防抖
前言
在前端开发中会遇到一些频繁的事件触发,比如:
- window 的 resize、scroll
- mousedown、mousemove
- keyup、keydown
为此,我们举个示例代码来了解事件如何频繁的触发:
我们写个 index.html 文件:
<!DOCTYPE html>
<html lang="zh-cmn-Hans">
<head>
<meta charset="utf-8" />
<meta http-equiv="x-ua-compatible" content="IE=edge, chrome=1" />
<title>debounce</title>
<style>
#container {
width: 100%;
height: 200px;
line-height: 200px;
text-align: center;
color: #fff;
background-color: #444;
font-size: 30px;
}
</style>
</head>
<body>
<div id="container"></div>
<script src="debounce.js"></script>
</body>
</html>debounce.js 文件的代码如下:
var count = 1;
var container = document.getElementById('container');
function getUserAction() {
container.innerHTML = count++;
}
container.onmousemove = getUserAction;我们来看看效果:

从左边滑到右边就触发了 165 次 getUserAction 函数!
因为这个例子很简单,所以浏览器完全反应的过来,可是如果是复杂的回调函数或是 ajax 请求呢?假设 1 秒触发了 60 次,每个回调就必须在 1000 / 60 = 16.67ms 内完成,否则就会有卡顿出现。
为了解决这个问题,一般有两种解决方案:
- debounce 防抖
- throttle 节流
防抖
今天重点讲讲防抖的实现。
防抖的原理就是:你尽管触发事件,但是我一定在事件触发 n 秒后才执行,如果你在一个事件触发的 n 秒内又触发了这个事件,那我就以新的事件的时间为准,n 秒后才执行,总之,就是要等你触发完事件 n 秒内不再触发事件,我才执行
第一版
根据这段表述,我们可以写第一版的代码:
// 第一版
function debounce(func, wait) {
var timeout;
return function() {
clearTimeout(timeout);
timeout = setTimeout(func, wait);
};
}如果我们要使用它,以最一开始的例子为例:
container.onmousemove = debounce(getUserAction, 1000);现在随你怎么移动,反正你移动完 1000ms 内不再触发,我才执行事件。看看使用效果:

顿时就从 165 次降成了 1 次!
this
如果我们在 getUserAction 函数中 console.log(this),在不使用 debounce 函数的时候,this 的值为:
<div id='container'></div>但是如果使用我们的 debounce 函数,this 就会指向 Window 对象!
所以我们需要将 this 指向正确的对象。
我们修改下代码:
// 第二版
function debounce(func, wait) {
var timeout;
return function() {
var context = this;
clearTimeout(timeout);
timeout = setTimeout(function() {
func.apply(context);
}, wait);
};
}event 对象
JavaScript 在事件处理函数中会提供事件对象 event,我们修改下 getUserAction 函数:
function getUserAction(e) {
console.log(e);
container.innerHTML = count++;
}如果我们不使用 debouce 函数,这里会打印 MouseEvent 对象,如图所示:

但是在我们实现的 debounce 函数中,却只会打印 undefined!
所以我们再修改一下代码:
// 第二版
function debounce(func, wait) {
var timeout;
return function() {
var context = this;
var args = arguments;
clearTimeout(timeout);
timeout = setTimeout(function() {
func.apply(context, args);
}, wait);
};
}到此为止,我们修复了两个小问题:
- this 指向
- event 对象
立刻执行
这个时候,代码已经很是完善了,但是为了让这个函数更加完善,我们接下来思考一个新的需求。
这个需求就是:
我不希望非要等到事件停止触发后才执行,我希望立刻执行函数,然后等到停止触发 n 秒后,才可以重新触发执行。
想想这个需求也是很有道理的嘛,那我们加个 immediate 参数判断是否是立刻执行。
// 第四版,immediate 代表停止触发 n 秒后立即执行
function debounce(func, wait, immediate) {
var timeout;
return function() {
var context = this;
var args = arguments;
if (timeout) clearTimeout(timeout);
if (immediate) {
// 如果已经执行过,不再执行
var callNow = !timeout;
// 拿 click 事件为例,如果传递的 immediate 为 true, 那么连续点击过程中仅在第一次点击时执行,后面的点击会被 if (timeout) clearTimeout(timeout); 拦截,点击再多次都不会再次执行;当停止点击 wait 毫秒后,设置 timeout = null; 恢复初始时的状态,这次的第一次点击就不会被 if (timeout) clearTimeout(timeout); 拦截。所以这句必须要加,是比较关键的代码。
timeout = setTimeout(function() {
timeout = null;
}, wait);
if (callNow) func.apply(context, args);
} else {
timeout = setTimeout(function() {
func.apply(context, args);
}, wait);
}
};
}再来看看使用效果:

返回值
此时注意一点,就是 getUserAction 函数可能是有返回值的,所以我们也要返回函数的执行结果,但是当 immediate 为 false 的时候,因为使用了 setTimeout ,我们将 func.apply(context, args) 的返回值赋给变量,最后再 return 的时候,值将会一直是 undefined,所以我们只在 immediate 为 true 的时候返回函数的执行结果。
// 第五版
function debounce(func, wait, immediate) {
var timeout, result;
return function() {
var context = this;
var args = arguments;
if (timeout) clearTimeout(timeout);
if (immediate) {
// 如果已经执行过,不再执行
var callNow = !timeout;
timeout = setTimeout(function() {
timeout = null;
}, wait);
if (callNow) result = func.apply(context, args);
} else {
timeout = setTimeout(function() {
func.apply(context, args);
}, wait);
}
return result;
};
}取消
最后我们再思考一个小需求,我希望能取消 debounce 函数,比如说我 debounce 的时间间隔是 10 秒钟,immediate 为 true,这样的话,我只有等 10 秒后才能重新触发事件,现在我希望有一个按钮,点击后,取消防抖,这样我再去触发,就可以又立刻执行啦,是不是很开心?
为了这个需求,我们写最后一版的代码:
// 第六版
function debounce(func, wait, immediate) {
var timeout, result;
var debounced = function() {
var context = this;
var args = arguments;
if (timeout) {
clearTimeout(timeout);
}
if (immediate) {
// 如果已经执行过,不再执行
var callNow = !timeout;
timeout = setTimeout(function() {
timeout = null;
}, wait);
if (callNow) result = func.apply(context, args);
} else {
timeout = setTimeout(function() {
func.apply(context, args);
}, wait);
}
return result;
};
debounced.cancel = function() {
clearTimeout(timeout);
timeout = null;
};
return debounced;
}那么该如何使用这个 cancel 函数呢?依然是以上面的 demo 为例:
var count = 1;
var container = document.getElementById('container');
function getUserAction(e) {
container.innerHTML = count++;
}
var setUseAction = debounce(getUserAction, 10000, true);
container.onmousemove = setUseAction;
document.getElementById('button').addEventListener('click', function() {
setUseAction.cancel();
});演示效果如下:

至此我们已经完整实现了一个 underscore 中的 debounce 函数,恭喜,撒花!
节流
节流的原理很简单:
如果你持续触发事件,每隔一段时间,只执行一次事件。
根据首次是否执行以及结束后是否执行,效果有所不同,实现的方式也有所不同。我们用 leading 代表首次是否执行,trailing 代表结束后是否再执行一次。
关于节流的实现,有两种主流的实现方式,一种是使用时间戳,一种是设置定时器。
使用时间戳
让我们来看第一种方法:使用时间戳,当触发事件的时候,我们取出当前的时间戳,然后减去之前的时间戳(最一开始值设为 0 ),如果大于设置的时间周期,就执行函数,然后更新时间戳为当前的时间戳,如果小于,就不执行。
看了这个表述,是不是感觉已经可以写出代码了…… 让我们来写第一版的代码:
// 第一版
function throttle(func, wait) {
var previous = 0;
return function() {
var now = +new Date();
var context = this;
var args = arguments;
if (now - previous > wait) {
func.apply(context, args);
previous = now;
}
};
}例子依然是用讲 debounce 中的例子,如果你要使用:
container.onmousemove = throttle(getUserAction, 1000);效果演示如下:

我们可以看到:当鼠标移入的时候,事件立刻执行,每过 1s 会执行一次,如果在 4.2s 停止触发,以后不会再执行事件。
使用定时器
接下来,我们讲讲第二种实现方式,使用定时器。
当触发事件的时候,我们设置一个定时器,再触发事件的时候,如果定时器存在,就不执行,直到定时器执行,然后执行函数,清空定时器,这样就可以设置下个定时器。
// 第一版
function throttle(func, wait) {
var timer;
return function() {
var context = this;
var args = arguments;
if (!timer) {
timer = setTimeout(function() {
func.apply(context, args);
timer = null;
}, wait);
}
};
}为了让效果更加明显,我们设置 wait 的时间为 3s,效果演示如下:

我们可以看到:当鼠标移入的时候,事件不会立刻执行,晃了 3s 后终于执行了一次,此后每 3s 执行一次,当数字显示为 3 的时候,立刻移出鼠标,相当于大约 9.2s 的时候停止触发,但是依然会在第 12s 的时候执行一次事件。
所以比较两个方法:
- 第一种事件会立刻执行,第二种事件会在 n 秒后第一次执行
- 第一种事件停止触发后没有办法再执行事件,第二种事件停止触发后依然会再执行一次事件
双剑合璧
那我们想要一个什么样的呢?
有人就说了:我想要一个有头有尾的!就是鼠标移入能立刻执行,停止触发的时候还能再执行一次!
所以我们综合两者的优势,然后双剑合璧,写一版代码:
// 第三版
function throttle(func, wait) {
var timeout, context, args;
var previous = 0;
var later = function() {
previous = +new Date();
timeout = null;
func.apply(context, args);
};
var throttled = function() {
var now = +new Date();
// 下次触发 func 剩余的时间
var remaining = wait - (now - previous);
context = this;
args = arguments;
// 如果没有剩余的时间了或者你改了系统时间
if (remaining <= 0 || remaining > wait) {
if (timeout) {
clearTimeout(timeout);
timeout = null;
}
previous = now;
func.apply(context, args);
} else if (!timeout) {
timeout = setTimeout(later, remaining);
}
};
return throttled;
}效果演示如下:

我们可以看到:鼠标移入,事件立刻执行,晃了 3s,事件再一次执行,当数字变成 3 的时候,也就是 6s 后,我们立刻移出鼠标,停止触发事件,9s 的时候,依然会再执行一次事件。
优化
但是我有时也希望无头有尾,或者有头无尾,这个咋办?
那我们设置个 options 作为第三个参数,然后根据传的值判断到底哪种效果,我们约定:
- leading:false 表示禁用第一次执行
- trailing: false 表示禁用停止触发的回调
我们来改一下代码:
// 第四版
function throttle(func, wait, options) {
var timeout, context, args;
var previous = 0;
if (!options) options = {};
var later = function() {
// 这个作用?
previous = options.leading === false ? 0 : new Date().getTime();
timeout = null;
func.apply(context, args);
if (!timeout) {
context = args = null;
}
};
var throttled = function() {
var now = new Date().getTime();
if (!previous && options.leading === false) {
previous = now;
}
var remaining = wait - (now - previous);
context = this;
args = arguments;
if (remaining <= 0 || remaining > wait) {
// 因为 setTimeOut 有误差,所以有可能到时间了定时器还没有执行,就会进入时间戳判断逻辑,所以要把定时器删掉
if (timeout) {
clearTimeout(timeout);
timeout = null;
}
previous = now;
func.apply(context, args);
if (!timeout) {
context = args = null;
}
} else if (!timeout && options.trailing !== false) {
timeout = setTimeout(later, remaining);
}
};
return throttled;
}取消
在 debounce 的实现中,我们加了一个 cancel 方法,throttle 我们也加个 cancel 方法:
throttled.cancel = function() {
clearTimeout(timeout);
previous = 0;
timeout = null;
};注意
我们要注意 underscore 的实现中有这样一个问题:
那就是 leading:false 和 trailing: false 不能同时设置。
如果同时设置的话,比如当你将鼠标移出的时候,因为 trailing 设置为 false,停止触发的时候不会设置定时器,所以只要再过了设置的时间,再移入的话,就会立刻执行,就违反了 leading: false,bug 就出来了,所以,这个 throttle 只有三种用法:
container.onmousemove = throttle(getUserAction, 1000);
container.onmousemove = throttle(getUserAction, 1000, {
leading: false
});
container.onmousemove = throttle(getUserAction, 1000, {
trailing: false
});数组去重
双层循环
var array = [1, 1, '1', '1'];
function unique(array) {
// res用来存储结果
var res = [];
for (var i = 0, arrayLen = array.length; i < arrayLen; i++) {
for (var j = 0, resLen = res.length; j < resLen; j++) {
// 相等说明可能有重复值
if (array[i] === res[j]) {
break;
}
}
// 如果 array[i] 是唯一的,那么执行完循环,j 等于resLen
if (j === resLen) {
res.push(array[i]);
}
}
return res;
}
console.log(unique(array)); // [1, "1"]在这个方法中,我们使用循环嵌套,最外层循环 array,里面循环 res,如果 array[i] 的值跟 res[j] 的值相等,就跳出循环,如果都不等于,说明元素是唯一的,这时候 j 的值就会等于 res 的长度,根据这个特点进行判断,将值添加进 res。
看起来很简单吧,之所以要讲一讲这个方法,是因为——————兼容性好!
indexOf
我们可以用 indexOf 简化内层的循环:
var array = [1, 1, '1'];
function unique(array) {
var res = [];
for (var i = 0, len = array.length; i < len; i++) {
var current = array[i];
if (res.indexOf(current) === -1) {
res.push(current);
}
}
return res;
}
console.log(unique(array));排序后去重
试想我们先将要去重的数组使用 sort 方法排序后,相同的值就会被排在一起,然后我们就可以只判断当前元素与上一个元素是否相同,相同就说明重复,不相同就添加进 res,让我们写个 demo:
var array = [1, 1, '1'];
function unique(array) {
var res = [];
var sortedArray = array.concat().sort();
var seen;
for (var i = 0, len = sortedArray.length; i < len; i++) {
// 如果是第一个元素或者相邻的元素不相同
if (!i || seen !== sortedArray[i]) {
res.push(sortedArray[i]);
}
seen = sortedArray[i];
}
return res;
}
console.log(unique(array));如果我们对一个已经排好序的数组去重,这种方法效率肯定高于使用 indexOf。
unique API
知道了这两种方法后,我们可以去尝试写一个名为 unique 的工具函数,我们根据一个参数 isSorted 判断传入的数组是否是已排序的,如果为 true,我们就判断相邻元素是否相同,如果为 false,我们就使用 indexOf 进行判断
var array1 = [1, 2, '1', 2, 1];
var array2 = [1, 1, '1', 2, 2];
// 第一版
function unique(array, isSorted) {
var res = [];
var seen = [];
for (var i = 0, len = array.length; i < len; i++) {
var value = array[i];
if (isSorted) {
if (!i || seen !== value) {
res.push(value);
}
seen = value;
} else if (res.indexOf(value) === -1) {
res.push(value);
}
}
return res;
}
console.log(unique(array1)); // [1, 2, "1"]
console.log(unique(array2, true)); // [1, "1", 2]优化
尽管 unqique 已经可以试下去重功能,但是为了让这个 API 更加强大,我们来考虑一个需求:
新需求:字母的大小写视为一致,比如’a’和’A’,保留一个就可以了!
虽然我们可以先处理数组中的所有数据,比如将所有的字母转成小写,然后再传入 unique 函数,但是有没有方法可以省掉处理数组的这一遍循环,直接就在去重的循环中做呢?让我们去完成这个需求:
var array3 = [1, 1, 'a', 'A', 2, 2];
// 第二版
// iteratee 英文释义:迭代 重复
function unique(array, isSorted, iteratee) {
var res = [];
var seen = [];
for (var i = 0, len = array.length; i < len; i++) {
var value = array[i];
var computed = iteratee ? iteratee(value, i, array) : value;
if (isSorted) {
if (!i || seen !== computed) {
res.push(value);
}
seen = computed;
} else if (iteratee) {
if (seen.indexOf(computed) === -1) {
seen.push(computed);
res.push(value);
}
} else if (res.indexOf(value) === -1) {
res.push(value);
}
}
return res;
}
console.log(
unique(array3, false, function(item) {
return typeof item == 'string' ? item.toLowerCase() : item;
})
); // [1, "a", 2]在这一版也是最后一版的实现中,函数传递三个参数:
array:表示要去重的数组,必填
isSorted:表示函数传入的数组是否已排过序,如果为 true,将会采用更快的方法进行去重
iteratee:传入一个函数,可以对每个元素进行重新的计算,然后根据处理的结果进行去重
至此,我们已经仿照着 underscore 的思路写了一个 unique 函数,具体可以查看 Github。
filter
ES5 提供了 filter 方法,我们可以用来简化外层循环:
比如使用 indexOf 的方法:
var array = [1, 2, 1, 1, '1'];
function unique(array) {
var res = array.filter(function(item, index, array) {
return array.indexOf(item) === index;
});
return res;
}
console.log(unique(array));排序去重的方法:
var array = [1, 2, 1, 1, '1'];
function unique(array) {
return array
.concat()
.sort()
.filter(function(item, index, array) {
return !index || item !== array[index - 1];
});
}
console.log(unique(array));Object 键值对
去重的方法众多,尽管我们已经跟着 underscore 写了一个 unqiue API,但是让我们看看其他的方法拓展下视野:
这种方法是利用一个空的 Object 对象,我们把数组的值存成 Object 的 key 值,比如 Object[value1] = true,在判断另一个值的时候,如果 Object[value2] 存在的话,就说明该值是重复的。示例代码如下:
var array = [1, 2, 1, 1, '1'];
function unique(array) {
var obj = {};
return array.filter(function(item, index, array) {
return obj.hasOwnProperty(item) ? false : (obj[item] = true);
});
}
console.log(unique(array)); // [1, 2]我们可以发现,是有问题的,因为 1 和 ‘1’ 是不同的,但是这种方法会判断为同一个值,这是因为对象的键值只能是字符串,所以我们可以使用 typeof item + item 拼成字符串作为 key 值来避免这个问题:
var array = [1, 2, 1, 1, '1'];
function unique(array) {
var obj = {};
return array.filter(function(item, index, array) {
return obj.hasOwnProperty(typeof item + item) ? false : (obj[typeof item + item] = true);
});
}
console.log(unique(array)); // [1, 2, "1"]然而,即便如此,我们依然无法正确区分出两个对象,比如 {value: 1} 和 {value: 2},因为 typeof item + item 的结果都会是 object[object Object],不过我们可以使用 JSON.stringify 将对象序列化:
var array = [{ value: 1 }, { value: 1 }, { value: 2 }];
function unique(array) {
var obj = {};
return array.filter(function(item, index, array) {
console.log(typeof item + JSON.stringify(item));
return obj.hasOwnProperty(typeof item + JSON.stringify(item))
? false
: (obj[typeof item + JSON.stringify(item)] = true);
});
}
console.log(unique(array)); // [{value: 1}, {value: 2}]ES6
随着 ES6 的到来,去重的方法又有了进展,比如我们可以使用 Set 和 Map 数据结构,以 Set 为例,ES6 提供了新的数据结构 Set。它类似于数组,但是成员的值都是唯一的,没有重复的值。
是不是感觉就像是为去重而准备的?让我们来写一版:
var array = [1, 2, 1, 1, '1'];
function unique(array) {
return Array.from(new Set(array));
}
console.log(unique(array)); // [1, 2, "1"]甚至可以再简化下:
function unique(array) {
return [...new Set(array)];
}还可以再简化下:
var unique = (a) => [...new Set(a)];此外,如果用 Map 的话:
function unique(arr) {
const seen = new Map();
return arr.filter((a) => !seen.has(a) && seen.set(a, 1));
}JavaScript 的进化
我们可以看到,去重方法从原始的 14 行代码到 ES6 的 1 行代码,其实也说明了 JavaScript 这门语言在不停的进步,相信以后的开发也会越来越高效。
特殊类型比较
去重的方法就到此结束了,然而要去重的元素类型可能是多种多样,除了例子中简单的 1 和 ‘1’ 之外,其实还有 null、undefined、NaN、对象等,那么对于这些元素,之前的这些方法的去重结果又是怎样呢?
在此之前,先让我们先看几个例子:
var str1 = '1';
var str2 = new String('1');
console.log(str1 == str2); // true
console.log(str1 === str2); // false
console.log(null == null); // true
console.log(null === null); // true
console.log(undefined == undefined); // true
console.log(undefined === undefined); // true
console.log(NaN == NaN); // false
console.log(NaN === NaN); // false
console.log(/a/ == /a/); // false
console.log(/a/ === /a/); // false
console.log({} == {}); // false
console.log({} === {}); // false那么,对于这样一个数组
var array = [1, 1, '1', '1', null, null, undefined, undefined, new String('1'), new String('1'), /a/, /a/, NaN, NaN];以上各种方法去重的结果到底是什么样的呢?
我特地整理了一个列表,我们重点关注下对象和 NaN 的去重情况:
| 方法 | 结果 | 说明 |
|---|---|---|
| for 循环 | [ 1, “1”, null, undefined, String, String, /a/, /a/, NaN, NaN ] | 对象和 NaN 不去重 |
| indexOf | [ 1, “1”, null, undefined, String, String, /a/, /a/, NaN, NaN ] | 对象和 NaN 不去重 |
| sort | [ /a/, /a/, “1”, 1, String, 1, String, NaN, NaN, null, undefined ] | 对象和 NaN 不去重 数字 1 也不去重 |
| filter + indexOf | [ 1, “1”, null, undefined, String, String, /a/, /a/ ] | 对象不去重 NaN 会被忽略掉 |
| filter + sort | [ /a/, /a/, “1”, 1, String, 1, String, NaN, NaN, null, undefined ] | 对象和 NaN 不去重 数字 1 不去重 |
| 优化后的键值对方法 | [ 1, “1”, null, undefined, String, /a/, NaN ] | 全部去重 |
| Set | [ 1, “1”, null, undefined, String, String, /a/, /a/, NaN ] | 对象不去重、NaN 去重 |
想了解为什么会出现以上的结果,看两个 demo 便能明白:
// demo1
var arr = [1, 2, NaN];
arr.indexOf(NaN); // -1indexOf 底层还是使用 === 进行判断,因为 NaN === NaN 的结果为 false,所以使用 indexOf 查找不到 NaN 元素
// demo2
function unique(array) {
return Array.from(new Set(array));
}
console.log(unique([NaN, NaN])); // [NaN]Set 认为尽管 NaN === NaN 为 false,但是这两个元素是重复的。
类型判断
类型判断在 web 开发中有非常广泛的应用,简单的有判断数字还是字符串,进阶一点的有判断数组还是对象,再进阶一点的有判断日期、正则、错误类型,再再进阶一点还有比如判断 plainObject、空对象、Window 对象等等。
typeof
我们最最常用的莫过于 typeof,注意尽管我们会看到诸如:
console.log(typeof 'yayu'); // string的写法,但是 typeof 可是一个正宗的运算符,就跟加减乘除一样!这就能解释为什么下面这种写法也是可行的:
console.log(typeof 'yayu'); // string引用《JavaScript 权威指南》中对 typeof 的介绍:
typeof 是一元操作符,放在其单个操作数的前面,操作数可以是任意类型。返回值为表示操作数类型的一个字符串。
那我们都知道,在 ES6 前,JavaScript 共六种数据类型,分别是:
Undefined、Null、Boolean、Number、String、Object
然而当我们使用 typeof 对这些数据类型的值进行操作的时候,返回的结果却不是一一对应,分别是:
undefined、object、boolean、number、string、object
注意以上都是小写的字符串。Null 和 Object 类型都返回了 object 字符串。
尽管不能一一对应,但是 typeof 却能检测出函数类型:
function a() {}
console.log(typeof a); // function所以 typeof 能检测出六种类型的值,但是,除此之外 Object 下还有很多细分的类型呐,如 Array、Function、Date、RegExp、Error 等。
如果用 typeof 去检测这些类型,举个例子:
var date = new Date();
var error = new Error();
console.log(typeof date); // object
console.log(typeof error); // object返回的都是 object 呐,这可怎么区分~ 所以有没有更好的方法呢?
Object.prototype.toString
是的,当然有!这就是 Object.prototype.toString!
那 Object.protototype.toString 究竟是一个什么样的方法呢?
为了更加细致的讲解这个函数,让我先献上 ES5 规范地址:https://es5.github.io/#x15.2.4.2。
在第 15.2.4.2 节讲的就是 Object.prototype.toString(),为了不误导大家,我先奉上英文版:
When the toString method is called, the following steps are taken:
- If the
thisvalue isundefined, return"[object Undefined]".- If the
thisvalue isnull, return"[object Null]".- Let O be the result of calling ToObject passing the
thisvalue as the argument.- Let class be the value of the [[Class]] internal property of O.
- Return the String value that is the result of concatenating the three Strings
"[object ", class, and "]".
凡是规范上加粗或者斜体的,在这里我也加粗或者斜体了,就是要让大家感受原汁原味的规范!
如果没有看懂,就不妨看看我理解的:
当 toString 方法被调用的时候,下面的步骤会被执行:
- 如果 this 值是 undefined,就返回 [object Undefined]
- 如果 this 的值是 null,就返回 [object Null]
- 让 O 成为 ToObject(this) 的结果
- 让 class 成为 O 的内部属性 [[Class]] 的值
- 最后返回由 ”[object ” 和 class 和 ”]” 三个部分组成的字符串
通过规范,我们至少知道了调用 Object.prototype.toString 会返回一个由 ”[object ” 和 class 和 ”]” 组成的字符串,而 class 是要判断的对象的内部属性。
让我们写个 demo:
console.log(Object.prototype.toString.call(undefined)); // [object Undefined]
console.log(Object.prototype.toString.call(null)); // [object Null]
var date = new Date();
console.log(Object.prototype.toString.call(date)); // [object Date]由此我们可以看到这个 class 值就是识别对象类型的关键!
正是因为这种特性,我们可以用 Object.prototype.toString 方法识别出更多类型!
那到底能识别多少种类型呢?
至少 12 种!
// 以下是 11 种:
var number = 1; // [object Number]
var string = '123'; // [object String]
var boolean = true; // [object Boolean]
var und = undefined; // [object Undefined]
var nul = null; // [object Null]
var obj = { a: 1 }; // [object Object]
var array = [1, 2, 3]; // [object Array]
var date = new Date(); // [object Date]
var error = new Error(); // [object Error]
var reg = /a/g; // [object RegExp]
var func = function a() {}; // [object Function]
function checkType() {
for (var i = 0; i < arguments.length; i++) {
console.log(Object.prototype.toString.call(arguments[i]));
}
}
checkType(number, string, boolean, und, nul, obj, array, date, error, reg, func);除了以上 11 种之外,还有:
console.log(Object.prototype.toString.call(Math)); // [object Math]
console.log(Object.prototype.toString.call(JSON)); // [object JSON]除了以上 13 种之外,还有:
function a() {
console.log(Object.prototype.toString.call(arguments)); // [object Arguments]
}
a();所以我们可以识别至少 14 种类型,当然我们也可以算出来,[[class]] 属性至少有 12 个。
type API
既然有了 Object.prototype.toString 这个神器!那就让我们写个 type 函数帮助我们以后识别各种类型的值吧!
我的设想:
写一个 type 函数能检测各种类型的值,如果是基本类型,就使用 typeof,引用类型就使用 toString。此外鉴于 typeof 的结果是小写,我也希望所有的结果都是小写。
考虑到实际情况下并不会检测 Math 和 JSON,所以去掉这两个类型的检测。
我们来写一版代码:
// 第一版
var class2type = {};
// 生成class2type映射
'Boolean Number String Function Array Date RegExp Object Error Null Undefined'.split(' ').map(function(item, index) {
class2type['[object ' + item + ']'] = item.toLowerCase();
});
function type(obj) {
return typeof obj === 'object' || typeof obj === 'function'
? class2type[Object.prototype.toString.call(obj)] || 'object'
: typeof obj;
}嗯,看起来很完美的样子~~ 但是注意,在 IE6 中,null 和 undefined 会被 Object.prototype.toString 识别成 [object Object]!
我去,竟然还有这个兼容性!有什么简单的方法可以解决吗?那我们再改写一版,绝对让你惊艳!
// 第二版
var class2type = {};
// 生成class2type映射
'Boolean Number String Function Array Date RegExp Object Error'.split(' ').map(function(item, index) {
class2type['[object ' + item + ']'] = item.toLowerCase();
});
function type(obj) {
// 一箭双雕
if (obj == null) {
return obj + '';
}
return typeof obj === 'object' || typeof obj === 'function'
? class2type[Object.prototype.toString.call(obj)] || 'object'
: typeof obj;
}isFunction
有了 type 函数后,我们可以对常用的判断直接封装,比如 isFunction:
function isFunction(obj) {
return type(obj) === 'function';
}数组
jQuery 判断数组类型,旧版本是通过判断 Array.isArray 方法是否存在,如果存在就使用该方法,不存在就使用 type 函数。
var isArray =
Array.isArray ||
function(obj) {
return type(obj) === 'array';
};但是在 jQuery v3.0 中已经完全采用了 Array.isArray。
plainObject
plainObject 来自于 jQuery,可以翻译成纯粹的对象,所谓”纯粹的对象”,就是该对象是通过 ”{}” 或 “new Object” 创建的,该对象含有零个或者多个键值对。
之所以要判断是不是 plainObject,是为了跟其他的 JavaScript 对象如 null,数组,宿主对象(documents)等作区分,因为这些用 typeof 都会返回 object。
jQuery 提供了 isPlainObject 方法进行判断,先让我们看看使用的效果:
function Person(name) {
this.name = name;
}
console.log($.isPlainObject({})); // true
console.log($.isPlainObject(new Object())); // true
console.log($.isPlainObject(Object.create(null))); // true
console.log($.isPlainObject(Object.assign({ a: 1 }, { b: 2 }))); // true
console.log($.isPlainObject(new Person('yayu'))); // false
console.log($.isPlainObject(Object.create({}))); // false由此我们可以看到,除了 {} 和 new Object 创建的之外,jQuery 认为一个没有原型的对象也是一个纯粹的对象。
实际上随着 jQuery 版本的提升,isPlainObject 的实现也在变化,我们今天讲的是 3.0 版本下的 isPlainObject,我们直接看源码:
// 上节中写 type 函数时,用来存放 toString 映射结果的对象
var class2type = {};
// 相当于 Object.prototype.toString
var toString = class2type.toString;
// 相当于 Object.prototype.hasOwnProperty
var hasOwn = class2type.hasOwnProperty;
function isPlainObject(obj) {
var proto, Ctor;
// 排除掉明显不是 obj 的以及一些宿主对象如Window
if (!obj || toString.call(obj) !== '[object Object]') {
return false;
}
/**
* getPrototypeOf es5 方法,获取 obj 的原型
* 以 new Object 创建的对象为例的话
* obj.__proto__ === Object.prototype
*/
proto = Object.getPrototypeOf(obj);
// 没有原型的对象是纯粹的,Object.create(null) 就在这里返回 true
if (!proto) {
return true;
}
/**
* 以下判断通过 new Object 方式创建的对象
* 判断 proto 是否有 constructor 属性,如果有就让 Ctor 的值为 proto.constructor
* 如果是 Object 函数创建的对象,Ctor 在这里就等于 Object 构造函数
*/
Ctor = hasOwn.call(proto, 'constructor') && proto.constructor;
// 在这里判断 Ctor 构造函数是不是 Object 构造函数,用于区分自定义构造函数和 Object 构造函数,比较函数源代码字符串
return typeof Ctor === 'function' && hasOwn.toString.call(Ctor) === hasOwn.toString.call(Object);
}注意:我们判断 Ctor 构造函数是不是 Object 构造函数,用的是 hasOwn.toString.call(Ctor),这个方法可不是 Object.prototype.toString,不信我们在函数里加上下面这两句话:
console.log(hasOwn.toString.call(Ctor)); // function Object() { [native code] }
console.log(Object.prototype.toString.call(Ctor)); // [object Function]发现返回的值并不一样,这是因为 hasOwn.toString 调用的其实是 Function.prototype.toString,毕竟 hasOwnProperty 可是一个函数!
而且 Function 对象覆盖了从 Object 继承来的 Object.prototype.toString 方法。函数的 toString 方法会返回一个表示函数源代码的字符串。具体来说,包括 function 关键字,形参列表,大括号,以及函数体中的内容。
EmptyObject
jQuery 提供了 isEmptyObject 方法来判断是否是空对象,代码简单,我们直接看源码:
function isEmptyObject(obj) {
var name;
for (name in obj) {
return false;
}
return true;
}其实所谓的 isEmptyObject 就是判断是否有属性,for 循环一旦执行,就说明有属性,有属性就会返回 false。
但是根据这个源码我们可以看出 isEmptyObject 实际上判断的并不仅仅是空对象。
举个栗子:
console.log(isEmptyObject({})); // true
console.log(isEmptyObject([])); // true
console.log(isEmptyObject(null)); // true
console.log(isEmptyObject(undefined)); // true
console.log(isEmptyObject(1)); // true
console.log(isEmptyObject('')); // true
console.log(isEmptyObject(true)); // true以上都会返回 true。
但是既然 jQuery 是这样写,可能是因为考虑到实际开发中 isEmptyObject 用来判断 {} 和 {a: 1} 是足够的吧。如果真的是只判断 {},完全可以结合上篇写的 type 函数筛选掉不适合的情况。
Window 对象
Window 对象作为客户端 JavaScript 的全局对象,它有一个 window 属性指向自身,这点在《JavaScript 深入之变量对象》中讲到过。我们可以利用这个特性判断是否是 Window 对象。
function isWindow(obj) {
return obj != null && obj === obj.window;
}isArrayLike
isArrayLike,看名字可能会让我们觉得这是判断类数组对象的,其实不仅仅是这样,jQuery 实现的 isArrayLike,数组和类数组都会返回 true。
因为源码比较简单,我们直接看源码:
function isArrayLike(obj) {
// obj 必须有 length属性
var length = !!obj && 'length' in obj && obj.length;
var typeRes = type(obj);
// 排除掉函数和 Window 对象
if (typeRes === 'function' || isWindow(obj)) {
return false;
}
return typeRes === 'array' || length === 0 || (typeof length === 'number' && length > 0 && length - 1 in obj);
}重点分析 return 这一行,使用了或语句,只要一个为 true,结果就返回 true。
所以如果 isArrayLike 返回 true,至少要满足三个条件之一:
- 是数组
- 长度为 0
- lengths 属性是大于 0 的数字类型,并且 obj[length - 1] 必须存在
第一个就不说了,看第二个,为什么长度为 0 就可以直接判断为 true 呢?
那我们写个对象:
var obj = {
a: 1,
b: 2,
length: 0
};isArrayLike 函数就会返回 true,那这个合理吗?
回答合不合理之前,我们先看一个例子:
function a() {
console.log(isArrayLike(arguments));
}
a();如果我们去掉 length === 0 这个判断,就会打印 false,然而我们都知道 arguments 是一个类数组对象,这里是应该返回 true 的。
所以是不是为了放过空的 arguments 时也放过了一些存在争议的对象呢?
第三个条件:length 是数字,并且 length > 0 且最后一个元素存在。
为什么仅仅要求最后一个元素存在呢?
让我们先想下数组是不是可以这样写:
var arr = [, , 3];当我们写一个对应的类数组对象就是:
var arrLike = {
2: 3,
length: 3
};也就是说当我们在数组中用逗号直接跳过的时候,我们认为该元素是不存在的,类数组对象中也就不用写这个元素,但是最后一个元素是一定要写的,要不然 length 的长度就不会是最后一个元素的 key 值加 1。比如数组可以这样写
var arr = [1, ,];
console.log(arr.length); // 2但是类数组对象就只能写成:
var arrLike = {
0: 1,
length: 1
};所以符合条件的类数组对象是一定存在最后一个元素的!
这就是满足 isArrayLike 的三个条件,其实除了 jQuery 之外,很多库都有对 isArrayLike 的实现,比如 underscore:
var MAX_ARRAY_INDEX = Math.pow(2, 53) - 1;
var isArrayLike = function(collection) {
var length = getLength(collection);
return typeof length == 'number' && length >= 0 && length <= MAX_ARRAY_INDEX;
};isElement
isElement 判断是不是 DOM 元素。
isElement = function(obj) {
return !!(obj && obj.nodeType === 1);
};深浅拷贝
数组的浅拷贝
如果是数组,我们可以利用数组的一些方法比如:slice、concat 返回一个新数组的特性来实现拷贝。
比如:
var arr = ['old', 1, true, null, undefined];
var new_arr = arr.concat();
new_arr[0] = 'new';
console.log(arr); // ["old", 1, true, null, undefined]
console.log(new_arr); // ["new", 1, true, null, undefined]用 slice 可以这样做:
var new_arr = arr.slice();但是如果数组嵌套了对象或者数组的话,比如:
var arr = [{ old: 'old' }, ['old']];
var new_arr = arr.concat();
arr[0].old = 'new';
arr[1][0] = 'new';
console.log(arr); // [{old: 'new'}, ['new']]
console.log(new_arr); // [{old: 'new'}, ['new']]我们会发现,无论是新数组还是旧数组都发生了变化,也就是说使用 concat 方法,克隆的并不彻底。
如果数组元素是基本类型,就会拷贝一份,互不影响,而如果是对象或者数组,就会只拷贝对象和数组的引用,这样我们无论在新旧数组进行了修改,两者都会发生变化。
我们把这种复制引用的拷贝方法称之为浅拷贝,与之对应的就是深拷贝,深拷贝就是指完全的拷贝一个对象,即使嵌套了对象,两者也相互分离,修改一个对象的属性,也不会影响另一个。
所以我们可以看出使用 concat 和 slice 是一种浅拷贝。
数组的深拷贝
那如何深拷贝一个数组呢?这里介绍一个技巧,不仅适用于数组还适用于对象!那就是:
var arr = ['old', 1, true, ['old1', 'old2'], { old: 1 }];
var new_arr = JSON.parse(JSON.stringify(arr));
console.log(new_arr);是一个简单粗暴的好方法,就是有一个问题,不能拷贝函数,我们做个试验:
var arr = [
function() {
console.log(a);
},
{
b: function() {
console.log(b);
}
}
];
var new_arr = JSON.parse(JSON.stringify(arr));
console.log(new_arr);我们会发现 new_arr 变成了:

浅拷贝的实现
以上三个方法 concat、slice、JSON.stringify 都算是技巧类,可以根据实际项目情况选择使用,接下来我们思考下如何实现一个对象或者数组的浅拷贝。
想一想,好像很简单,遍历对象,然后把属性和属性值都放在一个新的对象不就好了~
嗯,就是这么简单,注意几个小点就可以了:
var shallowCopy = function(obj) {
// 只拷贝对象
if (typeof obj !== 'object') return;
// 根据 obj 的类型判断是新建一个数组还是对象
var newObj = obj instanceof Array ? [] : {};
// 遍历obj,并且判断是obj的属性才拷贝
for (var key in obj) {
if (obj.hasOwnProperty(key)) {
newObj[key] = obj[key];
}
}
return newObj;
};深拷贝的实现
那如何实现一个深拷贝呢?说起来也好简单,我们在拷贝的时候判断一下属性值的类型,如果是对象,我们递归调用深拷贝函数不就好了~
var deepCopy = function(obj) {
if (typeof obj !== 'object') return;
var newObj = obj instanceof Array ? [] : {};
for (var key in obj) {
if (obj.hasOwnProperty(key)) {
newObj[key] = typeof obj[key] === 'object' ? deepCopy(obj[key]) : obj[key];
}
}
return newObj;
};求数组的最大值和最小值
取出数组中的最大值或者最小值是开发中常见的需求,但你能想出几种方法来实现这个需求呢?
Math.max
JavaScript 提供了 Math.max 函数返回一组数中的最大值,用法是:
Math.max([value1[,value2, ...]])值得注意的是:
- 如果有任一参数不能被转换为数值,则结果为 NaN。
- max 是 Math 的静态方法,所以应该像这样使用:Math.max(),而不是作为 Math 实例的方法 (简单的来说,就是不使用 new )
- 如果没有参数,则结果为 -Infinity (注意是负无穷大)
而我们需要分析的是:
- 如果任一参数不能被转换为数值,这就意味着如果参数可以被转换成数字,就是可以进行比较的,比如:
Math.max(true, 0); // 1
Math.max(true, '2', null); // 2
Math.max(1, undefined); // NaN
Math.max(1, {}); // NaN- 如果没有参数,则结果为 -Infinity,对应的 Math.min 函数,如果没有参数,则结果为 Infinity,所以:
var min = Math.min();
var max = Math.max();
console.log(min > max);了解了 Math.max 方法,我们以求数组最大值的为例,思考有哪些方法可以实现这个需求。
原始方法
最最原始的方法,莫过于循环遍历一遍:
var arr = [6, 4, 1, 8, 2, 11, 23];
var result = arr[0];
for (var i = 1; i < arr.length; i++) {
result = Math.max(result, arr[i]);
}
console.log(result);reduce
既然是通过遍历数组求出一个最终值,那么我们就可以使用 reduce 方法:
var arr = [6, 4, 1, 8, 2, 11, 23];
function max(prev, next) {
return Math.max(prev, next);
}
console.log(arr.reduce(max));排序
如果我们先对数组进行一次排序,那么最大值就是最后一个值:
var arr = [6, 4, 1, 8, 2, 11, 23];
arr.sort(function(a, b) {
return a - b;
});
console.log(arr[arr.length - 1]);eval
Math.max 支持传多个参数来进行比较,那么我们如何将一个数组转换成参数传进 Math.max 函数呢?eval 便是一种
var arr = [6, 4, 1, 8, 2, 11, 23];
var max = eval('Math.max(' + arr + ')');
console.log(max);apply
使用 apply 是另一种。
var arr = [6, 4, 1, 8, 2, 11, 23];
console.log(Math.max.apply(null, arr));ES6 …
使用 ES6 的扩展运算符:
var arr = [6, 4, 1, 8, 2, 11, 23];
console.log(Math.max(...arr));数组扁平化
扁平化
数组的扁平化,就是将一个嵌套多层的数组 array (嵌套可以是任何层数)转换为只有一层的数组。
举个例子,假设有个名为 flatten 的函数可以做到数组扁平化,效果就会如下:
var arr = [1, [2, [3, 4]]];
console.log(flatten(arr)); // [1, 2, 3, 4]递归
我们最一开始能想到的莫过于循环数组元素,如果还是一个数组,就递归调用该方法:
// 方法 1
var arr = [1, [2, [3, 4]]];
function flatten(arr) {
var result = [];
for (var i = 0, len = arr.length; i < len; i++) {
if (Array.isArray(arr[i])) {
result = result.concat(flatten(arr[i]));
} else {
result.push(arr[i]);
}
}
return result;
}
console.log(flatten(arr));toString
如果数组的元素都是数字,那么我们可以考虑使用 toString 方法,因为:
[1, [2, [3, 4]]].toString(); // "1,2,3,4"调用 toString 方法,返回了一个逗号分隔的扁平的字符串,这时候我们再 split,然后转成数字不就可以实现扁平化了吗?
// 方法2
var arr = [1, [2, [3, 4]]];
function flatten(arr) {
return arr
.toString()
.split(',')
.map(function(item) {
return +item;
});
}
console.log(flatten(arr));然而这种方法使用的场景却非常有限,如果数组是 [1, ‘1’, 2, ‘2’] 的话,这种方法就会产生错误的结果。
reduce
既然是对数组进行处理,最终返回一个值,我们就可以考虑使用 reduce 来简化代码:
// 方法3
var arr = [1, [2, [3, 4]]];
function flatten(arr) {
return arr.reduce(function(prev, next) {
return prev.concat(Array.isArray(next) ? flatten(next) : next);
}, []);
}
console.log(flatten(arr));ES6 …
ES6 增加了扩展运算符,用于取出参数对象的所有可遍历属性,拷贝到当前对象之中:
var arr = [1, [2, [3, 4]]];
console.log([].concat(...arr)); // [1, 2, [3, 4]]我们用这种方法只可以扁平一层,但是顺着这个方法一直思考,我们可以写出这样的方法:
// 方法4
var arr = [1, [2, [3, 4]]];
function flatten(arr) {
while (arr.some((item) => Array.isArray(item))) {
arr = [].concat(...arr);
}
return arr;
}
console.log(flatten(arr));undercore
那么如何写一个抽象的扁平函数,来方便我们的开发呢,所有又到了我们抄袭 underscore 的时候了~
在这里直接给出源码和注释,但是要注意,这里的 flatten 函数并不是最终的 _.flatten,为了方便多个 API 进行调用,这里对扁平进行了更多的配置。
/**
* 数组扁平化
* @param {Array} input 要处理的数组
* @param {boolean} shallow 是否只扁平一层
* @param {boolean} strict 是否严格处理元素,下面有解释
* @param {Array} output 这是为了方便递归而传递的参数
* 源码地址:https://github.com/jashkenas/underscore/blob/master/underscore.js#L528
*/
function flatten(input, shallow, strict, output) {
// 递归使用的时候会用到output
output = output || [];
var idx = output.length;
for (var i = 0, len = input.length; i < len; i++) {
var value = input[i];
// 如果是数组,就进行处理
if (Array.isArray(value)) {
// 如果是只扁平一层,遍历该数组,依此填入 output
if (shallow) {
var j = 0,
length = value.length;
while (j < length) output[idx++] = value[j++];
}
// 如果是全部扁平就递归,传入已经处理的 output,递归中接着处理 output
else {
flatten(value, shallow, strict, output);
idx = output.length;
}
}
// 不是数组,根据 strict 的值判断是跳过不处理还是放入 output
else if (!strict) {
output[idx++] = value;
}
}
return output;
}解释下 strict,在代码里我们可以看出,当遍历数组元素时,如果元素不是数组,就会对 strict 取反的结果进行判断,如果设置 strict 为 true,就会跳过不进行任何处理,这意味着可以过滤非数组的元素,举个例子:
var arr = [1, 2, [3, 4]];
console.log(flatten(arr, true, true)); // [3, 4]那么设置 strict 到底有什么用呢?不急,我们先看下 shallow 和 strct 各种值对应的结果:
- shallow true + strict false :正常扁平一层
- shallow false + strict false :正常扁平所有层
- shallow true + strict true :去掉非数组元素
- shallow false + strict true : 返回一个[]
我们看看 underscore 中哪些方法调用了 flatten 这个基本函数:
_.flatten
首先就是 _.flatten:
_.flatten = function(array, shallow) {
return flatten(array, shallow, false);
};在正常的扁平中,我们并不需要去掉非数组元素。
_.union
接下来是 _.union:
该函数传入多个数组,然后返回传入的数组的并集,
举个例子:
_.union([1, 2, 3], [101, 2, 1, 10], [2, 1]);
=> [1, 2, 3, 101, 10]如果传入的参数并不是数组,就会将该参数跳过:
_.union([1, 2, 3], [101, 2, 1, 10], 4, 5);
=> [1, 2, 3, 101, 10]为了实现这个效果,我们可以将传入的所有数组扁平化,然后去重,因为只能传入数组,这时候我们直接设置 strict 为 true,就可以跳过传入的非数组的元素。
// 关于 unique 可以查看《JavaScript专题之数组去重》[](https://github.com/mqyqingfeng/Blog/issues/27)
function unique(array) {
return Array.from(new Set(array));
}
_.union = function() {
return unique(flatten(arguments, true, true));
};_.difference
是不是感觉折腾 strict 有点用处了,我们再看一个 _.difference:
语法为:
_.difference(array, *others)
效果是取出来自 array 数组,并且不存在于多个 other 数组的元素。跟 _.union 一样,都会排除掉不是数组的元素。
举个例子:
_.difference([1, 2, 3, 4, 5], [5, 2, 10], [4], 3);
=> [1, 3]实现方法也很简单,扁平 others 的数组,筛选出 array 中不在扁平化数组中的值:
function difference(array, ...rest) {
rest = flatten(rest, true, true);
return array.filter(function(item) {
return rest.indexOf(item) === -1;
});
}注意,以上实现的细节并不是完全按照 underscore,具体细节的实现感兴趣可以查看源码。
判断两个对象相等
虽然标题写的是如何判断两个对象相等,但本篇我们不仅仅判断两个对象相等,实际上,我们要做到的是如何判断两个参数相等,而这必然会涉及到多种类型的判断。
相等
什么是相等?在《JavaScript 专题之去重》中,我们认为只要 === 的结果为 true,两者就相等,然而今天我们重新定义相等:
我们认为:
- NaN 和 NaN 是相等
- [1] 和 [1] 是相等
- {value: 1} 和 {value: 1} 是相等
不仅仅是这些长得一样的,还有
- 1 和 new Number(1) 是相等
- ‘Curly’ 和 new String(‘Curly’) 是相等
- true 和 new Boolean(true) 是相等
更复杂的我们会在接下来的内容中看到。
目标
我们的目标是写一个 eq 函数用来判断两个参数是否相等,使用效果如下:
function eq(a, b) { ... }
var a = [1];
var b = [1];
console.log(eq(a, b)) // true在写这个看似很简单的函数之前,我们首先了解在一些简单的情况下是如何判断的?
+0 与 -0
如果 a === b 的结果为 true, 那么 a 和 b 就是相等的吗?一般情况下,当然是这样的,但是有一个特殊的例子,就是 +0 和 -0。
JavaScript 处心积虑 的想抹平两者的差异:
// 表现1
console.log(+0 === -0); // true
// 表现2
(-0)
.toString()(
// '0'
+0
)
.toString() - // '0'
// 表现3
0 <
+0 + // false
0 <
-0; // false即便如此,两者依然是不同的:
1 / +0; // Infinity
1 / -0; // -Infinity
1 / +0 === 1 / -0; // false也许你会好奇为什么要有 +0 和 -0 呢?
这是因为 JavaScript 采用了 IEEE_754 浮点数表示法(几乎所有现代编程语言所采用),这是一种二进制表示法,按照这个标准,最高位是符号位(0 代表正,1 代表负),剩下的用于表示大小。而对于零这个边界值 ,1000(-0) 和 0000(0)都是表示 0 ,这才有了正负零的区别。
也许你会好奇什么时候会产生 -0 呢?
Math.round(-0.1); // -0那么我们又该如何在 === 结果为 true 的时候,区别 0 和 -0 得出正确的结果呢?我们可以这样做:
function eq(a, b) {
if (a === b) return a !== 0 || 1 / a === 1 / b;
return false;
}
console.log(eq(0, 0)); // true
console.log(eq(0, -0)); // falseNaN
在本篇,我们认为 NaN 和 NaN 是相等的,那又该如何判断出 NaN 呢?
console.log(NaN === NaN); // false利用 NaN 不等于自身的特性,我们可以区别出 NaN,那么这个 eq 函数又该怎么写呢?
function eq(a, b) {
if (a !== a) return b !== b;
}
console.log(eq(NaN, NaN)); // trueeq 函数
现在,我们已经可以去写 eq 函数的第一版了。
// eq 第一版
// 用来过滤掉简单的类型比较,复杂的对象使用 deepEq 函数进行处理
function eq(a, b) {
// === 结果为 true 的区别出 +0 和 -0
if (a === b) return a !== 0 || 1 / a === 1 / b;
// typeof null 的结果为 object ,这里做判断,是为了让有 null 的情况尽早退出函数
if (a == null || b == null) return false;
// 判断 NaN
if (a !== a) return b !== b;
// 判断参数 a 类型,如果是基本类型,在这里可以直接返回 false
var type = typeof a;
if (type !== 'function' && type !== 'object' && typeof b != 'object') return false;
// 更复杂的对象使用 deepEq 函数进行深度比较
return deepEq(a, b);
}也许你会好奇是不是少了一个 typeof b !== function?
试想如果我们添加上了这句,当 a 是基本类型,而 b 是函数的时候,就会进入 deepEq 函数,而去掉这一句,就会进入直接进入 false,实际上基本类型和函数肯定是不会相等的,所以这样做代码又少,又可以让一种情况更早退出。
String 对象
现在我们开始写 deepEq 函数,一个要处理的重大难题就是 ‘Curly’ 和 new String(‘Curly’) 如何判断成相等?
两者的类型都不一样呐!不信我们看 typeof 的操作结果:
console.log(typeof 'Curly'); // string
console.log(typeof new String('Curly')); // object可是我们在《JavaScript 专题之类型判断上》中还学习过更多的方法判断类型,比如 Object.prototype.toString:
var toString = Object.prototype.toString;
toString.call('Curly'); // "[object String]"
toString.call(new String('Curly')); // "[object String]"神奇的是使用 toString 方法两者判断的结果却是一致的,可是就算知道了这一点,还是不知道如何判断字符串和字符串包装对象是相等的呢?
那我们利用隐式类型转换呢?
console.log(‘Curly’ + ” === new String(‘Curly’) + ”); // true
看来我们已经有了思路:如果 a 和 b 的 Object.prototype.toString 的结果一致,并且都是”[object String]“,那我们就使用 ” + a === ” + b 进行判断。
可是不止有 String 对象呐,Boolean、Number、RegExp、Date 呢?
更多对象
跟 String 同样的思路,利用隐式类型转换。
Boolean
var a = true;
var b = new Boolean(true);
console.log(+a === +b); // trueDate
var a = new Date(2009, 9, 25);
var b = new Date(2009, 9, 25);
console.log(+a === +b); // trueRegExp
var a = /a/i;
var b = new RegExp(/a/i);
console.log('' + a === '' + b); // trueNumber
var a = 1;
var b = new Number(1);
console.log(+a === +b); // true嗯哼?你确定 Number 能这么简单的判断?
var a = Number(NaN);
var b = Number(NaN);
console.log(+a === +b); // false可是 a 和 b 应该被判断成 true 的呐~
那么我们就改成这样:
var a = Number(NaN);
var b = Number(NaN);
function eq() {
// 判断 Number(NaN) Object(NaN) 等情况
if (+a !== +a) return +b !== +b;
// 其他判断 ...
}
console.log(eq(a, b)); // truedeepEq 函数
现在我们可以写一点 deepEq 函数了。
var toString = Object.prototype.toString;
function deepEq(a, b) {
var className = toString.call(a);
if (className !== toString.call(b)) return false;
switch (className) {
case '[object RegExp]':
case '[object String]':
return '' + a === '' + b;
case '[object Number]':
if (+a !== +a) return +b !== +b;
return +a === 0 ? 1 / +a === 1 / b : +a === +b;
case '[object Date]':
case '[object Boolean]':
return +a === +b;
}
// 其他判断
}构造函数实例
我们看个例子:
function Person() {
this.name = name;
}
function Animal() {
this.name = name;
}
var person = new Person('Kevin');
var animal = new Animal('Kevin');
eq(person, animal); // ???虽然 person 和 animal 都是 {name: ‘Kevin’},但是 person 和 animal 属于不同构造函数的实例,为了做出区分,我们认为是不同的对象。
如果两个对象所属的构造函数对象不同,两个对象就一定不相等吗?
并不一定,我们再举个例子:
var attrs = Object.create(null);
attrs.name = 'Bob';
eq(attrs, { name: 'Bob' }); // ???尽管 attrs 没有原型,{name: “Bob”} 的构造函数是 Object,但是在实际应用中,只要他们有着相同的键值对,我们依然认为是相等。
从函数设计的角度来看,我们不应该让他们相等,但是从实践的角度,我们让他们相等,所以相等就是一件如此随意的事情吗?!对啊,我也在想:undersocre,你怎么能如此随意呢!!!
哎,吐槽完了,我们还是要接着写这个相等函数,我们可以先做个判断,对于不同构造函数下的实例直接返回 false。
function isFunction(obj) {
return toString.call(obj) === '[object Function]';
}
function deepEq(a, b) {
// 接着上面的内容
var areArrays = className === '[object Array]';
// 不是数组
if (!areArrays) {
// 过滤掉两个函数的情况
if (typeof a != 'object' || typeof b != 'object') return false;
var aCtor = a.constructor,
bCtor = b.constructor;
// aCtor 和 bCtor 必须都存在并且都不是 Object 构造函数的情况下,aCtor 不等于 bCtor, 那这两个对象就真的不相等啦
if (
aCtor !== bCtor &&
!(isFunction(aCtor) && aCtor instanceof aCtor && isFunction(bCtor) && bCtor instanceof bCtor) &&
('constructor' in a && 'constructor' in b)
) {
return false;
}
}
// 下面还有好多判断
}数组相等
现在终于可以进入我们期待已久的数组和对象的判断,不过其实这个很简单,就是递归遍历一遍……
function deepEq(a, b) {
// 再接着上面的内容
if (areArrays) {
length = a.length;
if (length !== b.length) return false;
while (length--) {
if (!eq(a[length], b[length])) return false;
}
} else {
var keys = Object.keys(a),
key;
length = keys.length;
if (Object.keys(b).length !== length) return false;
while (length--) {
key = keys[length];
if (!(b.hasOwnProperty(key) && eq(a[key], b[key]))) return false;
}
}
return true;
}循环引用
如果觉得这就结束了,简直是太天真,因为最难的部分才终于要开始,这个问题就是循环引用!
举个简单的例子:
a = { abc: null };
b = { abc: null };
a.abc = a;
b.abc = b;
eq(a, b);再复杂一点的,比如:
a = { foo: { b: { foo: { c: { foo: null } } } } };
b = { foo: { b: { foo: { c: { foo: null } } } } };
a.foo.b.foo.c.foo = a;
b.foo.b.foo.c.foo = b;
eq(a, b);为了给大家演示下循环引用,大家可以把下面这段已经精简过的代码复制到浏览器中尝试:
// demo
var a, b;
a = { foo: { b: { foo: { c: { foo: null } } } } };
b = { foo: { b: { foo: { c: { foo: null } } } } };
a.foo.b.foo.c.foo = a;
b.foo.b.foo.c.foo = b;
function eq(a, b, aStack, bStack) {
if (typeof a == 'number') {
return a === b;
}
return deepEq(a, b);
}
function deepEq(a, b) {
var keys = Object.keys(a);
var length = keys.length;
var key;
while (length--) {
key = keys[length];
// 这是为了让你看到代码其实一直在执行
console.log(a[key], b[key]);
if (!eq(a[key], b[key])) return false;
}
return true;
}
eq(a, b);嗯,以上的代码是死循环。
那么,我们又该如何解决这个问题呢?underscore 的思路是 eq 的时候,多传递两个参数为 aStack 和 bStack,用来储存 a 和 b 递归比较过程中的 a 和 b 的值,咋说的这么绕口呢?
我们直接看个精简的例子:
var a, b;
a = { foo: { b: { foo: { c: { foo: null } } } } };
b = { foo: { b: { foo: { c: { foo: null } } } } };
a.foo.b.foo.c.foo = a;
b.foo.b.foo.c.foo = b;
function eq(a, b, aStack, bStack) {
if (typeof a == 'number') {
return a === b;
}
return deepEq(a, b, aStack, bStack);
}
function deepEq(a, b, aStack, bStack) {
aStack = aStack || [];
bStack = bStack || [];
var length = aStack.length;
while (length--) {
if (aStack[length] === a) {
return bStack[length] === b;
}
}
aStack.push(a);
bStack.push(b);
var keys = Object.keys(a);
var length = keys.length;
var key;
while (length--) {
key = keys[length];
if (!eq(a[key], b[key], aStack, bStack)) return false;
}
// aStack.pop();
// bStack.pop();
return true;
}
console.log(eq(a, b));之所以注释掉 aStack.pop() 和 bStack.pop() 这两句,是为了方便大家查看 aStack bStack 的值。
最终的 eq 函数
最终的代码如下:
var toString = Object.prototype.toString;
function isFunction(obj) {
return toString.call(obj) === '[object Function]';
}
function eq(a, b, aStack, bStack) {
// === 结果为 true 的区别出 +0 和 -0
if (a === b) return a !== 0 || 1 / a === 1 / b;
// typeof null 的结果为 object ,这里做判断,是为了让有 null 的情况尽早退出函数
if (a == null || b == null) return false;
// 判断 NaN
if (a !== a) return b !== b;
// 判断参数 a 类型,如果是基本类型,在这里可以直接返回 false
var type = typeof a;
if (type !== 'function' && type !== 'object' && typeof b != 'object') return false;
// 更复杂的对象使用 deepEq 函数进行深度比较
return deepEq(a, b, aStack, bStack);
}
function deepEq(a, b, aStack, bStack) {
// a 和 b 的内部属性 [[class]] 相同时 返回 true
var className = toString.call(a);
if (className !== toString.call(b)) return false;
switch (className) {
case '[object RegExp]':
case '[object String]':
return '' + a === '' + b;
case '[object Number]':
if (+a !== +a) return +b !== +b;
return +a === 0 ? 1 / +a === 1 / b : +a === +b;
case '[object Date]':
case '[object Boolean]':
return +a === +b;
}
var areArrays = className === '[object Array]';
// 不是数组
if (!areArrays) {
// 过滤掉两个函数的情况
if (typeof a != 'object' || typeof b != 'object') return false;
var aCtor = a.constructor,
bCtor = b.constructor;
// aCtor 和 bCtor 必须都存在并且都不是 Object 构造函数的情况下,aCtor 不等于 bCtor, 那这两个对象就真的不相等啦
if (
aCtor !== bCtor &&
!(isFunction(aCtor) && aCtor instanceof aCtor && isFunction(bCtor) && bCtor instanceof bCtor) &&
('constructor' in a && 'constructor' in b)
) {
return false;
}
}
aStack = aStack || [];
bStack = bStack || [];
var length = aStack.length;
// 检查是否有循环引用的部分
while (length--) {
if (aStack[length] === a) {
return bStack[length] === b;
}
}
aStack.push(a);
bStack.push(b);
// 数组判断
if (areArrays) {
length = a.length;
if (length !== b.length) return false;
while (length--) {
if (!eq(a[length], b[length], aStack, bStack)) return false;
}
}
// 对象判断
else {
var keys = Object.keys(a),
key;
length = keys.length;
if (Object.keys(b).length !== length) return false;
while (length--) {
key = keys[length];
if (!(b.hasOwnProperty(key) && eq(a[key], b[key], aStack, bStack))) return false;
}
}
aStack.pop();
bStack.pop();
return true;
}
console.log(eq(0, 0)); // true
console.log(eq(0, -0)); // false
console.log(eq(NaN, NaN)); // true
console.log(eq(Number(NaN), Number(NaN))); // true
console.log(eq('Curly', new String('Curly'))); // true
console.log(eq([1], [1])); // true
console.log(eq({ value: 1 }, { value: 1 })); // true
var a, b;
a = { foo: { b: { foo: { c: { foo: null } } } } };
b = { foo: { b: { foo: { c: { foo: null } } } } };
a.foo.b.foo.c.foo = a;
b.foo.b.foo.c.foo = b;
console.log(eq(a, b)); // true函数柯里化
在数学和计算机科学中,柯里化是一种将使用多个参数的一个函数转换成一系列使用一个参数的函数的技术。
举个例子:
function add(a, b) {
return a + b;
}
// 执行 add 函数,一次传入两个参数即可
add(1, 2); // 3
// 假设有一个 curry 函数可以做到柯里化
var addCurry = curry(add);
addCurry(1)(2); // 3用途
我们会讲到如何写出这个 curry 函数,并且会将这个 curry 函数写的很强大,但是在编写之前,我们需要知道柯里化到底有什么用?
举个例子:
// 示意而已
function ajax(type, url, data) {
var xhr = new XMLHttpRequest();
xhr.open(type, url, true);
xhr.send(data);
}
// 虽然 ajax 这个函数非常通用,但在重复调用的时候参数冗余
ajax('POST', 'www.test.com', 'name=kevin');
ajax('POST', 'www.test2.com', 'name=kevin');
ajax('POST', 'www.test3.com', 'name=kevin');
// 利用 curry
var ajaxCurry = curry(ajax);
// 以 POST 类型请求数据
var post = ajaxCurry('POST');
post('www.test.com', 'name=kevin');
// 以 POST 类型请求来自于 www.test.com 的数据
var postFromTest = post('www.test.com');
postFromTest('name=kevin');想想 jQuery 虽然有 $.ajax 这样通用的方法,但是也有 $.get 和 $.post 的语法糖。(当然 jQuery 底层是否是这样做的,我就没有研究了)。
curry 的这种用途可以理解为:参数复用。本质上是降低通用性,提高适用性。
可是即便如此,是不是依然感觉没什么用呢?
如果我们仅仅是把参数一个一个传进去,意义可能不大,但是如果我们是把柯里化后的函数传给其他函数比如 map 呢?
举个例子:
比如我们有这样一段数据:
var person = [{ name: 'kevin' }, { name: 'daisy' }];如果我们要获取所有的 name 值,我们可以这样做:
var name = person.map(function(item) {
return item.name;
});不过如果我们有 curry 函数:
var prop = curry(function(key, obj) {
return obj[key];
});
var name = person.map(prop('name'));我们为了获取 name 属性还要再编写一个 prop 函数,是不是又麻烦了些?
但是要注意,prop 函数编写一次后,以后可以多次使用,实际上代码从原本的三行精简成了一行,而且你看代码是不是更加易懂了?
person.map(prop(‘name’)) 就好像直白的告诉你:person 对象遍历(map)获取(prop) name 属性。
是不是感觉有点意思了呢?
第一版
未来我们会接触到更多有关柯里化的应用,不过那是未来的事情了,现在我们该编写这个 curry 函数了。
一个经常会看到的 curry 函数的实现为:
// 第一版
var curry = function(fn) {
var args = [].slice.call(arguments, 1);
return function() {
var newArgs = args.concat([].slice.call(arguments));
return fn.apply(this, newArgs);
};
};我们可以这样使用:
function add(a, b) {
return a + b;
}
var addCurry = curry(add, 1, 2);
addCurry(); // 3
//或者
var addCurry = curry(add, 1);
addCurry(2); // 3
//或者
var addCurry = curry(add);
addCurry(1, 2); // 3已经有柯里化的感觉了,但是还没有达到要求,不过我们可以把这个函数用作辅助函数,帮助我们写真正的 curry 函数。
第二版
// 第二版
function sub_curry(fn) {
var args = [].slice.call(arguments, 1);
return function() {
return fn.apply(this, args.concat([].slice.call(arguments)));
};
}
function curry(fn, length) {
length = length || fn.length;
var slice = Array.prototype.slice;
return function() {
if (arguments.length < length) {
var combined = [fn].concat(slice.call(arguments));
return curry(sub_curry.apply(this, combined), length - arguments.length);
} else {
return fn.apply(this, arguments);
}
};
}我们验证下这个函数:
var fn = curry(function(a, b, c) {
return [a, b, c];
});
fn('a', 'b', 'c'); // ["a", "b", "c"]
fn('a', 'b')('c'); // ["a", "b", "c"]
fn('a')('b')('c'); // ["a", "b", "c"]
fn('a')('b', 'c'); // ["a", "b", "c"]效果已经达到我们的预期,然而这个 curry 函数的实现好难理解呐……
为了让大家更好的理解这个 curry 函数,我给大家写个极简版的代码:
function sub_curry(fn) {
return function() {
return fn();
};
}
function curry(fn, length) {
length = length || 4;
return function() {
if (length > 1) {
return curry(sub_curry(fn), --length);
} else {
return fn();
}
};
}
var fn0 = function() {
console.log(1);
};
var fn1 = curry(fn0);
fn1()()()(); // 1大家先从理解这个 curry 函数开始。
当执行 fn1() 时,函数返回:
curry(sub_curry(fn0));
// 相当于
curry(function() {
return fn0();
});当执行 fn1()() 时,函数返回:
curry(
sub_curry(function() {
return fn0();
})
);
// 相当于
curry(function() {
return (function() {
return fn0();
})();
});
// 相当于
curry(function() {
return fn0();
});当执行 fn1()()() 时,函数返回:
// 跟 fn1()() 的分析过程一样
curry(function() {
return fn0();
});当执行 fn1()()()() 时,因为此时 length > 2 为 false,所以执行 fn():
fn()(
// 相当于
function() {
return fn0();
}
)();
// 相当于
fn0();
// 执行 fn0 函数,打印 1再回到真正的 curry 函数,我们以下面的例子为例:
var fn0 = function(a, b, c, d) {
return [a, b, c, d];
};
var fn1 = curry(fn0);
fn1('a', 'b')('c')('d');当执行 fn1(“a”, “b”) 时:
fn1("a", "b")
// 相当于
curry(fn0)("a", "b")
// 相当于
curry(sub_curry(fn0, "a", "b"))
// 相当于
// 注意 ... 只是一个示意,表示该函数执行时传入的参数会作为 fn0 后面的参数传入
curry(function(...){
return fn0("a", "b", ...)
})当执行 fn1(“a”, “b”)(“c”) 时,函数返回:
curry(sub_curry(function(...){
return fn0("a", "b", ...)
}), "c")
// 相当于
curry(function(...){
return (function(...) {return fn0("a", "b", ...)})("c")
})
// 相当于
curry(function(...){
return fn0("a", "b", "c", ...)
})当执行 fn1(“a”, “b”)(“c”)(“d”) 时,此时 arguments.length < length 为 false ,执行 fn(arguments),相当于:
(function(...){
return fn0("a", "b", "c", ...)
})("d")
// 相当于
fn0("a", "b", "c", "d")函数执行结束。
所以,其实整段代码又很好理解:
sub_curry 的作用就是用函数包裹原函数,然后给原函数传入之前的参数,当执行 fn0(…)(…) 的时候,执行包裹函数,返回原函数,然后再调用 sub_curry 再包裹原函数,然后将新的参数混合旧的参数再传入原函数,直到函数参数的数目达到要求为止。
如果要明白 curry 函数的运行原理,大家还是要动手写一遍,尝试着分析执行步骤。
更易懂的实现
当然了,如果你觉得还是无法理解,你可以选择下面这种实现方式,可以实现同样的效果:
function curry(fn, args) {
var length = fn.length;
args = args || [];
return function() {
var _args = args.slice(0),
arg,
i;
for (i = 0; i < arguments.length; i++) {
arg = arguments[i];
_args.push(arg);
}
if (_args.length < length) {
return curry.call(this, fn, _args);
} else {
return fn.apply(this, _args);
}
};
}
var fn = curry(function(a, b, c) {
console.log([a, b, c]);
});
fn('a', 'b', 'c'); // ["a", "b", "c"]
fn('a', 'b')('c'); // ["a", "b", "c"]
fn('a')('b')('c'); // ["a", "b", "c"]
fn('a')('b', 'c'); // ["a", "b", "c"]或许大家觉得这种方式更好理解,又能实现一样的效果,为什么不直接就讲这种呢?
因为想给大家介绍各种实现的方法嘛,不能因为难以理解就不给大家介绍呐~
第三版
curry 函数写到这里其实已经很完善了,但是注意这个函数的传参顺序必须是从左到右,根据形参的顺序依次传入,如果我不想根据这个顺序传呢?
我们可以创建一个占位符,比如这样:
var fn = curry(function(a, b, c) {
console.log([a, b, c]);
});
fn('a', _, 'c')('b'); // ["a", "b", "c"]我们直接看第三版的代码:
// 第三版
function curry(fn, args, holes) {
length = fn.length;
args = args || [];
holes = holes || [];
return function() {
var _args = args.slice(0),
_holes = holes.slice(0),
argsLen = args.length,
holesLen = holes.length,
arg,
i,
index = 0;
for (i = 0; i < arguments.length; i++) {
arg = arguments[i];
// 处理类似 fn(1, _, _, 4)(_, 3) 这种情况,index 需要指向 holes 正确的下标
if (arg === _ && holesLen) {
index++;
if (index > holesLen) {
_args.push(arg);
_holes.push(argsLen - 1 + index - holesLen);
}
}
// 处理类似 fn(1)(_) 这种情况
else if (arg === _) {
_args.push(arg);
_holes.push(argsLen + i);
}
// 处理类似 fn(_, 2)(1) 这种情况
else if (holesLen) {
// fn(_, 2)(_, 3)
if (index >= holesLen) {
_args.push(arg);
}
// fn(_, 2)(1) 用参数 1 替换占位符
else {
_args.splice(_holes[index], 1, arg);
_holes.splice(index, 1);
}
} else {
_args.push(arg);
}
}
if (_holes.length || _args.length < length) {
return curry.call(this, fn, _args, _holes);
} else {
return fn.apply(this, _args);
}
};
}
var _ = {};
var fn = curry(function(a, b, c, d, e) {
console.log([a, b, c, d, e]);
});
// 验证 输出全部都是 [1, 2, 3, 4, 5]
fn(1, 2, 3, 4, 5);
fn(_, 2, 3, 4, 5)(1);
fn(1, _, 3, 4, 5)(2);
fn(1, _, 3)(_, 4)(2)(5);
fn(1, _, _, 4)(_, 3)(2)(5);
fn(_, 2)(_, _, 4)(1)(3)(5);总结
至此,我们已经实现了一个强大的 curry 函数,可是这个 curry 函数符合柯里化的定义吗?柯里化可是将一个多参数的函数转换成多个单参数的函数,但是现在我们不仅可以传入一个参数,还可以一次传入两个参数,甚至更多参数……这看起来更像一个柯里化 (curry) 和偏函数 (partial application) 的综合应用,可是什么又是偏函数呢?下篇文章会讲到。
简短写法
var curry = (fn) => (judge = (...args) => (args.length === fn.length ? fn(...args) : (arg) => judge(...args, arg)));偏函数
在计算机科学中,局部应用是指固定一个函数的一些参数,然后产生另一个更小元的函数。
什么是元?元是指函数参数的个数,比如一个带有两个参数的函数被称为二元函数。
举个简单的例子
function add(a, b) {
return a + b;
}
// 执行 add 函数,一次传入两个参数即可
add(1, 2); // 3
// 假设有一个 partial 函数可以做到局部应用
var addOne = partial(add, 1);
addOne(2); // 3个人觉得翻译成“局部应用”或许更贴切些,以下全部使用“局部应用”。
柯里化与局部应用
如果看过上一篇文章《JavaScript 专题之柯里化》,实际上你会发现这个例子和柯里化太像了,所以两者到底是有什么区别呢?
其实也很明显:
柯里化是将一个多参数函数转换成多个单参数函数,也就是将一个 n 元函数转换成 n 个一元函数。
局部应用则是固定一个函数的一个或者多个参数,也就是将一个 n 元函数转换成一个 n - x 元函数。
如果说两者有什么关系的话,引用 functional-programming-jargon 中的描述就是:
Curried functions are automatically partially applied.
partial
我们今天的目的是模仿 underscore 写一个 partial 函数,比起 curry 函数,这个显然简单了很多。
也许你在想我们可以直接使用 bind 呐,举个例子:
function add(a, b) {
return a + b;
}
var addOne = add.bind(null, 1);
addOne(2); // 3然而使用 bind 我们还是改变了 this 指向,我们要写一个不改变 this 指向的方法。
第一版
根据之前的表述,我们可以尝试着写出第一版:
// 第一版
// 似曾相识的代码
function partial(fn) {
var args = [].slice.call(arguments, 1);
return function() {
var newArgs = args.concat([].slice.call(arguments));
return fn.apply(this, newArgs);
};
}我们来写个 demo 验证下 this 的指向:
function add(a, b) {
return a + b + this.value;
}
// var addOne = add.bind(null, 1);
var addOne = partial(add, 1);
var value = 1;
var obj = {
value: 2,
addOne: addOne
};
obj.addOne(2); // ???
// 使用 bind 时,结果为 4
// 使用 partial 时,结果为 5第二版
然而正如 curry 函数可以使用占位符一样,我们希望 partial 函数也可以实现这个功能,我们再来写第二版:
// 第二版
var _ = {};
function partial(fn) {
var args = [].slice.call(arguments, 1);
return function() {
var position = 0,
len = args.length;
for (var i = 0; i < len; i++) {
args[i] = args[i] === _ ? arguments[position++] : args[i];
}
while (position < arguments.length) args.push(arguments[position++]);
return fn.apply(this, args);
};
}我们验证一下:
var subtract = function(a, b) {
return b - a;
};
subFrom20 = partial(subtract, _, 20);
subFrom20(5);惰性函数
我们现在需要写一个 foo 函数,这个函数返回首次调用时的 Date 对象,注意是首次。
普通方法
var t;
function foo() {
if (t) return t;
t = new Date();
return t;
}问题有两个,一是污染了全局变量,二是每次调用 foo 的时候都需要进行一次判断。
闭包
var foo = (function() {
var t;
return function() {
if (t) return t;
t = new Date();
return t;
};
})();然而还是没有解决调用时都必须进行一次判断的问题。
函数对象
函数也是一种对象,利用这个特性,我们也可以解决这个问题。
function foo() {
if (foo.t) return foo.t;
foo.t = new Date();
return foo.t;
}依旧没有解决调用时都必须进行一次判断的问题。
惰性函数
不错,惰性函数就是解决每次都要进行判断的这个问题,解决原理很简单,重写函数。
var foo = function() {
var t = new Date();
// 运行一次后,以后只会调用这个函数
foo = function() {
return t;
};
return foo();
};更多应用
DOM 事件添加中,为了兼容现代浏览器和 IE 浏览器,我们需要对浏览器环境进行一次判断:
// 简化写法
function addEvent(type, el, fn) {
if (window.addEventListener) {
el.addEventListener(type, fn, false);
} else if (window.attachEvent) {
el.attachEvent('on' + type, fn);
}
}问题在于我们每当使用一次 addEvent 时都会进行一次判断。
利用惰性函数,我们可以这样做:
function addEvent(type, el, fn) {
if (window.addEventListener) {
addEvent = function(type, el, fn) {
el.addEventListener(type, fn, false);
};
} else if (window.attachEvent) {
addEvent = function(type, el, fn) {
el.attachEvent('on' + type, fn);
};
}
}当然我们也可以使用闭包的形式:
var addEvent = (function() {
if (window.addEventListener) {
return function(type, el, fn) {
el.addEventListener(type, fn, false);
};
} else if (window.attachEvent) {
return function(type, el, fn) {
el.attachEvent('on' + type, fn);
};
}
})();当我们每次都需要进行条件判断,其实只需要判断一次,接下来的使用方式都不会发生改变的时候,想想是否可以考虑使用惰性函数。
函数组合
我们需要写一个函数,输入 ‘kevin’,返回 ‘HELLO, KEVIN’。
尝试
var toUpperCase = function(x) {
return x.toUpperCase();
};
var hello = function(x) {
return 'HELLO, ' + x;
};
var greet = function(x) {
return hello(toUpperCase(x));
};
greet('kevin');还好我们只有两个步骤,首先小写转大写,然后拼接字符串。如果有更多的操作,greet 函数里就需要更多的嵌套,类似于 fn3(fn2(fn1(fn0(x))))。
优化
试想我们写个 compose 函数:
var compose = function(f, g) {
return function(x) {
return f(g(x));
};
};greet 函数就可以被优化为:
var greet = compose(
hello,
toUpperCase
);
greet('kevin');利用 compose 将两个函数组合成一个函数,让代码从右向左运行,而不是由内而外运行,可读性大大提升。这便是函数组合。
但是现在的 compose 函数也只是能支持两个参数,如果有更多的步骤呢?我们岂不是要这样做:
compose(
d,
compose(
c,
compose(
b,
a
)
)
);为什么我们不写一个帅气的 compose 函数支持传入多个函数呢?这样就变成了:
compose(
d,
c,
b,
a
);compose
我们直接抄袭 underscore 的 compose 函数的实现:
function compose() {
var args = arguments;
var start = args.length - 1;
return function() {
var i = start;
var result = args[start].apply(this, arguments);
while (i--) result = args[i].call(this, result);
return result;
};
}现在的 compose 函数已经可以支持多个函数了,然而有了这个又有什么用呢?
在此之前,我们先了解一个概念叫做 pointfree。
pointfree (函数式编程)
pointfree 指的是函数无须提及将要操作的数据是什么样的。依然是以最初的需求为例:
// 需求:输入 'kevin',返回 'HELLO, KEVIN'。
// 非 pointfree,因为提到了数据:name
var greet = function(name) {
return ('hello ' + name).toUpperCase();
};
// pointfree
// 先定义基本运算,这些可以封装起来复用
var toUpperCase = function(x) {
return x.toUpperCase();
};
var hello = function(x) {
return 'HELLO, ' + x;
};
var greet = compose(
hello,
toUpperCase
);
greet('kevin');我们再举个稍微复杂一点的例子,为了方便书写,我们需要借助在《JavaScript 专题之函数柯里化》中写到的 curry 函数:
// 需求:输入 'kevin daisy kelly',返回 'K.D.K'
// 非 pointfree,因为提到了数据:name
var initials = function(name) {
return name
.split(' ')
.map(
compose(
toUpperCase,
head
)
)
.join('. ');
};
// pointfree
// 先定义基本运算
var split = curry(function(separator, str) {
return str.split(separator);
});
var head = function(str) {
return str.slice(0, 1);
};
var toUpperCase = function(str) {
return str.toUpperCase();
};
var join = curry(function(separator, arr) {
return arr.join(separator);
});
var map = curry(function(fn, arr) {
return arr.map(fn);
});
var initials = compose(
join('.'),
map(
compose(
toUpperCase,
head
)
),
split(' ')
);
initials('kevin daisy kelly');从这个例子中我们可以看到,利用柯里化(curry)和函数组合 (compose) 非常有助于实现 pointfree。
也许你会想,这种写法好麻烦呐,我们还需要定义那么多的基础函数……可是如果有工具库已经帮你写好了呢?比如 ramda.js:
// 使用 ramda.js
var initials = R.compose(
R.join('.'),
R.map(
R.compose(
R.toUpper,
R.head
)
),
R.split(' ')
);而且你也会发现:
Pointfree 的本质就是使用一些通用的函数,组合出各种复杂运算。上层运算不要直接操作数据,而是通过底层函数去处理。即不使用所要处理的值,只合成运算过程。
那么使用 pointfree 模式究竟有什么好处呢?
pointfree 模式能够帮助我们减少不必要的命名,让代码保持简洁和通用,更符合语义,更容易复用,测试也变得轻而易举。
实战
这个例子来自于 Favoring Curry:
假设我们从服务器获取这样的数据:
var data = {
result: 'SUCCESS',
tasks: [
{
id: 104,
complete: false,
priority: 'high',
dueDate: '2013-11-29',
username: 'Scott',
title: 'Do something',
created: '9/22/2013'
},
{
id: 105,
complete: false,
priority: 'medium',
dueDate: '2013-11-22',
username: 'Lena',
title: 'Do something else',
created: '9/22/2013'
},
{
id: 107,
complete: true,
priority: 'high',
dueDate: '2013-11-22',
username: 'Mike',
title: 'Fix the foo',
created: '9/22/2013'
},
{
id: 108,
complete: false,
priority: 'low',
dueDate: '2013-11-15',
username: 'Punam',
title: 'Adjust the bar',
created: '9/25/2013'
},
{
id: 110,
complete: false,
priority: 'medium',
dueDate: '2013-11-15',
username: 'Scott',
title: 'Rename everything',
created: '10/2/2013'
},
{
id: 112,
complete: true,
priority: 'high',
dueDate: '2013-11-27',
username: 'Lena',
title: 'Alter all quuxes',
created: '10/5/2013'
}
]
};我们需要写一个名为 getIncompleteTaskSummaries 的函数,接收一个 username 作为参数,从服务器获取数据,然后筛选出这个用户的未完成的任务的 ids、priorities、titles、和 dueDate 数据,并且按照日期升序排序。
以 Scott 为例,最终筛选出的数据为:
[
{ id: 110, title: 'Rename everything', dueDate: '2013-11-15', priority: 'medium' },
{ id: 104, title: 'Do something', dueDate: '2013-11-29', priority: 'high' }
];普通的方式为:
// 第一版 过程式编程
var fetchData = function() {
// 模拟
return Promise.resolve(data);
};
var getIncompleteTaskSummaries = function(membername) {
return fetchData()
.then(function(data) {
return data.tasks;
})
.then(function(tasks) {
return tasks.filter(function(task) {
return task.username == membername;
});
})
.then(function(tasks) {
return tasks.filter(function(task) {
return !task.complete;
});
})
.then(function(tasks) {
return tasks.map(function(task) {
return {
id: task.id,
dueDate: task.dueDate,
title: task.title,
priority: task.priority
};
});
})
.then(function(tasks) {
return tasks.sort(function(first, second) {
var a = first.dueDate,
b = second.dueDate;
return a < b ? -1 : a > b ? 1 : 0;
});
})
.then(function(task) {
console.log(task);
});
};
getIncompleteTaskSummaries('Scott');如果使用 pointfree 模式:
// 第二版 pointfree 改写
var fetchData = function() {
return Promise.resolve(data);
};
// 编写基本函数
var prop = curry(function(name, obj) {
return obj[name];
});
var propEq = curry(function(name, val, obj) {
return obj[name] === val;
});
var filter = curry(function(fn, arr) {
return arr.filter(fn);
});
var map = curry(function(fn, arr) {
return arr.map(fn);
});
var pick = curry(function(args, obj) {
var result = {};
for (var i = 0; i < args.length; i++) {
result[args[i]] = obj[args[i]];
}
return result;
});
var sortBy = curry(function(fn, arr) {
return arr.sort(function(a, b) {
var a = fn(a),
b = fn(b);
return a < b ? -1 : a > b ? 1 : 0;
});
});
var getIncompleteTaskSummaries = function(membername) {
return fetchData()
.then(prop('tasks'))
.then(filter(propEq('username', membername)))
.then(filter(propEq('complete', false)))
.then(map(pick(['id', 'dueDate', 'title', 'priority'])))
.then(sortBy(prop('dueDate')))
.then(console.log);
};
getIncompleteTaskSummaries('Scott');如果直接使用 ramda.js,你可以省去编写基本函数:
// 第三版 使用 ramda.js
var fetchData = function() {
return Promise.resolve(data);
};
var getIncompleteTaskSummaries = function(membername) {
return fetchData()
.then(R.prop('tasks'))
.then(R.filter(R.propEq('username', membername)))
.then(R.filter(R.propEq('complete', false)))
.then(R.map(R.pick(['id', 'dueDate', 'title', 'priority'])))
.then(R.sortBy(R.prop('dueDate')))
.then(console.log);
};
getIncompleteTaskSummaries('Scott');当然了,利用 compose,你也可以这样写:
// 第四版 使用 compose
var fetchData = function() {
return Promise.resolve(data);
};
var getIncompleteTaskSummaries = function(membername) {
return fetchData().then(
R.compose(
console.log,
R.sortBy(R.prop('dueDate')),
R.map(R.pick(['id', 'dueDate', 'title', 'priority'])),
R.filter(R.propEq('complete', false)),
R.filter(R.propEq('username', membername)),
R.prop('tasks')
)
);
};
getIncompleteTaskSummaries('Scott');compose 是从右到左依此执行,当然你也可以写一个从左到右的版本,但是从右向左执行更加能够反映数学上的含义。
ramda.js 提供了一个 R.pipe 函数,可以做的从左到右,以上可以改写为:
// 第五版 使用 R.pipe
var getIncompleteTaskSummaries = function(membername) {
return fetchData()
.then(R.pipe(
R.prop('tasks'),
R.filter(R.propEq('username', membername)),
R.filter(R.propEq('complete', false)),
R.map(R.pick(['id', 'dueDate', 'title', 'priority'])
R.sortBy(R.prop('dueDate')),
console.log,
))
};函数记忆
函数记忆是指将上次的计算结果缓存起来,当下次调用时,如果遇到相同的参数,就直接返回缓存中的数据。
举个例子:
function add(a, b) {
return a + b;
}
// 假设 memoize 可以实现函数记忆
var memoizedAdd = memoize(add);
memoizedAdd(1, 2); // 3
memoizedAdd(1, 2); // 相同的参数,第二次调用时,从缓存中取出数据,而非重新计算一次原理
实现这样一个 memoize 函数很简单,原理上只用把参数和对应的结果数据存到一个对象中,调用时,判断参数对应的数据是否存在,存在就返回对应的结果数据。
第一版
我们来写一版:
// 第一版 (来自《JavaScript权威指南》)
function memoize(f) {
var cache = {};
return function() {
var key = arguments.length + Array.prototype.join.call(arguments, ',');
if (key in cache) {
return cache[key];
} else {
return (cache[key] = f.apply(this, arguments));
}
};
}我们来测试一下:
var add = function(a, b, c) {
return a + b + c;
};
var memoizedAdd = memoize(add);
console.time('use memoize');
for (var i = 0; i < 100000; i++) {
memoizedAdd(1, 2, 3);
}
console.timeEnd('use memoize');
console.time('not use memoize');
for (var i = 0; i < 100000; i++) {
add(1, 2, 3);
}
console.timeEnd('not use memoize');在 Chrome 中,使用 memoize 大约耗时 60ms,如果我们不使用函数记忆,大约耗时 1.3 ms 左右。
注意
什么,我们使用了看似高大上的函数记忆,结果却更加耗时,这个例子近乎有 60 倍呢!
所以,函数记忆也并不是万能的,你看这个简单的场景,其实并不适合用函数记忆。
需要注意的是,函数记忆只是一种编程技巧,本质上是牺牲算法的空间复杂度以换取更优的时间复杂度,在客户端 JavaScript 中代码的执行时间复杂度往往成为瓶颈,因此在大多数场景下,这种牺牲空间换取时间的做法以提升程序执行效率的做法是非常可取的。
第二版
因为第一版使用了 join 方法,我们很容易想到当参数是对象的时候,就会自动调用 toString 方法转换成 [Object object],再拼接字符串作为 key 值。我们写个 demo 验证一下这个问题:
var propValue = function(obj) {
return obj.value;
};
var memoizedAdd = memoize(propValue);
console.log(memoizedAdd({ value: 1 })); // 1
console.log(memoizedAdd({ value: 2 })); // 1两者都返回了 1,显然是有问题的,所以我们看看 underscore 的 memoize 函数是如何实现的:
// 第二版 (来自 underscore 的实现)
var memoize = function(func, hasher) {
var memoize = function(key) {
var cache = memoize.cache;
var address = '' + (hasher ? hasher.apply(this, arguments) : key);
if (!cache[address]) {
cache[address] = func.apply(this, arguments);
}
return cache[address];
};
memoize.cache = {};
return memoize;
};从这个实现可以看出,underscore 默认使用 function 的第一个参数作为 key,所以如果直接使用
var add = function(a, b, c) {
return a + b + c;
};
var memoizedAdd = memoize(add);
memoizedAdd(1, 2, 3); // 6
memoizedAdd(1, 2, 4); // 6肯定是有问题的,如果要支持多参数,我们就需要传入 hasher 函数,自定义存储的 key 值。所以我们考虑使用 JSON.stringify:
var memoizedAdd = memoize(add, function() {
var args = Array.prototype.slice.call(arguments);
return JSON.stringify(args);
});
console.log(memoizedAdd(1, 2, 3)); // 6
console.log(memoizedAdd(1, 2, 4)); // 7如果使用 JSON.stringify,参数是对象的问题也可以得到解决,因为存储的是对象序列化后的字符串。
适用场景
我们以斐波那契数列为例:
var count = 0;
var fibonacci = function(n) {
count++;
return n < 2 ? n : fibonacci(n - 1) + fibonacci(n - 2);
};
for (var i = 0; i <= 10; i++) {
fibonacci(i);
}
console.log(count); // 453我们会发现最后的 count 数为 453,也就是说 fibonacci 函数被调用了 453 次!也许你会想,我只是循环到了 10,为什么就被调用了这么多次,所以我们来具体分析下:
当执行 fib(0) 时,调用 1 次
当执行 fib(1) 时,调用 1 次
当执行 fib(2) 时,相当于 fib(1) + fib(0) 加上 fib(2) 本身这一次,共 1 + 1 + 1 = 3 次
当执行 fib(3) 时,相当于 fib(2) + fib(1) 加上 fib(3) 本身这一次,共 3 + 1 + 1 = 5 次
当执行 fib(4) 时,相当于 fib(3) + fib(2) 加上 fib(4) 本身这一次,共 5 + 3 + 1 = 9 次
当执行 fib(5) 时,相当于 fib(4) + fib(3) 加上 fib(5) 本身这一次,共 9 + 5 + 1 = 15 次
当执行 fib(6) 时,相当于 fib(5) + fib(4) 加上 fib(6) 本身这一次,共 15 + 9 + 1 = 25 次
当执行 fib(7) 时,相当于 fib(6) + fib(5) 加上 fib(7) 本身这一次,共 25 + 15 + 1 = 41 次
当执行 fib(8) 时,相当于 fib(7) + fib(6) 加上 fib(8) 本身这一次,共 41 + 25 + 1 = 67 次
当执行 fib(9) 时,相当于 fib(8) + fib(7) 加上 fib(9) 本身这一次,共 67 + 41 + 1 = 109 次
当执行 fib(10) 时,相当于 fib(9) + fib(8) 加上 fib(10) 本身这一次,共 109 + 67 + 1 = 177 次所以执行的总次数为:177 + 109 + 67 + 41 + 25 + 15 + 9 + 5 + 3 + 1 + 1 = 453 次!
如果我们使用函数记忆呢?
var count = 0;
var fibonacci = function(n) {
count++;
return n < 2 ? n : fibonacci(n - 1) + fibonacci(n - 2);
};
fibonacci = memoize(fibonacci);
for (var i = 0; i <= 10; i++) {
fibonacci(i);
}
console.log(count); // 12我们会发现最后的总次数为 12 次,因为使用了函数记忆,调用次数从 453 次降低为了 12 次!
兴奋的同时不要忘记思考:为什么会是 12 次呢?
从 0 到 10 的结果各储存一遍,应该是 11 次呐?咦,那多出来的一次是从哪里来的?
所以我们还需要认真看下我们的写法,在我们的写法中,其实我们用生成的 fibonacci 函数覆盖了原本了 fibonacci 函数,当我们执行 fibonacci(0) 时,执行一次函数,cache 为 {0: 0},但是当我们执行 fibonacci(2) 的时候,执行 fibonacci(1) + fibonacci(0),因为 fibonacci(0) 的值为 0,!cache[address] 的结果为 true,又会执行一次 fibonacci 函数。原来,多出来的那一次是在这里!
总结
也许你会觉得在日常开发中又用不到 fibonacci,这个例子感觉实用价值不高呐,其实,这个例子是用来表明一种使用的场景,也就是如果需要大量重复的计算,或者大量计算又依赖于之前的结果,便可以考虑使用函数记忆。而这种场景,当你遇到的时候,你就会知道的。
递归
定义
程序调用自身的编程技巧称为递归(recursion)。
阶乘
以阶乘为例:
function factorial(n) {
if (n == 1) return n;
return n * factorial(n - 1);
}
console.log(factorial(5)); // 5 * 4 * 3 * 2 * 1 = 120斐波那契数列
function fibonacci(n) {
return n < 2 ? n : fibonacci(n - 1) + fibonacci(n - 2);
}
console.log(fibonacci(5)); // 1 1 2 3 5递归条件
从这两个例子中,我们可以看出:
构成递归需具备边界条件、递归前进段和递归返回段,当边界条件不满足时,递归前进,当边界条件满足时,递归返回,斐波那契数列中的 n < 2 就是边界条件。
总结一下递归的特点:
- 子问题须与原始问题为同样的事,且更为简单;
- 不能无限制地调用本身,须有个出口,化简为非递归状况处理。
了解这些特点可以帮助我们更好的编写递归函数。
执行上下文栈
当执行一个函数的时候,就会创建一个执行上下文,并且压入执行上下文栈,当函数执行完毕的时候,就会将函数的执行上下文从栈中弹出。
试着对阶乘函数分析执行的过程,我们会发现,JavaScript 会不停的创建执行上下文压入执行上下文栈,对于内存而言,维护这么多的执行上下文也是一笔不小的开销呐!那么,我们该如何优化呢?
答案就是尾调用。
尾调用
尾调用,是指函数内部的最后一个动作是函数调用。该调用的返回值,直接返回给函数。
举个例子:
// 尾调用
function f(x) {
return g(x);
}然而
// 非尾调用
function f(x) {
return g(x) + 1;
}并不是尾调用,因为 g(x) 的返回值还需要跟 1 进行计算后,f(x) 才会返回值。
两者又有什么区别呢?答案就是执行上下文栈的变化不一样。
为了模拟执行上下文栈的行为,让我们定义执行上下文栈是一个数组:
ECStack = [];我们模拟下第一个尾调用函数执行时的执行上下文栈变化:
// 伪代码
ECStack.push(<f> functionContext);
ECStack.pop();
ECStack.push(<g> functionContext);
ECStack.pop();我们再来模拟一下第二个非尾调用函数执行时的执行上下文栈变化:
ECStack.push(<f> functionContext);
ECStack.push(<g> functionContext);
ECStack.pop();
ECStack.pop();也就说尾调用函数执行时,虽然也调用了一个函数,但是因为原来的的函数执行完毕,执行上下文会被弹出,执行上下文栈中相当于只多压入了一个执行上下文。然而非尾调用函数,就会创建多个执行上下文压入执行上下文栈。
函数调用自身,称为递归。如果尾调用自身,就称为尾递归。
所以我们只用把阶乘函数改造成一个尾递归形式,就可以避免创建那么多的执行上下文。但是我们该怎么做呢?
阶乘函数优化
我们需要做的就是把所有用到的内部变量改写成函数的参数,以阶乘函数为例:
// factorial(4, 1)
// factorial(3, 4)
// factorial(2, 12)
// factorial(1, 24)
// 24
function factorial(n, res) {
if (n == 1) return res;
return factorial(n - 1, n * res);
}
console.log(factorial(4, 1)); // 24然而这个很奇怪呐……我们计算 4 的阶乘,结果函数要传入 4 和 1,我就不能只传入一个 4 吗?
这个时候就要用到 partial 函数了:
var newFactorial = partial(factorial, _, 1);
newFactorial(4); // 24乱序
乱序的意思就是将数组打乱。
Math.random
一个经常会遇见的写法是使用 Math.random():
var values = [1, 2, 3, 4, 5];
values.sort(function() {
return Math.random() - 0.5;
});
console.log(values);Math.random() - 0.5 随机得到一个正数、负数或是 0,如果是正数则降序排列,如果是负数则升序排列,如果是 0 就不变,然后不断的升序或者降序,最终得到一个乱序的数组。
看似很美好的一个方案,实际上,效果却不尽如人意。不信我们写个 demo 测试一下:
var times = [0, 0, 0, 0, 0];
for (var i = 0; i < 100000; i++) {
let arr = [1, 2, 3, 4, 5];
arr.sort(() => Math.random() - 0.5);
times[arr[4] - 1]++;
}
console.log(times);测试原理是:将 [1, 2, 3, 4, 5] 乱序 10 万次,计算乱序后的数组的最后一个元素是 1、2、3、4、5 的次数分别是多少。
一次随机的结果为:
[30636, 30906, 20456, 11743, 6259];该结果表示 10 万次中,数组乱序后的最后一个元素是 1 的情况共有 30636 次,是 2 的情况共有 30906 次,其他依此类推。
我们会发现,最后一个元素为 5 的次数远远低于为 1 的次数,所以这个方案是有问题的。
插入排序
如果要追究这个问题所在,就必须了解 sort 函数的原理,然而 ECMAScript 只规定了效果,没有规定实现的方式,所以不同浏览器实现的方式还不一样。
为了解决这个问题,我们以 v8 为例,v8 在处理 sort 方法时,当目标数组长度小于 10 时,使用插入排序;反之,使用快速排序和插入排序的混合排序。
所以我们来看看 v8 的源码,因为是用 JavaScript 写的,大家也是可以看懂的。
源码地址:https://github.com/v8/v8/blob/master/src/js/array.js
为了简化篇幅,我们对 [1, 2, 3] 这个数组进行分析,数组长度为 3,此时采用的是插入排序。
插入排序的源码是:
function InsertionSort(a, from, to) {
for (var i = from + 1; i < to; i++) {
var element = a[i];
for (var j = i - 1; j >= from; j--) {
var tmp = a[j];
var order = comparefn(tmp, element);
if (order > 0) {
a[j + 1] = tmp;
} else {
break;
}
}
a[j + 1] = element;
}
}其原理在于将第一个元素视为有序序列,遍历数组,将之后的元素依次插入这个构建的有序序列中。
我们来个简单的示意图:
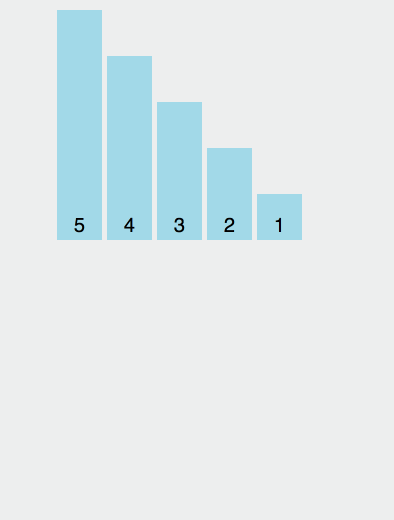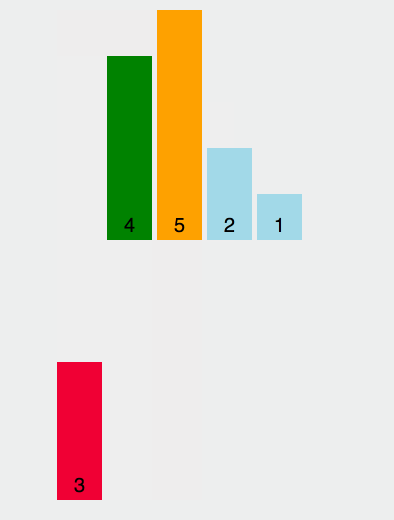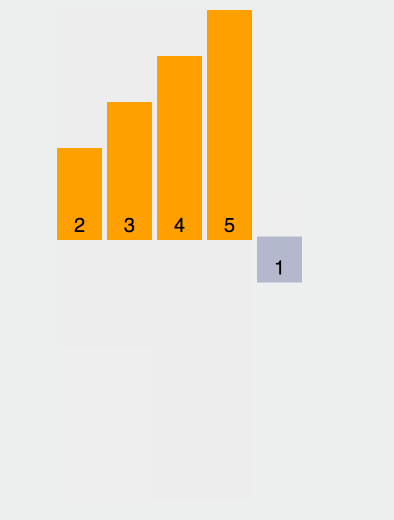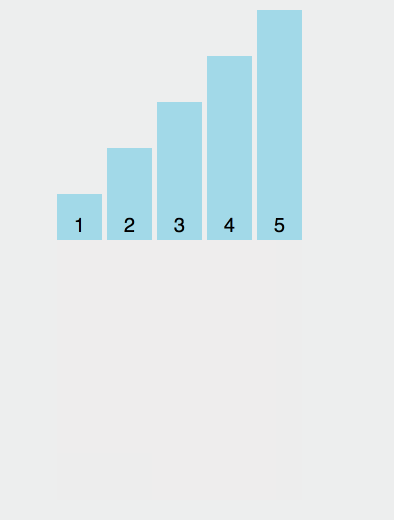
具体分析
明白了插入排序的原理,我们来具体分析下 [1, 2, 3] 这个数组乱序的结果。
演示代码为:
var values = [1, 2, 3];
values.sort(function() {
return Math.random() - 0.5;
});注意此时 sort 函数底层是使用插入排序实现,InsertionSort 函数的 from 的值为 0,to 的值为 3。
我们开始逐步分析乱序的过程:
因为插入排序视第一个元素为有序的,所以数组的外层循环从 i = 1 开始,a[i] 值为 2,此时内层循环遍历,比较 compare(1, 2),因为 Math.random() - 0.5 的结果有 50% 的概率小于 0 ,有 50% 的概率大于 0,所以有 50% 的概率数组变成 [2, 1, 3],50% 的结果不变,数组依然为 [1, 2, 3]。
假设依然是 [1, 2, 3],我们再进行一次分析,接着遍历,i = 2,a[i] 的值为 3,此时内层循环遍历,比较 compare(2, 3):
有 50% 的概率数组不变,依然是 [1, 2, 3],然后遍历结束。
有 50% 的概率变成 [1, 3, 2],因为还没有找到 3 正确的位置,所以还会进行遍历,所以在这 50% 的概率中又会进行一次比较,compare(1, 3),有 50% 的概率不变,数组为 [1, 3, 2],此时遍历结束,有 50% 的概率发生变化,数组变成 [3, 1, 2]。
综上,在 [1, 2, 3] 中,有 50% 的概率会变成 [1, 2, 3],有 25% 的概率会变成 [1, 3, 2],有 25% 的概率会变成 [3, 1, 2]。
另外一种情况 [2, 1, 3] 与之分析类似,我们将最终的结果汇总成一个表格:
| 数组 | i = 1 | i = 2 | 总计 |
|---|---|---|---|
| [1, 2, 3] | 50% [1, 2, 3] | 50% [1, 2, 3] | 25% [1, 2, 3] |
| 25% [1, 3, 2] | 12.5% [1, 3, 2] | ||
| 25% [3, 1, 2] | 12.5% [3, 1, 2] | ||
| 50% [2, 1, 3] | 50% [2, 1, 3] | 25% [2, 1, 3] | |
| 25% [2, 3, 1] | 12.5% [2, 3, 1] | ||
| 25% [3, 2, 1] | 12.5% [3, 2, 1] |
为了验证这个推算是否准确,我们写个 demo 测试一下:
var times = 100000;
var res = {};
for (var i = 0; i < times; i++) {
var arr = [1, 2, 3];
arr.sort(() => Math.random() - 0.5);
var key = JSON.stringify(arr);
res[key] ? res[key]++ : (res[key] = 1);
}
// 为了方便展示,转换成百分比
for (var key in res) {
res[key] = (res[key] / times) * 100 + '%';
}
console.log(res);这是一次随机的结果:

我们会发现,乱序后,3 还在原位置(即 [1, 2, 3] 和 [2, 1, 3]) 的概率有 50% 呢。
所以根本原因在于什么呢?其实就在于在插入排序的算法中,当待排序元素跟有序元素进行比较时,一旦确定了位置,就不会再跟位置前面的有序元素进行比较,所以就乱序的不彻底。
那么如何实现真正的乱序呢?而这就要提到经典的 Fisher–Yates 算法。
Fisher–Yates
为什么叫 Fisher–Yates 呢? 因为这个算法是由 Ronald Fisher 和 Frank Yates 首次提出的。
话不多说,我们直接看 JavaScript 的实现:
function shuffle(a) {
var j, x, i;
for (i = a.length; i; i--) {
j = Math.floor(Math.random() * i);
x = a[i - 1];
a[i - 1] = a[j];
a[j] = x;
}
return a;
}原理很简单,就是遍历数组元素,然后将当前元素与以后随机位置的元素进行交换,从代码中也可以看出,这样乱序的就会更加彻底。
如果利用 ES6,代码还可以简化成:
function shuffle(a) {
for (let i = a.length; i; i--) {
let j = Math.floor(Math.random() * i);
[a[i - 1], a[j]] = [a[j], a[i - 1]];
}
return a;
}还是再写个 demo 测试一下吧:
var times = 100000;
var res = {};
for (var i = 0; i < times; i++) {
var arr = shuffle([1, 2, 3]);
var key = JSON.stringify(arr);
res[key] ? res[key]++ : (res[key] = 1);
}
// 为了方便展示,转换成百分比
for (var key in res) {
res[key] = (res[key] / times) * 100 + '%';
}
console.log(res);这是一次随机的结果:

真正的实现了乱序的效果!
解读 v8 排序源码
v8 是 Chrome 的 JavaScript 引擎,其中关于数组的排序完全采用了 JavaScript 实现。
排序采用的算法跟数组的长度有关,当数组长度小于等于 10 时,采用插入排序,大于 10 的时候,采用快速排序。(当然了,这种说法并不严谨)。
我们先来看看插入排序和快速排序。
插入排序
原理
将第一个元素视为有序序列,遍历数组,将之后的元素依次插入这个构建的有序序列中。
图示
实现
function insertionSort(arr) {
for (var i = 1; i < arr.length; i++) {
var element = arr[i];
for (var j = i - 1; j >= 0; j--) {
var tmp = arr[j];
var order = tmp - element;
if (order > 0) {
arr[j + 1] = tmp;
} else {
break;
}
}
arr[j + 1] = element;
}
return arr;
}
var arr = [6, 5, 4, 3, 2, 1];
console.log(insertionSort(arr));时间复杂度
时间复杂度是指执行算法所需要的计算工作量,它考察当输入值大小趋近无穷时的情况,一般情况下,算法中基本操作重复执行的次数是问题规模 n 的某个函数。
最好情况:数组升序排列,时间复杂度为:O(n)
最坏情况:数组降序排列,时间复杂度为:O(n²)
稳定性
稳定性,是指相同的元素在排序后是否还保持相对的位置。
要注意的是对于不稳定的排序算法,只要举出一个实例,即可说明它的不稳定性;而对于稳定的排序算法,必须对算法进行分析从而得到稳定的特性。
比如 [3, 3, 1],排序后,还是 [3, 3, 1],但是其实是第二个 3 在第一个 3 前,那这就是不稳定的排序算法。
插入排序是稳定的算法。
优势
当数组是快要排序好的状态或者问题规模比较小的时候,插入排序效率更高。这也是为什么 v8 会在数组长度小于等于 10 的时候采用插入排序。
快速排序
原理
- 选择一个元素作为”基准”
- 小于”基准”的元素,都移到”基准”的左边;大于”基准”的元素,都移到”基准”的右边。
- 对”基准”左边和右边的两个子集,不断重复第一步和第二步,直到所有子集只剩下一个元素为止。
示例
以数组 [85, 24, 63, 45, 17, 31, 96, 50] 为例:
第一步,选择中间的元素 45 作为”基准”。(基准值可以任意选择,但是选择中间的值比较容易理解。)

第二步,按照顺序,将每个元素与”基准”进行比较,形成两个子集,一个”小于 45”,另一个”大于等于 45”。

第三步,对两个子集不断重复第一步和第二步,直到所有子集只剩下一个元素为止。
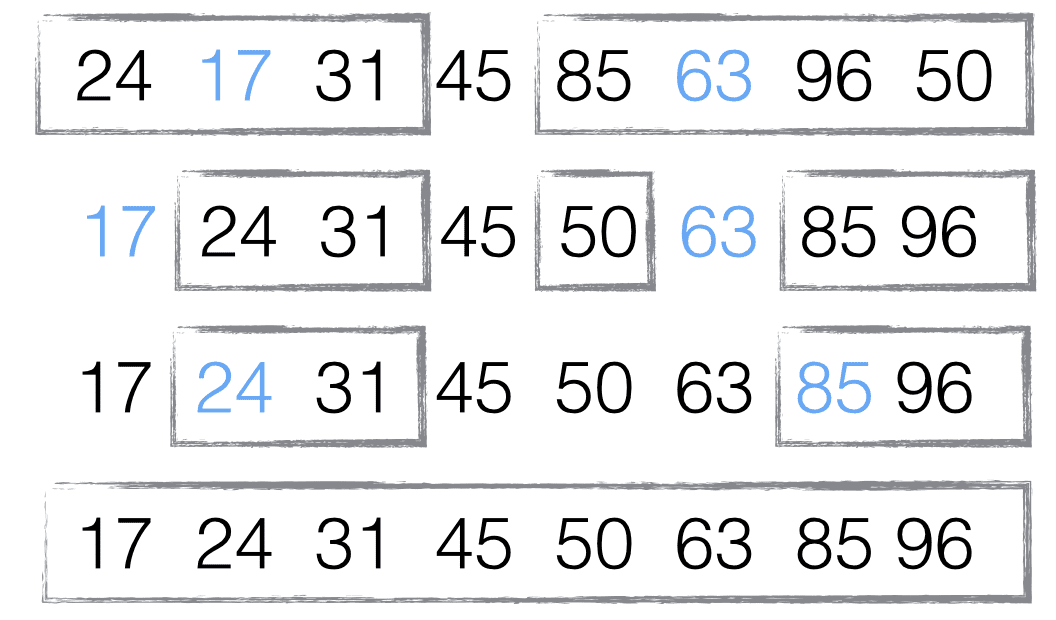
实现
var quickSort = function(arr) {
if (arr.length <= 1) {
return arr;
}
// 取数组的中间元素作为基准
var pivotIndex = Math.floor(arr.length / 2);
var pivot = arr.splice(pivotIndex, 1)[0];
var left = [];
var right = [];
for (var i = 0; i < arr.length; i++) {
if (arr[i] < pivot) {
left.push(arr[i]);
} else {
right.push(arr[i]);
}
}
return quickSort(left).concat([pivot], quickSort(right));
};然而这种实现方式需要额外的空间用来储存左右子集,所以还有一种原地(in-place)排序的实现方式。
in-place 实现
在这张示意图里,基准的取值规则是取最左边的元素,黄色代表当前的基准,绿色代表小于基准的元素,紫色代表大于基准的元素。
我们会发现,绿色的元素会紧挨在基准的右边,紫色的元素会被移到后面,然后交换基准和绿色的最后一个元素,此时,基准处于正确的位置,即前面的元素都小于基准值,后面的元素都大于基准值。然后再对前面的和后面的多个元素取基准,做排序。
function quickSort(arr) {
// 交换元素
function swap(arr, a, b) {
var temp = arr[a];
arr[a] = arr[b];
arr[b] = temp;
}
function partition(arr, left, right) {
var pivot = arr[left];
var storeIndex = left;
for (var i = left + 1; i <= right; i++) {
if (arr[i] < pivot) {
swap(arr, ++storeIndex, i);
}
}
swap(arr, left, storeIndex);
return storeIndex;
}
function sort(arr, left, right) {
if (left < right) {
var storeIndex = partition(arr, left, right);
sort(arr, left, storeIndex - 1);
sort(arr, storeIndex + 1, right);
}
}
sort(arr, 0, arr.length - 1);
return arr;
}
console.log(quickSort([6, 7, 3, 4, 1, 5, 9, 2, 8]));稳定性
快速排序是不稳定的排序。如果要证明一个排序是不稳定的,你只用举出一个实例就行。
所以我们举一个呗~
就以数组 [1, 2, 3, 3, 4, 5] 为例,因为基准的选择不确定,假如选定了第三个元素(也就是第一个 3) 为基准,所有小于 3 的元素在前面,大于等于 3 的在后面,排序的结果没有问题。可是如果选择了第四个元素(也就是第二个 3 ),小于 3 的在基准前面,大于等于 3 的在基准后面,第一个 3 就会被移动到第二个 3 后面,所以快速排序是不稳定的排序。
时间复杂度
阮一峰老师的实现中,基准取的是中间元素,而原地排序中基准取最左边的元素。快速排序的关键点就在于基准的选择,选取不同的基准时,会有不同性能表现。
快速排序的时间复杂度最好为 O(nlogn),可是为什么是 nlogn 呢?来一个并不严谨的证明:
在最佳情况下,每一次都平分整个数组。假设数组有 n 个元素,其递归的深度就为 log2n + 1,时间复杂度为 O(n)[(log2n + 1)],因为时间复杂度考察当输入值大小趋近无穷时的情况,所以会忽略低阶项,时间复杂度为:o(nlog2n)。
如果一个程序的运行时间是对数级的,则随着 n 的增大程序会渐渐慢下来。如果底数是 10,lg1000 等于 3,如果 n 为 1000000,lgn 等于 6,仅为之前的两倍。如果底数为 2,log21000 的值约为 10,log21000000 的值约为 19,约为之前的两倍。我们可以发现任意底数的一个对数函数其实都相差一个常数倍而已。所以我们认为 O(logn)已经可以表达所有底数的对数了,所以时间复杂度最后为: O(nlogn)。
而在最差情况下,如果对一个已经排序好的数组,每次选择基准元素时总是选择第一个元素或者最后一个元素,那么每次都会有一个子集是空的,递归的层数将达到 n,最后导致算法的时间复杂度退化为 O(n²)。
这也充分说明了一个基准的选择是多么的重要,而 v8 为了提高性能,就对基准的选择做了很多优化。
v8 基准选择
v8 选择基准的原理是从头和尾之外再选择一个元素,然后三个值排序取中间值。
当数组长度大于 10 但是小于 1000 的时候,取中间位置的元素,实现代码为:
// 基准的下标
// >> 1 相当于除以 2 (忽略余数)
third_index = from + ((to - from) >> 1);当数组长度大于 1000 的时候,每隔 200 ~ 215 个元素取一个值,然后将这些值进行排序,取中间值的下标,实现的代码为:
// 简单处理过
function GetThirdIndex(a, from, to) {
var t_array = new Array();
// & 位运算符
var increment = 200 + ((to - from) & 15);
var j = 0;
from += 1;
to -= 1;
for (var i = from; i < to; i += increment) {
t_array[j] = [i, a[i]];
j++;
}
// 对随机挑选的这些值进行排序
t_array.sort(function(a, b) {
return comparefn(a[1], b[1]);
});
// 取中间值的下标
var third_index = t_array[t_array.length >> 1][0];
return third_index;
}也许你会好奇 200 + ((to - from) & 15) 是什么意思?
& 表示是按位与,对整数操作数逐位执行布尔与操作。只有两个操作数中相对应的位都是 1,结果中的这一位才是 1。
以 15 & 127 为例:
15 二进制为: (0000 1111)
127 二进制为:(1111 1111)
按位与结果为:(0000 1111)= 15
所以 15 & 127 的结果为 15。
注意 15 的二进制为: 1111,这就意味着任何和 15 按位与的结果都会小于或者等于 15,这才实现了每隔 200 ~ 215 个元素取一个值。
v8 源码
function InsertionSort(a, from, to) {
for (var i = from + 1; i < to; i++) {
var element = a[i];
for (var j = i - 1; j >= from; j--) {
var tmp = a[j];
var order = comparefn(tmp, element);
if (order > 0) {
a[j + 1] = tmp;
} else {
break;
}
}
a[j + 1] = element;
}
}
function QuickSort(a, from, to) {
var third_index = 0;
while (true) {
// Insertion sort is faster for short arrays.
if (to - from <= 10) {
InsertionSort(a, from, to);
return;
}
if (to - from > 1000) {
third_index = GetThirdIndex(a, from, to);
} else {
third_index = from + ((to - from) >> 1);
}
// Find a pivot as the median of first, last and middle element.
var v0 = a[from];
var v1 = a[to - 1];
var v2 = a[third_index];
var c01 = comparefn(v0, v1);
if (c01 > 0) {
// v1 < v0, so swap them.
var tmp = v0;
v0 = v1;
v1 = tmp;
} // v0 <= v1.
var c02 = comparefn(v0, v2);
if (c02 >= 0) {
// v2 <= v0 <= v1.
var tmp = v0;
v0 = v2;
v2 = v1;
v1 = tmp;
} else {
// v0 <= v1 && v0 < v2
var c12 = comparefn(v1, v2);
if (c12 > 0) {
// v0 <= v2 < v1
var tmp = v1;
v1 = v2;
v2 = tmp;
}
}
// v0 <= v1 <= v2
a[from] = v0;
a[to - 1] = v2;
var pivot = v1;
var low_end = from + 1; // Upper bound of elements lower than pivot.
var high_start = to - 1; // Lower bound of elements greater than pivot.
a[third_index] = a[low_end];
a[low_end] = pivot;
// From low_end to i are elements equal to pivot.
// From i to high_start are elements that haven't been compared yet.
partition: for (var i = low_end + 1; i < high_start; i++) {
var element = a[i];
var order = comparefn(element, pivot);
if (order < 0) {
a[i] = a[low_end];
a[low_end] = element;
low_end++;
} else if (order > 0) {
do {
high_start--;
if (high_start == i) break partition;
var top_elem = a[high_start];
order = comparefn(top_elem, pivot);
} while (order > 0);
a[i] = a[high_start];
a[high_start] = element;
if (order < 0) {
element = a[i];
a[i] = a[low_end];
a[low_end] = element;
low_end++;
}
}
}
if (to - high_start < low_end - from) {
QuickSort(a, high_start, to);
to = low_end;
} else {
QuickSort(a, from, low_end);
from = high_start;
}
}
}
var arr = [10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0];
function comparefn(a, b) {
return a - b;
}
QuickSort(arr, 0, arr.length);
console.log(arr);我们以数组 [10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0] 为例,分析执行的过程。
-
执行 QuickSort 函数参数 from 值为 0,参数 to 的值 11。
-
10 < to - from < 1000 第三个基准元素的下标为 (0 + 11 >> 1) = 5,基准值 a[5] 为 5。
-
比较 a[0] a[10] a[5] 的值,然后根据比较结果修改数组,数组此时为 [0, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10]
-
将基准值和数组的第(from + 1)个即数组的第二个元素互换,此时数组为 [0, 5, 8, 7, 6, 9, 4, 3, 2, 1, 10],此时在基准值 5 前面的元素肯定是小于 5 的,因为第三步已经做了一次比较。后面的元素是未排序的。我们接下来要做的就是把后面的元素中小于 5 的全部移到 5 的前面。
-
然后我们进入 partition 循环,我们依然以这个数组为例,单独抽出来写个 demo 讲一讲
// 假设代码执行到这里,为了方便演示,我们直接设置 low_end 等变量的值 // 可以直接复制到浏览器中查看数组变换效果 var a = [0, 5, 8, 7, 6, 9, 4, 3, 2, 1, 10]; var low_end = 1; var high_start = 10; var pivot = 5; console.log('起始数组为', a); partition: for (var i = low_end + 1; i < high_start; i++) { var element = a[i]; console.log('循环当前的元素为:', a[i]); var order = element - pivot; if (order < 0) { a[i] = a[low_end]; a[low_end] = element; low_end++; console.log(a); } else if (order > 0) { do { high_start--; if (high_start == i) break partition; var top_elem = a[high_start]; order = top_elem - pivot; } while (order > 0); a[i] = a[high_start]; a[high_start] = element; console.log(a); if (order < 0) { element = a[i]; a[i] = a[low_end]; a[low_end] = element; low_end++; } console.log(a); } } console.log('最后的结果为', a); console.log(low_end); console.log(high_start); -
此时数组为 [0, 5, 8, 7, 6, 9, 4, 3, 2, 1, 10],循环从第三个元素开始,a[i] 的值为 8,因为大于基准值 5,即 order > 0,开始执行 do while 循环,do while 循环的目的在于倒序查找元素,找到第一个小于基准值的元素,然后让这个元素跟 a[i] 的位置交换。第一个小于基准值的元素为 1,然后 1 与 8 交换,数组变成 [0, 5, 1, 7, 6, 9, 4, 3, 2, 8, 10]。high_start 的值是为了记录倒序查找到哪里了。
-
此时 a[i] 的值变成了 1,然后让 1 跟基准值 5 交换,数组变成了 [0, 1, 5, 7, 6, 9, 4, 3, 2, 8, 10],lowend 的值加 1,lowend 的值是为了记录基准值的所在位置。
-
循环接着执行,遍历第四个元素 7,跟第 6、7 的步骤一致,数组先变成 [0, 1, 5, 2, 6, 9, 4, 3, 7, 8, 10],再变成 [0, 1, 2, 5, 6, 9, 4, 3, 7, 8, 10]
-
遍历第五个元素 6,跟第 6、7 的步骤一致,数组先变成 [0, 1, 2, 5, 3, 9, 4, 6, 7, 8, 10],再变成 [0, 1, 2, 3, 5, 9, 4, 6, 7, 8, 10]
-
遍历第六个元素 9,跟第 6、7 的步骤一致,数组先变成 [0, 1, 2, 3, 5, 4, 9, 6, 7, 8, 10],再变成 [0, 1, 2, 3, 4, 5, 9, 6, 7, 8, 10]
-
在下一次遍历中,因为 i == high_start,意味着正序和倒序的查找终于找到一起了,后面的元素肯定都是大于基准值的,此时退出循环
-
遍历后的结果为 [0, 1, 2, 3, 4, 5, 9, 6, 7, 8, 10],在基准值 5 前面的元素都小于 5,后面的元素都大于 5,然后我们分别对两个子集进行 QuickSort
-
此时 lowend 值为 5,highstart 值为 6,to 的值依然是 10,from 的值依然是 0,to - highstart < lowend - from 的结果为 true,我们对 QuickSort(a, 6, 10),即对后面的元素进行排序,但是注意,在新的 QuickSort 中,因为 to - from 的值小于 10,所以这一次其实是采用了插入排序。所以准确的说,当数组长度大于 10 的时候,v8 采用了快速排序和插入排序的混合排序方法。
-
然后 to = low_end 即设置 to 为 5,因为 while(true) 的原因,会再执行一遍,to - from 的值为 5,执行 InsertionSort(a, 0, 5),即对基准值前面的元素执行一次插入排序。
-
因为在 to - from <= 10 的判断中,有 return 语句,所以 while 循环结束。
-
v8 在对数组进行了一次快速排序后,然后对两个子集分别进行了插入排序,最终修改数组为正确排序后的数组。
比较
最后来张示意图感受下插入排序和快速排序:
