅父进程执行 (a.js)
cluster.on('exit', (worker) => {
// |
console.log(`${worker.process.pid} died`); // |
}); // |
} else {
// |-------------------
// Workers can share any TCP connection // |
// In this case it is an HTTP server // |
http
.createServer((req, res) => {
// |
res.writeHead(200); // | 仅子进程执行 (b.js)
res.end('hello world\n'); // |
})
.listen(8000); // |
} // |-------------------
// | |
console.log('hello'); // | | 都执行了在上述代码中 numCPUs 虽然是全局变量但是, 在父进程中修改它, 子进程中并不会改变, 因为父进程与子进程是完全独立的两个空间. 他们所谓的共有仅仅只是都执行了, 并不是同一份.
你可以把父进程执行的部分当做 a.js, 子进程执行的部分当做 b.js, 你可以把他们想象成是先执行了 node a.js 然后 cluster.fork 了几次, 就执行了几次 node b.js. 而 cluster 模块则是二者之间的一个桥梁, 你可以通过 cluster 提供的方法, 让其二者之间进行沟通交流.
How It Works
worker 进程是由 child_process.fork() 方法创建的, 所以可以通过 IPC 在主进程和子进程之间相互传递服务器句柄.
cluster 模块提供了两种分发连接的方式.
第一种方式 (默认方式, 不适用于 windows), 通过时间片轮转法(round-robin)分发连接. 主进程监听端口, 接收到新连接之后, 通过时间片轮转法来决定将接收到的客户端的 socket 句柄传递给指定的 worker 处理. 至于每个连接由哪个 worker 来处理, 完全由内置的循环算法决定.
第二种方式是由主进程创建 socket 监听端口后, 将 socket 句柄直接分发给相应的 worker, 然后当连接进来时, 就直接由相应的 worker 来接收连接并处理.
使用第二种方式时理论上性能应该较高, 然而时间上存在负载不均衡的问题, 比如通常 70% 的连接仅被 8 个进程中的 2 个处理, 而其他进程比较清闲.
进程间通信
IPC (Inter-process communication) 进程间通信技术. 常见的进程间通信技术列表如下:
| 类型 | 无连接 | 可靠 | 流控制 | 优先级 |
|---|---|---|---|---|
| 普通 PIPE | N | Y | Y | N |
| 命名 PIPE | N | Y | Y | N |
| 消息队列 | N | Y | Y | N |
| 信号量 | N | Y | Y | Y |
| 共享存储 | N | Y | Y | Y |
| UNIX 流 SOCKET | N | Y | Y | N |
| UNIX 数据包 SOCKET | Y | Y | N | N |
Node.js 中的 IPC 通信是由 libuv 通过管道技术实现的, 在 windows 下由命名管道(named pipe)实现也就是上表中的最后第二个, *nix 系统则采用 UDS (Unix Domain Socket) 实现.
普通的 socket 是为网络通讯设计的, 而网络本身是不可靠的, 而为 IPC 设计的 socket 则不然, 因为默认本地的网络环境是可靠的, 所以可以简化大量不必要的 encode/decode 以及计算校验等, 得到效率更高的 UDS 通信.
如果了解 Node.js 的 IPC 的话, 可以问个比较有意思的问题
在 IPC 通道建立之前, 父进程与子进程是怎么通信的? 如果没有通信, 那 IPC 是怎么建立的?
这个问题也挺简单, 只是个思路的问题. 在通过 child_process 建立子进程的时候, 是可以指定子进程的 env (环境变量) 的. 所以 Node.js 在启动子进程的时候, 主进程先建立 IPC 频道, 然后将 IPC 频道的 fd (文件描述符) 通过环境变量 (NODE_CHANNEL_FD) 的方式传递给子进程, 然后子进程通过 fd 连上 IPC 与父进程建立连接.
最后于进程间通信 (IPC) 的问题, 一般不会直接问 IPC 的实现, 而是会问什么情况下需要 IPC, 以及使用 IPC 处理过什么业务场景等.
守护进程
最后的守护进程, 是服务端方面一个很基础的概念了. 很多人可能只知道通过 pm2 之类的工具可以将进程以守护进程的方式启动, 却不了解什么是守护进程, 为什么要用守护进程. 对于水平好的同学, 我们是希望能了解守护进程的实现的.
普通的进程, 在用户退出终端之后就会直接关闭. 通过 & 启动到后台的进程, 之后会由于会话(session 组)被回收而终止进程. 守护进程是不依赖终端(tty)的进程, 不会因为用户退出终端而停止运行的进程.
// 守护进程实现 (C语言版本)
void init_daemon()
{
pid_t pid;
int i = 0;
if ((pid = fork()) == -1) {
printf("Fork error !\n");
exit(1);
}
if (pid != 0) {
exit(0); // 父进程退出
}
setsid(); // 子进程开启新会话, 并成为会话首进程和组长进程
if ((pid = fork()) == -1) {
printf("Fork error !\n");
exit(-1);
}
if (pid != 0) {
exit(0); // 结束第一子进程, 第二子进程不再是会话首进程
// 避免当前会话组重新与tty连接
}
chdir("/tmp"); // 改变工作目录
umask(0); // 重设文件掩码
for (; i < getdtablesize(); ++i) {
close(i); // 关闭打开的文件描述符
}
return;
}var spawn = require('child_process').spawn;
var process = require('process');
var p = spawn('node', ['b.js'], {
detached: true
});
console.log(process.pid, p.pid);
process.exit(0);IO
简述
Node.js 是以 IO 密集型业务著称. 那么问题来了, 你真的了解什么叫 IO, 什么又叫 IO 密集型业务吗?
Buffer
Buffer 是 Node.js 中用于处理二进制数据的类, 其中与 IO 相关的操作 (网络/文件等) 均基于 Buffer. Buffer 类的实例非常类似整数数组, 但其大小是固定不变的, 并且其内存在 V8 堆栈外分配原始内存空间. Buffer 类的实例创建之后, 其所占用的内存大小就不能再进行调整.
在 Node.js v6.x 之后 new Buffer() 接口开始被废弃, 理由是参数类型不同会返回不同类型的 Buffer 对象, 所以当开发者没有正确校验参数或没有正确初始化 Buffer 对象的内容时, 以及不了解的情况下初始化 就会在不经意间向代码中引入安全性和可靠性问题.
| 接口 | 用途 |
|---|---|
| Buffer.from() | 根据已有数据生成一个 Buffer 对象 |
| Buffer.alloc() | 创建一个初始化后的 Buffer 对象 |
| Buffer.allocUnsafe() | 创建一个未初始化的 Buffer 对象 |
TypedArray
Node.js 的 Buffer 在 ES6 增加了 TypedArray 类型之后, 修改了原来的 Buffer 的实现, 选择基于 TypedArray 中 Uint8Array 来实现, 从而提升了一波性能.
使用上, 你需要了解如下情况:
const arr = new Uint16Array(2);
arr[0] = 5000;
arr[1] = 4000;
const buf1 = Buffer.from(arr); // 拷贝了该 buffer
const buf2 = Buffer.from(arr.buffer); // 与该数组共享了内存
console.log(buf1);
// 输出: <Buffer 88 a0>, 拷贝的 buffer 只有两个元素
console.log(buf2);
// 输出: <Buffer 88 13 a0 0f>
arr[1] = 6000;
console.log(buf1);
// 输出: <Buffer 88 a0>
console.log(buf2);
// 输出: <Buffer 88 13 70 17>String Decoder
字符串解码器 (String Decoder) 是一个用于将 Buffer 拿来 decode 到 string 的模块, 是作为 Buffer.toString 的一个补充, 它支持多字节 UTF-8 和 UTF-16 字符. 例如
const StringDecoder = require('string_decoder').StringDecoder;
const decoder = new StringDecoder('utf8');
const cent = Buffer.from([0xc2, 0xa2]);
console.log(decoder.write(cent)); // ¢
const euro = Buffer.from([0xe2, 0x82, 0xac]);
console.log(decoder.write(euro)); // €stringDecoder.write 会确保返回的字符串不包含 Buffer 末尾残缺的多字节字符,残缺的多字节字符会被保存在一个内部的 buffer 中用于下次调用 stringDecoder.write() 或 stringDecoder.end()。
const StringDecoder = require('string_decoder').StringDecoder;
const decoder = new StringDecoder('utf8');
decoder.write(Buffer.from([0xe2]));
decoder.write(Buffer.from([0x82]));
console.log(decoder.end(Buffer.from([0xac]))); // €Stream
Node.js 内置的 stream 模块是多个核心模块的基础. 但是流 (stream) 是一种很早之前流行的编程方式. 可以用大家比较熟悉的 C 语言来看这种流式操作:
int copy(const char *src, const char *dest)
{
FILE *fpSrc, *fpDest;
char buf[BUF_SIZE] = {0};
int lenSrc, lenDest;
// 打开 src 的文件
if ((fpSrc = fopen(src, "r")) == NULL)
{
printf("文件 '%s' 无法打开\n", src);
return FAILURE;
}
// 打开 dest 的文件
if ((fpDest = fopen(dest, "w")) == NULL)
{
printf("文件 '%s' 无法打开\n", dest);
fclose(fpSrc);
return FAILURE;
}
// 从 src 中读取 BUF_SIZE 长的数据到 buf 中
while ((lenSrc = fread(buf, 1, BUF_SIZE, fpSrc)) > 0)
{
// 将 buf 中的数据写入 dest 中
if ((lenDest = fwrite(buf, 1, lenSrc, fpDest)) != lenSrc)
{
printf("写入文件 '%s' 失败\n", dest);
fclose(fpSrc);
fclose(fpDest);
return FAILURE;
}
// 写入成功后清空 buf
memset(buf, 0, BUF_SIZE);
}
// 关闭文件
fclose(fpSrc);
fclose(fpDest);
return SUCCESS;
}应用的场景很简单, 你要拷贝一个 20G 大的文件, 如果你一次性将 20G 的数据读入到内存, 你的内存条可能不够用, 或者严重影响性能. 但是你如果使用一个 1MB 大小的缓存 (buf) 每次读取 1Mb, 然后写入 1Mb, 那么不论这个文件多大都只会占用 1Mb 的内存.
而在 Node.js 中, 原理与上述 C 代码类似, 不过在读写的实现上通过 libuv 与 EventEmitter 加上了异步的特性. 在 linux/unix 中你可以通过 | 来感受到流式操作.
Stream 的类型
| 类 | 使用场景 | 重写方法 |
|---|---|---|
| Readable | 只读 | _ read |
| Writable | 只写 | _ write |
| Duplex | 读写 | _ read, _ write |
| Transform | 操作被写入数据, 然后读出结果 | _ transform, _ flush |
对象模式
通过 Node API 创建的流, 只能够对字符串或者 buffer 对象进行操作. 但其实流的实现是可以基于其他的 JavaScript 类型(除了 null, 它在流中有特殊的含义)的. 这样的流就处在 “对象模式(objectMode)” 中. 在创建流对象的时候, 可以通过提供 objectMode 参数来生成对象模式的流. 试图将现有的流转换为对象模式是不安全的
缓冲区
Node.js 中 stream 的缓冲区, 以开头的 C 语言拷贝文件的代码为模板讨论, (抛开异步的区别看) 则是从 src 中读出数据到 buf 中后, 并没有直接写入 dest 中, 而是先放在一个比较大的缓冲区中, 等待写入(消费) dest 中. 即, 在缓冲区的帮助下可以使读与写的过程分离.
Readable 和 Writable 流都会将数据储存在内部的缓冲区中. 缓冲区可以分别通过 writable._writableState.getBuffer() 和 readable._readableState.buffer 来访问. 缓冲区的大小, 由构造 stream 时候的 highWaterMark 标志指定可容纳的 byte 大小, 对于 objectMode 的 stream, 该标志表示可以容纳的对象个数.
可读流
当一个可读实例调用 stream.push() 方法的时候, 数据将会被推入缓冲区. 如果数据没有被消费, 即调用 stream.read() 方法读取的话, 那么数据会一直留在缓冲队列中. 当缓冲区中的数据到达 highWaterMark 指定的阈值, 可读流将停止从底层汲取数据, 直到当前缓冲的报备成功消耗为止.
可写流
在一个在可写实例上不停地调用 writable.write(chunk) 的时候数据会被写入可写流的缓冲区. 如果当前缓冲区的缓冲的数据量低于 highWaterMark 设定的值, 调用 writable.write() 方法会返回 true (表示数据已经写入缓冲区), 否则当缓冲的数据量达到了阈值, 数据无法写入缓冲区 write 方法会返回 false, 直到 drain 事件触发之后才能继续调用 write 写入.
// Write the data to the supplied writable stream one million times.
// Be attentive to back-pressure.
function writeOneMillionTimes(writer, data, encoding, callback) {
let i = 1000000;
write();
function write() {
var ok = true;
do {
i--;
if (i === 0) {
// last time!
writer.write(data, encoding, callback);
} else {
// see if we should continue, or wait
// don't pass the callback, because we're not done yet.
ok = writer.write(data, encoding);
}
} while (i > 0 && ok);
if (i > 0) {
// had to stop early!
// write some more once it drains
writer.once('drain', write);
}
}
}Duplex 与 Transform
Duplex 流和 Transform 流都是同时可读写的, 他们会在内部维持两个缓冲区, 分别对应读取和写入, 这样就可以允许两边同时独立操作, 维持高效的数据流. 比如说 net.Socket 是一个 Duplex 流, Readable 端允许从 socket 获取、消耗数据, Writable 端允许向 socket 写入数据. 数据写入的速度很有可能与消耗的速度有差距, 所以两端可以独立操作和缓冲是很重要的.
pipe
stream 的 .pipe(), 将一个可写流附到可读流上, 同时将可写流切换到流模式, 并把所有数据推给可写流. 在 pipe 传递数据的过程中, objectMode 是传递引用, 非 objectMode 则是拷贝一份数据传递下去.
pipe 方法最主要的目的就是将数据的流动缓冲到一个可接受的水平, 不让不同速度的数据源之间的差异导致内存被占满. 关于 pipe 的实现参见 David Cai 的 通过源码解析 Node.js 中导流(pipe)的实现
Console
console.log 同步还是异步取决于与谁相连和os. 不过一般情况下的实现都是如下 (6.x 源代码),其中 this._stdout 默认是 process.stdout:
// As of v8 5.0.71.32, the combination of rest param, template string
// and .apply(null, args) benchmarks consistently faster than using
// the spread operator when calling util.format.
Console.prototype.log = function(...args) {
this._stdout.write(`${util.format.apply(null, args)}\n`);
};自己实现一个 console.log 可以参考如下代码:
let print = (str) => process.stdout.write(str + '\n');
print('hello world');注意: 该代码并没有处理多参数, 也没有处理占位符 (即 util.format 的功能).
console.log.bind(console) 问题
// 源码出处 https://github.com/nodejs/node/blob/v6.x/lib/console.js
function Console(stdout, stderr) {
// ... init ...
// bind the prototype functions to this Console instance
var keys = Object.keys(Console.prototype);
for (var v = 0; v < keys.length; v++) {
var k = keys[v];
this[k] = this[k].bind(this);
}
}File
“一切皆是文件”是 Unix/Linux 的基本哲学之一, 不仅普通的文件、目录、字符设备、块设备、套接字等在 Unix/Linux 中都是以文件被对待, 也就是说这些资源的操作对象均为 fd (文件描述符), 都可以通过同一套 system call 来读写. 在 linux 中你可以通过 ulimit 来对 fd 资源进行一定程度的管理限制.
Node.js 封装了标准 POSIX 文件 I/O 操作的集合. 通过 require(‘fs’) 可以加载该模块. 该模块中的所有方法都有异步执行和同步执行两个版本. 你可以通过 fs.open 获得一个文件的文件描述符.
编码
UTF8, GBK, es6 中对编码的支持, 如何计算一个汉字的长度
BOM
stdio
stdio (standard input output) 标准的输入输出流, 即输入流 (stdin), 输出流 (stdout), 错误流 (stderr) 三者. 在 Node.js 中分别对应 process.stdin (Readable), process.stdout (Writable) 以及 process.stderr (Writable) 三个 stream.
输出函数是每个人在学习任何一门编程语言时所需要学到的第一个函数. 例如 C 语言的 printf("hello, world!"); python/ruby 的 print 'hello, world!' 以及 JavaScript 中的 console.log('hello, world!');
以 C 语言的伪代码来看的话, 这类输出函数的实现思路如下:
int printf(FILE *stream, 要打印的内容)
{
// ...
// 1. 申请一个临时内存空间
char *s = malloc(4096);
// 2. 处理好要打印的的内容, 其值存储在 s 中
// ...
// 3. 将 s 上的内容写入到 stream 中
fwrite(s, stream);
// 4. 释放临时空间
free(s);
// ...
}我们需要了解的是第 3 步, 其中的 stream 则是指 stdout (输出流). 实际上在 shell 上运行一个应用程序的时候, shell 做的第一个操作是 fork 当前 shell 的进程 (所以, 如果你通过 ps 去查看你从 shell 上启动的进程, 其父进程 pid 就是当前 shell 的 pid), 在这个过程中也把 shell 的 stdio 继承给了你当前的应用进程, 所以你在当前进程里面将数据写入到 stdout, 也就是写入到了 shell 的 stdout, 即在当前 shell 上显示了.
输入也是同理, 当前进程继承了 shell 的 stdin, 所以当你从 stdin 中读取数据时, 其实就获取到你在 shell 上输入的数据. (PS: shell 可以是 windows 下的 cmd, powershell, 也可以是 linux 下 bash 或者 zsh 等)
当你使用 ssh 在远程服务器上运行一个命令的时候, 在服务器上的命令输出虽然也是写入到服务器上 shell 的 stdout, 但是这个远程的 shell 是从 sshd 服务上 fork 出来的, 其 stdout 是继承自 sshd 的一个 fd, 这个 fd 其实是个 socket, 所以最终其实是写入到了一个 socket 中, 通过这个 socket 传输你本地的计算机上的 shell 的 stdout.
如果你理解了上述情况, 那么你也就能理解为什么守护进程需要关闭 stdio, 如果切到后台的守护进程没有关闭 stdio 的话, 那么你在用 shell 操作的过程中, 屏幕上会莫名其妙的多出来一些输出. 此处对应守护进程的 C 实现中的这一段:
for (; i < getdtablesize(); ++i) {
close(i); // 关闭打开的 fd
}Linux/unix 的 fd 都被设计为整型数字, 从 0 开始. 你可以尝试运行如下代码查看.
console.log(process.stdin.fd); // 0
console.log(process.stdout.fd); // 1
console.log(process.stderr.fd); // 2在上一节中的 在 IPC 通道建立之前, 父进程与子进程是怎么通信的? 如果没有通信, 那 IPC 是怎么建立的? 中使用环境变量传递 fd 的方法, 这么看起来就很直白了, 因为传递 fd 其实是直接传递了一个整型数字.
如何同步的获取用户的输入?
如果你理解了上述的内容, 那么放到 Node.js 中来看, 获取用户的输入其实就是读取 Node.js 进程中的输入流 (即 process.stdin 这个 stream) 的数据.
而要同步读取, 则是不用异步的 read 接口, 而是用同步的 readSync 接口去读取 stdin 的数据即可实现. 以下来自万能的 stackoverflow:
/*
* http://stackoverflow.com/questions/3430939/node-js-readsync-from-stdin
* @mklement0
*/
var fs = require('fs');
var BUFSIZE = 256;
var buf = new Buffer(BUFSIZE);
var bytesRead;
module.exports = function() {
var fd = 'win32' === process.platform ? process.stdin.fd : fs.openSync('/dev/stdin', 'rs');
bytesRead = 0;
try {
bytesRead = fs.readSync(fd, buf, 0, BUFSIZE);
} catch (e) {
if (e.code === 'EAGAIN') {
// 'resource temporarily unavailable'
// Happens on OS X 10.8.3 (not Windows 7!), if there's no
// stdin input - typically when invoking a script without any
// input (for interactive stdin input).
// If you were to just continue, you'd create a tight loop.
console.error('ERROR: interactive stdin input not supported.');
process.exit(1);
} else if (e.code === 'EOF') {
// Happens on Windows 7, but not OS X 10.8.3:
// simply signals the end of *piped* stdin input.
return '';
}
throw e; // unexpected exception
}
if (bytesRead === 0) {
// No more stdin input available.
// OS X 10.8.3: regardless of input method, this is how the end
// of input is signaled.
// Windows 7: this is how the end of input is signaled for
// *interactive* stdin input.
return '';
}
// Process the chunk read.
var content = buf.toString(null, 0, bytesRead - 1);
return content;
};Readline
readline 模块提供了一个用于从 Readble 的 stream (例如 process.stdin) 中一次读取一行的接口. 当然你也可以用来读取文件或者 net, http 的 stream, 比如:
const readline = require('readline');
const fs = require('fs');
const rl = readline.createInterface({
input: fs.createReadStream('sample.txt')
});
rl.on('line', (line) => {
console.log(`Line from file: ${line}`);
});实现上, realine 在读取 TTY 的数据时, 是通过 input.on('keypress', onkeypress) 时发现用户按下了回车键来判断是新的 line 的, 而读取一般的 stream 时, 则是通过缓存数据然后用正则 .test 来判断是否为 new line 的.
PS: 打个广告, 如果在编写脚本时, 不习惯这样异步获取输入, 想要同步获取同步的用户输入可以看一看这个 Node.js 版本类 C 语言使用的 scanf 模块 (支持 ts).
REPL
Read-Eval-Print-Loop (REPL)
Network
Net
目前互联化的核心是建立在 TCP/IP 协议的基础上的, 这些协议将数据分割成小的数据包进行传输, 并且解决传输过程中各种各样复杂的问题. 关于协议的具体细节推荐阅读 W.Richard Stevens 的《TCP/IP 详解 卷 1:协议》, 本文不做赘述, 只是列举一些常见的知识点, 新人推荐看《图解 TCP/IP》, 抓包工具推荐看《Wireshark 网络分析就这么简单》.
粘包
默认情况下, TCP 连接会启用延迟传送算法 (Nagle 算法), 在数据发送之前缓存他们. 如果短时间有多个数据发送, 会缓冲到一起作一次发送 (缓冲大小见 socket.bufferSize), 这样可以减少 IO 消耗提高性能.
如果是传输文件的话, 那么根本不用处理粘包的问题, 来一个包拼一个包就好了. 但是如果是多条消息, 或者是别的用途的数据那么就需要处理粘包.
可以参见网上流传比较广的一个例子, 连续调用两次 send 分别发送两段数据 data1 和 data2, 在接收端有以下几种常见的情况:
- A. 先接收到 data1, 然后接收到 data2 .
- B. 先接收到 data1 的部分数据, 然后接收到 data1 余下的部分以及 data2 的全部.
- C. 先接收到了 data1 的全部数据和 data2 的部分数据, 然后接收到了 data2 的余下的数据.
- D. 一次性接收到了 data1 和 data2 的全部数据.
其中的 BCD 就是我们常见的粘包的情况. 而对于处理粘包的问题, 常见的解决方案有:
- 多次发送之前间隔一个等待时间
- 关闭 Nagle 算法
- 进行封包/拆包
方案 1
只需要等上一段时间再进行下一次 send 就好, 适用于交互频率特别低的场景. 缺点也很明显, 对于比较频繁的场景而言传输效率实在太低. 不过几乎不用做什么处理.
方案 2
关闭 Nagle 算法, 在 Node.js 中你可以通过 socket.setNoDelay() 方法来关闭 Nagle 算法, 让每一次 send 都不缓冲直接发送.
该方法比较适用于每次发送的数据都比较大 (但不是文件那么大), 并且频率不是特别高的场景. 如果是每次发送的数据量比较小, 并且频率特别高的, 关闭 Nagle 纯属自废武功.
另外, 该方法不适用于网络较差的情况, 因为 Nagle 算法是在服务端进行的包合并情况, 但是如果短时间内客户端的网络情况不好, 或者应用层由于某些原因不能及时将 TCP 的数据 recv, 就会造成多个包在客户端缓冲从而粘包的情况. (如果是在稳定的机房内部通信那么这个概率是比较小可以选择忽略的)
方案 3
封包/拆包是目前业内常见的解决方案了. 即给每个数据包在发送之前, 于其前/后放一些有特征的数据, 然后收到数据的时候根据特征数据分割出来各个数据包.
可靠传输
为每一个发送的数据包分配一个序列号(SYN, Synchronize packet), 每一个包在对方收到后要返回一个对应的应答数据包(ACK, Acknowledgement), 发送方如果发现某个包没有被对方 ACK, 则会选择重发. 接收方通过 SYN 序号来保证数据的不会乱序(reordering), 发送方通过 ACK 来保证数据不缺漏, 以此参考决定是否重传. 关于具体的序号计算, 丢包时的重传机制等可以参见阅读陈皓的 《TCP 的那些事儿(上)》 此处不做赘述.
window
TCP 头里有一个 Window 字段, 是接收端告诉发送端自己还有多少缓冲区可以接收数据的. 发送端就可以根据接收端的处理能力来发送数据, 从而避免接收端处理不过来. 详细参见陈皓的 《TCP 的那些事儿(下)》
window 是否设置的越大越好?
类似木桶理论, 一个木桶能装多少水, 是由最短的那块木板决定的. 一个 TCP 连接的 window 是由该连接中间一连串设备中 window 最小的那一个设备决定的.
backlog
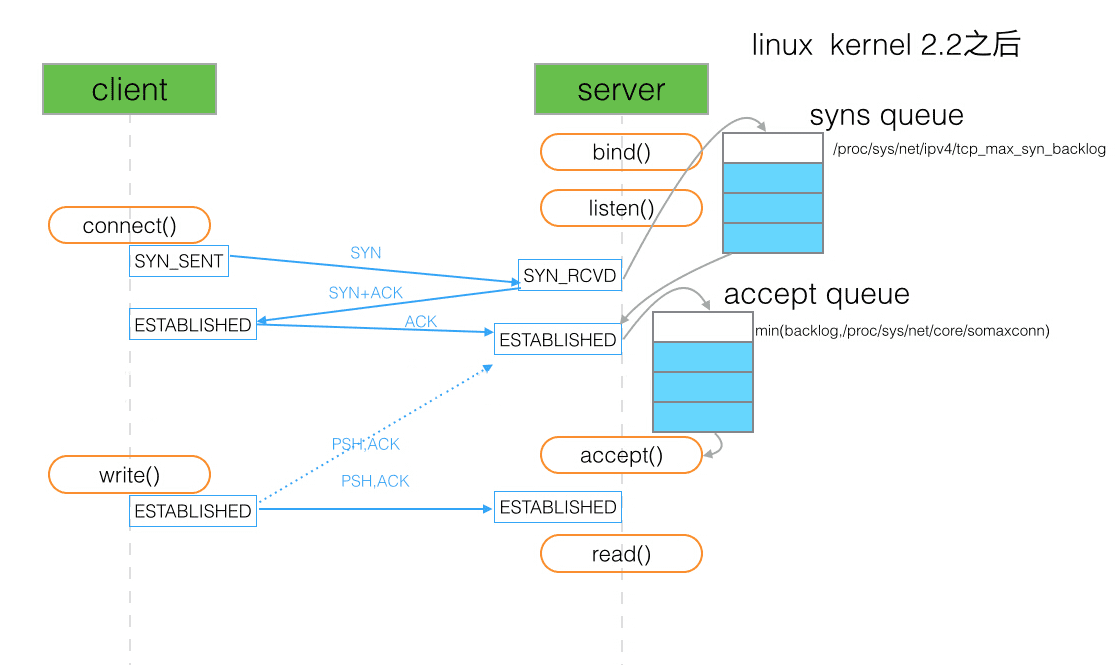
关于该 backlog 的定义参见 man 手册:
The behavior of the backlog argument on TCP sockets changed with Linux 2.2. Now it specifies the queue length for completely established sockets waiting to be accepted, instead of the number of incomplete connection requests.
backlog 用于设置客户端与服务端 ESTABLISHED 之后等待 accept 的队列长图 (如上图中的 accept queue). 如果 backlog 过小, 在并发连接大的情况下容易导致 accept queue 装满之后断开连接. 但是如果将这个队列设置的特别大, 那么假定连接数并发量是 65525, 以 php-fpm 的 qps 5000 为例, 处理完约耗时 13s, 而这段时间中连接可能早已被 nginx 或者客户端断开, 那么我们去 accept 这个 socket 时只会拿到一个 broken pipe (该例子出处见 PHP 源码 Set FPMBACKLOGDEFAULT to 511). 经过我也不懂的计算 backlog 的长度默认是 511.
另外提一句, 这个 backlog 是通过系统指定时是通过 somaxconn 参数来指定 accept queue 的. 而 tcp_max_syn_backlog 参数指定的是 SYN queue 的长度.
状态机
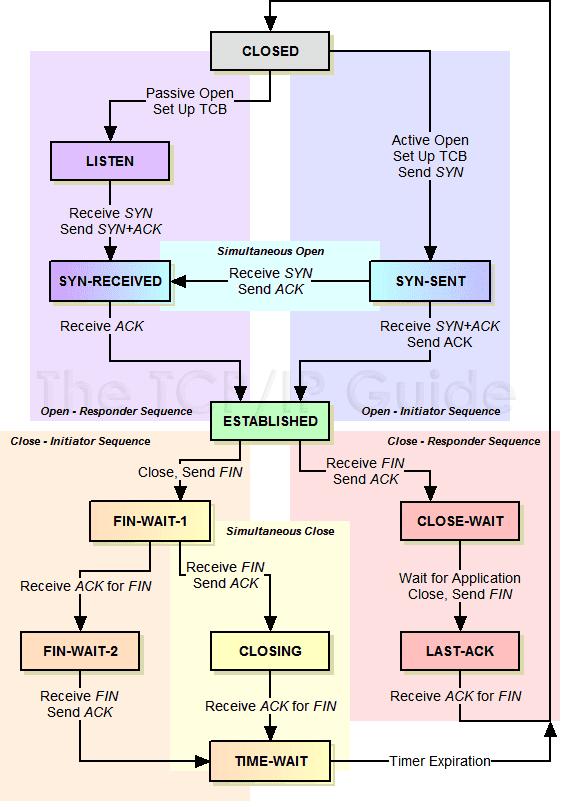
关于网络连接的建立以及断开, 存在着一个复杂的状态转换机制, 完整的状态表参见 [《The TCP/IP Guide》](http://www.tcpipguide.com/free/t_TCPOperationalOverviewandtheTCPFiniteStateMachineF-2.htm
| state | 简述 |
|---|---|
| CLOSED | 连接关闭, 所有连接的初始状态 |
| LISTEN | 监听状态, 等待客户端发送 SYN |
| SYN-SENT | 客户端发送了 SYN, 等待服务端回复 |
| SYN-RECEIVED | 双方都收到了 SYN, 等待 ACK |
| ESTABLISHED | SYN-RECEIVED 收到 ACK 之后, 状态切换为连接已建立. |
| CLOSE-WAIT | 被动方收到了关闭请求(FIN)后, 发送 ACK, 如果有数据要发送, 则发送数据, 无数据发送则回复 FIN. 状态切换到 LAST-ACK |
| LAST-ACK | 等待对方 ACK 当前设备的 CLOSE-WAIT 时发送的 FIN, 等到则切换 CLOSED |
| FIN-WAIT-1 | 主动方发送 FIN, 等待 ACK |
| FIN-WAIT-2 | 主动方收到被动方的 ACK, 等待 FIN |
| CLOSING | 主动方收到了 FIN, 却没收到 FIN-WAIT-1 时发的 ACK, 此时等待那个 ACK |
| TIME-WAIT | 主动方收到 FIN, 返回收到对方 FIN 的 ACK, 等待对方是否真的收到了 ACK, 如果过一会又来一个 FIN, 表示对方没收到, 这时要再 ACK 一次 |
TIME_WAIT是什么情况? 出现过多的TIME_WAIT可能是什么原因?
TIME_WAIT 是连接的某一方 (可能是服务端也可能是客户端) 主动断开连接时, 四次挥手等待被断开的一方是否收到最后一次挥手 (ACK) 的状态. 如果在等待时间中, 再次收到第三次挥手 (FIN) 表示对方没收到最后一次挥手, 这时要再 ACK 一次. 这个等待的作用是避免出现连接混用的情况 (prevent potential overlap with new connections see TCP Connection Termination for more).
出现大量的 TIME_WAIT 比较常见的情况是, 并发量大, 服务器在短时间断开了大量连接. 对应 HTTP server 的情况可能是没开启 keepAlive. 如果有开 keepAlive, 一般是等待客户端自己主动断开, 那么TIME_WAIT 就只存在客户端, 而服务端则是 CLOSE_WAIT 的状态, 如果服务端出现大量 CLOSE_WAIT, 意味着当前服务端建立的连接大面积的被断开, 可能是目标服务集群重启之类.
UDP
TCP/UDP 的区别? UDP 有粘包吗?
| 协议 | 连接性 | 双工性 | 可靠性 | 有序性 | 有界性 | 拥塞控制 | 传输速度 | 量级 | 头部大小 |
|---|---|---|---|---|---|---|---|---|---|
| TCP | 面向连接
(Connection oriented) |
全双工(1:1) | 可靠
(重传机制) |
有序
(通过 SYN 排序) |
无, 有 粘包情况 | 有 | 慢 | 低 | 20~60 字节 |
| UDP | 无连接
(Connection less) |
n:m | 不可靠
(丢包后数据丢失) |
无序 | 有消息边界, 无粘包 | 无 | 快 | 高 | 8 字节 |
UDP socket 支持 n 对 m 的连接状态, 在官方文档中有写到在 dgram.createSocket(options[, callback]) 中的 option 可以指定 reuseAddr 即 SO_REUSEADDR 标志. 通过 SO_REUSEADDR 可以简单的实现 n 对 m 的多播特性 (不过仅在支持多播的系统上才有).
常见的应用场景
| 传输层协议 | 应用 | 应用层协议 |
|---|---|---|
| TCP | 电子邮件 | SMTP |
| 终端连接 | TELNET | |
| 终端连接 | SSH | |
| 万维网 | HTTP | |
| 文件传输 | FTP | |
| UDP | 域名解析 | DNS |
| 简单文件传输 | TFTP | |
| 网络时间校对 | NTP | |
| 网络文件系统 | NFS | |
| 路由选择 | RIP | |
| IP电话 | - | |
| 流式多媒体通信 | - |
简单的说, UDP 速度快, 开销低, 不用封包/拆包允许丢一部分数据, 监控统计/日志数据上报/流媒体通信等场景都可以用 UDP. 目前 Node.js 的项目中使用 UDP 比较流行的是 StatsD 监控服务.
HTTP
目前世界上运行最良好的分布式集群, 莫过于当前的万维网 (http servers) 了. 目前前端工程师也都是靠 HTTP 协议吃饭的, 所以 2-3 年的前端同学都应该对 HTTP 有比较深的理解了, 所以这里不做太多的赘述. 推荐书籍《图解 HTTP》, 博客HTTP 协议入门.
另外最近几年开始大家对 HTTP 的面试的考察也渐渐偏向理解 RESTful 架构. 简单的说, RESTful 是把每个 URI 当做资源 (Resources), 通过 method 作为动词来对资源做不同的动作, 然后服务器返回 status 来得知资源状态的变化 (State Transfer);
method/status
因为 HTTP 的方法 (method) 与状态码 (status) 讲解太常见, 你可以使用如下代码打印出来自己看 Node.js 官方定义的, 完整的就不列举了.
const http = require('http');
console.log(http.METHODS);
console.log(http.STATUS_CODES);一个常见的 method 列表, 关于这些 method 在 RESTful 中的一些应用的详细可以参见Using HTTP Methods for RESTful Services
| methods | CRUD | 幂等 | 缓存 |
|---|---|---|---|
| GET | Read | ✓ | ✓ |
| POST | Create | ||
| PUT | Update/Replace | ✓ | |
| PATCH | Update/Modify | ||
| DELETE | Delete | ✓ |
GET 和 POST 有什么区别?
网上有很多讲这个的, 比如从书签, url 等前端的角度去看他们的区别这里不赘述. 而从后端的角度看, 前两年出来一个 《GET 和 POST 没有区别》(出处不好考究, 就没贴了) 的文章比较有名, 早在我刚学 PHP 的时候也有过这种疑惑, 刚学 Node 的时候发现不能像 PHP 那样同时处理 GET 和 POST 的时候还很不适应. 后来接触 RESTful 才意识到, 这两个东西最根本的差别是语义, 引申了看, 协议 (protocol) 这种东西就是人与人之间协商的约定, 什么行为是什么作用都是”约定”好的, 而不是强制使用的, 非要把 GET 当 POST 这样不遵守约定的做法我们也爱莫能助.
跑题了, 简而言之, 讨论这二者的区别最好从 RESTful 提倡的语义角度来讲比较符合当代程序员的逼格比较合理.
POST 和 PUT 有什么区别?
POST 是新建 (create) 资源, 非幂等, 同一个请求如果重复 POST 会新建多个资源. PUT 是 Update/Replace, 幂等, 同一个 PUT 请求重复操作会得到同样的结果.
headers
HTTP headers 是在进行 HTTP 请求的交互过程中互相支会对方一些信息的主要字段. 比如请求 (Request) 的时候告诉服务端自己能接受的各项参数, 以及之前就存在本地的一些数据等. 详细各位可以参见 wikipedia:
cookie 与 session 的区别? 服务端如何清除 cookie?
主要区别在于, session 存在服务端, cookie 存在客户端. session 比 cookie 更安全. 而且 cookie 不一定一直能用 (可能被浏览器关掉). 服务端可以通过设置 cookie 的值为空并设置一个及时的 expires 来清除存在客户端上的 cookie.
什么是跨域请求? 如何允许跨域?
出于安全考虑, 默认情况下使用 XMLHttpRequest 和 Fetch 发起 HTTP 请求必须遵守同源策略, 即只能向相同 host 请求 (host = hostname : port) 注[1]. 向不同 host 的请求被称作跨域请求 (cross-origin HTTP request). 可以通过设置 CORS headers 即 Access-Control-Allow- 系列来允许跨域. 例如:
location ~* ^/(?:v1|_) {
if ($request_method = OPTIONS) { return 200 ''; }
header_filter_by_lua '
ngx.header["Access-Control-Allow-Origin"] = ngx.var.http_origin; # 这样相当于允许所有来源了
ngx.header["Access-Control-Allow-Methods"] = "GET, POST, PUT, DELETE, PATCH, OPTIONS";
ngx.header["Access-Control-Allow-Credentials"] = "true";
ngx.header["Access-Control-Allow-Headers"] = "Content-Type";
';
proxy_pass http://localhost:3001;
}注[1]:同源除了相同 host 也包括相同协议. 所以即使 host 相同, 从 HTTP 到 HTTPS 也属于跨域, 见讨论.
Script error.是什么错误? 如何拿到更详细的信息?
接上题, 由于同源性策略 (CORS), 如果你引用的 js 脚本所在的域与当前域不同, 那么浏览器会把 onError 中的 msg 替换为 Script error. 要拿到详细错误的方法, 处理配好 Access-Control-Allow-Origin 还有在引用脚本的时候指定 crossorigin 例如:
<script src="http://another-domain.com/app.js" crossorigin="anonymous"></script>Agent
Node.js 中的 http.Agent 用于池化 HTTP 客户端请求的 socket (pooling sockets used in HTTP client requests). 也就是复用 HTTP 请求时候的 socket. 如果你没有指定 Agent 的话, 默认用的是 http.globalAgent.
另外, 目前在 Node.js 的 6.8.1(包括)到 6.10(不包括)版本中发现一个问题:
-
- 你将 keepAlive 设置为
true时, socket 有复用
- 你将 keepAlive 设置为
-
- 即使 keepAlive 没有设置成
true但是长时间内有大量请求时, 同样有复用 socket (复用情况参见@zcs19871221的解析)
- 即使 keepAlive 没有设置成
1 和 2 这两种情况下, 一旦设置了 request timeout, 由于 socket 一直未销毁, 如果你在请求完成以后没有注意清除该事件, 会导致事件重复监听, 且该事件闭包引用了 req, 会导致内存泄漏.
如果有疑虑的话可以参见 Node 官方讨论的 issue 以及引入此 bug 的 commit, 如果此处描述有疑问可以在本 repo 的 issue 中指出.
socket hang up
hang up 有挂断的意思, socket hang up 也可以理解为 socket 被挂断. 在 Node.js 中当你要 response 一个请求的时候, 发现该这个 socket 已经被 “挂断”, 就会就会报 socket hang up 错误.
function socketCloseListener() {
var socket = this;
var req = socket._httpMessage;
// Pull through final chunk, if anything is buffered.
// the ondata function will handle it properly, and this
// is a no-op if no final chunk remains.
socket.read();
// NOTE: It's important to get parser here, because it could be freed by
// the `socketOnData`.
var parser = socket.parser;
req.emit('close');
if (req.res && req.res.readable) {
// Socket closed before we emitted 'end' below.
req.res.emit('aborted');
var res = req.res;
res.on('end', function() {
res.emit('close');
});
res.push(null);
} else if (!req.res && !req.socket._hadError) {
// This socket error fired before we started to
// receive a response. The error needs to
// fire on the request.
req.emit('error', createHangUpError()); // <------------------- socket hang up
req.socket._hadError = true;
}
// Too bad. That output wasn't getting written.
// This is pretty terrible that it doesn't raise an error.
// Fixed better in v0.10
if (req.output) req.output.length = 0;
if (req.outputEncodings) req.outputEncodings.length = 0;
if (parser) {
parser.finish();
freeParser(parser, req, socket);
}
}典型的情况是用户使用浏览器, 请求的时间有点长, 然后用户简单的按了一下 F5 刷新页面. 这个操作会让浏览器取消之前的请求, 然后导致服务端 throw 了一个 socket hang up.
详见万能的 stackoverflow: NodeJS - What does “socket hang up” actually mean?
DNS
早期可以用 TCP/IP 通信之后, 有一个比较蛋疼的问题, 就是 ip 都是一串比较长的数字, 比较难记, 于是大家想了个办法, 给每个 ip 取个好记一点的名字比如 Alan -> 192.168.0.11 这样只需要记住好记的名字即可, 随着这个名字的规范化最终变成了今天的域名 (Domain name), 而帮助别人记录这个名字的服务就叫域名解析服务 (Domain Name Service).
DNS 服务主要基于 UDP, 这里简单介绍 Node.js 实现的接口中的两个方法:
| 方法 | 功能 | 同步 | 网络请求 | 速度 |
|---|---|---|---|---|
| .lookup(hostname [ , options ] , cb) | 通过系统自带的 DNS 缓存 (如
/etc/hosts
) |
同步 | 无 | 快 |
| .resolve(hostname [ , rrtype ] , cb) | 通过系统配置的 DNS 服务器指定的记录 (rrtype 指定) | 异步 | 有 | 慢 |
DNS 模块中 .lookup 与 .resolve 的区别?
当你要解析一个域名的 ip 时, 通过 .lookup 查询直接调用 getaddrinfo 来拿取地址, 速度很快, 但是如果本地的 hosts 文件被修改了, .lookup 就会拿 hosts 文件中的地方, 而 .resolve 依旧是外部正常的地址.
由于 .lookup 是同步的, 所以如果由于什么不可控的原因导致 getaddrinfo 缓慢或者阻塞是会影响整个 Node 进程的, 参见文档.
hosts 文件是什么? 什么叫 DNS 本地解析?
hosts 文件是个没有扩展名的系统文件, 其作用就是将网址域名与其对应的 IP 地址建立一个关联“数据库”, 当用户在浏览器中输入一个需要登录的网址时, 系统会首先自动从 hosts 文件中寻找对应的 IP 地址.
当我们访问一个域名时, 实际上需要的是访问对应的 IP 地址. 这时候, 获取 IP 地址的方式, 先是读取浏览器缓存, 如果未命中 => 接着读取本地 hosts 文件, 如果还是未命中 => 则向 DNS 服务器发送请求获取. 在向 DNS 服务器获取 IP 地址之前的行为, 叫做 DNS 本地解析.
ZLIB
在网络传输过程中, 如果网速稳定的情况下, 对数据进行压缩, 压缩比率越大, 那么传输的效率就越高等同于速度越快了. zlib 模块提供了 Gzip/Gunzip, Deflate/Inflate 和 DeflateRaw/InflateRaw 等压缩方法的类, 这些类接收相同的参数, 都属于可读写的 Stream 实例.
RPC
RPC (Remote Procedure Call Protocol) 基于 TCP/IP 来实现调用远程服务器的方法, 与 http 同属应用层. 常用于构建集群, 以及微服务 (推荐一本《Node.js 微服务》虽然我还没看完)
常见的 RPC 方式:
- Thrift
- HTTP
- MQ
Thrift
Thrift是一种接口描述语言和二进制通讯协议,它被用来定义和创建跨语言的服务。它被当作一个远程过程调用(RPC)框架来使用,是由Facebook为“大规模跨语言服务开发”而开发的。它通过一个代码生成引擎联合了一个软件栈,来创建不同程度的、无缝的跨平台高效服务,可以使用C#、C++(基于POSIX兼容系统)、Cappuccino、Cocoa、Delphi、Erlang、Go、Haskell、Java、Node.js、OCaml、Perl、PHP、Python、Ruby和Smalltalk。虽然它以前是由 Facebook 开发的,但它现在是Apache 软件基金会的开源项目了。该实现被描述在 2007 年 4 月的一篇由 Facebook 发表的技术论文中,该论文现由 Apache 掌管。
HTTP
使用 HTTP 协议来进行 RPC 调用也是很常见的, 相比 TCP 连接, 通过 HTTP 的方式性能会差一些, 但是在使用以及调试上会简单一些. 近期比较有名的框架参见 gRPC:
gRPC is an open source remote procedure call (RPC) system initially developed at Google. It uses HTTP/2 for transport, Protocol Buffers as the interface description language, and provides features such as authentication, bidirectional streaming and flow control, blocking or nonblocking bindings, and cancellation and timeouts. It generates cross-platform client and server bindings for many languages.
MQ
使用消息队列 (Message Queue) 来进行 RPC 调用 (RPC over mq) 在业内有不少例子, 比较适合业务解耦/广播/限流等场景.
OS
TTY
“tty” 原意是指 “teletype” 即打字机, “pty” 则是 “pseudo-teletype” 即伪打字机. 在 Unix 中, /dev/tty* 是指任何表现的像打字机的设备, 例如终端 (terminal).
你可以通过 w 命令查看当前登录的用户情况, 你会发现每登录了一个窗口就会有一个新的 tty.
$ w
11:49:43 up 482 days, 19:38, 3 users, load average: 0.03, 0.08, 0.07
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
dev pts/0 10.0.128.252 10:44 1:01m 0.09s 0.07s -bash
dev pts/2 10.0.128.252 11:08 2:07 0.17s 0.14s top
root pts/3 10.0.240.2 11:43 7.00s 0.04s 0.00s w使用 ps 命令查看进程信息中也有 tty 的信息:
$ ps -x
PID TTY STAT TIME COMMAND
5530 ? S 0:00 sshd: dev@pts/3
5531 pts/3 Ss+ 0:00 -bash
11296 ? S 0:00 sshd: dev@pts/4
11297 pts/4 Ss 0:00 -bash
13318 pts/4 R+ 0:00 ps -x
23733 ? Ssl 2:53 PM2 v1.1.2: God Daemon其中为 ? 的是没有依赖 TTY 的进程, 即守护进程.
在 Node.js 中你可以通过 stdio 的 isTTY 来判断当前进程是否处于 TTY (如终端) 的环境.
$ node -p -e "Boolean(process.stdout.isTTY)"
true
$ node -p -e "Boolean(process.stdout.isTTY)" | cat
falseOS
通过 OS 模块可以获取到当前系统一些基础信息的辅助函数.
| 属性 | 描述 |
|---|---|
| os.EOL | 根据当前系统, 返回当前系统的
End Of Line |
| os.arch() | 返回当前系统的 CPU 架构, 如
'x86'
和
'x64' |
| os.constants | 返回系统常量 |
| os.cpus() | 返回 CPU 每个核的信息 |
| os.endianness() | 返回 CPU 字节序, 如果是大端字节序返回
BE
, 小端字节序则
LE |
| os.freemem() | 返回系统空闲内存的大小, 单位是字节 |
| os.homedir() | 返回当前用户的根目录 |
| os.hostname() | 返回当前系统的主机名 |
| os.loadavg() | 返回负载信息 |
| os.networkInterfaces() | 返回网卡信息 (类似
ifconfig
) |
| os.platform() | 返回编译时指定的平台信息, 如
win32
,
linux
, 同
process.platform() |
| os.release() | 返回操作系统的分发版本号 |
| os.tmpdir() | 返回系统默认的临时文件夹 |
| os.totalmem() | 返回总内存大小(同内存条大小) |
| os.type() | 根据
[uname](https://en.wikipedia.org/wiki/Uname#Examples)
返回系统的名称 |
| os.uptime() | 返回系统的运行时间,单位是秒 |
| os.userInfo( [ options ] ) | 返回当前用户信息 |
不同操作系统的换行符 (EOL) 有什么区别?
end of line (EOL) 同 newline, line ending, 以及 line break.
通常由 line feed (LF, \n) 和 carriage return (CR, \r) 组成. 常见的情况:
| 符号 | 系统 |
|---|---|
| LF | 在 Unix 或 Unix 相容系统 (GNU/Linux, AIX, Xenix, Mac OS X, …)、BeOS、Amiga、RISC OS |
| CR+LF | MS-DOS、微软视窗操作系统 (Microsoft Windows)、大部分非 Unix 的系统 |
| CR | Apple II 家族, Mac OS 至版本 9 |
如果不了解 EOL 跨系统的兼容情况, 那么在处理文件的行分割/行统计等情况时可能会被坑.
OS 常量
- 信号常量 (Signal Constants), 如
SIGHUP,SIGKILL等. - POSIX 错误常量 (POSIX Error Constants), 如
EACCES,EADDRINUSE等. - Windows 错误常量 (Windows Specific Error Constants), 如
WSAEACCES,WSAEBADF等. - libuv 常量 (libuv Constants), 仅
UV_UDP_REUSEADDR.
Path
Node.js 内置的 path 是用于处理路径问题的模块. 不过众所周知, 路径在不同操作系统下有不可调和的差异.
Windows vs. POSIX
| POSIX | 值 | Windows | 值 |
|---|---|---|---|
| path.posix.sep | '/' |
path.win32.sep | '\\' |
| path.posix.normalize(‘/foo/bar//baz/asdf/quux/..‘) | '/foo/bar/baz/asdf' |
path.win32.normalize(‘C: \ temp \ \ foo \ bar \ .. \ ‘) | 'C:\\temp\\foo\\' |
| path.posix.basename(‘/tmp/myfile.html’) | 'myfile.html' |
path.win32.basename(‘C: \ temp \ myfile.html’) | 'myfile.html' |
| path.posix.join(‘/asdf’, ‘/test.html’) | '/asdf/test.html' |
path.win32.join(‘/asdf’, ‘/test.html’) | '\\asdf\\test.html' |
| path.posix.relative(‘/root/a’, ‘/root/b’) | '../b' |
path.win32.relative(‘C: \ a’, ‘c: \ b’) | '..\\b' |
| path.posix.isAbsolute(‘/baz/..‘) | true |
path.win32.isAbsolute(‘C: \ foo \ ..‘) | true |
| path.posix.delimiter | ':' |
path.win32.delimiter | ',' |
| process.env.PATH | '/usr/bin:/bin' |
process.env.PATH | C:\Windows\system32;C:\Program Files\node\' |
| PATH.split(path.posix.delimiter) | ['/usr/bin', '/bin'] |
PATH.split(path.win32.delimiter) | ['C:\\Windows\\system32', 'C:\\Program Files\\node\\'] |
看了上表之后, 你应该了解到当你处于某个平台之下的时候, 所使用的 path 模块的方法其实就是对应的平台的方法, 例如笔者这里用的是 mac, 所以:
const path = require('path');
console.log(path.basename === path.posix.basename); // true如果你处于其中某一个平台, 但是要处理另外一个平台的路径, 需要注意这个跨平台的问题.
path 对象
on POSIX:
path.parse('/home/user/dir/file.txt');
// Returns:
// {
// root : "/",
// dir : "/home/user/dir",
// base : "file.txt",
// ext : ".txt",
// name : "file"
// }┌─────────────────────┬────────────┐
│ dir │ base │
├──────┬ ├──────┬─────┤
│ root │ │ name │ ext │
" / home/user/dir / file .txt "
└──────┴──────────────┴──────┴─────┘on Windows:
path.parse('C:\\path\\dir\\file.txt');
// Returns:
// {
// root : "C:\\",
// dir : "C:\\path\\dir",
// base : "file.txt",
// ext : ".txt",
// name : "file"
// }┌─────────────────────┬────────────┐
│ dir │ base │
├──────┬ ├──────┬─────┤
│ root │ │ name │ ext │
" C:\ path\dir \ file .txt "
└──────┴──────────────┴──────┴─────┘path.extname(path)
| case | return |
|---|---|
| path.extname(‘index.html’) | '.html' |
| path.extname(‘index.coffee.md’) | '.md' |
| path.extname(‘index.‘) | '.' |
| path.extname(‘index’) | '' |
| path.extname(‘.index’) | '' |
命令行参数
命令行参数 (Command Line Options), 即对 CLI 使用上的一些文档. 关于 CLI 主要有 4 种使用方式:
- node options script.js | -e “script”
- node debug [script.js | -e “script” |
<host>:<port>] … - node —v8-options
- 无参数直接启动 REPL 环境
Options
| 参数 | 简介 |
|---|---|
| -v, —version | 查看当前 node 版本 |
| -h, —help | 查看帮助文档 |
| -e, —eval “script” | 将参数字符串当做代码执行 |
| -p, —print “script” | 打印
-e
的返回值 |
| -c, —check | 检查语法并不执行 |
| -i, —interactive | 即使 stdin 不是终端也打开 REPL 模式 |
| -r, —require module | 在启动前预先
require
指定模块 |
| —no-deprecation | 关闭废弃模块警告 |
| —trace-deprecation | 打印废弃模块的堆栈跟踪信息 |
| —throw-deprecation | 执行废弃模块时抛出错误 |
| —no-warnings | 无视报警(包括废弃警告) |
| —trace-warnings | 打印警告的 stack (包括废弃模块) |
| —trace-sync-io | 只要检测到异步 I/O 出于 Event loop 的开头就打印 stack trace |
| —zero-fill-buffers | 自动初始化(zero-fill) Buffer 和 SlowBuffer |
| —preserve-symlinks | 在解析和缓存模块时指示模块加载程序保存符号链接 |
| —track-heap-objects | 为堆快照跟踪堆对象的分配情况 |
| —prof-process | 使用 v8 选项
--prof
生成 Profilling 报告 |
| —v8-options | 显示 v8 命令行选项 |
| —tls-cipher-list=list | 指明替代的默认 TLS 加密器列表 |
| —enable-fips | 在启动时开启 FIPS-compliant crypto |
| —force-fips | 在启动时强制实施 FIPS-compliant |
| —openssl-config=file | 启动时加载 OpenSSL 配置文件 |
| —icu-data-dir=file | 指定 ICU 数据加载路径 |
环境变量
| 环境变量 | 简介 |
|---|---|
NODE_DEBUG=module[,…] |
指定要打印调试信息的核心模块列表 |
NODE_PATH=path[:…] |
指定搜索目录模块路径的前缀列表 |
NODE_DISABLE_COLORS=1 |
关闭 REPL 的颜色显示 |
NODE_ICU_DATA=file |
ICU (Intl object) 数据路径 |
NODE_REPL_HISTORY=file |
持久化存储 REPL 历史文件的路径 |
NODE_TTY_UNSAFE_ASYNC=1 |
设置为 1 时, 将同步操作 stdio (如 console.log 变成同步) |
NODE_EXTRA_CA_CERTS=file |
指定 CA (如 VeriSign) 的额外证书路径 |
负载
负载是衡量服务器运行状态的一个重要概念. 通过负载情况, 我们可以知道服务器目前状态是空闲、良好、繁忙还是即将 crash.
通常我们要查看的负载是 CPU 负载, 详细一点的情况你可以通过阅读这篇博客: Understanding Linux CPU Load 来了解.
命令行上可以通过 uptime, top 命令, Node.js 中可以通过 os.loadavg() 来获取当前系统的负载情况:
load average: 0.09, 0.05, 0.01其中分别是最近 1 分钟, 5 分钟, 15 分钟内系统 CPU 的平均负载. 当 CPU 的一个核工作饱和的时候负载为 1, 有几核 CPU 那么饱和负载就是几.
在 Node.js 中单个进程的 CPU 负载查看可以使用 pidusage 模块.
除了 CPU 负载, 对于服务端 (偏维护) 还需要了解网络负载, 磁盘负载等.
CheckList
有一个醉汉半夜在路灯下徘徊,路过的人奇怪地问他:“你在路灯下找什么?”醉汉回答:“我在找我的 KEY”,路人更奇怪了:“找钥匙为什么在路灯下?”,醉汉说:“因为这里最亮!”。
很多服务端的同学在说到检查服务器状态时只知道使用 top 命令, 其实情况就和上面的笑话一样, 因为对于他们而言 top 是最亮的那盏路灯.
对于服务端程序员而言, 完整的服务器 checklist 首推 《性能之巅》 第二章中讲述的 USE 方法.
The USE Method provides a strategy for performing a complete check of system health, identifying common bottlenecks and errors. For each system resource, metrics for utilization, saturation and errors are identified and checked. Any issues discovered are then investigated using further strategies.
This is an example USE-based metric list for Linux operating systems (eg, Ubuntu, CentOS, Fedora). This is primarily intended for system administrators of the physical systems, who are using command line tools. Some of these metrics can be found in remote monitoring tools.
Physical Resources
| component | type | metric |
|---|---|---|
| CPU | utilization | system-wide: vmstat 1, "us" + "sy" + "st"; sar -u, sum fields except "%idle" and "%iowait"; dstat -c, sum fields except "idl" and "wai"; per-cpu: mpstat -P ALL 1, sum fields except "%idle" and "%iowait"; sar -P ALL, same as mpstat; per-process: top, "%CPU"; htop, "CPU%"; ps -o pcpu; pidstat 1, "%CPU"; per-kernel-thread: top/htop ("K" to toggle), where VIRT == 0 (heuristic). [1] |
| CPU | saturation | system-wide: vmstat 1, "r" > CPU count [2]; sar -q, "runq-sz" > CPU count; dstat -p, "run" > CPU count; per-process: /proc/PID/schedstat 2nd field (sched_info.run_delay); perf sched latency (shows "Average" and "Maximum" delay per-schedule); dynamic tracing, eg, SystemTap schedtimes.stp "queued(us)" [3] |
| CPU | errors | perf (LPE) if processor specific error events (CPC) are available; eg, AMD64's "04Ah Single-bit ECC Errors Recorded by Scrubber" [4] |
| Memory capacity | utilization | system-wide: free -m, "Mem:" (main memory), "Swap:" (virtual memory); vmstat 1, "free" (main memory), "swap" (virtual memory); sar -r, "%memused"; dstat -m, "free"; slabtop -s c for kmem slab usage; per-process: top/htop, "RES" (resident main memory), "VIRT" (virtual memory), "Mem" for system-wide summary |
| Memory capacity | saturation | system-wide: vmstat 1, "si"/"so" (swapping); sar -B, "pgscank" + "pgscand" (scanning); sar -W; per-process: 10th field (min_flt) from /proc/PID/stat for minor-fault rate, or dynamic tracing [5]; OOM killer: dmesg | grep killed |
| Memory capacity | errors | dmesg for physical failures; dynamic tracing, eg, SystemTap uprobes for failed malloc()s |
| Network Interfaces | utilization | sar -n DEV 1, "rxKB/s"/max "txKB/s"/max; ip -s link, RX/TX tput / max bandwidth; /proc/net/dev, "bytes" RX/TX tput/max; nicstat "%Util" [6] |
| Network Interfaces | saturation | ifconfig, "overruns", "dropped"; netstat -s, "segments retransmited"; sar -n EDEV, *drop and *fifo metrics; /proc/net/dev, RX/TX "drop"; nicstat "Sat" [6]; dynamic tracing for other TCP/IP stack queueing [7] |
| Network Interfaces | errors | ifconfig, "errors", "dropped"; netstat -i, "RX-ERR"/"TX-ERR"; ip -s link, "errors"; sar -n EDEV, "rxerr/s" "txerr/s"; /proc/net/dev, "errs", "drop"; extra counters may be under /sys/class/net/...; dynamic tracing of driver function returns 76] |
| Storage device I/O | utilization | system-wide: iostat -xz 1, "%util"; sar -d, "%util"; per-process: iotop; pidstat -d; /proc/PID/sched "se.statistics.iowait_sum" |
| Storage device I/O | saturation | iostat -xnz 1, "avgqu-sz" > 1, or high "await"; sar -d same; LPE block probes for queue length/latency; dynamic/static tracing of I/O subsystem (incl. LPE block probes) |
| Storage device I/O | errors | /sys/devices/.../ioerr_cnt; smartctl; dynamic/static tracing of I/O subsystem response codes [8] |
| Storage capacity | utilization | swap: swapon -s; free; /proc/meminfo "SwapFree"/"SwapTotal"; file systems: "df -h" |
| Storage capacity | saturation | not sure this one makes sense - once it's full, ENOSPC |
| Storage capacity | errors | strace for ENOSPC; dynamic tracing for ENOSPC; /var/log/messages errs, depending on FS |
| Storage controller | utilization | iostat -xz 1, sum devices and compare to known IOPS/tput limits per-card |
| Storage controller | saturation | see storage device saturation, ... |
| Storage controller | errors | see storage device errors, ... |
| Network controller | utilization | infer from ip -s link (or /proc/net/dev) and known controller max tput for its interfaces |
| Network controller | saturation | see network interface saturation, ... |
| Network controller | errors | see network interface errors, ... |
| CPU interconnect | utilization | LPE (CPC) for CPU interconnect ports, tput / max |
| CPU interconnect | saturation | LPE (CPC) for stall cycles |
| CPU interconnect | errors | LPE (CPC) for whatever is available |
| Memory interconnect | utilization | LPE (CPC) for memory busses, tput / max; or CPI greater than, say, 5; CPC may also have local vs remote counters |
| Memory interconnect | saturation | LPE (CPC) for stall cycles |
| Memory interconnect | errors | LPE (CPC) for whatever is available |
| I/O interconnect | utilization | LPE (CPC) for tput / max if available; inference via known tput from iostat/ip/... |
| I/O interconnect | saturation | LPE (CPC) for stall cycles |
| I/O interconnect | errors | LPE (CPC) for whatever is available |
Software Resources
| component | type | metric |
|---|---|---|
| Kernel mutex | utilization | With CONFIG_LOCK_STATS=y, /proc/lock_stat "holdtime-totat" / "acquisitions" (also see "holdtime-min", "holdtime-max") [8]; dynamic tracing of lock functions or instructions (maybe) |
| Kernel mutex | saturation | With CONFIG_LOCK_STATS=y, /proc/lock_stat "waittime-total" / "contentions" (also see "waittime-min", "waittime-max"); dynamic tracing of lock functions or instructions (maybe); spinning shows up with profiling (perf record -a -g -F 997 ..., oprofile, dynamic tracing) |
| Kernel mutex | errors | dynamic tracing (eg, recusive mutex enter); other errors can cause kernel lockup/panic, debug with kdump/crash |
| User mutex | utilization | valgrind --tool=drd --exclusive-threshold=... (held time); dynamic tracing of lock to unlock function time |
| User mutex | saturation | valgrind --tool=drd to infer contention from held time; dynamic tracing of synchronization functions for wait time; profiling (oprofile, PEL, ...) user stacks for spins |
| User mutex | errors | valgrind --tool=drd various errors; dynamic tracing of pthread_mutex_lock() for EAGAIN, EINVAL, EPERM, EDEADLK, ENOMEM, EOWNERDEAD, ... |
| Task capacity | utilization | top/htop, "Tasks" (current); sysctl kernel.threads-max, /proc/sys/kernel/threads-max (max) |
| Task capacity | saturation | threads blocking on memory allocation; at this point the page scanner should be running (sar -B "pgscan*"), else examine using dynamic tracing |
| Task capacity | errors | "can't fork()" errors; user-level threads: pthread_create() failures with EAGAIN, EINVAL, ...; kernel: dynamic tracing of kernel_thread() ENOMEM |
| File descriptors | utilization | system-wide: sar -v, "file-nr" vs /proc/sys/fs/file-max; dstat --fs, "files"; or just /proc/sys/fs/file-nr; per-process: ls /proc/PID/fd | wc -l vs ulimit -n |
| File descriptors | saturation | does this make sense? I don't think there is any queueing or blocking, other than on memory allocation. |
| File descriptors | errors | strace errno == EMFILE on syscalls returning fds (eg, open(), accept(), ...). |
ulimit
ulimit 用于管理用户对系统资源的访问.
-a 显示目前全部限制情况
-c 设定 core 文件的最大值, 单位为区块
-d <数据节区大小> 程序数据节区的最大值, 单位为KB
-f <文件大小> shell 所能建立的最大文件, 单位为区块
-H 设定资源的硬性限制, 也就是管理员所设下的限制
-m <内存大小> 指定可使用内存的上限, 单位为 KB
-n <文件描述符数目> 指定同一时间最多可开启的 fd 数
-p <缓冲区大小> 指定管道缓冲区的大小, 单位512字节
-s <堆叠大小> 指定堆叠的上限, 单位为 KB
-S 设定资源的弹性限制
-t 指定CPU使用时间的上限, 单位为秒
-u <进程数目> 用户最多可开启的进程数目
-v <虚拟内存大小> 指定可使用的虚拟内存上限, 单位为 KB例如:
$ ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 127988
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 655360
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 4096
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited注意, open socket 等资源拿到的也是 fd, 所以 ulimit -n 比较小除了文件打不开, 还可能建立不了 socket 链接.
错误处理/调试
Errors
在 Node.js 中的错误主要有以下四种类型:
| 错误 | 名称 | 触发 |
|---|---|---|
| Standard JavaScript errors | 标准 JavaScript 错误 | 由错误代码触发 |
| System errors | 系统错误 | 由操作系统触发 |
| User-specified errors | 用户自定义错误 | 通过 throw 抛出 |
| Assertion errors | 断言错误 | 由
assert
模块触发 |
其中标准的 JavaScript 错误常见有:
- EvalError: 调用 eval() 出现错误时抛出该错误
- SyntaxError: 代码不符合 JavaScript 语法规范时抛出该错误
- RangeError: 数组越界时抛出该错误
- ReferenceError: 引用未定义的变量时抛出该错误
- TypeError: 参数类型错误时抛出该错误
- URIError: 误用全局的 URI 处理函数时抛出该错误
而常见的系统错误列表可以通过 Node.js 的 os 对象常看列表:
const os = require('os');
console.log(os.constants.errno);目前搜索 Node.js 面试题, 发现很多题目已经跟不上 Node.js 的发展了.比较老的 NodeJS 错误处理最佳实践, 译自 Joyent 的官方博客, 其中有这样的描述:
实际上,
try/catch唯一常用的是在JSON.parse和类似验证用户输入的地方
然而实际上现在在 Node.js 中你已经可以轻松的使用 try/catch 去捕获异步的异常了. 并且在 Node.js v7.6 之后使用了升级引擎的新版 v8, 旧版中 try/catch 代码不能优化的问题也解决了. 所以我们现在再来看
怎么处理未预料的出错? 用 try/catch , domains 还是其它什么?
在 Node.js 中错误处理主要有一下几种方法:
- callback(err, data) 回调约定
- throw / try / catch
- EventEmitter 的 error 事件
callback(err, data) 这种形式的错误处理起来繁琐, 并不具备强制性, 目前已经处于仅需要了解, 不推荐使用的情况. 而 domain 模块则是半只脚踏进棺材了.
-
感谢 co 的先河, 现在的你已经简单的使用 try/catch 保护关键的位置, 以 koa 为例, 可以通过中间件的形式来进行错误处理, 详见 Koa error handling. 之后的 async/await 均属于这种模式.
-
通过 EventEmitter 的错误监听形式为各大关键的对象加上错误监听的回调. 例如监听 http server, tcp server 等对象的
error事件以及 process 对象提供的uncaughtException和unhandledRejection等等. -
使用 Promise 来封装异步, 并通过 Promise 的错误处理来 handle 错误.
-
如果上述办法不能起到良好的作用, 那么你需要学习如何优雅的 Let It Crash
为什么要在 cb 的第一参数传 error? 为什么有的 cb 第一个参数不是 error, 例如 http.createServer?
错误栈丢失
function test() {
throw new Error('test error');
}
function main() {
test();
}
main();可以收获报错:
/data/node-interview/error.js:2
throw new Error('test error');
^
Error: test error
at test (/data/node-interview/error.js:2:9)
at main (/data/node-interview/error.js:6:3)
at Object.<anonymous> (/data/node-interview/error.js:9:1)
at Module._compile (module.js:570:32)
at Object.Module._extensions..js (module.js:579:10)
at Module.load (module.js:487:32)
at tryModuleLoad (module.js:446:12)
at Function.Module._load (module.js:438:3)
at Module.runMain (module.js:604:10)
at run (bootstrap_node.js:394:7)可以发现报错的行数, test 函数, main 函数的调用关系都在 stack 中清晰的体现.
当你使用 setImmediate 等定时器来设置异步的时候:
function test() {
throw new Error('test error');
}
function main() {
setImmediate(() => test());
}
main();我们发现
/data/node-interview/error.js:2
throw new Error('test error');
^
Error: test error
at test (/data/node-interview/error.js:2:9)
at Immediate.setImmediate (/data/node-interview/error.js:6:22)
at runCallback (timers.js:637:20)
at tryOnImmediate (timers.js:610:5)
at processImmediate [as _immediateCallback] (timers.js:582:5)错误栈中仅输出到 test 函数内调用的地方位置, 再往上 main 的调用信息就丢失了. 也就是说如果你的函数调用深度比较深的情况下, 你使用异步调用某个函数出错了的情况下追溯这个异步的调用是一个很困难的事情, 因为其之上的栈都已经丢失了. 如果你用过 async 之类的模块, 你还可能发现, 报错的 stack 会非常的长而且曲折, 光看 stack 很难去定位问题.
这在项目不大/作者清楚的情况下不是问题, 但是当项目大起来, 开发人员多起来之后, 这样追溯错误会变得异常痛苦. 关于这个问题, 在上文中提到 错误处理的最佳实践 中, 关于 编写新函数的具体建议 那一带的内容有描述到. 通过使用 verror 这样的方式, 让 Error 一层层封装, 并在每一层将错误的信息一层层的包上, 最后拿到的 Error 直接可以从 message 中获取用于定位问题的关键信息.
以昨天的数据为准(2017-3-13)各位只要对比一下看看 npm 上上个月 verror 的下载量 1100w 比 express 的 1070w 还高. 应该就能感受到这种写法有多流行了.
防御性编程
错误并不可怕, 可怕的是你不去准备应对错误————防御性编程的介绍和技巧
let it crash
uncaughtException
当异常没有被捕获一路冒泡到 Event Loop 时就会触发该事件 process 对象上的 uncaughtException 事件. 默认情况下, Node.js 对于此类异常会直接将其堆栈跟踪信息输出给 stderr 并结束进程, 而为 uncaughtException 事件添加监听可以覆盖该默认行为, 不会直接结束进程.
process.on('uncaughtException', (err) => {
console.log(`Caught exception: ${err}`);
});
setTimeout(() => {
console.log('This will still run.');
}, 500);
// Intentionally cause an exception, but don't catch it.
nonexistentFunc();
console.log('This will not run.');合理使用 uncaughtException
uncaughtException 的初衷是可以让你拿到错误之后可以做一些回收处理之后再 process.exit. 官方的同志们还曾经讨论过要移除该事件 (详见 issues)
所以你需要明白 uncaughtException 其实已经是非常规手段了, 应尽量避免使用它来处理错误. 因为通过该事件捕获到错误后, 并不代表 你可以愉快的继续运行 (On Error Resume Next). 程序内部存在未处理的异常, 这意味着应用程序处于一种未知的状态. 如果不能适当的恢复其状态, 那么很有可能会触发不可预见的问题. (使用 domain 会很夸张的加剧这个现象, 并产生新人不能理解的各类幽灵问题)
如果在 .on 指定的监听回调中报错不会被捕获, Node.js 的进程会直接终断并返回一个非零的退出码, 最后输出相应的堆栈信息. 否则, 会出现无限递归. 除此之外, 内存崩溃/底层报错等情况也不会被捕获, 目前猜测是 v8/C++ 那边撂担子不干了, Node.js 完全插不上话导致的 (TODO 整理到这里才想起来这个念头尚未验证, 如果有空的朋友帮忙验证下).
所以官方建议的使用 uncaughtException 的正确姿势是在结束进程前使用同步的方式清理已使用的资源 (文件描述符、句柄等) 然后 process.exit.
在 uncaughtException 事件之后执行普通的恢复操作并不安全. 官方建议是另外在专门准备一个 monitor 进程来做健康检查并通过 monitor 来管理恢复情况, 并在必要的时候重启 (所以官方是含蓄的提醒各位用 pm2 之类的工具).
unhandledRejection
当 Promise 被 reject 且没有绑定监听处理时, 就会触发该事件. 该事件对排查和追踪没有处理 reject 行为的 Promise 很有用.
该事件的回调函数接收以下参数:
reason<Error>|<any>该 Promise 被 reject 的对象 (通常为 Error 对象)p被 reject 的 Promise 本身
例如
process.on('unhandledRejection', (reason, p) => {
console.log('Unhandled Rejection at: Promise', p, 'reason:', reason);
// application specific logging, throwing an error, or other logic here
});
somePromise.then((res) => {
return reportToUser(JSON.pasre(res)); // note the typo (`pasre`)
}); // no `.catch` or `.then`以下代码也会触发 unhandledRejection 事件:
function SomeResource() {
// Initially set the loaded status to a rejected promise
this.loaded = Promise.reject(new Error('Resource not yet loaded!'));
}
var resource = new SomeResource();
// no .catch or .then on resource.loaded for at least a turnIn this example case, it is possible to track the rejection as a developer error as would typically be the case for other ‘unhandledRejection’ events. To address such failures, a non-operational
.catch(() => { })handler may be attached to resource.loaded, which would prevent the ‘unhandledRejection’ event from being emitted. Alternatively, the ‘rejectionHandled’ event may be used.
Domain
Node.js 早期, try/catch 无法捕获异步的错误, 而错误优先的 callback 仅仅是一种约定并没有强制性并且写起来十分繁琐. 所以为了能够很好的捕获异常, Node.js 从 v0.8 开始引入 domain 这个模块.
domain 本身是一个 EventEmitter 对象, 其中文意思是 “域” 的意思, 捕获异步异常的基本思路是创建一个域, cb 函数会在定义时会继承上一层的域, 报错通过当前域的 .emit('error', err) 方法触发错误事件将错误传递上去, 从而使得异步错误可以被强制捕获. (更多内容详见 Node.js 异步异常的处理与 domain 模块解析)
但是 domain 的引入也带来了更多新的问题. 比如依赖的模块无法继承你定义的 domain, 导致你写的 domain 无法 cover 依赖模块报错. 而且, 很多人 (特别是新人) 由于不了解 Node.js 的内存/异步流程等问题, 在使用 domain 处理报错的时候, 没有做到完善的处理并盲目的让代码继续走下去, 这很可能导致项目完全无法维护 (可能出现的问题真是不胜枚举, 各种梦魇…)
该模块目前的情况: deprecate domains
Debugger
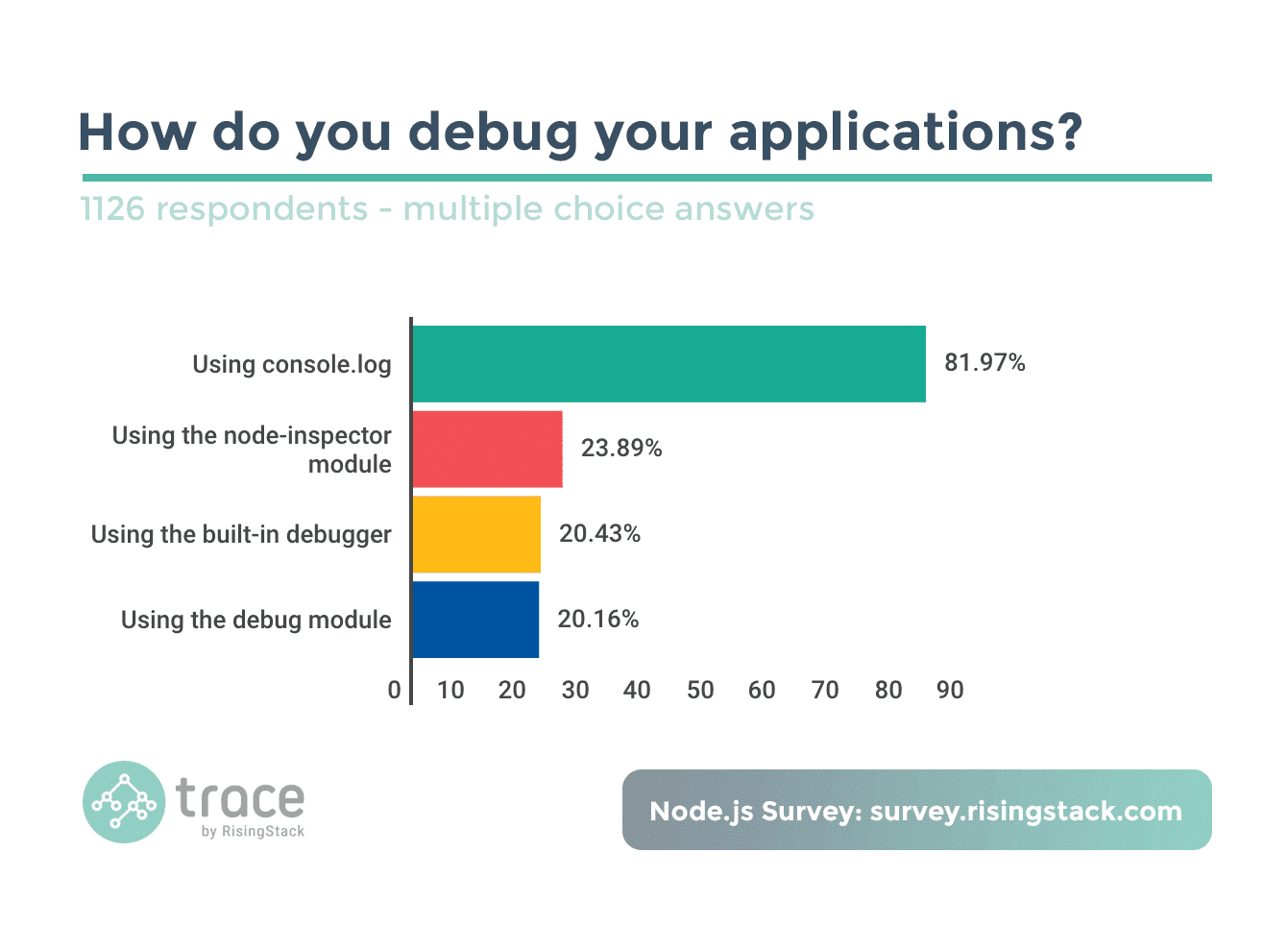
类似 gdb 的命令行下 debug 工具 (上图中的 build-in debugger), 同时也支持远程 debug (类似 node-inspector, 目前处于试验状态). 当然, 目前有不少同学觉得 vscode 对 debug 工具集成的比较好.
关于这个 build-in debugger 使用推荐看官方文档. 如果要深入一点, 你可能对本文感兴趣: 动态修改 NodeJS 程序中的变量值
C/C++ Addon
在 Node.js 中开发 addon 最痛苦的地方莫过于升级 V8 导致的 C/C++ 代码不能兼容的问题, 这个问题在很早就出现了. 为了解决这个问题前人开了一个叫 nan 的项目.
要学习 addon 开发, 除了官方文档也推荐阅读这个: https://github.com/nodejs/node-addon-examples
V8
这里并不是介绍 V8, 而是介绍 Node.js 中的 V8 这个模块. 该模块用于开放 Node.js 内建的 V8 引擎的事件和接口. 这些接口由 V8 底层决定, 所以无法保证绝对的稳定性.
| 接口 | 描述 |
|---|---|
| v8.getHeapStatistics() | 获取 heap 信息 |
| v8.getHeapSpaceStatistics() | 获取 heap space 信息 |
| v8.setFlagsFromString(string) | 动态设置 V8 options |
v8.setFlagsFromString(string)
该方法用于添加额外的 V8 命令行标志. 该方法需谨慎使用, 在 VM 启动后修改配置可能会发生不可预测的行为、崩溃和数据丢失; 或者什么反应都没有.
通过 node --v8-options 命令可以查询当前 Node.js 环境中有哪些可用的 V8 options. 此外, 还可以参考非官方维护的一个 V8 options 列表.
用法:
// Print GC events to stdout for one minute.
const v8 = require('v8');
v8.setFlagsFromString('--trace_gc');
setTimeout(function() {
v8.setFlagsFromString('--notrace_gc');
}, 60e3);内存快照
内存快照常用与解决内存泄漏的问题. 快照工具推荐使用 heapdump 用来保存内存快照, 使用 devtool 来查看内存快照. 使用 heapdump 保存内存快照时, 只会有 Node.js 环境中的对象, 不会受到干扰(如果使用 node-inspector 的话, 快照中会有前端的变量干扰).
使用以及内存泄漏的常见原因详见: 如何分析 Node.js 中的内存泄漏.
CPU profiling
CPU profiling (剖析) 常用于性能优化. 有许多用于做 profiling 的第三方工具, 但是大部分情况下, 使用 Node.js 内置的是最简单的. 其内置调用的就是 V8 本身的 profiler, 它可以在程序执行过程中中是对 stack 间隔性的抽样分析.
使用 --prof 开启内置的 profilling
node --prof app.js程序运行之后会生成一个 isolate-0xnnnnnnnnnnnn-v8.log 在当前运行目录.
你可以使用 --prof-process 来生成报告查看
node --prof-process isolate-0xnnnnnnnnnnnn-v8.log报告形如:
Statistical profiling result from isolate-0x103001200-v8.log, (12042 ticks, 2634 unaccounted, 0 excluded).
[Shared libraries]:
ticks total nonlib name
35 0.3% /usr/lib/system/libsystem_platform.dylib
27 0.2% /usr/lib/system/libsystem_pthread.dylib
7 0.1% /usr/lib/system/libsystem_c.dylib
3 0.0% /usr/lib/system/libsystem_kernel.dylib
1 0.0% /usr/lib/system/libsystem_malloc.dylib
[JavaScript]:
ticks total nonlib name
208 1.7% 1.7% Stub: LoadICStub
187 1.6% 1.6% KeyedLoadIC: A keyed load IC from the snapshot
104 0.9% 0.9% Stub: VectorStoreICStub
69 0.6% 0.6% LazyCompile: *emit events.js:136:44
68 0.6% 0.6% Builtin: CallFunction_ReceiverIsNotNullOrUndefined
65 0.5% 0.5% KeyedStoreIC: A keyed store IC from the snapshot {2}
47 0.4% 0.4% Builtin: CallFunction_ReceiverIsAny
43 0.4% 0.4% LazyCompile: *storeHeader _http_outgoing.js:312:21
34 0.3% 0.3% LazyCompile: *removeListener events.js:315:28
33 0.3% 0.3% Stub: RegExpExecStub
33 0.3% 0.3% LazyCompile: *_addListener events.js:210:22
32 0.3% 0.3% Stub: CEntryStub
32 0.3% 0.3% Builtin: ArgumentsAdaptorTrampoline
31 0.3% 0.3% Stub: FastNewClosureStub
30 0.2% 0.3% Stub: InstanceOfStub
...
[C++]:
ticks total nonlib name
460 3.8% 3.8% _mach_port_extract_member
329 2.7% 2.7% _openat$NOCANCEL
199 1.7% 1.7% ___bsdthread_register
136 1.1% 1.1% ___mkdir_extended
116 1.0% 1.0% node::HandleWrap::Close(v8::FunctionCallbackInfo<v8::Value> const&)
112 0.9% 0.9% void v8::internal::BodyDescriptorBase::IterateBodyImpl<v8::internal::StaticScavengeVisitor>(v8::internal::Heap*, v8::internal::HeapObject*, int, int)
106 0.9% 0.9% _http_parser_execute
103 0.9% 0.9% _szone_malloc_should_clear
99 0.8% 0.8% int v8::internal::BinarySearch<(v8::internal::SearchMode)1, v8::internal::DescriptorArray>(v8::internal::DescriptorArray*, v8::internal::Name*, int, int*)
89 0.7% 0.7% node::TCPWrap::Connect(v8::FunctionCallbackInfo<v8::Value> const&)
86 0.7% 0.7% v8::internal::LookupIterator::State v8::internal::LookupIterator::LookupInRegularHolder<false>(v8::internal::Map*, v8::internal::JSReceiver*)
...
[Bottom up (heavy) profile]:
Note: percentage shows a share of a particular caller in the total
amount of its parent calls.
Callers occupying less than 2.0% are not shown.
ticks parent name
2634 21.9% UNKNOWN
764 29.0% LazyCompile: *connect net.js:815:17
764 100.0% LazyCompile: ~<anonymous> net.js:966:30
764 100.0% LazyCompile: *_tickCallback internal/process/next_tick.js:87:25
193 7.3% LazyCompile: *createWriteReq net.js:732:24
101 52.3% LazyCompile: *Socket._writeGeneric net.js:660:42
99 98.0% LazyCompile: ~<anonymous> net.js:667:34
99 100.0% LazyCompile: ~g events.js:287:13
99 100.0% LazyCompile: *emit events.js:136:44
92 47.7% LazyCompile: ~Socket._writeGeneric net.js:660:42
91 98.9% LazyCompile: ~<anonymous> net.js:667:34
91 100.0% LazyCompile: ~g events.js:287:13
91 100.0% LazyCompile: *emit events.js:136:44
...| 字段 | 描述 |
|---|---|
| ticks | 时间片 |
| total | 当前操作执行的时间占总时间的比率 |
| nonlib | 当前非 System library 执行时间比率 |
util
URL
┌─────────────────────────────────────────────────────────────────────────────┐
│ href │
├──────────┬┬───────────┬─────────────────┬───────────────────────────┬───────┤
│ protocol ││ auth │ host │ path │ hash │
│ ││ ├──────────┬──────┼──────────┬────────────────┤ │
│ ││ │ hostname │ port │ pathname │ search │ │
│ ││ │ │ │ ├─┬──────────────┤ │
│ ││ │ │ │ │ │ query │ │
" http: // user:pass @ host.com : 8080 /p/a/t/h ? query=string #hash "
│ ││ │ │ │ │ │ │ │
└──────────┴┴───────────┴──────────┴──────┴──────────┴─┴──────────────┴───────┘转义字符
常见的需要转义的字符列表:
| 字符 | encodeURI |
|---|---|
' ' |
'%20' |
< |
'%3C' |
> |
'%3E' |
" |
'%22' |
| ` | '%60' |
\r |
'%0D' |
\n |
'%0A' |
\t |
'%09' |
{ |
'%7B' |
} |
'%7D' |
| |
'%7C' |
\\ |
'%5C' |
^ |
'%5E' |
' |
'%27' |
想了解更多? 你可以这样:
Array(range)
.fill(0)
.map((_, i) => String.fromCharCode(i))
.map(encodeURI);Query Strings
query string 属于 URL 的一部分, 见上方 URL 的表. 在 Node.js 中有内置提供一个 querystring 的模块.
| 方法 | 描述 |
|---|---|
| .parse(str[, sep[, eq [ , options ] ]]) | 将一个 query string 解析为 json 对象 |
| .unescape(str) | 供 .parse 调用的内置解转义方法, 暴露出来以供用户自行替代 |
| .stringify(obj[, sep[, eq [ , options ] ]]) | 将一个 json 对象转换成 query string |
| .escape(str) | 供 .stringify 调用的内置转义方法, 暴露出来以供用户自行替代 |
Node.js 内置的 querystring 目前对于有深度的结构尚不支持. 见如下:
const qs = require('qs'); // 第三方
const querystring = require('querystring'); // Node.js 内置
let obj = { a: { b: { c: 1 } } };
console.log(qs.stringify(obj)); // 'a%5Bb%5D%5Bc%5D=1'
console.log(querystring.stringify(obj)); // 'a='
let str = 'a%5Bb%5D%5Bc%5D=1';
console.log(qs.parse(str)); // { a: { b: { c: '1' } } }
console.log(querystring.parse(str)); // { 'a[b][c]': '1' }const qs = require('qs');
let arr = [1, 2, 3, 4];
let str = qs.stringify({ arr });
console.log(str); // arr%5B0%5D=1&arr%5B1%5D=2&arr%5B2%5D=3&arr%5B3%5D=4
console.log(decodeURI(str)); // 'arr[0]=1&arr[1]=2&arr[2]=3&arr[3]=4'
console.log(qs.parse(str)); // { arr: [ '1', '2', '3', '4' ] }通过 https://your.host/api/?arr[0]=1&arr[1]=2&arr[2]=3&arr[3]=4 即可传递把 arr 数组传递给服务器
util
util.is*() 从 v4.0.0 开始被不建议使用即将废弃 (deprecated). 大概的废弃原因, 笔者个人认为是维护这些功能吃力不讨好, 而且现在流行的轮子那么多. 那么一下是具体列表:
- util.debug(string)
- util.error([…strings])
- util.isArray(object)
- util.isBoolean(object)
- util.isBuffer(object)
- util.isDate(object)
- util.isError(object)
- util.isFunction(object)
- util.isNull(object)
- util.isNullOrUndefined(object)
- util.isNumber(object)
- util.isObject(object)
- util.isPrimitive(object)
- util.isRegExp(object)
- util.isString(object)
- util.isSymbol(object)
- util.isUndefined(object)
- util.log(string)
- util.print([…strings])
- util.puts([…strings])
- util._extend(target, source)
其中大部分都可以作为面试题来问如何实现.
util.inherits
Node.js 中继承 (util.inherits) 的实现?
https://github.com/nodejs/node/blob/v7.6.0/lib/util.js#L960
/**
* Inherit the prototype methods from one constructor into another.
*
* The Function.prototype.inherits from lang.js rewritten as a standalone
* function (not on Function.prototype). NOTE: If this file is to be loaded
* during bootstrapping this function needs to be rewritten using some native
* functions as prototype setup using normal JavaScript does not work as
* expected during bootstrapping (see mirror.js in r114903).
*
* @param {function} ctor Constructor function which needs to inherit the
* prototype.
* @param {function} superCtor Constructor function to inherit prototype from.
* @throws {TypeError} Will error if either constructor is null, or if
* the super constructor lacks a prototype.
*/
exports.inherits = function(ctor, superCtor) {
if (ctor === undefined || ctor === null)
throw new TypeError('The constructor to "inherits" must not be ' + 'null or undefined');
if (superCtor === undefined || superCtor === null)
throw new TypeError('The super constructor to "inherits" must not ' + 'be null or undefined');
if (superCtor.prototype === undefined)
throw new TypeError('The super constructor to "inherits" must ' + 'have a prototype');
ctor.super_ = superCtor;
Object.setPrototypeOf(ctor.prototype, superCtor.prototype);
};正则表达式
正则表达式最早生物学上用来描述大脑神经元的一种表达式, 被 GNU 的大胡子拿来做字符串匹配之后在原本的道路上渐行渐远.
整理中..
常用模块
Awesome Node.js Most depended-upon packages
一个简单的例子:
const fs = require('fs');
const path = require('path');
function traversal(dir) {
let res = [];
for (let item of fs.readdirSync(dir)) {
let filepath = path.join(dir, item);
try {
let fd = fs.openSync(filepath, 'r');
let flag = fs.fstatSync(fd).isDirectory();
fs.close(fd);
if (flag) {
res.push(...traversal(filepath));
} else {
res.push(filepath);
}
} catch (err) {
if (
err.code === 'ENOENT' && // link 文件打不开
!!fs.readlinkSync(filepath)
) {
// 判断是否 link 文件
res.push(filepath);
} else {
console.error('err', err);
}
}
}
return res.map((file) => path.basename(file));
}
console.log(traversal('.'));当然也可以 Oh my glob:
const glob = require('glob');
glob('**/*.js', (err, files) => {
if (err) {
throw new Error(err);
}
files.map((filename) => {
console.log('Here you are:', filename);
});
});存储
简介
科班的同学可以了解一下数据库范式, 在 ElemeFe 面试不会问, 但是其他地方可能会问 (比如阿里).
Mysql
SQL (Structured Query Language) 是关系式数据库管理系统的标准语言, 关于关系型数据库这里主要带大家看一下 Mysql 的几个问题
存储引擎
| attr | MyISAM | InnoDB |
|---|---|---|
| Locking | Table-level | Row-level |
| designed for | need of speed | high volume of data |
| foreign keys | × (DBMS) | ✓ (RDBMS) |
| transaction | × | ✓ |
| fulltext search | ✓ | × |
| scene | lots of select | lots of insert/update |
| count rows | fast | slow |
| auto_increment | fast | slow |
- 你的数据库有外键吗?
- 你需要事务支持吗?
- 你需要全文索引吗?
- 你经常使用什么样的查询模式?
- 你的数据有多大?
索引
索引是用空间换时间的一种优化策略. 推荐阅读: mysql 索引类型 以及 主键与唯一索引的区别
Mongodb
Monogdb 连接问题(超时/断开等)有可能是什么问题导致的?
- 网络问题
- 任务跑不完, 超过了 driver 的默认链接超时时间 (如 30s)
- Monogdb 宕机了
- 超过了连接空闲时间 (connection idle time) 被断开
- fd 不够用 (ulimit 设置)
- mongodb 最大连接数不够用 (可能是连接未复用导致)
- etc…
other
populate
aggregate
pipeline
Cursor
整理中
Replication
备份数据库与 M/S, M/M 等部署方式的区别?
关于数据库基于各种模式的特点全部可以通过以下图片分清:
图片出处:Google App Engine 的 co-founder Ryan Barrett 在 2009 年的 google i/o 上的演讲 《Transaction Across DataCenter》(视频: http://www.youtube.com/watch?v=srOgpXECblk)
根据上图, 我们可以知道 Master/Slave 与 Master/Master 的关系.
| attr | Master/Slave | Master/Master |
|---|---|---|
| 一致性 | Eventually:当你写入一个新值后,有可能读不出来,但在某个时间窗口之后保证最终能读出来。比如:DNS,电子邮件、Amazon S3,Google搜索引擎这样的系统。 | |
| 事务 | 完整 | 本地 |
| 延迟 | 低延迟 | |
| 吞吐 | 高吞吐 | |
| 数据丢失 | 部分丢失 | |
| 熔断 | 只读 | 读/写 |
读写分离
读写分离是在 query 量大的情况下减轻单个 DB 节点压力, 优化数据库读/写速度的一种策略. 不论是 MySQL 还是 MongoDB 都可以进行读写分离.
读写分离的配置方式直接搜索一下 数据库名 + 读写分离 即可找到. 通常是 M/S 的情况, 使用 Master 专门写, 用 Slave 节点专门读. 使用读写分离时, 请确认读的请求对一致性要求不高, 因为从写库同步读库是有延迟的.
数据一致性
关于数据一致性推荐看陈皓的分布式系统的事务处理
什么情况下数据会出现脏数据? 如何避免?
- 从 A 帐号中把余额读出来
- 对 A 帐号做减法操作
- 把结果写回 A 帐号中
- 从 B 帐号中把余额读出来
- 对 B 帐号做加法操作
- 把结果写回 B 帐号中
为了数据的一致性, 这 6 件事, 要么都成功做完, 要么都不成功, 而且这个操作的过程中, 对 A、B 帐号的其它访问必需锁死, 所谓锁死就是要排除其它的读写操作, 否则就会出现脏数据 ---- 即数据一致性的问题.
这个问题并不仅仅出现在数据库操作中, 普通的并发以及并行操作都可能导致出现脏数据. 避免出现脏数据通常是从架构上避免或者采用事务的思想处理.
矛盾
- 1)要想让数据有高可用性,就得写多份数据
- 2)写多份的问题会导致数据一致性的问题
- 3)数据一致性的问题又会引发性能问题
强一致性必然导致性能短板, 而弱一致性则有很好的性能但是存在数据安全(灾备数据丢失)/一致性(脏读/脏写等)的问题.
目前 Node.js 业内流行的主要是与 Mongodb 配合, 在数据一致性方面属于短板.
事务
事务并不仅仅是 sql 数据库中的一个功能, 也是分布式系统开发中的一个思想, 事务在分布式的问题中可以称为 “两阶段提交” (以下引用陈皓原文)
第一阶段:
- 协调者会问所有的参与者结点,是否可以执行提交操作。
- 各个参与者开始事务执行的准备工作:如:为资源上锁,预留资源,写 undo/redo log……
- 参与者响应协调者,如果事务的准备工作成功,则回应“可以提交”,否则回应“拒绝提交”。
第二阶段:
- 如果所有的参与者都回应“可以提交”,那么,协调者向所有的参与者发送“正式提交”的命令。参与者完成正式提交,并释放所有资源,然后回应“完成”,协调者收集各结点的“完成”回应后结束这个 Global Transaction。
- 如果有一个参与者回应“拒绝提交”,那么,协调者向所有的参与者发送“回滚操作”,并释放所有资源,然后回应“回滚完成”,协调者收集各结点的“回滚”回应后,取消这个 Global Transaction。
异常:
- 如果第一阶段中,参与者没有收到询问请求,或是参与者的回应没有到达协调者。那么,需要协调者做超时处理,一旦超时,可以当作失败,也可以重试。
- 如果第二阶段中,正式提交发出后,如果有的参与者没有收到,或是参与者提交/回滚后的确认信息没有返回,一旦参与者的回应超时,要么重试,要么把那个参与者标记为问题结点剔除整个集群,这样可以保证服务结点都是数据一致性的。
- 第二阶段中,如果参与者收不到协调者的 commit/fallback 指令,参与者将处于“状态未知”阶段,参与者完全不知道要怎么办。
缓存
redis 与 memcached 的区别?
| attr | memcached | redis |
|---|---|---|
| struct | key/value | key/value + list, set, hash etc. |
| backup | × | ✓ |
| Persistence | × | ✓ |
| transcations | × | ✓ |
| consistency | strong (by cas) | weak |
| thread | multi | single |
| memory | physical | physical & swap |
其他
- zookeeper
- kafka
- storm
- hadoop
- spark
安全
Crypto
Node.js 的 crypto 模块封装了诸多的加密功能, 包括 OpenSSL 的哈希、HMAC、加密、解密、签名和验证函数等.
Node.js 的加密貌似有点问题, 某些算法算出来跟别的语言 (比如 Python) 不一样. 具体情况还在整理中 (时间不定), 欢迎补充.
加密是如何保证用户密码的安全性?
在客户端加密, 是增加传输的过程中被第三方嗅探到密码后破解的成本. 对于游戏, 在客户端加密是防止外挂/破解等. 在服务端加密 (如 md5) 是避免管理数据库的 DBA 或者攻击者攻击数据库之后直接拿到明文密码, 从而提高安全性.
TLS/SSL
早期的网络传输协议由于只在大学内使用, 所以是默认互相信任的. 所以传统的网络通信可以说是没有考虑网络安全的. 早年的浏览器大厂网景公司为了应对这个情况设计了 SSL (Secure Socket Layer), SSL 的主要用途是:
- 认证用户和服务器, 确保数据发送到正确的客户机和服务器;
- 加密数据以防止数据中途被窃取;
- 维护数据的完整性, 确保数据在传输过程中不被改变.
存在三个特性:
- 机密性:SSL 协议使用密钥加密通信数据
- 可靠性:服务器和客户都会被认证, 客户的认证是可选的
- 完整性:SSL 协议会对传送的数据进行完整性检查
1999 年, SSL 因为应用广泛, 已经成为互联网上的事实标准. IETF 就在那年把 SSL 标准化/强化. 标准化之后的名称改为传输层安全协议 (Transport Layer Security, TLS). 很多相关的文章都把这两者并列称呼 (TLS/SSL), 因为这两者可以视作同一个东西的不同阶段.
HTTPS
在网络上, 每个网站都在各自的服务器上, 想要确保你访问的是一个正确的网站, 并且访问到这个网站正确的数据 (没有被劫持/篡改), 除了需要传输安全之外, 还需要安全的认证, 认证不能由目标网站进行, 否则恶意/钓鱼网站也可以自己说自己是对的, 所以为了能在网络上维护网络之间的基本信任, 早期的大厂们合力推动了一项名为 PKI 的基础设施, 通过第三方来认证网站.
公钥基础设施 (Public Key Infrastructure, PKI) 是一种遵循标准的, 利用公钥加密技术为电子商务的开展提供一套安全基础平台的技术和规范. 其基础建置包含认证中心 (Certification Authority, CA) 、注册中心 (Register Authority, RA) 、目录服务 (Directory Service, DS) 服务器.
由 RA 统筹、审核用户的证书申请, 将证书申请送至 CA 处理后发出证书, 并将证书公告至 DS 中. 在使用证书的过程中, 除了对证书的信任关系与证书本身的正确性做检查外, 并透过产生和发布证书废止列表 (Certificate Revocation List, CRL) 对证书的状态做确认检查, 了解证书是否因某种原因而遭废弃. 证书就像是个人的身分证, 其内容包括证书序号、用户名称、公开金钥 (Public Key) 、证书有效期限等.
在 TLS/SSL 中你可以使用 OpenSSL 来生成 TLS/SSL 传输时用来认证的 public/private key. 不过这个 public/private key 是自己生成的, 而通过 PKI 基础设施可以获得权威的第三方证书 (key) 从而加密 HTTP 传输安全. 目前博客圈子里比较流行的是 Let’s Encrypt 签发免费的 HTTPS 证书.
需要注意的是, 如果 PKI 受到攻击, 那么 HTTPS 也一样不安全. 可以参见 HTTPS 劫持 - 知乎讨论 中的情况, 证书由 CA 机构签发, 一般浏览器遇到非权威的 CA 机构是会告警的 (参见 12306), 但是如果你在某些特殊的情况下信任了某个未知机构/证书, 那么也可能被劫持.
此外有的 CA 机构以邮件方式认证, 那么当某个网站的邮件服务收到攻击/渗透, 那么攻击者也可能以此从 CA 机构获取权威的正确的证书.
XSS
跨站脚本 (Cross-Site Scripting, XSS) 是一种代码注入方式, 为了与 CSS 区分所以被称作 XSS. 早期常见于网络论坛, 起因是网站没有对用户的输入进行严格的限制, 使得攻击者可以将脚本上传到帖子让其他人浏览到有恶意脚本的页面, 其注入方式很简单包括但不限于 JavaScript / VBScript / CSS / Flash 等.
当其他用户浏览到这些网页时, 就会执行这些恶意脚本, 对用户进行 Cookie 窃取/会话劫持/钓鱼欺骗等各种攻击. 其原理, 如使用 js 脚本收集当前用户环境的信息 (Cookie 等), 然后通过 img.src, Ajax, onclick/onload/onerror 事件等方式将用户数据传递到攻击者的服务器上. 钓鱼欺骗则常见于使用脚本进行视觉欺骗, 构建假的恶意的 Button 覆盖/替换真实的场景等情况 (该情况在用户上传 CSS 的时候也可能出现, 如早期淘宝网店装修, 使用 CSS 拼接假的评分数据等覆盖在真的评分数据上误导用户).
过滤 Html 标签能否防止 XSS? 请列举不能的情况?
用户除了上传
<script>
alert('xss');
</script>还可以使用图片 url 等方式来上传脚本进行攻击
<table background="javascript:alert(/xss/)"></table>
<img src="javascript:alert('xss')" />还可以使用各种方式来回避检查, 例如空格, 回车, Tab
<img
src="javas cript:
alert('xss')"
/>还可以通过各种编码转换 (URL 编码, Unicode 编码, HTML 编码, ESCAPE 等) 来绕过检查
<img%20src=%22javascript:alert('xss');%22>
<img src="javascript:alert(/xss/)">CSP 策略
在百般无奈, 没有统一解决方案的情况下, 厂商们推出了 CSP 策略.
以 Node.js 为例, 计算脚本的 hashes 值:
const crypto = require('crypto');
function getHashByCode(code, algorithm = 'sha256') {
return (
algorithm +
'-' +
crypto
.createHash(algorithm)
.update(code, 'utf8')
.digest('base64')
);
}
getHashByCode('console.log("hello world");'); // 'sha256-wxWy1+9LmiuOeDwtQyZNmWpT0jqCUikqaqVlJdtdh/0='设置 CSP 头:
content-security-policy: script-src 'sha256-wxWy1+9LmiuOeDwtQyZNmWpT0jqCUikqaqVlJdtdh/0='<script>
console.log('hello geemo');
</script>
<!-- 不执行 -->
<script>
console.log('hello world');
</script>
<!-- 执行 -->策略指令可以参见 CSP Policy Directives以及阮一峰的博文, 屈大神的博文
CSRF
跨站请求伪造 (Cross-Site Request Forgery, CSRF, https://www.owasp.org/index.php/Cross-Site_Request_Forgery_(CSRF)_Prevention_Cheat_Sheet) 是一种伪造跨站请求的攻击方式. 例如利用你在 A 站 (攻击目标) 的 cookie / 权限等, 在 B 站 (恶意/钓鱼网站) 拼装 A 站的请求.
比如 Q 君是某论坛管理员. 已知这个论坛 A 删除的接口是 post 到某个地址, 并指定一个帖子的 id. 那么我可以在自己的博客 B 上组织一个 CSRF 请求. 然后诱使 Q 君来访问我的博客. 就可以在 Q 君不知情的情况下删除掉我想删的某个帖子.
钓鱼方式包括但不限于公开网站 (xss), 攻击者的恶意网站, email 邮件, 微博, 微信, 短信等及时消息.
同源策略是最早用于防止 CSRF 的一种方式, 即关于跨站请求 (Cross-Site Request) 只有在同源/信任的情况下才可以请求. 但是如果一个网站群, 在互相信任的情况下, 某个网站出现了问题:
a.public.com
b.public.com
c.public.com
...以上情况下, 如果 c.public.com 上没有预防 xss 等情况, 使得攻击者可以基于此站对其他信任的网站发起 CSRF 攻击.
另外同源策略主要是浏览器来进行验证的, 并且不同浏览器的实现又各自不同, 所以在某些浏览器上可以直接绕过, 而且也可以直接通过短信等方式直接绕过浏览器.
预防:
- A 站 (预防站) 检查 http 请求的 header 确认其 origin
- 检查 CSRF token
1.同源检查
通过检查来过滤简单的 CSRF 攻击, 主要检查一下两个 header:
- Origin Header
- Referer Header
2.CSRF token
简单来说, 对需要预防的请求, 通过特别的算法生成 token 存在 session 中, 然后将 token 隐藏在正确的界面表单中, 正式请求时带上该 token 在服务端验证, 避免跨站请求.
中间人攻击
中间人 (Man-in-the-middle attack, MITM) 是指攻击者与通讯的两端分别创建独立的联系, 并交换其所收到的数据, 使通讯的两端认为他们正在通过一个私密的连接与对方直接对话, 但事实上整个会话都被攻击者完全控制. 在中间人攻击中, 攻击者可以拦截通讯双方的通话并插入新的内容.
目前比较常见的是在公共场所放置精心准备的免费 wifi, 劫持/监控通过该 wifi 的流量. 或者攻击路由器, 连上你家 wifi 攻破你家 wifi 之后在上面劫持流量等.
对于通信过程中的 MITM, 常见的方案是通过 PKI / TLS 预防, 及时是通过存在第三方中间人的 wifi 你通过 HTTPS 访问的页面依旧是安全的. 而 HTTP 协议是明文传输, 则没有任何防护可言.
不常见的还有强力的互相认证, 你确认他之后, 他也确认你一下; 延迟测试, 统计传输时间, 如果通讯延迟过高则认为可能存在第三方中间人; 等等.
SQL/NoSQL 注入
注入攻击是指当所执行的一些操作中有部分由用户传入时, 用户可以将其恶意逻辑注入到操作中. 当你使用 eval, new Function 等方式执行的字符串中有用户输入的部分时, 就可能被注入攻击. 上文中的 XSS 就属于一种注入攻击. 前面的章节中也提到过 Node.js 的 child_process.exec 由于调用 bash 解析, 如果执行的命令中有部分属于用户输入, 也可能被注入攻击.
SQL
Sql 注入是网站常见的一种注入攻击方式. 其原因主要是由于登录时需要验证用户名/密码, 其执行 sql 类似:
SELECT * FROM users WHERE usernae = 'myName' AND password = 'mySecret';其中的用户名和密码属于用户输入的部分, 那么在未做检查的情况下, 用户可能拼接恶意的字符串来达到其某种目的, 例如上传密码为 '; DROP TABLE users; -- 使得最终执行的内容为:
SELECT * FROM users WHERE usernae = 'myName' AND password = ''; DROP TABLE users; --';其能实现的功能, 包括但不限于删除数据 (经济损失), 篡改数据 (密码等), 窃取数据 (网站管理权限, 用户数据) 等. 防治手段常见于:
- 给表名/字段名加前缀 (避免被猜到)
- 报错隐藏表信息 (避免被看到, 12306 早期就出现过的问题)
- 过滤可以拼接 SQL 的关键字符
- 对用户输入进行转义
- 验证用户输入的类型 (避免 limit, order by 等注入)
NoSQL
看个简单的情况:
let { user, pass, age } = ctx.query;
db.collection.find({
user,
pass,
$where: `this.age >= ${age}`
});那么这里的 age 就可以注入了. 另外 GET/POST 还可以传递深层结构 (比如 ?name[0]=alan 传递上来), 通过 qs 之类的模块解析后导致注入, 如 cnodejs 遭遇 mongodb 注入.