分布式系统、单体系统区别
分布式系统是对单体系统的一种改进,但这种改进同样也带来了复杂度和实现难度。
背景
单体系统是包含一个物理组件的系统,能够独立进行部署和运行。可以看到在单体系统内部可以采用分层的方式合理组织代码结构,但从物理上看就是一个能够独立运行的应用程序。
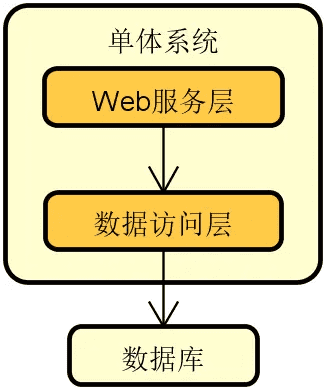
存在以下情况不能应对:
- 业务复杂度和产品迭代速度
- 处理高并发、大数据量的用户请求
- 代码维护和团队协作
但是分布式系统引入了新问题
- 网络传输的三态性
- 数据的一致性
- 可用性
技术体系
单体系统的核心问题
单体系统的核心问题表现在三个方面
-
业务扩展性:任何业务的调整都需要发布整个系统,改一个地方就要重新构建、发布整个系统
-
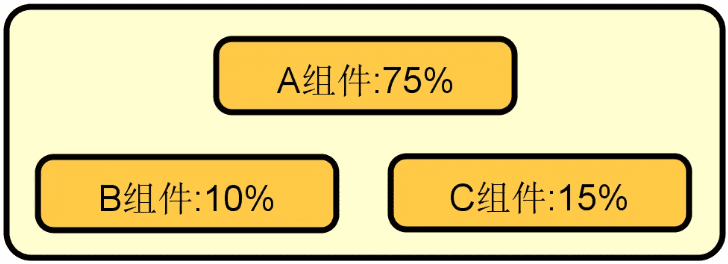
性能伸缩性:动态扩容对单体系统而言效率低下,如果通过简单扩容就能确保系统性能得到等比例提升,那么该系统就具备良好的伸缩性。对于单体系统来说,由于不同功能都在里面,即内存密集型和 CPU 密集型的代码都位于同一个服务器上,所以很难做到对资源的充分利用,如下图每个组件对资源利用率不同,无法针对组件级别进行资源利用率的提升
![2024 10 11 18 18 37]()
-
代码复杂度:修改一处代码容易引发连锁问题,不同组件间边界模糊,由于代码复杂度导致的系统缺陷会触发很多连锁问题
分布式系统的本质特性
区别于单体系统,分布式系统会将整个系统拆分成多个能够独立运行的服务,这些服务在物理上是隔离的,相互之间基于网络进行通信和协调
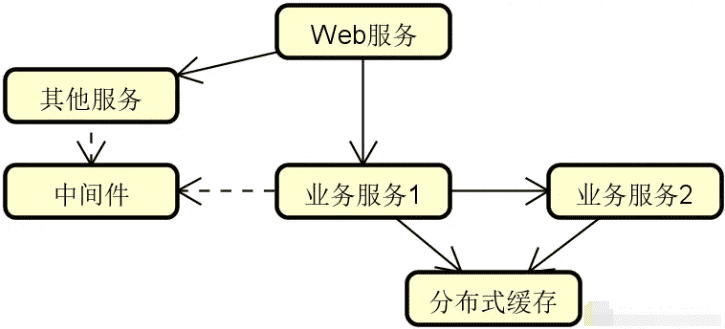
下图展示的就是现实场景中常见的一种分布式系统,可以看到这里有专门针对业务处理的业务服务 1 和业务服务 2 这两个独立的服务,也存在 Web 服务、消息中间件、缓存等提供技术能力的独立组件
想要实现分布式系统,首要的就是完成对系统中各个服务的合理拆分。通常,我们有两种主流的拆分方式,即纵向(Vertical)拆分和横向(Horizontal)拆分
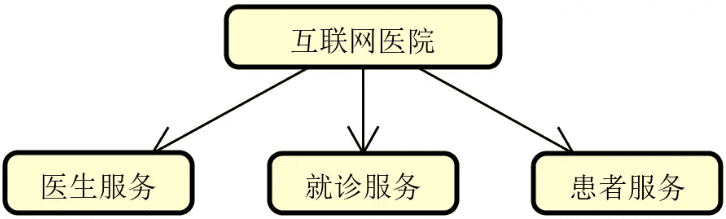
可以认为纵向拆分的目的就是更好地完成对系统中业务服务的合理组织。围绕一个完整而复杂的业务执行流程,我们通常可以根据不同的业务场景以及数据属性来完成对业务服务的拆分。例如,在常见的互联网医院系统中,具备最基本的医生、患者以及问诊等业务处理场景和数据,这时候我们就可以基于这些场景和数据来分别提取独立的业务服务,如下图所示
介绍完纵向拆分,我们再来看横向拆分。横向拆分的切入点在于复用,即我们在提取一系列独立服务的同时,还需要考虑通过一定的手段将它们高效地整合在一起。这样,整个系统就可以像是在搭积木一样对各个服务进行排列组合,如下图所示:
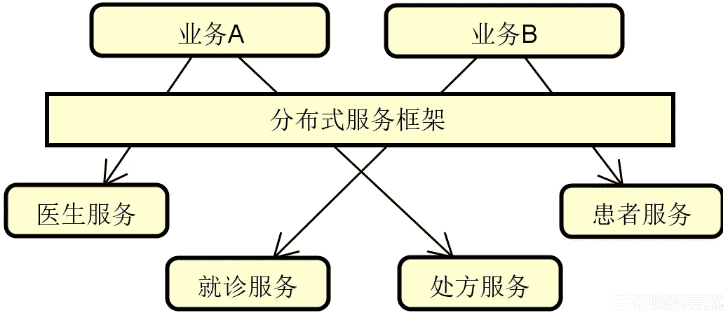
在上图中,我们注意到引入了一个分布式服务框架。通过该框架,系统中的医生服务、患者服务等一系列独立服务就可以进行合理地编排和整合,从而构建业务 A、业务 B 等不同的业务场景。显然,分布式服务框架在这里扮演了重要作用,而后续内容中所要介绍的 Dubbo 和 Spring Cloud 就是目前主流的分布式服务框架。
请注意,分布式系统相较于单体系统而言具备优势的同时,也存在一些我们不得不考虑的特性,包括以下
-
网络传输的三态性
我们知道对于单体系统中的函数式方法调用而言,只有“成功”或“失败”这两种状态。但是分布式系统则不同,因为远程请求是通过网络进行传输的,而网络在处理请求时还会出现”超时”这个状态,这样就相当于有三个状态。
显然,网络传输的三态性为系统开发带来新的挑战。面对超时状态,我们不能简单把它处理成是一种成功或失败,而是要具体场景具体分析,避免出现请求丢失或请求重复发送现象。在分布式系统设计过程中,我们需要考虑这种由于网络通信所导致的用户体验问题。
-
请求的容错性
从错误发生的几率而言,分布式系统显然比单体系统更加容易出错,因为系统的调用链路变得更长、更复杂。每个分布式服务自身可能会发生异常,而这种异常在整个调用链路上会进行扩散,最终可能导致整个系统都不可用。
在分布式系统设计过程中,一大挑战就是需要确保部分服务的异常情况不会影响到整个系统的可用性。
-
系统的异构性
分布式系统的异构性很好理解,原则上,每个服务都可以采用一套完全不同的技术体系来进行实现,只要它们对外暴露接口是统一的。但是,因为技术异构性的存在,会增加分布式系统的开发难度和维护成本。
-
数据的一致性
在分布式系统中,各个服务通常都会构建属于自身的数据库,这样就会导致业务数据无法进行集中管理,也就无法通过传统的事务机制确保它们之间的一致性。如何实现数据的一致性是分布式系统构建过程的一大难点。
以上几点是分布式系统的基本特性,我们无法避免,只能想办法进行利用和管理,这就给我们设计和实现分布式系统提出了挑战。
解题要点
通过对单体系统的核心问题和分布式系统本质特性的分析,我们明确了一点,即从技术演进角度讲,分布式系统的诞生是单体系统发展的必然结果。因此,在回答这类问题时,对于技术演进的背景和需求的讨论是我们的第一点回答思路。这部分内容通常不用过多展开,我们可以结合日常开发场景,从业务需求和技术需求角度简要介绍即可。
针对该类问题的第二点解答思路在于充分利用逻辑性和对比性。从面试题的考查方式而言,这是一道典型的对比类面试题。因此,针对如何介绍两个不同事物之间的差异,我们需要采用一定的逻辑性。一种比较容易掌握的技巧是:先抛出一个应用场景,然后分别对两种事物的正反面进行展开讨论。举例来说,如果我们想要阐述扩展性这一应用场景,那么对于单体系统而言,因为没有合理的业务边界和拆分策略,扩展性就很难保证;而对于分布式系统而言,通过引入合理的纵向/横向拆分机制就可以很好地解决这一问题。
虽然这是一道概念类的面试题,但也不要忘记在回答过程中提及一定的实践内容。对于面试过程而言,不管是怎么样的面试题,面试官都希望从候选人身上看到相关的实践经验。因此,最后一个解题的要点,就是建议你可以从日常开发过程出发,基于分布式系统的拆分和集成、请求容错性的实现、数据一致性的不同应对策略等角度,谈谈自己对分布式系统构建的一些思考和总结,相信是很好的加分项。
总结
我们已经提到了分布式系统所具备的一组本质特性,也强调了我们需要对这些特性进行合理的应用和管理。为此,我们需要进一步梳理分布式系统开发过程中的技术组件。那么,实现分布式系统应该具备哪些核心技术组件呢?
实现分布式系统应该具备哪些核心技术组件?
背景
分布式服务是构建分布式系统的基础,可以认为,任何一个分布式系统都是有若干个独立的服务所构成,这些服务通过网络通信实现相互调用,从而完成复杂的业务处理流程。
虽然,上图看起来并不复杂,但想要实现一套高性能、高可用、高扩展的分布式服务体系绝非易事。在日常开发过程中,我们在设计和实现分布式系统时需要系统梳理构建分布式服务的各个技术组件。而在实际的面试过程中这也是非常常见的一个面试问题,考查了候选人对分布式服务相关技术概念以及对应实现方案的理解程度。
从面试角度讲,涉及分布式服务技术组件的知识体系非常广泛,所以可以认为这是一道发散型的面试题,面试官想要的并不是一个标准答案,而是看候选人对这一主题理解的深度和广度。针对面试不同岗位的候选者,面试官的要求是不一样的,判断的标准也或有所不同。
问题分析
相信只要你开发过分布式系统,基本上都能对构建分布式服务所需要的技术组件说出个一二三来,比方说网络通信、远程调用。你可能也会提到负载均衡、集群容错这些更为复杂的名词。事实上,分布式服务的技术组件之间是有一定的逻辑关系的,有些组件能够独立运行,而有些组件则是构建在另一些组件的基础之上。比较典型的例子就是:配置中心的运行往往需要注册中心的支持,而服务容错则依赖于负载均衡的实现。
另一方面,对于分布式服务而言,组件与组件之间的定位也有所区别。有些是必备组件,缺少了它们系统就无法运行。有些则是扩展性组件,比较典型的就是前面提到的配置中心,原则上我们不使用配置中心也照样可以构建分布式系统。而还有一些则是通用型组件,这些组件并不局限于只能用于构建分布式服务,例如动态代理组件。
在面试过程中,关于这道题的问法其实有很多种,常见的包括:
- 如果想实现一套远程过程调用机制,你会重点设计哪几个技术组件?
- 负载均衡机制是如何与集群容错机制整合在一起的?
- 想要实现服务容错,有哪些技术手段?
- 微服务架构中,配置中心是如何与注册中心进行交互的?
- 为什么在分布式系统中,处处是代理?
- 在分布式服务构建过程中,经常用到的架构模式有哪些?
这些问题虽然问法各异,但考查的都是候选人对分布式服务中核心组件的理解程度。通过这样的分析,我们发现这一问题的难点在于我们要回答的概念有很多,而这些概念却又比较零散。当我们面对这种发散型面试题时,应对的方式绝对不能发散。单纯做零散的概念性阐述,往往很难得到面试官的认可,因为面试官会觉得你是刚接触分布式服务,没有自己的思考和体系。
应对这一问题的基本思路是要具备完整的技术认知,然后能够用自己的语言对各个组件的组成结构和基本原理做一定的展开,这样的话这道题应对起来就会比较自如。
因此,接下来我们就一起系统梳理该问题背后的技术体系。
技术体系
在分布式服务的开发过程中,开发人员需要应用到一批技术组件。按照这些技术组件的不同定位,我们把它们分成三大类,即远程过程调用组件、微服务构建组件和通用技术组件,如下图所示:
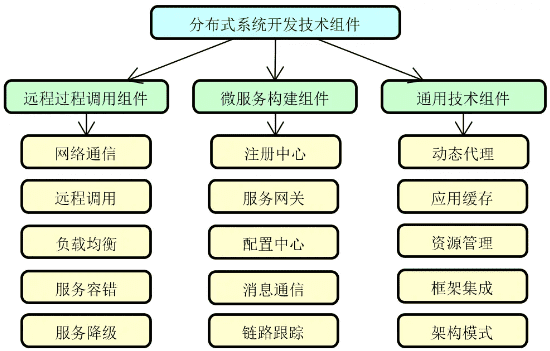
接下来,我们将对上图中的每一个技术组件做展开,从而为本课程后续内容的学习打好基础。
远程过程调用组件
远程过程调用是分布式服务最基础的实现技术,开发人员需要从网络通信、远程调用、负载均衡、服务容错以及服务降级这五个维度来进行系统的理解。
-
网络通信:网络通信是一切分布式操作的基础。当客户端和服务器端建立网络连接之后就可以相互发送消息。但围绕网络通信整个过程,事情并没有那么简单。我们需要考虑网络通信的性能、可靠性以及在通信过程中实现数据传输的方式,这就涉及到 IO 模型、可靠性设计以及序列化方式等一系列技术主题。
-
远程调用:远程调用解决的问题是如何发布远程服务以及如何引用远程服务。一旦服务发布成功,就相当于构建了一个有效的网络连接,并通过启动监听端口来对外暴露服务访问的入口;而服务引用则是一个向目标监听端点发起请求并获取响应结果的执行过程,如下图所示:
![2024 10 12 10 13 23]()
在服务调用过程中,远程调用本地化是基本要求,即远程调用过程的实现对于开发人员而言应该是透明的。同时,我们也需要考虑同步调用、异步调用以及同步转异步调用等一系列具体的调用实现策略。
-
负载均衡:所谓负载均衡,简单讲就是将请求按照一定的策略分摊到多个服务实例上进行执行,基本结构如下图所示:
![2024 10 12 10 14 04]()
负载均衡在实现上可以使用硬件、软件或者两者兼有。而针对软件负载均衡,也可以分成服务器端负载均衡和客户端负载均衡两大类。在分布式服务构建过程中,我们主要的讨论对象是基于软件的客户端负载均衡机制。例如,目前主流的微服务架构实现框架 Spring Cloud、Dubbo 等都内置了完整的客户端负载均衡模块。
另一方面,负载均衡算法决定了对请求进行分发的效果。负载均衡算法有很多,可以分成静态和动态两个大类,它们之间的区别在于动态算法依赖于当前服务的运行时状态,这些状态信息通常包括服务过去一段时间的平均调用时延和所承接的连接数等。
-
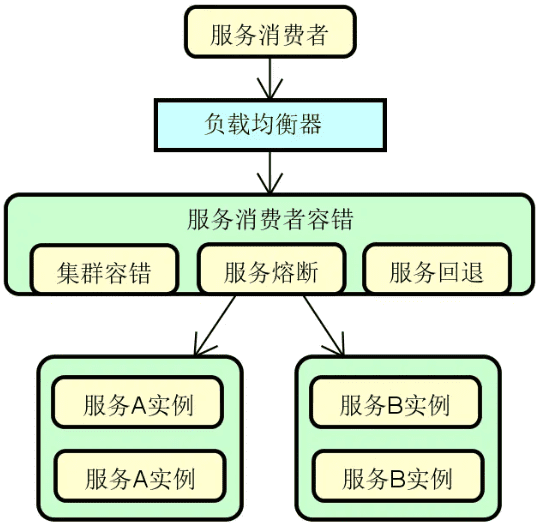
服务容错:在分布式环境中,服务访问出错了该怎么办?这就涉及到服务可靠性问题。服务可靠性是分布式服务构建过程中的一项关键要素,我们需要引入容错思想和机制。常见的服务容错技术包括集群容错、服务熔断(Circuit Breaker)和服务回退(Fallback)等。下图展示的是添加了服务容错机制的系统架构演进过程:
![2024 10 12 10 14 41]()
-
服务降级:从概念上讲,任何一个服务都是可以分等级的。具体的服务分级方法因业务场景和需求而定。一旦我们实现了对服务的针对性分级,那么就可以对那些处于业务链路最外围、等级最低的服务开始执行降级。至于如何对服务进行分级,可以按照需求采取一定的策略,例如常见的三级分类策略,如下图所示:
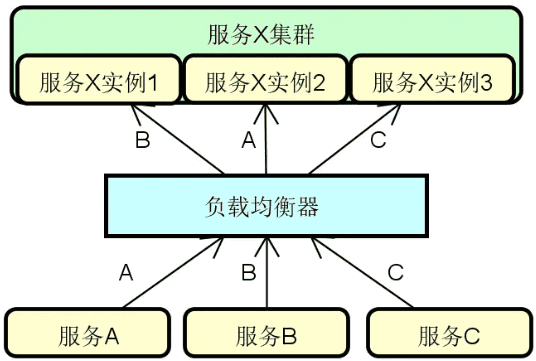
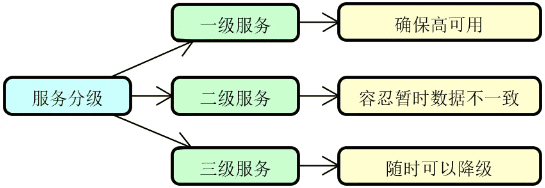
在上图中,一级服务属于核心服务,需要确保高可用,不能执行降级操作;二级服务通常采用的是异步交互方式,容忍暂时的数据不一致性;而三级服务则可以按需对整个服务实行降级操作。
微服务构建组件
在远程过程调用组件的基础上,我们继续讨论微服务构建组件,包括注册中心、服务网关、配置中心、消息通信和链路跟踪。这些组件扩展了分布式技术能力,为构建大规模分布式系统提供了技术保障。
-
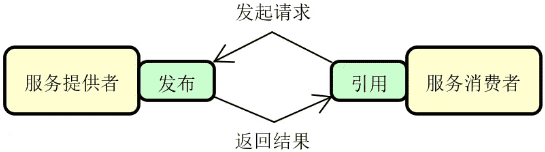
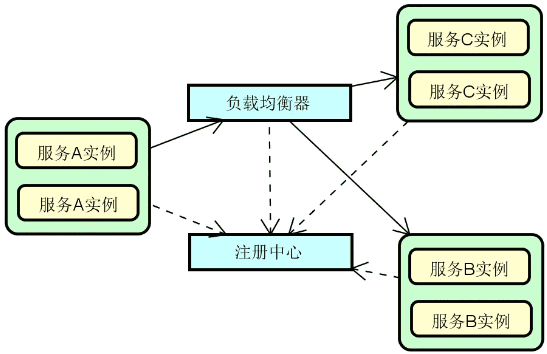
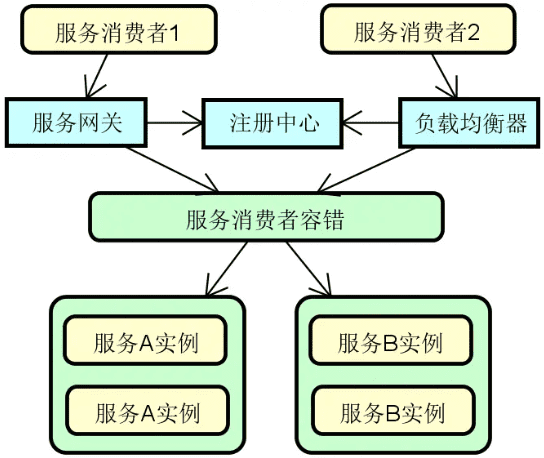
注册中心:在分布式服务构建过程中,服务与服务之间通过远程调用完成业务链路的构建。而在服务调用之前,我们首先需要发现服务,即解决在分布式集群环境下如何找到目标服务实例这一问题。服务发现和调用构成了服务交互的基础,整体流程下图所示,其中实线部分代表服务调用流程,而虚线部分则包含了服务的注册(Registration)和发现(Discovery)过程。
![2024 10 12 10 16 02]()
可以看到,图中的这三个服务都需要注册到注册中心以确保负载均衡器能够从注册中心获取各个服务的定义信息。
-
服务网关:在分布式系统中,API 网关(Gateway)或服务网关(Service Gateway)的出现有其必然性。我们可以根据需要在服务提供者和消费者之间架设这层服务网关。在注册中心和负载均衡的基础上,添加了服务网关之后的系统架构如下图所示:
![2024 10 12 10 16 32]()
当然,并不是所有的服务调用链路上都需要添加这层网关,我们也可以根据具体场景直接通过负载均衡器进行服务访问。在实际应用过程中,这种混合式的服务调用管理方式也是一种常见的做法。
-
配置中心:面对不断增长的服务实例数量,传统的配置信息管理方式就显得无能为力。为此,在分布式服务构建过程中,一般都需要引入配置中心(Configuration Center)的设计思想和相关工具。下图展示了在前面各个组件的基础上添加配置中心之后的系统架构图,分布式系统中的各个服务都可能会依赖配置中心,从而完成配置信息的统一管理。
![2024 10 12 10 17 34]()
-
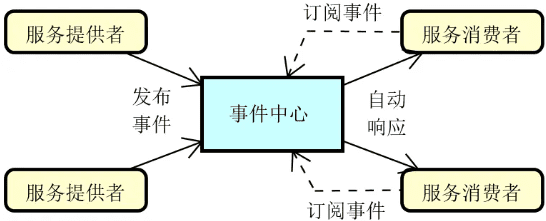
消息通信:降低服务与服务之间的耦合度是分布式系统设计的一大目标,为此,我们可以引入事件驱动架构,基本组成如下图所示:
![2024 10 12 10 18 20]()
基于事件驱动架构,每一个服务既可以作为事件的发布者也可以作为事件的消费者,或者两者兼之。而事件也可以在不同的服务之间进行传播,从而满足各种特定的应用场景。
-
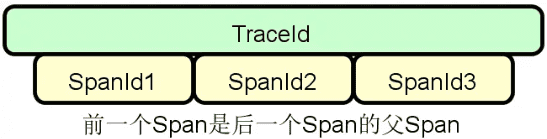
链路跟踪:服务之间的调用不可避免会出现各种问题,这时候就需要引入分布式链路跟踪体系来定位和解决这些问题。基于每一次分布式请求,我们都可以捕获该请求的一系列跟踪数据,下图展示了基于 TraceId 和 SpanId 所构建的一次服务调用的完整链路。
![2024 10 12 10 21 32]()
服务调用链路跟踪是分布式系统的基础需求之一,业界关于分布式链路跟踪也有统一的规范以及代表性的实现框架。
通用技术组件
在分布式服务构建过程中,也需要引入一组通用型的技术组件,这些技术组件在多个场景中(不仅限于分布式系统)都能发挥作用。本课程梳理了五种通用技术组件,包括动态代理、应用缓存、资源管理、框架集成以及架构模式。这种技术组件有些关注于具体某一个技术实现要点,有些则关注于框架的应用以及架构设计的方法和实践。
- 动态代理:在日常开发过程中,动态代理可以说是一种通用性非常高的实现机制,它是面向切面编程的基础,也在主流的分布式服务开源框架中得到了广泛的应用。通过代理机制,一个对象就可以在承接另一个对象功能的同时添加新的功能。相比直接在原有对象中嵌入代码,代理机制为我们提供了更为优雅的解决方案。
- 应用缓存:对于分布式服务而言,缓存应用非常广泛,开发人员可以使用位于应用程序内部的本地缓存,也可以使用位于独立服务器上的分布式缓存。在日常开发中,缓存的应用通常都是分层级的,我们会综合使用多级缓存来提高目标对象访问的效率和性能。
- 资源管理:相信你对线程池、数据库连接池等技术并不陌生。这里的池(Pool)是一种对资源的抽象方法,代表一组可以随时使用的资源,但这些资源的创建和释放过程则基于一定的管理策略。资源池的应用非常广泛,存在多种具体的池化组件。
- 框架集成:这里所说的框架集成,指的是 Dubbo、MyBatis、Spring Cloud 等主流的分布式开发框架与 Spring 框架之间的集成。我们可以基于命名空间以及自定义 starter 等机制完成与 Spring 之间的有效集成。理解框架集成的实现过程有利于掌握主流的分布式服务框架的运行原理。
- 架构模式:架构模式描述某一特定应用领域中系统组织和表现的惯用方式。对软件体系架构模式的研究和实践促进了对软件设计的重用。在分布式系统开发过程中,也大量应用了诸如微内核架构、管道过滤器架构等架构模式,这些模式能够为开发人员提供具有高度扩展性的技术组件。
解题要点
通过对技术体系的系统分析,我们明白了构建一个分布式服务系统所需要的各个技术组件。这里涉及了一大批专用名词。但是,光列举这些名称就够了吗?答案显然是否定的。
我们在解释这些名词时需要做一些扩展,多提及技术组件的关联关系,从而确保回答过程具备较好的逻辑性。这是解答这个问题的第一点思路。例如,我们在介绍注册中心时,需要提到该组件与负载均衡之间的集成关系。
针对该问题的第二点解答思路在于回归现实中的实践。本讲中介绍的技术组件都是很常见和很通用的,一般的分布式系统构建过程中都会使用到。你完全可以基于自己在日常开发过程中的应用情况来对这些组件做一定的展开。因为这是一道偏概念阐述的问题,所以如果能够做到理论联系实际,相信肯定能为你加分不少。
最后,我想强调的第三点是技术判断力,你需要对各个技术组件背后的实现复杂度有一定的认识。对于那些复杂度较高的技术组件,可以更为细化地进行阐述,并在一定程度上显现出自己所具备的设计思想和对实现原理的理解能力,这样就能达到一定的深度。
总结
分布式服务的相关组件虽然比较多,但并不难梳理和串联。正如我们在前面所讨论到的,很多技术组件的出现是必然的,而有些组件之间具备一定的相互关联关系。在本讲内容中,我们从远程调用、微服务以及通用技术组件这三大维度出发来对这些组件进行了分类,并针对每个类别梳理了五大技术组件,以帮助你能够更好地理解和把握,从而形成自己的知识体系。
在掌握了构建分布式服务的技术组件之后,下一讲我们将介绍基于这些组件所构建的分布式服务框架。实际上在本讲内容中,我们已经提到了 Dubbo、Spring Cloud 等框架,目前这些框架都非常主流。那么,这些框架都具备什么样的功能特性呢?
网络通信:如何完成客户端和服务端之间的高效通信?
从本讲开始,我们将进入到远程过程调用类技术组件的讨论,首先要讨论的是网络通信。
分布式系统的构建依赖网络通信。相比单块系统的函数式调用,分布式环境下的请求和响应过程涉及到客户端和服务器端之间跨网络的交互和协作。这个过程一方面要考虑到网络的三态性,另一方面也需要考虑资源的利用效率。
那么,如何设计并实现高效的网络通信机制?这是分布式服务框架的核心功能之一,也是我们在面试过程中经常会碰到的一个面试题。本讲内容将围绕这一问题展开讨论。
背景
在日常开发过程中,每一次分布式请求都会涉及到网络通信。网络通信表现为一个复杂且不可控的过程。然而,因为像 Dubbo、Spring Cloud 等主流的分布式服务框架都已经帮我们封装了网络通信过程,使得远程过程调用就像是在使用本地方法调用一样,导致了开发人员对网络通信过程的底层设计思想和实现原理往往不甚了解。
另一方面,对于分布式服务构建过程而言,网络通信是一个基础性、通用性的技术主题,涉及广泛的技术体系,既有深度又有广度,非常适合考查候选人的知识面。因此。网络通信在面试过程中出现的频率可以说非常高。作为面试官,我也经常会对候选人提出关于该主题的一些问题。
从面试角度讲,关于网络通信有很多种具体的问法,有些侧重于具体某一个知识点,有些则关注整个通信流程。当然,因为日常开发中大家都是使用一些开源框架来开发分布式系统,因此关于开源框架中网络通信具体实现过程和底层原理也是常见的考查方式。
这里我梳理了比较有代表性的一些面试话题,如下所示:
- 网络的长连接和短连接分别指什么?它们分别有什么特点和优势?
- 常见网络 IO 模型有哪些?各有什么功能特性?
- 如果确保网络通信过程的可靠性?
- 你认为网络通信包含的核心技术组件有哪些?
- 如果让你来设计网络传输协议,你有什么样的一些思考?
- 你能描述 Dubbo 框架中客户端和服务器端的网络通信实现过程吗?
- Dubbo 框架对网络通信过程采用了什么样的分层设计思想?
分析
网络通信的实现方式实际上有很多种,但因为网络通信过程复杂且不可控,因此如何使这个过程的代价降到用户可以接受的层次是分布式系统设计的重要目标。
我们知道客户端和服务器端之间需要完成跨网络的交互过程,也就意味着两者之间需要建立网络连接。网络连接的创建和维护方式决定了通信过程的效率。同时,我们知道任何网络请求的处理过程都涉及到 IO 操作,而不同类似的 IO 操作方式对性能的影响巨大。在网络通信过程中,我们需要选择合适的 IO 模型。
关于网络通信,可靠性是一个不得不提的话题。网络状态是不稳定的,网络之间的通信过程必须在发生问题时能够快速感知并修复。
我们把上述分析点整理成一张图,如下所示:
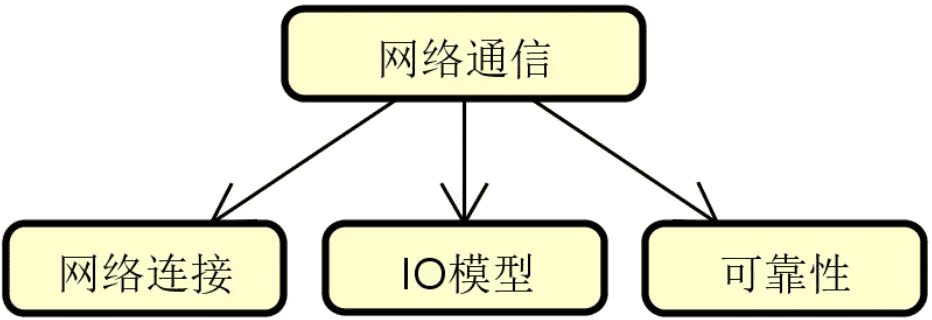
上图构成了我们回答这类面试题的基本思路。
技术体系
在本节内容中,让我们来对上图中所展示的各项技术体系展开讨论。
网络连接
关于网络连接,我们要讨论的主要是长连接和短连接的概念。当客户端在向服务端发送请求并获取响应结果之后,这两种连接方式的区别在于对连接本身的处理方式。
所谓短连接,是指一旦请求响应过程结束,连接自动关闭。而长连接则不同,客户端可以利用这个连接持续地发送请求并获取响应结果。显然,采用何种连接方式没有统一的标准,而是要看具体的应用场景。有时候,考虑到性能和服务治理等因素,我们也会把短连接和长连接组合起来使用。
IO 模型
任何网络请求处理过程都涉及到 IO 操作。
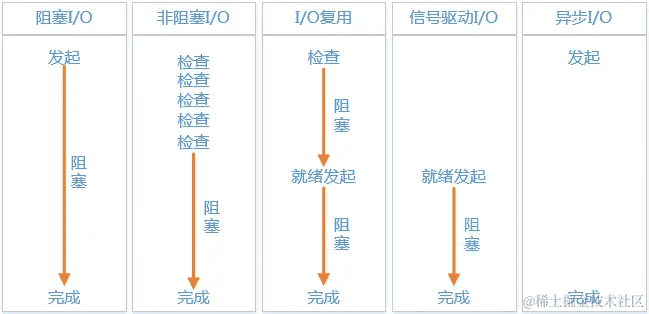
最基本的 IO 操作模型就是阻塞式 IO(Blocking IO,BIO),该模型要求服务器端针对每次客户端请求都生成一个处理线程,因此对服务器端的资源消耗要求很高。
非阻塞 IO(Non-Blocking IO,NIO)和 IO 复用(IO Multiplexing)技术实际上也会在 IO 上形成阻塞,真正在 IO 上没有形成阻塞的是异步 IO(Asynchronous,AIO)。
各个 IO 模型效果如下图所示:
可靠性
因为网络状态是不稳定的,所以业界诞生了一系列手段来确保网络通信的可靠性。
首先,我们需要对网络的通信链路进行有效性的检测,这方面最常见的实现机制就是心跳检测。我们可以在网络协议的 TCP 层发送心跳包,也可以在应用层协议上传递包含一定业务数据的心跳信息。
另一方面,一旦检测到网络通信出现问题,那么就需要采取一定措施来恢复网络状态。这方面主流的做法就是断线重连。针对不同场景,我们可以采用不同的重连次数和频率,直到网络重连成功或者超时。
讲到这里,我们需要注意,上述关于网络通信相关技术体系的讨论都是相对抽象的内容。在具体面试过程中,如果只是简单给出这些概念性的描述,显然无法满足面试官的要求。要想充分展示候选人对网络通信的掌握程度,就需要依托一定的开源框架。只有通过这些开源框架,我们才能了解网络通信的底层原理。
在接下来的内容中,我们将基于目前主流的分布式服务框架 Dubbo 来分析该框架针对网络通信采用了什么样的设计思想和实现过程。
源码解析
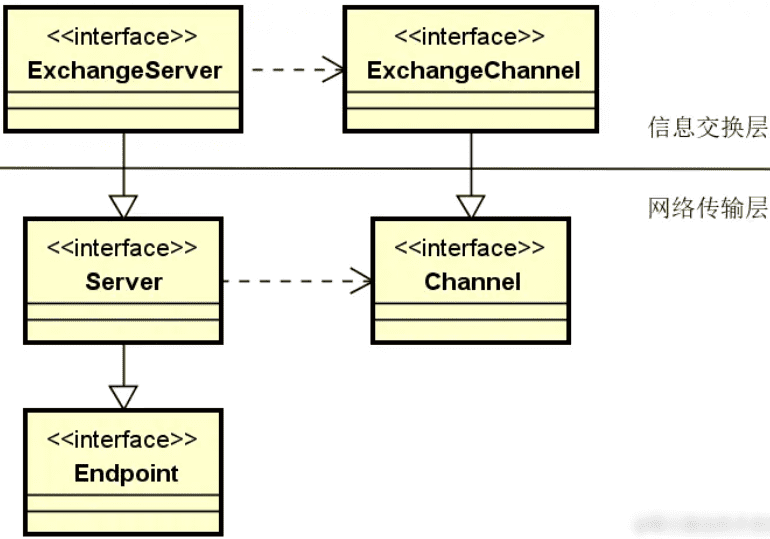
在 Dubbo 框架中,存在一个独立的 Remoting 模块,封装了对整个网络通信的实现过程,该模块的组成结构如下图所示:

从组成结构上讲,Remoting 模块主要包含三个组件。
- Exchange 组件。信息交换层,用来封装请求-响应过程。
- Transport 组件。网络传输层,基于 Netty 等框架抽象统一的网络通信接口。
- Serialize 组件。序列化层,主要完成数据的序列化和反序列化过程。
而从技术分层上讲,Remoting 模块处于整个 Dubbo 框架的底层,是我们后续要介绍的服务发布和服务消费的基础。显然,Remoting 模块的组件呈现的是一种对称结构,即 Dubbo 的生产者和消费者都依赖于底层的网络通信。所以,我们也将分别从服务器端和客户端两个角度出发分析 Dubbo 中具体的网络通信过程。
然后,在 Dubbo 中,真正实现网络通信的过程委托给了第三方组件。Dubbo 通过 SPI 的方式提供了与 Netty、Mina 等多种通信框架的集成方式。这部分内容相当于是对上图中 Remoting 模块的补充,从层次上讲应该属于 Dubbo 框架的最底层。
Dubbo 服务器端通信原理
我们首先介绍 Dubbo 服务器端的网络通信过程。请记住,Dubbo 中服务器端通信的目的就是集成并绑定 Netty 服务从而启动服务监听。我们关注 Exchange 信息交换层和 Transport 网络传输层这两个核心层之间的交互和协作过程,如下图所示:
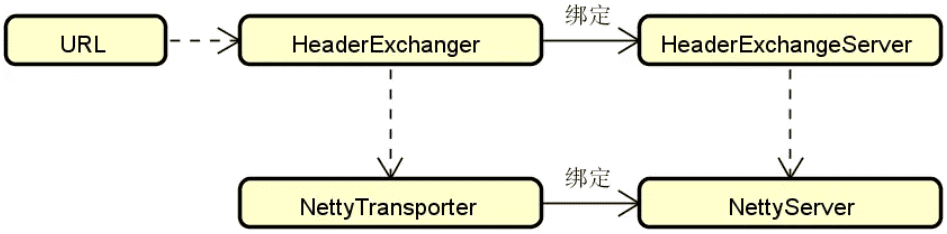
上图中涉及了 ExchangeServer、HeaderExchange、NettyTransport 和 NettyServer 等一系列核心对象。显然,通过这些对象从命名上就可以很明确地将它们划分到 Exchange 和 Transport 这两个层。
在 Dubbo 中存在一个 Protocol 接口,该接口是 Dubbo 中最基本的远程过程调用实现接口,完成了服务的发布和调用功能。而在 Protocol 接口中存在 export 和 refer 这两个核心方法,其中前者用于对外暴露服务,后者则用来对远程服务进行引用。针对 Protocol 接口,Dubbo 提供了一组实现类,其中最重要的就是 DubboProtocol。
我们从 DubboProtocol 中的 export 方法进行切入,该方法会根据传入的 URL 对象创建一个 Exchange 服务器,如下所示:
private void openServer(URL url) {
String key = url.getAddress();
boolean isServer = url.getParameter(Constants.IS_SERVER_KEY, true);
if (isServer) {
ExchangeServer server = serverMap.get(key);
if (server == null) {
serverMap.put(key, createServer(url));
} else {
server.reset(url);
}
}
}我们来看 Exchange 服务器的创建过程,对应的 createServer 方法如下所示:
private ExchangeServer createServer(URL url) {
// 省略其他代码
ExchangeServer server;
try {
server = Exchangers.bind(url, requestHandler);
}
return server;
}可以看到这里的关键代码就是通过 Exchangers 的 bind 方法创建了 ExchangeServer,这个过程依赖于一个 Exchanger 接口。那么这个 Exchanger 接口是做什么用的呢?该接口定义如下所示:
@SPI(HeaderExchanger.NAME)
public interface Exchanger {
@Adaptive({Constants.EXCHANGER_KEY})
ExchangeServer bind(URL url, ExchangeHandler handler) throws RemotingException;
@Adaptive({Constants.EXCHANGER_KEY})
ExchangeClient connect(URL url, ExchangeHandler handler) throws RemotingException;
}Exchanger 接口只有两个方法,一个是面向服务器端的 bind 方法,一个是面向客户端的 connect 方法。在 Dubbo 中,Exchanger 的实现类只有一个,即 HeaderExchanger,如下所示:
public class HeaderExchanger implements Exchanger {
public static final String NAME = "header";
public ExchangeClient connect(URL url, ExchangeHandler handler) throws RemotingException {
return new HeaderExchangeClient(Transporters.connect(url, new DecodeHandler(new HeaderExchangeHandler(handler))), true);
}
public ExchangeServer bind(URL url, ExchangeHandler handler) throws RemotingException {
return new HeaderExchangeServer(Transporters.bind(url, new DecodeHandler(new HeaderExchangeHandler(handler))));
}
}请注意,上述 HeaderExchanger 在创建 HeaderExchangeServer 的同时也加入心跳检测功能,如下所示:
private void startHeatbeatTimer() {
stopHeartbeatTimer();
if (heartbeat > 0) {
heatbeatTimer = scheduled.scheduleWithFixedDelay(
new HeartBeatTask(new HeartBeatTask.ChannelProvider() {
public Collection<Channel> getChannels() {
return Collections.unmodifiableCollection(
HeaderExchangeServer.this.getChannels());
}
}, heartbeat, heartbeatTimeout),
heartbeat, heartbeat, TimeUnit.MILLISECONDS);
}
}在 HeartBeatTask 的 run 方法中,我们根据所配置的 heartbeat、heartbeatTimeout 等相关心跳属性,执行 channel.reconnect、channel.close 等方法。这也是心跳检测机制的一种常见实现方式。
注意到,我们在 HeaderExchangeServer 中终于看到了属于 Transport 层的对象 Transporters,接下来我们来看服务器端 Transport 相关的组件。
站在服务器的角度,网络通信过程的目的只有一个,就是装配服务并启动监听,从而接收来自服务消费者的访问。而对于服务消费者而言,通信过程的目的无非是对远程服务进行连接、发送请求并获取响应。因此,在 Dubbo 中存在一个 Transporter 接口,该接口提供了 bind 和 connect 方法分别对这两个基本操作进行封装,如下所示:
@SPI("netty")
public interface Transporter {
@Adaptive({Constants.SERVER_KEY, Constants.TRANSPORTER_KEY})
Server bind(URL url, ChannelHandler handler) throws RemotingException;
@Adaptive({Constants.CLIENT_KEY, Constants.TRANSPORTER_KEY})
Client connect(URL url, ChannelHandler handler) throws RemotingException;
}我们发现 Transporter 接口的定义与 Exchanger 接口非常类似,两者同时提供了 bind 和 connect 这两个方法。区别在于 Exchanger 中用到的 ExchangeHandler,而 Transporter 中用到的是 ChannelHandler,显然 ChannelHandler 面向消息通信的通道,提供了比 ExchangeHandler 更底层的操作语义。
与 HeaderExchanger 不同,Dubbo 中针对 Transporter 接口提供了一批实现类,包括 GrizzlyTransporter、MinaTransporter 以及两个 NettyTransporter。系统默认会加载 org.apache.dubbo.remoting.transport.netty 包下的 NettyTransporter,该类如下所示:
public class NettyTransporter implements Transporter {
public static final String NAME = "netty4";
public Server bind(URL url, ChannelHandler listener) throws RemotingException {
return new NettyServer(url, listener);
}
public Client connect(URL url, ChannelHandler listener) throws RemotingException {
return new NettyClient(url, listener);
}
}这里看到了真正实现网络通信的 NettyServer 类,NettyServer 实现了 Server 接口并扩展了 AbstractServer 类。在 AbstractServer 中,Dubbo 提供了对网络服务端的通用抽象,即抽象出 open、close、send 等一组面向网络通信的通用方法。而 NettyServer 作为 AbstractServer 的子类,它的启动监听实现代码如下所示:
protected void doOpen() throws Throwable {
...
bootstrap = new ServerBootstrap(channelFactory);
final NettyHandler nettyHandler = new NettyHandler(getUrl(), this);
channels = nettyHandler.getChannels();
bootstrap.setOption("child.tcpNoDelay", true);
bootstrap.setPipelineFactory(new ChannelPipelineFactory() {
public ChannelPipeline getPipeline() {
NettyCodecAdapter adapter = new NettyCodecAdapter(getCodec(), getUrl(), NettyServer.this);
ChannelPipeline pipeline = Channels.pipeline();
pipeline.addLast("decoder", adapter.getDecoder());
pipeline.addLast("encoder", adapter.getEncoder());
pipeline.addLast("handler", nettyHandler);
return pipeline;
}
});
channel = bootstrap.bind(getBindAddress());
}熟悉 Netty 框架的开发人员对上述代码一定不会陌生,这里使用 Netty 的 ServerBootstrap 完成服务启动监听,同时构建了 NettyHandler 作为其网络事件的处理器。然后 NettyServer 的 doClose 方法基于 Netty 的 boostrap 和 channel 对象完成了网络资源释放。
这样我们对 Dubbo 中与网络通信相关的服务监听启动和关闭,以及发送消息的过程就有了整体的了解。
Dubbo 客户端通信原理
有了对前面服务器端各个技术组件的介绍,理解 Dubbo 客户端通信原理就会容易很多。我们在介绍服务器端时所引入的 Transporter 接口同时包含了对客户端方法的定义,而 Transporter 的实现类 NettyTransporter 也同时提供了 NettyClient 类,如下所示:
public class NettyTransporter implements Transporter {
public static final String NAME = "netty";
public Server bind(URL url, ChannelHandler listener) throws RemotingException {
return new NettyServer(url, listener);
}
public Client connect(URL url, ChannelHandler listener) throws RemotingException {
return new NettyClient(url, listener);
}
}与 NettyTransporter 相关的这些核心类之间的关系下图所示:
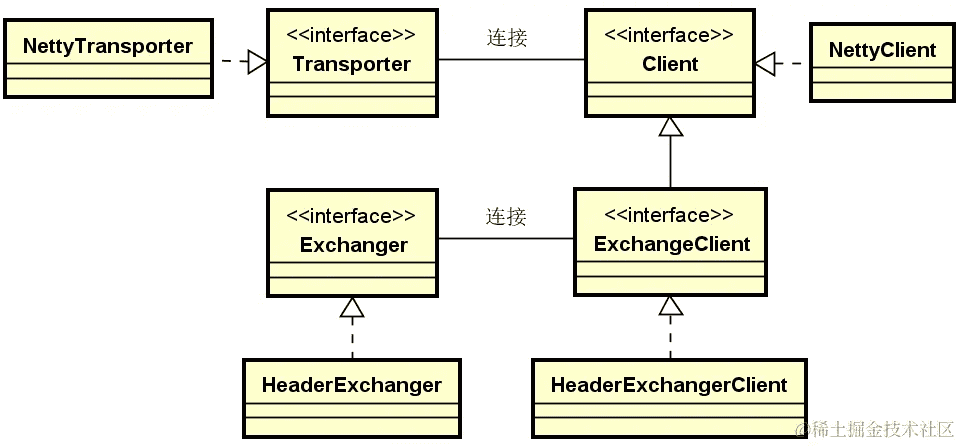
上图中的很多类我们都已经明确了,因此在介绍 Dubbo 的客户端通信原理时,不会像服务端那样做全面展开,而是更多关注于客户端本身的特性,所以我们的思路先从底层的 NettyClient 类进行切入。
与 NettyServer 类类似,NettyClient 也存在一个抽象的父类 AbstractClient。作为网络客户端的通用抽象,AbstractClient 这个模板类一共提供了 doOpen、doConnect、doDisconnect、doClose、getChannel 这 5 个模板方法。与服务器端所提供的 3 个方法相比,客户端还需要实现与 Connect 这一操作相关的两个方法。
NettyClient 中的 doOpen 方法如下所示,这里创建了 ClientBootstrap 并完成初始化参数设置。
@Override
protected void doOpen() throws Throwable {
...
bootstrap = new ClientBootstrap(channelFactory);
final NettyHandler nettyHandler = new NettyHandler(getUrl(), this);
bootstrap.setPipelineFactory(new ChannelPipelineFactory() {
public ChannelPipeline getPipeline() {
NettyCodecAdapter adapter = new NettyCodecAdapter(getCodec(), getUrl(), NettyClient.this);
ChannelPipeline pipeline = Channels.pipeline();
pipeline.addLast("decoder", adapter.getDecoder());
pipeline.addLast("encoder", adapter.getEncoder());
pipeline.addLast("handler", nettyHandler);
return pipeline;
}
});
}和 NettyServer 一样,NettyClient 同样完成了对 Netty 框架的封装。在 NettyClient 的 doConnect 方法中,同样使用 ClientBootstrap 完成与服务端的连接和事件监听。而 doDisconnect 方法则用于移除当前已经断开连接的 Channel。然后,和 HeaderExchangeServer 类类似,在 HeaderExchangeClient 类中也添加了定时心跳收发及心跳超时监测机制。
解题要点
对于远程过程调用而言,网络通信还是一个偏向于概念的技术考点。因此,在回答这类问题时,第一步需要针对网络通信这个话题本身给出一些说明和描述,这属于理论知识体系,是需要死记硬背的基础内容。基于对这一话题的了解,通常我们就可以引出一些自己比较熟悉的点,围绕这些点来进行展开和引导即可。例如,对于网络传输协议,如果你了解 ISO/OSI 模型,那就可以基于这个模型来对类似“消息头”这种自己比较熟悉的点进行发散。
第二个解题要点是对网络通信实现过程进行抽象化、系统化的阐述。在目前主流的分布式服务框架中,对于网络通信模块都会有自己的一些抽象和提炼,其内部结构往往比较复杂。以本讲中介绍的 Dubbo 框架为例,就采用了明确的分层架构。每一层中都包含了一些核心的接口,这些接口之间的继承关系以及所处于的层次如下图所示:
针对网络通信,我们要明确 Dubbo 框架集成了很多第三方工具,这部分工具只关注于底层的具体网络通信过程。Dubbo 把这一过程抽象成一个 Transport 层,即网络传输层。而 Dubbo 又提供了一个 Exchange 层,用于封装请求和响应,称为信息交换层。从功能职责上讲,Exchange 偏向于 Dubbo 对自身通信过程的抽象和封装,跟具体的网络通信关系不大,具体的网络传输工作都是由 Transport 层负责完成。理解 Dubbo 框架的这种设计思想和实现方式,一方面有助于提升面试内容的丰富程度,另一方面对于更好地理解框架实现原理也很有帮助。
在面试过程中,我们需要确保整个针对网络通信的分析过程是理论结合实践的,如果你能够把本讲内容结合起来进行讲解,相信这道面试题会成为你区别于其他候选人的一个亮点。
小结与预告
本讲介绍了分布式系统远程过程调用部分的第一个技术组件,即网络通信。可以说网络通信是一切分布式系统的基础,我们从网络连接、IO 模型等角度讨论了与网络通信相关的一些基本概念。
本讲的核心内容是对 Dubbo 中网络通信具体实现过程的深入分析,我们从源码级别对框架中的核心类进行了展开,并明确了 Dubbo 框架在实现网络通信模块时所采用的分层架构。Dubbo 在这一维度上的分层架构为我们如何合理规划底层模块的职责和边界提供了很好的参考价值。Dubbo 中关于服务器端和客户端通信的实现过程还是比较复杂的,涉及到更底层的 Channel 等相关的操作,大家可以自己通过阅读源码进行理解。
在本讲内容中,我们还留着一个伏笔,那就是序列化。任何一次网络请求过程都涉及到对数据的序列化操作。而序列化的具体实现工具很多,但这些工具背后实际上还是有一些通用的功能特性值得进行分析和总结,从而方便我们做出技术选型。下一讲我们将针对这个话题展开详细讨论。
序列化:如何对序列化实现工具进行正确选型?
在上一讲中,我们对远程过程调用中客户端与服务器端的网络通信过程进行了详细的讨论。借助于分布式服务框架,我们可以实现不同服务之间跨网络的交互和协作。网络通信涉及到数据的有效传输,这就需要引入另一个技术组件,即序列化。而目前关于如何实现序列化和反序列化,业界也诞生了一大批工具和框架。
那么,序列化是一种什么样的技术组件?我们又应该如何对种类繁多的序列化实现工具进行正确选型呢?这是面试官经常会抛出的一个面试话题。本讲内容将围绕这一话题展开讨论。
问题背景
在现实中,我们通常会使用 Dubbo、Spring Cloud 等开源框架,以及 TCP、HTTP 等网络传输协议来发起远程调用。对于这些框架和协议而言,客户端发起请求的方式,以及服务端返回响应结果的处理过程都是不一样的。但是这里存在一个共同点,即无论采用何种开发框架和网络传输协议,都涉及到业务数据在网络中的传输,这就需要应用到序列化技术。和上一讲介绍到的网络通信不同,序列化技术是直接面向开发人员的,我们可以对具体的序列化工具和框架进行选择,而不像网络通信过程那样只能依靠框架底层所封装的能力。对于序列化技术而言,这种差异性导致了面试过程不仅仅只会考查对技术本身的了解程度,而是更多会讨论如何对序列化工具进行合理选择。
目前,序列化工具很多,据统计已经不下 100 种。在面试过程中显然无法对具体的实现工具进行一一罗列。因此,关于序列化技术的考查方式是比较灵活的,需要候选人有足够的知识面,了解目前业界主流的序列化技术。更为重要的,候选人还需要具备综合的抽象思维,能够将不同的工具按照一定的维度进行分类,从不同的功能特性角度出发进行分析。
从面试角度讲,关于序列化技术的常见考查方式包括:
- 你知道哪些序列化工具,它们各自有什么特性?
- 你在选择序列化工具时,重点会考虑哪些方面的要素?
- 为什么像 Protobuf、Thrift 这些序列化工具会采用中间语言技术?
- 如果只考虑性能,你会选择哪款序列化工具?
- Google 的 Protobuf 为什么会那么快?
可以看到,这些面试题既包括对序列化技术原理和实现方法的考查,也会涉及到具体某一个工具框架的细节。从我的面试经验而言,能够回答比较顺畅的候选人并不是很多,需要大家在平时的工作中不断积累。
问题分析
究竟什么是序列化?我们可以简单把它理解为是一种从内存对象到字节数据的转换过程。通过序列化,我们就可以把数据变成可以在网络上进行传输的一种媒介,如下图所示:
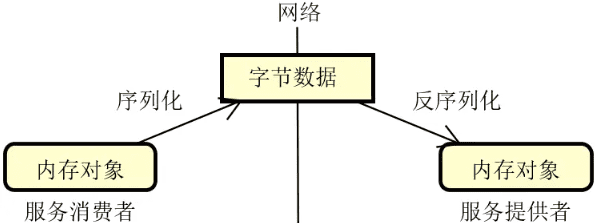
在上图中,我们注意到还有一个反序列化的概念。所谓反序列化,实际上就是序列化的逆向过程,把从网络上获取的字节数据再次转化为可以供内存使用的业务对象。
序列化的方式有很多,实现工具也非常丰富,常见的如下表所示:
| 序列化工具 | 简要描述 |
|---|---|
| Java Serializable | JDK 自带序列化工具 |
| Hessian | Dubbo 框架默认序列化工具 |
| Protobuf | gRPC 框架默认序列化工具 |
| Thrift | Facebook 跨语言序列化工具 |
| Jackson | Spring 框架默认序列化工具 |
| FastJson | 阿里巴巴高性能序列化工具 |
上表罗列的也只是一些最主流的序列化工具,其他可供开发人员使用的工具和框架还有很多。虽然这些工具的定位和作用是类似的,但所具备的特性却不尽相同。这就涉及到日常开发过程中开发人员经常要面对的一个问题,即技术选型问题。
关于技术选型,我们的思路首先是确定所需要考虑的技术维度。在序列化领域,我们可以抽象出三个技术维度。
- 功能:包括支持的序列化数据表现形式、数据结构等。
- 性能:包括空间复杂度和时间复杂度等。
- 兼容性:包括版本号机制等。
基于上述三个技术维度,我们回答这类面试题的思路就有了。而从这三个技术维度的描述出发,我们也不难看出每一个技术维度还可以继续进行细分,接下来,让我们来对具体的技术体系展开讨论。
技术体系
序列化工具和框架各有特色,但它们所采用的数据表现形式一般分成两大类,即具备可读性的文本类,以及不具备可读性的二进制类。对于前者,代表性的框架有 Jackson 和 FastJson,它们都采用了 JSON 作为数据表现形式。而后者则包括 Protobuf、Thrift 等。开发人员往往对序列化工具的数据表现形式比较在意,因为这直接决定了我们是否可以直接人为对数据的正确性进行判断。显然,数据的表现形式是序列化工具的一大功能特性,但并不是最重要的功能特性。接下来,就让我们先从序列化的核心功能开始展开讨论。
序列化的功能
在选择序列化工具时,功能完整度是我们首先要考虑的一个技术维度,具体的关注点包括:
- 数据结构的丰富程度;
- 开发的友好性;
- 对异构平台的支持性。
我们首先来看数据结构,这方面的功能差异性主要体现在是否对一些复杂数据结构的支持。常见的复杂数据结构包括泛型结构以及 Map/List 等集合结构。我们来看如下所示的一个具体的示例:
public class User {
public int id;
public String username;
public List<Link> links;
public Map result;
}
public class Link {
public String name;
public String phone;
}可以看到,这里定义了一个 User 对象,而这个 User 对象中又分别包含了一个 List 结构和一个 Map 结构,其中 List 结构所指向的还是一组自定义对象 Link。针对这种复杂数据结构,如果我们使用 FastJson 来进行序列化,那么如下所示的代码是可以正常运作的。
User user = new User();
// 省略对 user 对象进行赋值
// 将对象转化为 JSON 字符串
String str = JSON.toJSONString(user);
// 将 JSON 字符串转成对象
User myuser = JSON.parseObject(str, User.class);而如果我们使用 Protobuf,那么这种复杂数据结构是无法支持的。如果想要使用 Protobuf,需要对这个数据结构进行调整,将 List 换成更为通用的数据结构。另一方面,针对 Protobuf 框架,我们也可以引出下一个我们要讨论的功能点,即开发的友好性。
开发友好性用来衡量工具本身对于开发人员实现序列化的开发难易程度。就像前面示例所展示的,我们在使用 FastJson 时,通过几行代码就能实现对象的序列化和反序列化。而有些工具则不一定,以 Protobuf 为例,在使用该工具时,我们首先要做的是定义一种中间语言,示例如下:
syntax = "proto3";
message Student
{
int32 id= 1;
string name = 2;
int32 sex = 3;
string hobby = 4;
string skill = 5;
}这里的 syntax="proto3" 表示运用 proto3 版本的语法,而 message 类似于 Java 中的 Class。在开发过程中,我们需要将这段中间语言保存为一个 student.proto 文件,然后再通过 Protobuf 的 protoc 命令将它转化为 Java 文件才能使用,如下所示:
protoc --java_out=. student.proto可以看到,中间语言所带来的开发复杂度是显而易见的。使用中间语言的典型工具还包括 Thrift,它需要事先提供一个 .thrift 文件。
讲到这里,你可能会问,为什么 Protobuf 和 Thrift 要使用中间语言呢?原因就在于它们基于中间语言提供了一项重要的技术特性,即跨语言的异构性。
异构性的需求来自分布式系统中技术架构和实现方式的多样性。原则上,每个服务都可以基于不同的技术体系进行实现,这些技术体系所采用的开发语言可能都是不一样的,这时候就需要引入支持多语言的序列化工具,如下图所示:
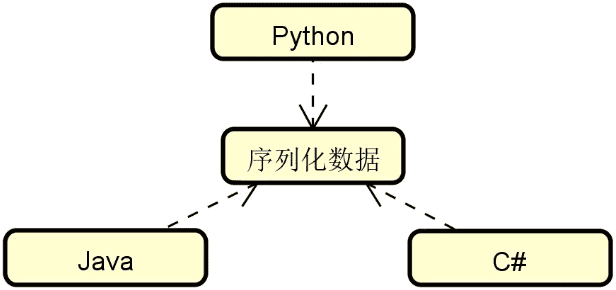
实际上,很多场景下我们之所以不选择 JDK 自带的序列化机制,很重要的一个原因就在于它只能支持 Java 语言。而基于 Protobuf 等工具所提供的中间语言机制,我们可以生成面向不同语言的序列化数据,包括 C++、JAVA、Python、Objective C、C#、Ruby、PHP、JavaScript 等,我们也可以找到几乎涵盖所有其他语言的第三方拓展包。
另一方面,无论是数据结构的丰富程度,还是开发友好性,这些功能特性与跨语言支持之间往往是存在一定矛盾的。举个例子,要想支持多语言,那么就必须采用那些非常通用的数据结构,确保所有语言都内置了对这些数据结构的支持。这样的话,诸如前面提到的 Map/List 等复杂数据结构显然就不合适了。
序列化的性能
在日常开发过程中,我们在选择序列化工具时往往会把性能作为一项重要的指标进行考虑。对于序列化的性能而言,我们关注两个指标,即:
- 时间复杂度:表示序列化/反序列化执行过程的速度。
- 空间复杂度:表示序列化数据所占有的字节大小。
对于日常开发过程中经常使用的一些序列化工具,我们可以列举了它们在性能上的一些量化数据,如下表所示:
| 时间复杂度(序列化) | 时间复杂度(反序列化) | 空间复杂度 | |
|---|---|---|---|
| Java | 8654 | 43787 | 889 |
| Hessian | 6725 | 10460 | 501 |
| Protobuf | 2964 | 1745 | 239 |
| Thrift | 3177 | 1949 | 349 |
| Jackson | 3052 | 4161 | 503 |
| Fastjson | 2595 | 1472 | 468 |
通过对比,我们注意到在时间复杂度上可以优先选择阿里巴巴的 FastJson,而在空间复杂度上 Google 的 Protobuf 则具备较大的优势。
序列化的兼容性
关于序列化技术最后需要讨论的一个话题是兼容性。
我们知道随着业务系统的不断演进,服务中所定义的接口以及数据结构也不可避免会发生变化。通常,在分布式服务开发过程中,我们会引入版本概念来应对接口和数据结构的调整。在序列化工具中,我们同样需要考虑版本。这方面比较典型的例子就是 JDK 自带的序列化版本 Id。一旦我们在类定义中实现了 Serializable 接口,JDK 就提示你需要指定一个序列化版本 Id,如下所示:
public class MyObject implements Serializable {
// 唯一的序列化版本号
private static final long serialVersionUID = -1127800498182345096L;
}基于这种显式的版本号机制,在序列化时,如果对象之间的版本 Id 不一致,那么 JVM 就会抛出一个 InvalidCastException 的异常;反之则可以正常进行转换。
有些序列化工具虽然没有明确指定版本号的概念,但也能实现前向兼容性,比较典型的就是 Protobuf。
源码解析
介绍完序列化的相关技术体系,让我们再次回到具体的分布式开源框架,来看看业界主流的框架是如何实现序列化过程的。这里还是以阿里巴巴的 Dubbo 框架为例展开讨论。
在上一讲中,我们介绍了 Dubbo 框架中的 Remoting 模块。作为回顾,我们给出该模块的组成结构图,如下图所示:

可以看到,在 Remoting 模块中还剩下一个 Serialize 组件没有介绍,从命名上我们不难看出该组件与序列化相关。事实上,Dubbo 提供了 Serialization 接口(位于 dubbo-common 代码工程中)作为对序列化的抽象。而对应的序列化和反序列化操作的返回值分别是 ObjectOutput 和 ObjectInput,其中 ObjectInput 扩展自 DataInput,用于读取对象;而 ObjectOutput 扩展自 DataOutput,用于写入对象,这两个接口的定义如下所示:
public interface ObjectInput extends DataInput {
Object readObject() throws IOException, ClassNotFoundException;
<T> T readObject(Class<T> cls) throws IOException, ClassNotFoundException;
<T> T readObject(Class<T> cls, Type type) throws IOException, ClassNotFoundException;
}
public interface ObjectOutput extends DataOutput {
void writeObject(Object obj) throws IOException;
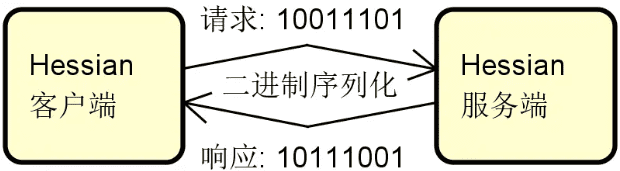
}在 Serialization 接口的定义上,可以看到 Dubbo 中默认使用的序列化实现方案基于 hessian2。Hessian 是一款优秀的序列化工具。在功能上,它支持基于二级制的数据表示形式,从而能够提供跨语言支持;在性能上,无论时间复杂度还是空间复杂度也比 Java 序列化高效很多,如下图所示:
在 Dubbo 中,Hessian2Serialization 类实现了 Serialization 接口,我们就以该类为例介绍 Dubbo 中具体的序列化/反序列化实现方法。Hessian2Serialization 类定义如下所示:
public class Hessian2Serialization implements Serialization {
public static final byte ID = 2;
public byte getContentTypeId() {
return ID;
}
public String getContentType() {
return "x-application/hessian2";
}
public ObjectOutput serialize(URL url, OutputStream out) throws IOException {
return new Hessian2ObjectOutput(out);
}
public ObjectInput deserialize(URL url, InputStream is) throws IOException {
return new Hessian2ObjectInput(is);
}
}Hessian2Serialization 中的 serialize 和 deserialize 方法分别创建了 Hessian2ObjectOutput 和 Hessian2ObjectInput 类。以 Hessian2ObjectInput 为例,该类使用 Hessian2Input 完成具体的反序列化操作,如下所示:
public class Hessian2ObjectInput implements ObjectInput {
private final Hessian2Input mH2i;
public Hessian2ObjectInput(InputStream is) {
mH2i = new Hessian2Input(is);
mH2i.setSerializerFactory(Hessian2SerializerFactory.SERIALIZER_FACTORY);
}
// 省略各种读取具体数据类型的工具方法
public Object readObject() throws IOException {
return mH2i.readObject();
}
public <T> T readObject(Class<T> cls) throws IOException,
ClassNotFoundException {
return (T) mH2i.readObject(cls);
}
public <T> T readObject(Class<T> cls, Type type) throws IOException, ClassNotFoundException {
return readObject(cls);
}
}Hessian2Input 是 Hessian2 的实现库 com.caucho.hessian 中的工具类,初始化时需要设置一个 SerializerFactory,所以我们在这里还看到存在一个 Hessian2SerializerFactory 工厂类,专门用于设置 SerializerFactory。而在 Hessian2ObjectInput 中,各种以 read 为前缀的方法实际上都是对 Hessian2Input 中相应方法的封装。
用于执行反序列化的 Hessian2ObjectOutput 与 Hessian2ObjectInput 类也比较简单,这里不再展开。
关于 Dubbo 序列化的另一条代码支线是 Codec2 接口,该接口位于 dubbo-remoting-api 代码工程中,提供了对网络编解码的抽象,而编解码过程显然需要依赖 Serialization 接口作为其数据序列化的手段。我们可以通过如下所示的代码片段来回顾这一点,这段代码来自 DubboCodec 中的 decodeBody 方法。
public class DubboCodec extends ExchangeCodec implements Codec2 {
protected Object decodeBody(Channel channel, InputStream is, byte[] header) throws IOException {
// 获取序列化对象
Serialization s = CodecSupport.getSerialization(channel.getUrl(), proto);
}
}那么,这里的 Codec 和 Serialization 如何与上一讲中介绍的 Exchange 和 Transport 结合起来构成一个完整的链路呢?我们可以明确一点,序列化和编解码过程在网络传输层和信息交换层中都应该存在。因此,我们快速来到 dubbo-remoting-api 代码工程的 META-INF/dubbo/internal 文件夹,发现存在一个 org.apache.dubbo.remoting.Codec2 配置文件,内容如下所示:
transport=org.apache.dubbo.remoting.transport.codec.TransportCodec
telnet=org.apache.dubbo.remoting.telnet.codec.TelnetCodec
exchange=org.apache.dubbo.remoting.exchange.codec.ExchangeCodecorg.apache.dubbo.remoting.Codec2 配置文件用来执行 SPI 机制,我们会在之后对这个主题进行专项介绍,这里只需要明白 Dubbo 采用这种配置方式来动态加载运行时的类对象。在这里,可以看到 Dubbo 针对 exchange 和 transport 都提供了 Codec 支持。
解题要点
从解题思路上讲,序列化是一个相对比较容易把握的面试题。基于本讲关于序列化技术组件的讨论,我们发现有很多列表式的内容需要记忆。这部分内容需要大家平时多看一些资料,尽量扩展自己的知识面,这是针对这一主题的第一个解题要点。关于序列化相关工具之间的对比也有一个非常好的汇总资料
但也正是因为序列化本身是一个内容比较固化的主题,所以在解题上就不能完全照本宣科。只讲概念,而不给出自己的一些思考和总结,往往体现不出你和其他候选人之间的差别,这也是日常面试过程中需要注意的一个点。因此,针对这类题的第二个解题要点在于要事先用自己的语言来梳理回答问题的内容体系,重点展示自己对于这一技术主题的抽象和分析能力。针对技术选型类面试题,更加需要明确给出自己的判断。
小结与预告
但凡开发分布式和微服务应用,就一定会使用到序列化技术。可以说,序列化技术是我们开发互联网应用程序的基础设施类技术之一。序列化的实现工具有很多,本讲内容并不是介绍具体的某一个工具,而是从功能、性能以及兼容性等维度出发对这些工具进行分析,从而帮助你更好的进行选择。
具备了网络通信和序列化技术,接下来我们就可以实现一个简单的远程调用过程了。那么,如果让你自己设计一个简单的 RPC 架构,你会怎么做呢?这就是我们下一讲要探讨的内容。
远程调用:如果让你自己设计一个简单的 RPC 架构,你会怎么做?
任何分布式系统的开发都涉及到跨进程之间的远程过程调用,也就是所谓的 RPC。前面两讲我们讨论的网络通信和序列化实际上也都属于是 RPC 架构的范畴,只是关注于不同的技术切入点。而 RPC 本身也构成一种架构体系,包含一系列相互协作的核心组件。在 Dubbo、Spring Cloud 等主流的分布式服务框架中,这些技术组件使用起来都非常简单,因为框架为开发人员屏蔽了底层的实现细节。
那么,现在假如没有这些开源框架,而是需要你自己来设计并实现一套远程过程调用机制,你应该怎么做的?我认为这是一个很好的面试题,考查了候选人的综合技术能力。本讲内容将围绕这个话题展开详细讨论。
问题背景
在分布式系统中,服务与服务之间需要通过远程调用来完成一个个具体的业务操作。这是一个全流程的执行过程,涉及到前面介绍到的网络通信和序列化技术,也涉及到本讲内容要进一步阐述的远程调用中的不同技术组件。
在使用 Dubbo、Spring Cloud 等框架时,你可能并没有感受到远程调用过程是如何执行的,因为这些框架都提供了“远程调用本地化”机制,开发人员调用远程方法感觉和调用本地方法并没有什么差别。这是框架所具备的能力,我们直接使用即可。但从面试角度讲,如果只考查框架的使用方式,显然无法真正判断候选人的技术能力。因此,在面试过程中,面试官通常都会暂时抛开框架的具体使用方式,而从远程调用的基本概念和执行流程出发来进行提问。
针对这类面试题,如果候选人没有做精心的准备,往往很难回答到位,原因就在于我们平时不大会从这一角度入手考虑问题,也就不会重点关注相关的技术体系。从面试角度讲,这道题也存在一些灵活的提问方式,包括:
- 想要实现远程调用,整个流程应该包含那些基本的技术组件?
- RPC 架构的组成结构是怎么样的?
- 如果让你设计一个简单的 RPC 架构,你会怎么做?
- 你认为 Dubbo 框架中最核心的组件有哪些?
RPC 这个概念我们一直都在说,但面对这一概念,我们应该如何进行系统化的学习呢?我们接下来对这个问题进行分析。
问题分析
远程过程调用,英文即为 Remote Procedure Call,也就是我们通常所说的 RPC,这个名词第一次出现是在 1974 年。从诞生到今天,RPC 架构存在了 40 多年,已经演变成一切分布式系统的基础性架构。而围绕 RPC 架构的基本概念,这么多年以来实际上并没有发生大的变化。所以,关于 RPC 架构本身的学习内容和范围是相对固定的,这是我们首先需要明确的一点。
从面试角度讲,RPC 架构最应该掌握的是它的基本组成结构。作为一种架构模式,业界已经对 RPC 架构的各个组成部分进行了抽象和提炼,从而形成一套完整的组件体系。正是基于这套 RPC 的组件体系,业界诞生了各种具体实现框架,Dubbo 就是其中的代表。而无论 Dubbo 等框架如何实现,其底层的组成结构是完全遵循 RPC 架构的。因此,只要掌握了 RPC 架构的组成结构,关于这类问题的大部分内容我们已经可以回答了。
事实上,基于 RPC 的组成结构,任何人都可以自己实现一套 RPC 框架。我们可以采用最简单、最常见的技术体系实现一个最基础的 RPC 架构。通过这一过程,一方面可以确保具体的实现技术和纯粹的理论体系能够对应起来;另一方面,在面试过程中,这也是凸显出个人优势的一个加分项,能够提升面试官对候选人的认可程度。
好了,讲到这里,相信你已经具备了针对这类问题的解答思路。接下来要讨论的就是具体的技术体系了,让我们从 RPC 架构的组成结构开始讲起。
技术体系
如果我们站在最高的层次来看 RPC 的执行流程,就是一个服务的消费者向服务的提供者发起远程调用并获取返回结果的过程,如下图所示:

接下来,如果我们把上图做一些展开。通过之前的学习,我们知道服务提供者需要暴露服务访问的入口,而消费者则会向提供者所暴露的访问入口发起请求。如下图所示:

可以看到,这里我们对服务消费者和提供者的组成结构做了细化,并提取了 RpcChannel、RpcProtocol、RpcConnector 和 RpcAcceptor 这四个技术组件。在这四个技术组件中,前两个属于公共组件,而后两个则面向服务的提供者和服务的消费者,分别用于发起请求和接收响应。
有了底层的用于完成网络通信的技术组件之后,我们再来看如何从业务接口定义和使用的角度出发进一步对 RPC 架构的组成结构进行扩充,如下图所示:
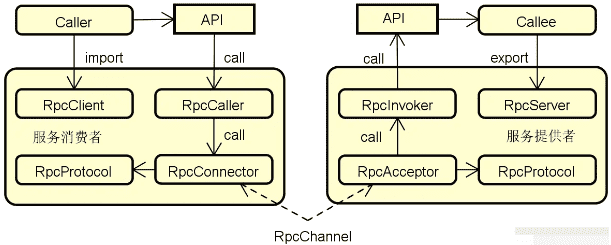
上图中出现了用于代表业务接口的 API 组件,同时,我们也看到了分别代表客户端和服务器的 RpcClient 和 RpcServer 组件。我们不难想象这些组件的定位和作用。而这里需要重点介绍的是 RpcCaller 组件和 RpcInvoker 组件。RpcCaller 组件位于服务消费者端,会根据 API 的定义信息发起请求。而 RpcInvoker 组件位于服务提供者端,负责对 RpcServer 执行具体的调用过程并返回结果。
最后,为了对远程调用过程进行更好的控制,我们还会引入两个技术组件,分别是 RpcProxy 和 RpcProcessor。完整的 RPC 架构组成结构如下图所示:
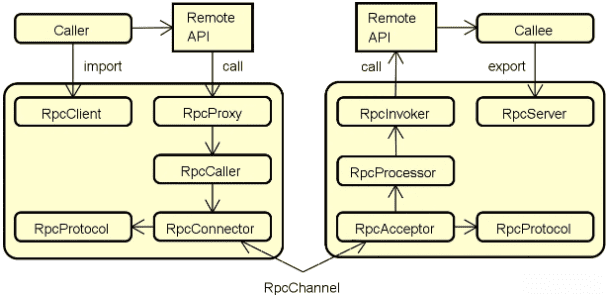
从命名上看,位于服务消费者端的 RpcProxy 组件充当了一种代理机制,确保服务消费者能够像调用本地方法一样调用远程服务。而位于服务提供者端的 RpcProcessor 的作用则是为远程调用执行过程添加各种辅助性支持,包括线程管理、超时控制等。
这样,我们对整个 RPC 架构的演进过程做了详细的描述。通过对上图中的技术组件做进一步梳理,我们会发现这些组件可以归为三大类,即客户端组件、服务端组件和公共组件。
其中,客户端组件与职责包括:
- RpcClient,负责导入远程接口代理实现;
- RpcProxy,远程接口的代理实现;
- RpcCaller,负责执行远程调用;
- RpcConnector,负责连接服务器。
服务端组件与职责包括:
- RpcServer,负责导出远程接口;
- RpcInvoker,负责调用服务端接口;
- RpcAcceptor,负责接收网络请求;
- RpcProcessor,负责处理调用过程。
而客户端和服务器端所共有的组件包括:
- RpcProtocol,负责执行网络传输;
- RpcChannel,数据传输的通道。
关于 RPC 架构的组成结构介绍到这里就结束了。在这一组成结构的基础上,如果采用合适的编程语言和实现技术,原则上我们就可以自己动手实现一个 RPC 架构。
源码解析
接下来我们通过一个简单的示例来实现前面所介绍的的各个技术组件。该示例的主要目的是演示如何从零开始构建一个最基本的 RPC 架构。
首先我们定义一个业务服务,称为 UserService,包含一个用于根据用户编码获取用户姓名的业务方法,如下所示:
public interface UserService {
// 根据用户编码获取用户姓名
public String getUserNameByCode(String userCode);
}UserService 接口的实现类也非常简单,我们通过一个内存 Map 来模拟对数据的存储和查询操作,如下所示:
public class UserServiceImpl implements UserService {
private Map<String, String> users = new HashMap<String, String>();
public UserServiceImpl() {
users.put("user1", "tianyalan1");
users.put("user2", "tianyalan2");
}
@Override
public String getUserNameByCode(String userCode) {
return users.get(userCode);
}
}对于 RPC 架构而言,有了服务定义之后,我们就需要分别构建一个服务端组件 RpcServer 和一个客户端组件 RpcClient。但在这之前,我们首先需要定义一种在客户端和服务器端之间进行通信的消息格式,这里命名为 Protocol,如下所示:
public class Protocol implements Serializable {
// 包名 + 接口名称
private String interfaceName;
// 调用方法名
private String methodName;
// 参数类型:按照接口参数顺序
private Class[] paramsTypes;
// 参数:按照接口参数顺序
private Object[] parameters;
public Protocol (String interfaceName, String methodName, Class[] paramsTypes, Object[] parameters) {
super();
this.interfaceName = interfaceName;
this.methodName = methodName;
this.paramsTypes = paramsTypes;
this.parameters = parameters;
}
// 省略 getter/setter 方法
}可以看到 Protocol 中定义了一次服务请求所需要的接口名、方法名以及方法调用所需要的参数。注意到该类同时实现了 Serializable 接口,这是 Java 中的序列化接口,实现该接口的类能够通过网络进行远程传输。在 RPC 基础架构图中,Protocol 类相当于是通过 RpcProtocol 进行传递的请求数据。
接下来我们考虑构建 RpcServer 类,该类需要实现 RPC 基础架构图中的各个服务端组件。RpcServer 类完整代码如下所示:
public class RpcServer {
// 线程池
private int threadSize = 10;
private ExecutorService threadPool;
// 自定义缓存
private Map<String, Object> servicePool;
// 服务端口
private int port = 9000;
public RpcServer() {
super();
synchronized (this) {
threadPool = Executors.newFixedThreadPool(this.threadSize);
}
}
public RpcServer(int threadSize, int port) {
this.threadSize = threadSize;
this.port = port;
synchronized (this) {
threadPool = Executors.newFixedThreadPool(this.threadSize);
}
}
public RpcServer(Map<String, Object> servicePool, int threadSize, int port) {
this.threadSize = threadSize;
this.port = port;
this.servicePool = servicePool;
synchronized (this) {
threadPool = Executors.newFixedThreadPool(this.threadSize);
}
}
// 1. 实现 Socket 监听:RpcAcceptor
public void service() throws IOException {
ServerSocket serverSocket = new ServerSocket(port);
while (true) {
Socket receiveSocket = serverSocket.accept();
final Socket socket = receiveSocket;
// 执行请求
threadPool.execute(new Runnable() {
@Override
public void run() {
try {
// 2. 处理请求
process(socket);
socket.close();
} catch(IOException e) {
// 篇幅关系,省略对各种异常信息的处理
}
}
});
}
}
// 2.处理请求:RpcProcessor
private void process(Socket receiveSocket) throws IOException, ClassNotFoundException, InvocationTargetException, NoSuchMethodException, InstantiationException, IllegalAccessException {
ObjectInputStream objectInputStream = new ObjectInputStream(receiveSocket.getInputStream());
Protocol protocol = (Protocol)objectInputStream.readObject();
// 调用服务
Object result = call(protocol);
ObjectOutputStream objectOutputStream = new ObjectOutputStream(receiveSocket.getOutputStream());
objectOutputStream.writeObject(result);
objectOutputStream.close();
}
// 3.执行方法调用:RpcInvoker
private Object call(Protocol protocol) throws ClassNotFoundException, NoSuchMethodException,
IllegalAccessException, InstantiationException, InvocationTargetException {
if(servicePool == null) {
synchronized (this) {
servicePool = new HashMap<String, Object>();
}
}
// 通过接口名称构建实现类
String interfaceName = protocol.getInterfaceName();
Object service = servicePool.get(interfaceName);
Class<?> serviceClass = Class.forName(interfaceName);
// 判断 servicePool 对象是否存在,如果不存在,就创建新对象并放入池中
if(service == null) {
synchronized (this) {
service = serviceClass.newInstance();
servicePool.put(interfaceName, service);
}
}
// 通过实现类来构建方法
Method method = serviceClass.getMethod(protocol.getMethodName(), protocol.getParamsTypes());
// 通过反射来实现方法的执行
Object result = method.invoke(service, protocol.getParameters());
return result;
}
}RpcServer 类代码相对比较长,我们结合 RPC 基本架构对其进行分段解析。
-
service 方法
service 方法接收请求并基于 Socket 启动端口监听,通过线程池为进入的每个请求启动一个线程进行处理。就 RPC 基础架构而言,该 service 方法相当于扮演 RpcAcceptor 的角色。
-
process 方法
service 方法启动了线程池,而每个线程负责执行 process 方法。这里的 process 方法从 Socket 中获取输入流,然后把输入流中的数据转化为 Protocol,从而获取远程方法调用的各项元数据。就 RPC 基础架构而言,该 process 方法充当了 RpcProcessor 的角色。
-
call 方法 一旦获取 Protocol,process 方法就调用内部的 call 方法来执行真正的方法调用。这里通过反射机制获取位于服务器端的方法并进行执行。显然,该 call 方法对应于 RpcInvoker 角色。
介绍完 RpcServer 中的各个技术组件,我们再来看一下 RpcClient 的代码,如下所示:
public class RpcClient {
private String serverAddress;
private int serverPort;
public RpcClient(String serverAddress, int serverPort) {
this.serverAddress = serverAddress;
this.serverPort = serverPort;
}
// RpcConnector + RpcCaller
public Object sendAndReceive(Protocol protocol) {
Object result = null;
try {
Socket socket = new Socket(serverAddress, serverPort);
ObjectOutputStream objectOutputStream = new ObjectOutputStream(socket.getOutputStream());
objectOutputStream.writeObject(protocol);
ObjectInputStream objectInputStream = new ObjectInputStream(socket.getInputStream());
result = objectInputStream.readObject();
} catch (Exception e) {
// 篇幅关系,省略对各种异常信息的处理
}
return result;
}
// 省略 getter/setter 方法
}RpcClient 类的代码相对比较简单,主要就是根据远程服务的地址通过 Socket 发起通信,传入一个 Protocol 对象并返回远程调用的结果。
完成了 RpcServer 和 RpcClient 类之后,我们就可以编写一些测试用例来进行验证。验证方法就是启动 RpcServer,然后通过 RpcClient 执行远程调用。这里我们编写一个 ServerTest 来启动 RpcServer,如下所示:
public class ServerTest {
public static void main(String[] args) {
Map<String, Object> servicePool = new HashMap<String, Object>();
servicePool.put("com.juejin.rpc.service.UserService", new UserServiceImpl());
RpcServer server = new RpcServer(servicePool, 4, 9000);
try{
server.service();
} catch (IOException e) {
e.printStackTrace();
}
}
}然后我们再编写一个 ClientTest 对远程服务发起请求,整个过程如下所示:
public class ClientTest {
public static void main(String[] args) {
String serverAddress = "127.0.0.1";
int serverPort = 9000;
RpcClient client = new RpcClient(serverAddress, serverPort);
Protocol protocol = buildProtocol("user1");
Object result = client.sendAndReceive(protocol);
System.out.println(result);
protocol = buildProtocol("user2");
result = client.sendAndReceive(protocol);
System.out.println(result);
}
private static Protocol buildProtocol(String userCode) {
String interfaceName = "com.juejin.rpc.service.UserService";
Class[] paramsTypes = {String.class};
Object[] parameters = {userCode};
String methodName = "getUserNameByCode";
Protocol protocol = new Protocol(interfaceName, methodName, paramsTypes, parameters);
return protocol;
}
}至此,我们构建了一个简洁但又完整的 RPC 架构。通过这个示例,我们可以对 RPC 的整体结构有一个清晰的认识。事实上,无论是多么复杂的 RPC 框架,都是从这样的基础架构开始逐步演进而来。
解题要点
围绕 RPC 架构,我们首先要明确的第一个解题要点就是它的组成结构。RPC 架构的组成呈现一种非常标准的对称结构,围绕远程调用过程,我们可以提炼出一组分别针对服务消费者和服务提供者的技术组件。把各个技术组件进行分类梳理是一种有助于记忆的学习方法,你也可以尝试能不能对这一组成结构再做进一步的细化。
RPC 架构的组成结构偏向理论描述,想要理解该架构中各个技术组件的具体实现过程,一种有效的方法就是自己动手做一些实践。而面试官实际上也非常看重候选人的这种实践能力,所以会以发散式的提问方式来考查候选人对 RPC 架构的掌握能力。基于本讲中给出的案例,你可以结合 RPC 架构的理论知识以及具体的代码实现过程来应对这种发散式的面试题。
最后,从本讲开头罗列的一些面试题可以看出,面试官往往会把 RPC 架构的组成结构和具体的 RPC 开源框架组合在一起进行提问。而在本讲内容中,我们也发现组成 RPC 架构的这些技术组件具有演进性。我们可以从最基本的组件出发,逐步进行扩展和完善,直至形成一个完整的技术体系。也就是说,我们可以从一个基础架构出发来系统掌握大型开源框架的实现原理。
小结与预告
想要掌握分布式服务框架,首先得掌握 RPC 架构。
本讲内容对 RPC 架构的组成结构进行了详细的介绍。同时,我们也针对 RPC 架构所需要实现的各个技术组件,提供了一个简洁但又完整的示例,从而有助于你对该架构有一个感性的认识。可以说,RPC 是分布式系统中一项基础设施类的技术体系,但凡涉及到服务与服务之间的交互就需要使用到 RPC 架构。当你在使用一个分布式框架时,可以尝试使用今天介绍的 RPC 架构的基本结构进行分析,从而加深对这项技术体系的理解。
在掌握了 RPC 架构的基本结构并动手实现了一个简易版的示例之后,让我们回到主流的开源框架,看看这些框架是如何实现远程调用的。远程调用涉及到服务发布和服务引用这两个方面。我们将先对前者展开讨论,并回答这样一个问题:如何合理设计服务发布机制?我们下一讲再聊。
远程调用:如何合理设计服务发布机制?
在上一讲中,我们通过一个简单但又完整的示例演示了如何实现一套自定义的 RPC 架构。在现实开发场景中,我们当然不建议大家重复造轮子,而是应该采用主流的 Dubbo、Spring Cloud 等开源框架来构建分布式系统。对于这些开源框架而言,RPC 架构的实现过程显然不会像上一讲中的示例那样简单,而是内置了各种强大的功能,从而为开发人员提供更好的开发体验。
本质上,一次远程调用涉及两个角色,即服务提供者和服务消费者,分别用来实现服务的发布和引用。在本讲内容中,我们将讨论服务的发布过程,并引出一个常见的面试题,即:如何合理设计服务发布机制?
问题背景
在分布式系统中,系统的能力来自于服务与服务之间的交互和集成。为了实现这一过程,就需要服务提供者对外暴露可以访问的入口。假设我们沿用上一讲中所介绍的业务服务 UserService,那么对该服务进行发布的一种实现方式如下所示:
UserService service = new UserServiceImpl(...);
RpcServer server = new RpcServer(…);
server.export(UserService.class, options);上述代码看上去也很简单,和我们在上一讲中所实现的示例代码有点类似。但在这几行代码的背后,我们需要考虑的事情非常多,比方说:
- 如果远程调用发生在同一个 JVM 中,服务发布应该如何实现?
- 如果我们想要在服务发布过程中添加一些定制化的切面逻辑,应该怎么做?
- 如果服务提供者具有多个服务实例,那么服务发布过程如何实现集群化?
- 如果服务发布操作还没完成,服务消费者的请求就进来了应该怎么办?
这些问题面向服务发布主流程中的特定场景,但正是这些特定场景才是面试过程中经常会出现的提问方式。同时,我们也应该注意到,远程调用是一个消耗大量资源的过程,资源的利用率也是框架必须要考虑的问题。如何合理地利用资源,避免远程通信所导致的性能消耗,也是服务发布机制设计上的一个重点。
如果针对 Dubbo 等具体的实现框架,面试官也可以这样来进行提问:
- Dubbo 中所采用的服务发布流程是怎么样的?
- Dubbo 框架中提供了哪几种服务发布机制?
- 为了提高资源利用的效率,Dubbo 在发布过程中做了哪些优化?
这些问题看上去侧重点各有不同,但其实都是围绕着一套服务发布流程来展开的,让我们来对这些问题做进一步分析。
问题分析
和前面几讲介绍的网络通信、序列化等主题不同,服务的发布和引用更多关注的是应用层的设计方法,而不是面向底层网络的通信组件。因此,我们对服务发布的分析也需要从应用层的角度进行切入,梳理一套通用而又完整的服务发布流程。而为了实现这一目标,就需要对业界主流的一些开源框架做一定的提炼和抽象。这是我们在应对这类面试题要把握的第一个方向。
然后,我们在这套流程中进一步提炼服务发布过程中所使用到的各个技术组件,这些技术组件能够与前面给出的特定场景下的面试问题相对应。这是我们要回答的第二个主要方向。
最后,我们还是要回到具体的实现框架,从源码切入来详细分析开源框架中针对服务发布机制的实现原理。只有这样,才能做到理论联系实际,也有助于我们更好地掌握开源框架的使用方式和技巧。
上述三个维度构成了我们回答这类问题的解答思路。接下来要讨论的就是具体的技术体系了,让我们给出对服务发布流程的统一描述。
技术体系
在现代的分布式架构中,服务的发布和引用过程往往与注册中心密切相关。服务注册中心是服务发布和引用的媒介,当我们把服务信息注册到注册中心,并能够从注册中心中获取服务调用地址时,需要考虑的问题就是如何进行有效的服务发布和引用。我们会在后面介绍注册中心,而在本讲接下来的内容中,我们重点关注的是服务发布所具备的流程和特性。
我们知道服务发布的目的是将该服务的访问入口暴露给分布式系统中的其他服务。抛开具体的技术和框架,我们先可以简单抽象出如下图所示的服务发布的整体流程:
上图包含了服务发布过程中的核心组件,我们来对这些核心组件做一一展开。
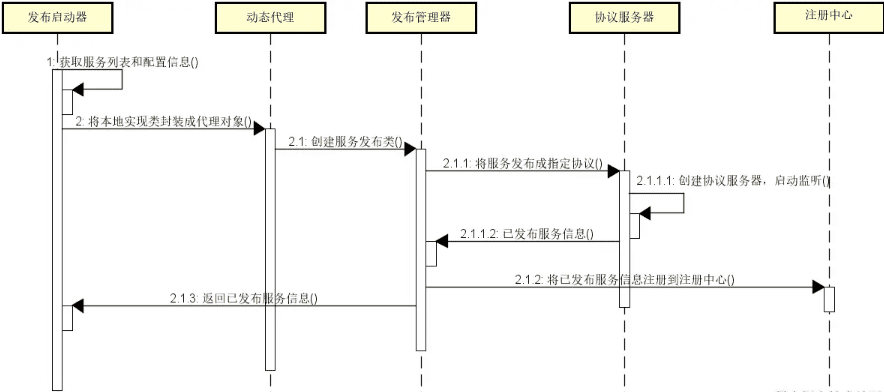
-
发布启动器
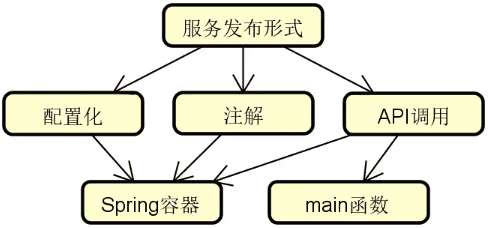
发布启动器的核心作用有两点,一个是确定服务的发布形式,一个是启动服务发布过程。在目前主流的开发框架中,常见的服务发布形式包括:
- 配置化:使用配置文件;
- 使用注解:使用 Java 中的注解机制;
- API 调用:使用底层的代码接口。
以上三种方式各有利弊。在日常开发过程中,配置和注解比较常用,而 API 调用则主要完成服务与服务之间的集成。
讲完发布形式,我们来讨论如何启动服务发布过程,常见的策略如下图所示:
![2024 10 23 11 12 57]()
可以看到,我们可以使用 Spring 容器来完成基于配置化和注解形式下的服务启动过程。而对于 API 调用而言,由于不一定会借助于容器,所以也可以直接使用 main 函数来实现这一目标。
-
动态代理
动态代理是远程过程调用中非常核心的一个技术组件,在服务发布和服务引用过程中都会用到,其主要作用就是简化服务发布和引用的开发难度,以及确保能够对发布过程进行扩展和定制。
关于动态代理的具体实现方式值得专门进行讨论,我们将在后面重点关注这一话题。
-
发布管理器
服务发布过程需要使用专门的组件来进行统一管理,这个组件就是发布管理器。该组件需要判断本次发布是否成功,然后在服务发布成功之后,把服务的地址信息注册到注册中心。而这里的服务地址信息则来自于协议服务器。
-
协议服务器
在服务发布过程中,在物理上真正建立网络连接,并对网络端口进行绑定的组件是协议服务器。协议服务器还会执行心跳检测以及在连接失败之后进行重连操作。用于发布服务的常见协议包括 HTTP、RMI、Hessian 等。我们也可以自己定义这样的协议,例如 Dubbo 框架就实现了一套自定义的 Dubbo 协议。实际上,关于网络通信方面的讨论就是针对这里的协议服务器。
-
注册中心
注册中心的作用是存储和管理服务定义的各类元数据,并能感知到这些元数据的变化。
以上所示的服务发布流程图有一定的共性,可以通过转化映射到具体的某个框架。事实上,基于 Dubbo 的服务发布流程与上述过程非常类似。让我们来一起看一下。
源码解析
在具体介绍 Dubbo 服务发布流程之前,我们先来讨论 Dubbo 暴露服务的两种时效,一种是延迟暴露,一种是正常暴露,如下图所示:
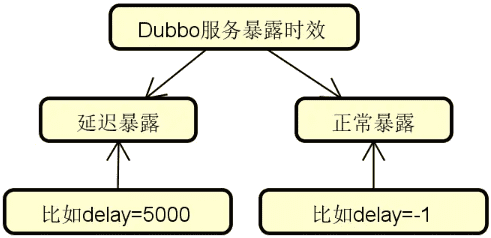
可以看到,如果这里的 delay 参数被设置成了 -1,代表不需要延迟暴露。反之,Dubbo 会根据该参数值的大小来执行对应的延迟策略。讲到这里,你可能会问,Dubbo 为什么要考虑发布时效这个问题呢?主要目的在于提供平滑发布机制。如果 Dubbo 服务本身还没有完全启动成功,那这时候对外暴露服务是没有意义的,我们可以通过设置延迟时间来确保服务在发布的时间点上就是可用的。
在判断是否需要延迟暴露之后,ServiceBean 就会调用 export 方法执行服务暴露。而 export 方法又来自 ServiceBean 的父类 ServiceConfig,所以关于 Dubbo 服务发布的流程就从 ServiceConfig 类进行切入。
那么,ServiceConfig 是如何实现延迟暴露的呢?实际上很简单,就是启动一个后台线程来延迟调用一个 doExport 方法,该方法负责执行具体的服务暴露逻辑。而如果没有采用延迟暴露策略,那么这个 doExport 方法就会被立即执行,具体的执行流程如下所示:
// 将 Bean 属性转化为 URL
URL url = new URL(name, host, port, (contextPath == null || contextPath.length() == 0 ? "" : contextPath + "/") + path, map);
String scope = url.getParameter(Constants.SCOPE_KEY);
// 如果 scope 配置为 none 则不暴露
if (!Constants.SCOPE_NONE.toString().equalsIgnoreCase(scope)) {
// 如果 scope 没有被配置为远程暴露,则采用本地暴露
if (!Constants.SCOPE_REMOTE.toString().equalsIgnoreCase(scope)) {
exportLocal(url);
}
// 如果 scope 没有被配置为本地暴露,则采用远程暴露
if (!Constants.SCOPE_LOCAL.toString().equalsIgnoreCase(scope)) {
if (registryURLs != null && registryURLs.size() > 0) {
for (URL registryURL : registryURLs) {
// 将具体服务转化为 Invoker
Invoker<?> invoker = proxyFactory.getInvoker(ref, (Class) interfaceClass, registryURL.addParameterAndEncoded(Constants.EXPORT_KEY, url.toFullString()));
DelegateProviderMetaDataInvoker wrapperInvoker = new DelegateProviderMetaDataInvoker(invoker, this);
// 将 Invoker转化为 Exporter
Exporter<?> exporter = protocol.export(wrapperInvoker);
exporters.add(exporter);
}
} else {
Invoker<?> invoker = proxyFactory.getInvoker(ref, (Class) interfaceClass, url);
DelegateProviderMetaDataInvoker wrapperInvoker = new DelegateProviderMetaDataInvoker(invoker, this);
Exporter<?> exporter = protocol.export(wrapperInvoker);
exporters.add(exporter);
}
}
}
this.urls.add(url);这段代码值得仔细分析。在这里,我们可以看到首先会构建一个 URL 对象,如下所示:
URL url = new URL(name, host, port, (contextPath == null || contextPath.length() == 0 ? "" : contextPath + "/") + path, map);请注意,在 Dubbo 中,URL 对象代表了统一数据模型,会贯穿服务暴露和调用的整个流程,绝对是一等公民。URL 格式如下所示:
protocol://username:password@host:port/path?key=value&key=value当不使用注册中心时,URL 表现形式比较简单,如下所示:
dubbo://service-host/com.foo.FooService?version=1.0.0而当使用注册中心时,URL 中会带有注册中心信息,如下所示:
registry://registry-host/org.apache.dubbo.registry.RegistryService?export=URL.encode("dubbo://service-host/com.foo.FooService?version=1.0.0")通过分析 Dubbo 源码,我们得到将配置信息通过一种统一的 URL 进行表示和传递的实现方法,这也是值得我们学习的一个设计技巧。
接着,我们根据 scope 参数判断服务的发布范围,判断规则如下图所示:
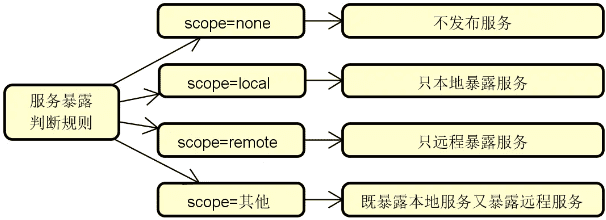
关于本地服务的暴露我们后面再具体展开,这里先讨论远程服务暴露的场景。
远程服务暴露
在 Dubbo 中,远程服务暴露过程需要执行非常重要的一个步骤,即将具体服务对象转换到 Invoker,如下所示:
Invoker<?> invoker = proxyFactory.getInvoker(ref, (Class) interfaceClass, registryURL.addParameterAndEncoded(Constants.EXPORT_KEY, url.toFullString()));这里看到了一个 proxyFactory 对象,从命名上不难看出它是一个代理工厂类,定义如下所示:
@SPI("javassist")
public interface ProxyFactory {
@Adaptive({Constants.PROXY_KEY})
<T> T getProxy(Invoker<T> invoker) throws RpcException;
@Adaptive({Constants.PROXY_KEY})
<T> Invoker<T> getInvoker(T proxy, Class<T> type, URL url) throws RpcException;
}在 Dubbo 中,该接口有两个实现类,即 JdkProxyFactory 和 JavassistProxyFactory。我们来看 JdkProxyFactory 中的 getInvoker 方法实现,如下所示:
public <T> Invoker<T> getInvoker(T proxy, Class<T> type, URL url) {
return new AbstractProxyInvoker<T>(proxy, type, url) {
@Override
protected Object doInvoke(T proxy, String methodName, Class<?>[] parameterTypes, Object[] arguments) throws Throwable {
Method method = proxy.getClass().getMethod(methodName, parameterTypes);
return method.invoke(proxy, arguments);
}
};
}可以看到这里返回了一个 AbstractProxyInvoker 对象,而 AbstractProxyInvoker 实现了 Invoker 接口。Invoker 接口定义如下所示:
public interface Invoker<T> extends Node {
// 获取服务接口
Class<T> getInterface();
// 执行远程调用
Result invoke(Invocation invocation) throws RpcException;
}Dubbo 为我们提供了一组 Invoker 接口的实现类,其中包括前面看到的 AbstractProxyInvoker。
我们已经在 JavaProxyFactory 中看到了构建一个 Invoker 对象的实现过程,背后使用的本质上就是反射机制。
现在我们明白了,Invoker 就是 Dubbo 实现远程调用的实体类。对于服务发布和引用而言,这个 Invoker 贯穿始终,可以说也是一个一等公民。
有了 Invoker 之后,我们再来关注 Exporter。我们看到 Exporter 是通过调用 Protocol 接口的 export 方法所生成的,这就需要我们对 Procotol 做一些回顾。Protocol 作为 Dubbo 中最基本的 RPC 组件,完成了服务的发布和调用功能,该接口定义如下所示:
@SPI("dubbo")
public interface Protocol {
int getDefaultPort();
@Adaptive
<T> Exporter<T> export(Invoker<T> invoker) throws RpcException;
@Adaptive
<T> Invoker<T> refer(Class<T> type, URL url) throws RpcException;
void destroy();
}从方法命名上不难看出,Protocol 接口中的核心方法就是 export 和 refer,前者用于对外暴露服务,而后者则用来对远程服务进行引用。当 Dubbo 获取 URL 之后会将 URL 传给 Protocol,Protocol 根据 URL 的协议头执行不同协议的服务暴露或引用。
关于 URL 的格式我们在前面已经给出说明和示例。根据 URL 中是否包含注册中心信息,服务发布流程也会判断是否需要与注册中心进行交互。关于注册中心的讨论我们放在后面进行详细展开。这里给出不基于注册中心的服务暴露方式,即如下所示的 DubboProtocol 中 export 方法的实现过程。
public <T> Exporter<T> export(Invoker<T> invoker) throws RpcException {
URL url = invoker.getUrl();
// 暴露服务
String key = serviceKey(url);
DubboExporter<T> exporter = new DubboExporter<T>(invoker, key, exporterMap);
exporterMap.put(key, exporter);
// 创建 Exchange 服务器
openServer(url);
return exporter;
}这里的 openServer 方法的目标是创建 Exchange 服务器,这是整个服务发布流程中的底层部分,我们已经在 网络通信:如何完成客户端和服务端之间的高效通信 中做了详细介绍,你可以做相应的回顾。
作为总结,我们把整个远程服务暴露流程做一个梳理,得到如下图所示的核心对象交互图:
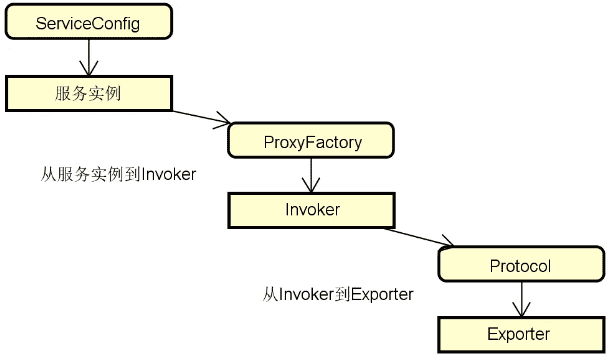
关于 Dubbo 中远程服务暴露的实现过程就介绍到这里,接下来我们讨论本地服务暴露过程。
本地服务暴露
我们回顾 ServiceConfig 中的服务暴露流程,存在如下所示的一个流程分支:
if (!Constants.SCOPE_REMOTE.toString().equalsIgnoreCase(scope)) {
exportLocal(url);
}可以看到,如果 scope 没有被设置为远程暴露,则采用本地暴露模式暴露服务。那么,什么样的场景适合这种服务暴露模式呢?我们知道远程调用只会发生在跨 JVM 的场景,如果在同一个 JVM 中同时存在某一个服务的提供者和消费者,那么就可以将服务发布和引用过程控制在同一个 JVM 之内,从而避免远程网络通信所导致的性能消耗。
Dubbo 中提供的 exportLocal 方法实现了这一过程,如下所示:
private void exportLocal(URL url) {
if (!Constants.LOCAL_PROTOCOL.equalsIgnoreCase(url.getProtocol())) {
URL local = URL.valueOf(url.toFullString())
.setProtocol(Constants.LOCAL_PROTOCOL)
.setHost(LOCALHOST)
.setPort(0);
Exporter<?> exporter = protocol.export(proxyFactory.getInvoker(ref, (Class) interfaceClass, local));
exporters.add(exporter);
}
}这里的特殊之处就在于当碰到场景为 local 的 URL 时,我们将它的协议设置为了 Constants.LOCAL_PROTOCOL,即 injvm。我们不难猜到 Protocol 接口应该存在一个名为 InjvmProtocol 的实现类。跟 DubboProtocol 相比,InjvmProtocol 的 export 方法就显得非常简单了,如下所示:
public <T> Exporter<T> export(Invoker<T> invoker) throws RpcException {
return new InjvmExporter<T>(invoker, invoker.getUrl().getServiceKey(), exporterMap);
}可以看到,这里没有执行任何关于远程调用的操作,而是构建了一个 InjvmExporter 对象并直接返回,InjvmExporter 类的定义如下所示:
class InjvmExporter<T> extends AbstractExporter<T> {
private final String key;
private final Map<String, Exporter<?>> exporterMap;
InjvmExporter(Invoker<T> invoker, String key, Map<String, Exporter<?>> exporterMap) {
super(invoker);
this.key = key;
this.exporterMap = exporterMap;
exporterMap.put(key, this);
}
public void unexport() {
super.unexport();
exporterMap.remove(key);
}
}看到这里,我们明白了所谓的本地暴露,Dubbo 只是将 InjvmExporter 对象放置到一个 Map 内存对象中。这样,我们就可以直接从 JVM 的内存中获取 InjvmExporter 对象来完成服务之间的调用。
解题要点
本讲介绍的服务发布机制以及下一讲要介绍的服务引用过程都是属于技术实现流程类的面试题,这种面试题想要回答得很到位是有难度的,需要具备高度的抽象能力。本讲对这些流程进行了梳理,面试者只要对有一个基本的认识,就能从动态代理、协议、注册中心等关键技术组件出发,并对这些组件的作用和运行机制做一些展开。这样,面试官的主要考察目标基本就能满足了。
请注意,考查技术实现流程性的面试题还有一个特点,就是它会关联到多个技术组件,相信你从本讲中所引用的其他各讲的数量就能感受到这一点。服务的发布需要注册中心,也需要底层的网络通信。在面试过程中,我们需要点到这些关联性的技术组件,并挑选自己比较熟悉的方向进行展开。
最后,我们同样建议基于具体的开源框架来展开对技术实现流程的讨论。对于 Dubbo 框架,建议不用做过多展开,只需要点到最核心的几个概念即可,例如远程服务暴露和本地服务暴露这两种服务暴露类型。然后,我们也可以重点对 Dubbo 框架中的核心对象做一些分析,例如 URL 对象和 Invoker 对象。
小结与预告
在远程过程调用的实现流程上,主要包括服务发布和服务引用两大维度。
本讲内容围绕远程调用的发布流程展开了详细的讨论,这部分内容是我们构建分布式系统的基本前提。同时,基于这套服务发布流程,我们对 Dubbo 这款主流的分布式服务框架的内部实现原理,即如何完成远程/本地服务暴露的过程进行分析。
介绍完服务发布流程和实现原理之后,下一讲我们继续讨论远程过程调用,我们要回答的一个核心问题是:服务引用有哪些实现方式?同样,我们也会基于 Dubbo 框架给出这个问题的答案。
远程调用:服务引用有哪些实现方式?
在上一讲中,我们介绍了远程过程调用中的服务发布流程。我们知道服务发布的过程就是服务提供者对外暴露可访问入口的过程。基于所暴露的访问入口,服务消费者就可以成功发起远程调用。我们把这个过程称为服务引用。
和服务发布类似,服务引用也具备一套完整的执行流程。那么,服务引用有哪些具体的实现方式呢?这就是本讲要介绍的内容。
问题背景
在分布式系统中,系统的能力来自于服务与服务之间的交互和集成。为了实现这一过程,就需要服务消费者对服务提供者所暴露的入口进行访问。假设我们继续使用 UserService 作为业务接口,那么服务引用的一种表现形式可以采用如下所示的代码风格:
RpcClient client = new RpcClient(…);
UserService service = client.refer(UserService.class);
service.getUserNameByCode("user1");和服务发布的过程类似,服务引用看上去并不复杂,但背后要考虑的事情也非常多,包括:
- 如何实现远程调用过程的透明化?
- 如何使用缓存机制提高远程调用的效率?
- 除了缓存机制,你还有什么办法可以提高远程调用的性能?
- 如何实现异步调用、泛化调用等多种调用形式?
实际上,相较服务发布,服务引用是一个更为复杂的话题,涉及的技术组件众多。后续几讲要介绍的负载均衡、服务容错等机制都发生在服务引用阶段,这些机制对于服务发布而言是不需要考虑的。
当然,如果针对 Dubbo 等具体的实现框架,面试官也可以这样来进行提问:
- Dubbo 中所采用的服务引用流程是怎么样的?
- Dubbo 框架中提供了哪几种服务调用方式?
同样,这些问题看上去侧重点各有不同,但其实都是围绕着一套服务引用流程来展开的,让我们来对这些问题做进一步分析。
问题分析
对于远程过程调用而言,服务引用和服务发布是两个对应的技术组件。因此,上一讲中所有关于服务发布的问题分析方法同样适用于服务引用过程,这部分内容这里就不一一展开,你可以参考上一讲内容做一些回顾。
然而,对于服务引用而言,也存在与服务发布不一样的地方。首要一点在于服务引用的类型可以是多样的,我们可以使用同步调用、异步调用等多种方式来完成远程调用过程。
在日常开发过程中,开发人员倾向于使用同步调用模式来完成远程调用,因为这一模式对于编码过程而言非常友好。而从性能上讲,异步调用模式显然更具优势,但实现复杂度较高。这就诞生了一种新的实现机制,即 异步转同步,诸如 Dubbo 等框架就内置了这种实现机制。
在面试过程中,除了介绍通用的服务引用流程,候选人最好能够对服务的引用类型,以及异步转同步这一特定技术实现机制做一定的展开,这些都是提高面试成功率的加分项。
技术体系
通用服务引用流程
相较服务发布,服务的调用是一个导入(Import)的过程,整体流程如下图所示:
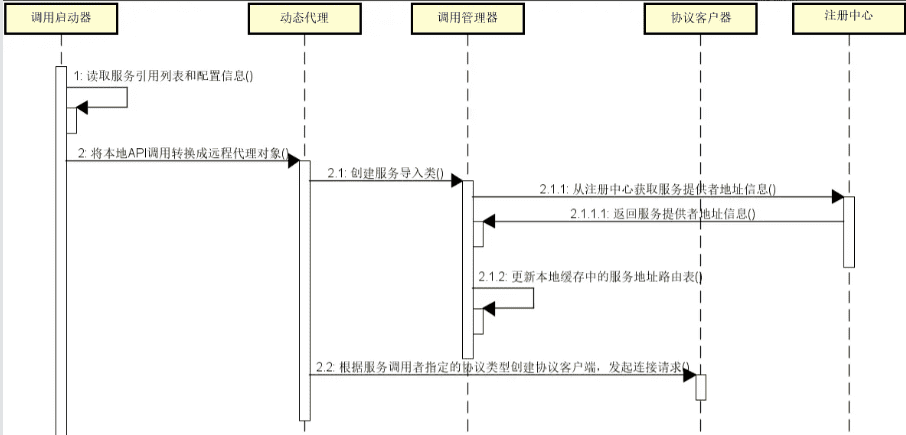
在上图中,我们可以看到服务调用流程与服务发布流程呈对称结构,所包含的组件包括以下。
-
调用启动器。调用启动器和上一讲介绍的发布启动器是对应的,这里不再重复介绍。
-
动态代理。在服务引用过程中,动态代理的作用就是确保远程调用过程的透明化,即开发人员可以使用本地对象来完成对远程对象的处理,如下图所示:
![2024 10 28 18 26 12]()
-
调用管理器。和发布管理器相比,调用管理器的核心功能是提供了一种缓存机制,从而根据保存在服务调用者本地的远程服务地址信息来发起调用。
-
协议客户端。和协议服务器相对应,协议客户端会创建与服务端的网络连接,发起请求并获取结果。
-
注册中心。注册中心在这里的作用是提供查询服务定义元数据的入口。

以上所示的服务引用流程图同样有一定的共性,可以通过转化映射到具体的某个框架。事实上,基于 Dubbo 的服务引用流程与上述过程也比较类似。
另一方面,与服务发布相比,Dubbo 等分布式服务框架中的服务引用整体过程会更加复杂一点。在服务调用过程中,因为面对的服务一般都会部署成集群模式,势必涉及到负载均衡。而如果调用超时或失败,还会采用集群容错机制。关于负载均衡和集群容错等内容不在这里讨论,我们在介绍完本讲内容之后马上就会有专门的主题进行详细阐述。
服务调用的类型
服务调用存在两种基本方式,即同步调用模式和异步调用模式。其中,同步调用的示意图如下图所示:
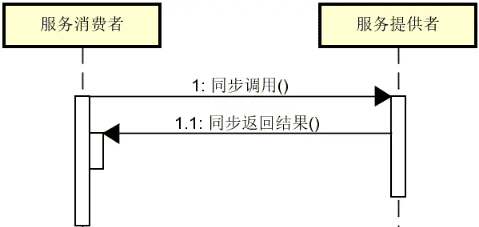
可以看到,同步调用的执行流程比较简单。在同步调用中,服务消费者在获取来自服务提供者的响应结果之前一直处于等待状态。
而异步调用则不同,服务消费者一旦发送完请求之后就可以继续执行其他操作,直到服务提供者异步返回结果并通知服务消费者进行接收,如下图所示:
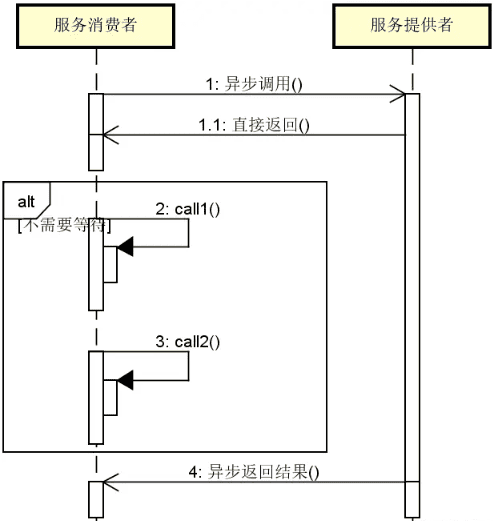
显然,使用异步调用的目的在于获取高性能。但是,异步调用的开发过程比较复杂,对开发人员的要求较高,所以很多 RPC 框架提供了专门的异步转同步机制,即面向开发人员提供的是同步调用的 API,而具体执行过程则使用的是异步机制。
除了同步和异步调用之外,还存在并行(Parallel)调用和泛化(Generic)调用等调用方法,这些调用方式并不常见,我们不做具体展开。
源码解析
与 ServiceConfig 中的 export 方法相对应,ReferenceConfig 中也存在一个 init 方法,该方法就是 Dubbo 服务引用流程的入口。
服务引用
在 ReferenceConfig 的 init 方法中,Dubbo 做了非常多的准备和校验工作,最终来到了如下所示的这行代码中:
ref = createProxy(map);这个 createProxy 方法是理解服务引用的关键入口,我们梳理它的主体结构如下所示:
private T createProxy(Map<String, String> map) {
if (isJvmRefer) {
// 生成本地引用 URL,使用 injvm 协议进行本地调用
URL url = new URL(Constants.LOCAL_PROTOCOL, NetUtils.LOCALHOST, 0, interfaceClass.getName()).addParameters(map);
invoker = refprotocol.refer(interfaceClass, url);
} else {
if (url != null && url.length() > 0) {
// URL 不为空,执行点对点调用
} else {
// 加载注册中心 URL
}
if (urls.size() == 1) {
// 单个服务提供者,直接调用
invoker = refprotocol.refer(interfaceClass, urls.get(0));
} else {
// 多个服务提供者
List<Invoker<?>> invokers = new ArrayList<Invoker<?>>();
URL registryURL = null;
for (URL url: urls) {
invokers.add(refprotocol.refer(interfaceClass, url));
if (Constants.REGISTRY_PROTOCOL.equals(url.getProtocol())) {
registryURL = url;
}
}
if (registryURL != null) {
// 如果注册中心链接不为空,则将使用 AvailableCluster
URL u = registryURL.addParameter(Constants.CLUSTER_KEY, AvailableCluster.NAME);
invoker = cluster.join(new StaticDirectory(u, invokers));
} else {
invoker = cluster.join(new StaticDirectory(invokers));
}
}
// 生成服务代理类
return (T) proxyFactory.getProxy(invoker);
}虽然 createProxy 方法的代码比较长,但它的执行逻辑还是比较清晰的。首先我们根据配置检查是否为本地调用,如果是则调用 InjvmProtocol 的 refer 方法生成 InjvmInvoker 实例;如果不是,则读取 URL 配置项,包括用于直联的 URL 或基于注册中心的 URL。
然后,我们对 URL 对象数量进行判断。如果 URL 数量为 1,则直接通过 Protocol 构建 Invoker 对象;如果 URL 数量大于 1,即存在多个服务地址,此时先根据每个 URL 构建 Invoker,然后再通过集群对象 Cluster 合并多个 Invoker,最后调用 ProxyFactory 生成代理类。
这个过程实际上完成了两个步骤,首先是创建 Invoker 对象,然后才是生成服务代理类,如下图所示:

显然,上述流程中,我们需要重点关注服务引用过程中 Invoker 对象的构建过程。那么问题来了,这里的这个 Invoker 是从何而来呢?实际上,Invoker 的构建过程是在 Protocol 中。与服务暴露的讲解思路一样,我们将从 DubboProtocol 这个 Protocol 的 refer 方法入手,如下所示:
public <T> Invoker<T> refer(Class<T> serviceType, URL url) throws RpcException {
DubboInvoker<T> invoker = new DubboInvoker<T>(serviceType, url, getClients(url), invokers);
invokers.add(invoker);
return invoker;
}这里出现了一个 getClients 方法,该方法用于获取客户端实例,实例类型为 ExchangeClient。我们已经在介绍 Dubbo 客户端通信原理时介绍过 ExchangeClient,可以参考前面做一些回顾。在理解了 getClients 方法之后,我们发现 DubboProtocol 的 refer 方法的作用就是返回一个新建的 DubboInvoker。
DubboInvoker 继承了 AbstractInvoker,而 AbstractInvoker 实现了 Invoker 接口。AbstractInvoker 是一个抽象的模板方法类,提供了一个 doInvoke 模板方法。我们来看 DubboInvoker 中如何实现了这个模板方法,如下所示:
@Override
protected Result doInvoke(final Invocation invocation) throws Throwable {
RpcInvocation inv = (RpcInvocation) invocation;
final String methodName = RpcUtils.getMethodName(invocation);
inv.setAttachment(Constants.PATH_KEY, getUrl().getPath());
inv.setAttachment(Constants.VERSION_KEY, version);
ExchangeClient currentClient;
if (clients.length == 1) {
currentClient = clients[0];
} else {
currentClient = clients[index.getAndIncrement() % clients.length];
}
try {
boolean isAsync = RpcUtils.isAsync(getUrl(), invocation);
boolean isOneway = RpcUtils.isOneway(getUrl(), invocation);
int timeout = getUrl().getMethodParameter(methodName, Constants.TIMEOUT_KEY, Constants.DEFAULT_TIMEOUT);
if (isOneway) { // 单向调用
boolean isSent = getUrl().getMethodParameter(methodName, Constants.SENT_KEY, false);
currentClient.send(inv, isSent);
RpcContext.getContext().setFuture(null);
return new RpcResult();
} else if (isAsync) { // 异步调用
ResponseFuture future = currentClient.request(inv, timeout);
RpcContext.getContext().setFuture(new FutureAdapter<Object>(future));
return new RpcResult();
} else { // 同步调用
RpcContext.getContext().setFuture(null);
return (Result) currentClient.request(inv, timeout).get();
}
} catch (TimeoutException e) {
}可以看到,Dubbo 的远程调用存在三种调用方式,即单向调用、异步无返回以及异步转同步。上述方法就包含了这三种调用方式的实现过程,而这些远程调用最终都是通过 ExchangeClient 进行完成。
在 Dubbo 提供的这三种远程调用方式中,异步转同步是默认的实现方式。接下来,我们重点对这一过程做具体展开。
服务调用异步转同步过程
在介绍 Dubbo 中异步转同步的服务调用方式之前,我们先围绕 JDK 中的 Future 模式讨论如何实现异步调用。
Future 模式是对传统调用模式的一种改进,它们之间的对比可以参考下图:
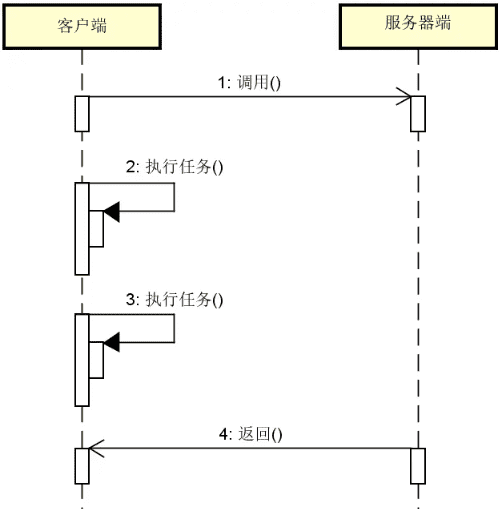
本质上,Future 模式为我们提供了一种无需等待的服务调用机制。当我们发起一次服务调用时,Future 机制可以直接返回并继续执行其他任务,而不是像传统调用模式那样一直需要等到调用方法的返回。
JDK 对 Future 模式提供了内置的实现,表现为如下所示的 Future 接口:
public interface Future<V> {
// 取消执行
boolean cancel(boolean mayInterruptIfRunning);
// 判断是否已取消
boolean isCancelled();
// 判断是否已完成
boolean isDone();
// 等待任务执行完毕并获取结果
V get() throws InterruptedException, ExecutionException;
// 基于一定的超时时间等待任务执行完毕并获取结果
V get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException;
}Dubbo 中大量使用了基于 Future 机制的异步调用过程,同时也提供了异步转同步的实现机制,这是 Dubbo 提供的这三种远程调用方式中默认的实现方式。这部分内容实际上已经超出了服务引用的范围,而是更多偏向于讨论底层的网络通信,所以需要你对网络通信相关的内容先进行学习和掌握。
在 DubboInvoker 中 doInvoke 方法中,异步转同步过程的实现如下所示:
RpcContext.getContext().setFuture(null);
return (Result) currentClient.request(inv, timeout).get();我们先来看这里的 request 方法定义(位于 HeaderExchangeChannel 类中),如下所示:
public ResponseFuture request(Object request, int timeout) throws RemotingException {
Request req = new Request();
req.setVersion("2.0.0");
req.setTwoWay(true);
req.setData(request);
DefaultFuture future = new DefaultFuture(channel, req, timeout);
try {
channel.send(req);
} catch (RemotingException e) {
future.cancel();
throw e;
}
return future;
}请注意,这里用于发送请求的 channel.send 方法是异步执行的,也就说该方法一旦调用就会直接返回。为了实现“异步转同步”,Dubbo 在这里使用了 DefaultFuture 这个辅助类。请记住这个类,我们在后续内容中还会再次提到该类。
另一方面,我们在介绍网络通信时也提到,当请求到达服务器端时,在 NettyServer 中会使用一个 NettyHandler 作为网络事件的处理器,如下所示:
pipeline.addLast("handler", nettyHandler);NettyHandler 是一个接口,我们来看它的 messageReceived 方法实现,如下所示:
private final ChannelHandler handler;
@Override
public void messageReceived(ChannelHandlerContext ctx, MessageEvent e) throws Exception {
NettyChannel channel = NettyChannel.getOrAddChannel(ctx.getChannel(), url, handler);
try {
handler.received(channel, e.getMessage());
} finally {
NettyChannel.removeChannelIfDisconnected(ctx.getChannel());
}
}这里把具体的处理逻辑转移到了 Dubbo 中自定义的 ChannelHandler 接口,这个接口有很多实现类,也包括 ChannelHandlerDelegate 这个代理类,而真正处理事件接收逻辑的 HeaderExchangeHandler 正是实现了这个代理类。HeaderExchangeHandler 中处理响应的实现过程如下所示:
static void handleResponse(Channel channel, Response response) throws RemotingException {
if (response != null && !response.isHeartbeat()) {
DefaultFuture.received(channel, response);
}
}我们在这里再次看到了 DefaultFuture,这里的 DefaultFuture 就是前面客户端发送请求时用到的 DefaultFuture。DefaultFuture 的 received 方法中有进一步调用了如下所示的 doReceived 方法:
private void doReceived(Response res) {
lock.lock();
try {
// 设置响应 response 对象
response = res;
if (done != null) {
// 唤醒阻塞的线程
done.signal();
}
} finally {
lock.unlock();
}
if (callback != null) {
invokeCallback(callback);
}
}注意到这里的 done.signal 方法的执行效果会唤醒阻塞的线程,那么这个阻塞的线程在哪里的?显然,这时候我们应该回到客户端组件看看同步获取调用结果的入口。
我们再次回到在 DubboInvoker 中 doInvoke 方法中,看到了如下所示的核心代码:
RpcContext.getContext().setFuture(null);
return (Result) currentClient.request(inv, timeout).get();我们来具体看一下这个获取调用结果的 get 方法执行逻辑,如下所示:
public Object get(int timeout) throws RemotingException {
if (timeout <= 0) {
timeout = Constants.DEFAULT_TIMEOUT;
}
if (!isDone()) {
long start = System.currentTimeMillis();
lock.lock();
try {
while (!isDone()) { // 当响应 response 对象为空
done.await(timeout, TimeUnit.MILLISECONDS);
if (isDone() || System.currentTimeMillis() - start > timeout) {
break;
}
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
lock.unlock();
}
if (!isDone()) {
throw new TimeoutException(sent > 0, channel, getTimeoutMessage(false));
}
}
return returnFromResponse();
}可以看到,当响应 response 对象为空时,Condition 会执行 await 方法来阻塞当前线程,直到该线程被唤醒、被中断或超过阻塞时间。而在前面所述的 DefaultFuture 类的 doReceived 方法中,我们也看到会先为 response 赋上返回值,之后执行 Condition 的 signal 方法唤醒被阻塞的线程,这样 get 方法就会释放锁,进而执行 returnFromResponse 方法来返回值。
这样,整个远程调用的异步转同步过程就介绍完毕。作为总结,我们明确 Dubbo 异步转同步的原理其实就是利用 Lock 和 Condition 实现了等待通知机制。当客户端发送请求时,将一个请求 Id 和一个 DefaultFuture 对象包装在请求对象中。而当客户端异步收到响应时,则根据这个请求 Id 从响应结果中获取对应的 DefaultFuture 对象,并调用该 DefaultFuture 对象的 get 方法获取最终的调用结果。
解题要点
在涉及到远程调用的应用场景,很多开源框架都会基于 Future 或它的一些变种,例如 JDK 自身提供的改进版 CompleteFuture,或是 Google 的 guava 框架中提供的 ListenableFuture 等。类似的问题主要还是关注 Future 机制本身的一些特性,可以发散出一系列的问题,但基本的考点是一致的,回答的思路也类似。
Future 机制本身提供的几个接口也并不复杂,需要理解它们的含义和作用,但也要理解它们存在的不足。普通 Future 机制的最大问题在于没有提供通知的机制,也就是说我们不知道 Future 什么时候能够完成。前面提到的 CompleteFuture 和 ListenableFuture 实际上都是为了改进普通 Future 存在的这一问题而诞生的。本讲内容对 Future 的概念做了类比介绍,同时给出了 JDK 中 Future 接口的各个核心方法。通过掌握这些核心方法,针对这个问题我们就能拿到 60 分。如果我们还能够进一步分析基本 Future 机制的不足,然后引出 CompleteFuture 或 ListenableFuture 等改进版本的 Future,那么拿到 80 分就不成问题。
另一方面,对于 Dubbo 框架中的服务引用过程,我们需要重点掌握的是它的三种调用方式,即单向、同步和异步。其中前面两种比较好理解,而针对异步,我们在使用 Dubbo 的过程中实际上最终也是转换为同步操作。针对这一问题,如果只是回答这个问题中所提出的实现方式的种类,那么只要简单列举即可。但要说明具体的实现细节,尤其是 Dubbo 中 异步转同步 的实现细节,那么需要对本讲内容做深入的理解,并尝试使用自己的语言来总结整个过程。
小结与预告
承接上一讲内容,本讲围绕远程过程调用的服务引用过程展开了讨论。同样的,基于这套服务引用流程,我们也对 Dubbo 中服务引用的底层设计思想和实现过程进行了分析,尤其对服务调用异步转同步过程做了详细的阐述。
事实上,关于服务引用的完整介绍还没有结束。相较服务发布,服务引用还涉及到负载均衡、服务容错等技术组件,这些技术组件都是构建分布式服务所必不可少的。在接下来的几讲内容中,我们将一一对这些技术组件展开讨论。下一讲内容将先从负载均衡进行切入,在服务发布和引用的基础上回答这样一个问题:负载均衡如何与远程调用过程进行整合?我们下一讲详聊。
负载均衡:负载均衡如何与远程调用过程进行整合?
在上一讲中,我们详细阐述了在远程调用过程中服务引用的流程和实现方式。请注意,在现实环境中,我们一般都会采用集群模式对服务进行多实例化的部署,以防止出现单点故障。
那么,问题就来了,服务消费者的每一次远程调用就需要确定对这些服务实例中的具体哪一个发起请求,这就是负载均衡要解决的问题。
负载均衡(Load Balance)是一个复杂的话题,要想在远程调用过程中引入负载均衡,我们首先需要回答一个基本的问题,即:负载均衡是如何与远程调用过程进行整合的呢?本讲内容将围绕这一问题展开讨论。
问题背景
相信你对集群这个概念并不陌生。在分布式系统开发过程中,集群的作用主要有两点,一方面通过服务的冗余为系统可用性提供了一种技术手段,另一方面也针对系统的性能问题提供了解决方案。通过集群,我们能够将业务请求分摊到多台单机性能不一定非常出众的服务器上。这部分内容作为负载均衡的基本概念,是每位面试候选人都应该掌握的。
但是,如果问到“如何在远程调用中集成负载均衡机制”这个问题,就我的面试经验,相信很多候选人就不一定能回答出来了。从问题本身而言,你可能会觉得负载均衡和远程调用是天生整合在一起的,因为在日常开发过程中,开源框架以及运行时环境都已经帮你准备好了这部分工作,普通开发人员不需要参与,这也导致了我们对这部分内容不够重视。但是,就技术实现而言,两者之间的集成过程又非常重要。可以说,正是因为能够在远程调用过程中集成负载均衡机制,才会有我们后续要介绍的集群容错、服务熔断等一系列技术组件的应用。
进一步,我们来梳理针对这一话题的常见面试提问方式,包括:
- 负载均衡的基本结构是怎么样的,它有什么作用?
- 如果想要在远程调用过程中嵌入负载均衡机制,你有什么设计思路?
- 你能简要描述 Dubbo 框架的负载均衡组成结构吗?
- 在 Spring Cloud 中,为什么在 RestTemplate 类上添加了 @LoadBalanced 注解,就能自动集成负载均衡功能?
对于这类问题,我们注意到问题的要点并不在于负载均衡本身的概念和原理,而更多的是关于具体的实现过程和机制,所以是一种偏实战类的考查方式。
问题分析
在分布式系统构建过程中,势必需要引入负载均衡机制,而业界关于如何实现负载均衡存在一系列工具。在这些工具中,有些提供的是偏向于底层负载均衡算法实现的工具库,而有些则提供了整套负载均衡实现方案。无论是哪种类型,我们都需要获取想要访问的目标服务当前实例信息,这是实现远程调用和负载均衡进行整合的前提,也是我们在回答这类问题时的第一个要点。
回答这类问题的第二个要点在于,我们以什么样的技术手段完成在远程调用链路中自动嵌入负载均衡机制。从系统架构设计角度,这个嵌入过程应该对开发人员透明,且应该是可扩展的。在这点上,不同的实现框架有不同的策略,常见的包括两大类。
- 基于拦截机制:通过类似 AOP 的实现机制对请求进行拦截,再应用动态代理机制完成对负载均衡机制的嵌入。
- 基于集群机制:在集群构建过程中完成对负载均衡机制的嵌入。
最后,正如问题背景部分所阐述的,“如何在远程调用中集成负载均衡机制”这类话题考查的并不是概念,而是一种实践能力。我们通常不会自己去完成这个集成过程,但对于主流开源框架中的做法需要非常熟悉,否则很难从实现机制和过程上对这类问题进行解答。
技术体系
前面提到有两大类技术手段可以完成对远程调用和负载均衡的集成,事实上这也是 Spring Cloud 和 Dubbo 这两个主流分布式服务框架所采用的实现方式。本讲内容将讨论第一种,即拦截机制。关于集群机制的分析我们放在之后再展开。
如果我们采用拦截机制,那么整体的设计思想可以用下图进行展示:
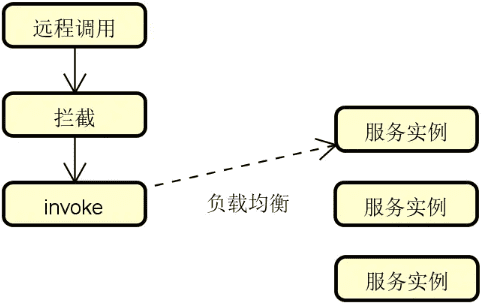
上图所展示的基本思想在于:当我们采用拦截机制对远程方法进行拦截时,并不是直接执行该方法中的业务逻辑,而是嵌入自定义的一套负载均衡机制。这套负载均衡机制能够获取当前所有可用的服务实例信息,并基于一定策略确定目标服务实例。这个过程对开发人员是透明的。
现实中,采用这种实现机制的代表性框架就是 Spring Cloud。如果你使用过 Spring Cloud,那你应该知道想要在服务调用过程中嵌入负载均衡机制,要做的事情只有一件,就是在 RestTemplate 模板工具类上添加一个 @LoadBalanced 注解,如下所示:
@LoadBalanced
@Bean
public RestTemplate getRestTemplate(){
return new RestTemplate();
}我们知道 RestTemplate 是 Spring 自带的一个 HTTP 请求工具类,本身并不具备负载均衡能力。讲到这里,你可能会觉得奇怪,为什么在这个工具类上添加了 @LoadBalanced 注解就能自动嵌入负载均衡机制呢?这个 @LoadBalanced 注解背后的工作原理又是怎么样的呢?为了回答这些问题,我们需要深入分析 Spring Cloud 的相关源码。
源码解析
让我们打开 Spring Cloud 源码,来到 spring-cloud-commons 这个代码工程,可以发现虽然这个工程的名称是 common,但内置了大量以 client 命名的代码包。这些代码包中就包含了与服务发现、负载均衡相关的所有基础类定义。我们要介绍的 @LoadBalanced 注解也位于这些代码包中。
接下来,让我们先从这个注解开始讲起。
Spring Cloud 中的 @LoadBalanced
事实上,在 Spring Cloud 中维护着一个 RestTemplate 模板工具类的列表,而在该列表上就嵌入了 @LoadBalanced 注解,如下所示:
@LoadBalanced
@Autowired(required = false)
private List<RestTemplate> restTemplates = Collections.emptyList();上述代码位于自动配置类 LoadBalancerAutoConfiguration 中。针对这些被 @LoadBalanced 注解修饰的 RestTemplate,在 LoadBalancerAutoConfiguration 初始化的过程中会调用 RestTemplateCustomizer 的 customize 方法进行定制化,这个定制化的过程就是对目标 RestTemplate 增加拦截器 LoadBalancerInterceptor,如下所示:
@Bean
@ConditionalOnMissingBean
public RestTemplateCustomizer restTemplateCustomizer(final LoadBalancerInterceptor loadBalancerInterceptor) {
return restTemplate -> {
List<ClientHttpRequestInterceptor> list = new ArrayList<>(restTemplate.getInterceptors());
list.add(loadBalancerInterceptor);
// 为 RestTemplate 添加拦截器
restTemplate.setInterceptors(list);
};
}这里就用到了 RestTemplate 的拦截器扩展机制。通过这种机制,我们可以在 RestTemplate 发送请求的过程中添加定制化的功能。从命名上看,这里的 LoadBalancerInterceptor 就是添加了负载均衡的拦截器,我们在它的构造函数中发现传入了一个 LoadBalancerClient,而在它的拦截方法中本质上就是使用这个 LoadBalanceClient 来执行真正的负载均衡,如下所示:
public class LoadBalancerInterceptor implements ClientHttpRequestInterceptor {
// ...
public LoadBalancerInterceptor(LoadBalancerClient loadBalancer) {
this(loadBalancer, new LoadBalancerRequestFactory(loadBalancer));
}
@Override
public ClientHttpResponse intercept(final HttpRequest request, final byte[] body, final ClientHttpRequestExecution execution) throws IOException {
final URI originalUri = request.getURI();
String serviceName = originalUri.getHost();
// 通过 LoadBalancerClient 执行负载均衡
return this.loadBalancer.execute(serviceName, requestFactory.createRequest(request, body, execution));
}
}这里的拦截方法 intercept 直接调用了 LoadBalancerClient 接口的 execute 方法完成对请求的负载均衡执行。而该方法的输入参数有两个,一个是代表服务名称的 serviceName,另一个则是代表负载均衡请求对象的 LoadBalancerRequest。而具体的 LoadBalancerRequest 则是如下所示的一个 ServiceRequestWrapper 包装类,如下所示:
public class ServiceRequestWrapper extends HttpRequestWrapper {
private final ServiceInstance instance;
private final LoadBalancerClient loadBalancer;
public ServiceRequestWrapper(HttpRequest request, ServiceInstance instance, LoadBalancerClient loadBalancer) {
super(request);
this.instance = instance;
this.loadBalancer = loadBalancer;
}
@Override
public URI getURI() {
URI uri = this.loadBalancer.reconstructURI(this.instance, getRequest().getURI());
return uri;
}
}可以看到,这里同样出现了 LoadBalanceClient,并用它来完成了请求地址 URI 的构建。显然,LoadBalanceClient 是我们分析负载均衡机制的核心入口。接下来,我们就对该接口及其实现类进行详细的展开。
LoadBalanceClient 接口与实现类
LoadBalancerClient 是一个非常重要的接口,定义如下:
public interface LoadBalancerClient extends ServiceInstanceChooser {
// 执行负载均衡调用
<T> T execute(String serviceId, LoadBalancerRequest<T> request) throws IOException;
// 执行负载均衡调用
<T> T execute(String serviceId, ServiceInstance serviceInstance, LoadBalancerRequest<T> request) throws IOException;
// 构建负载均衡调用 URI
URI reconstructURI(ServiceInstance instance, URI original);
}注意到这里有两个 execute 重载方法,用于根据负载均衡器所确定的服务实例来执行服务调用。而 reconstructURI 方法 则用于构建服务 URI,基于负载均衡所选择的 ServiceInstance 信息,并利用服务实例的 host、port 以及端点路径,我们就可以构造出一个真正可供访问的服务地址。
同时,我们发现 LoadBalancerClient 有一个父接口 ServiceInstanceChooser,该接口定义如下:
public interface ServiceInstanceChooser {
// 根据 serviceId 选择目标服务实例
ServiceInstance choose(String serviceId);
// 根据 serviceId 和请求选择目标服务实例
<T> ServiceInstance choose(String serviceId, Request<T> request);
}显然,从负载均衡角度讲,我们应该重点关注实际上是这两个 choose 方法的实现,因为它们完成了对目标服务实例的具体选择过程,而这个选择过程集成了各种负载均衡算法。
在 Spring Cloud 中,LoadBalancerClient 接口有一组实现类。我们接下来要介绍的是 Spring Cloud Netflix 中的 RibbonLoadBalancerClient 类,该类基于 Netflix Ribbon 组件实现了负载均衡机制,是 Spring Cloud 中最早、也是最经典的一种负载均衡实现方式。
这里有必要梳理一下 Netflix Ribbon 和 Spring Cloud 之间的关系。我们知道 Netflix Ribbon 是来自 Netflix 的一个外部组件,它提供的只是一个辅助工具,这个辅助工具的目的就是让你去集成它,而不是说它自己完成所有的工作。而 Spring Cloud 中的 Spring Cloud Netflix Ribbon 专门针对 Netflix Ribbon 提供了一个独立的集成实现。对于 Netflix Ribbon 而言,Spring Cloud Netflix Ribbon 相当于它的客户端,而对于 Spring Cloud Netflix Ribbon 而言,我们的应用服务相当于它的客户端。
Netflix Ribbon、Spring Cloud Netflix Ribbon、应用服务这三者之间的关系以及核心入口如下图所示:
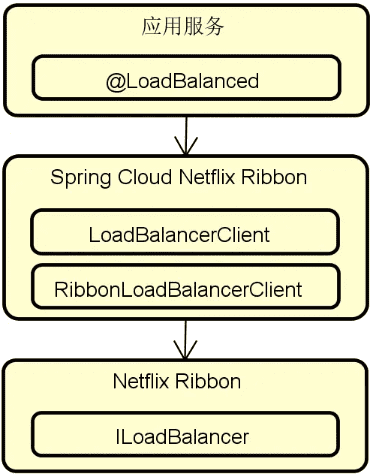
在 RibbonLoadBalancerClient 中,我们可以看到它的 choose 方法进一步调用了一个 getServer 方法来获取服务器信息,而这个 getServer 方法则是通过 ILoadBalancer 接口完成了对目标服务的选择,如下所示:
public ServiceInstance choose(String serviceId, Object hint) {
Server server = getServer(getLoadBalancer(serviceId), hint);
// ...
}
protected Server getServer(ILoadBalancer loadBalancer, Object hint) {
// ...
return loadBalancer.chooseServer(hint != null ? hint : "default");
}这个 ILoadBalancer 就来自于 Netflix Ribbon,该接口位于 com.netflix.loadbalancer 包下,定义如下:
public interface ILoadBalancer {
// 添加后端服务
public void addServers(List<Server> newServers);
// 选择一个后端服务
public Server chooseServer(Object key);
// 标记一个服务不可用
public void markServerDown(Server server);
// 获取当前可用的服务列表
public List<Server> getReachableServers();
// 获取所有后端服务列表
public List<Server> getAllServers();
}针对负载均衡,我们应该重点应该关注的是 ILoadBalancer 接口中 chooseServer 方法的实现,如下所示:
public Server chooseServer(Object key) {
if (counter == null) {
counter = createCounter();
}
counter.increment();
if (rule == null) {
return null;
} else {
try {
return rule.choose(key);
} catch (Exception e) {
return null;
}
}
}可以看到这里使用了一个 IRule 接口集成了具体负载均衡策略的实现。IRule 接口是对负载均衡策略的一种抽象,可以通过实现这个接口来提供各种负载均衡算法,该接口的类层结构如下图所示:
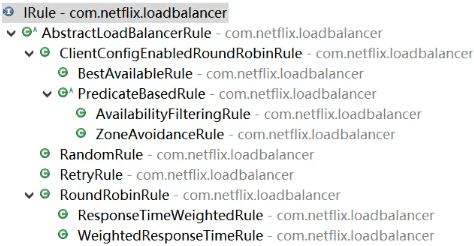
可以看到 Netflix Ribbon 中的负载均衡实现算法非常丰富,既提供了 RandomRule、RoundRobinRule 等无状态的静态算法,又实现了 AvailabilityFilteringRule、WeightedResponseTimeRule 等多种基于服务器运行状况进行实时路由的动态算法。关于这些负载均衡算法的讨论我们放在下一讲中。
在上图中还看到了 RetryRule 这种重试策略,该策略会对选定的负载均衡策略执行重试机制。严格意义上讲,重试是一种服务容错而不是负载均衡机制,但 Ribbon 也内置了这方面的功能。
事实上,我们也可以基于 IRule 接口实现任何定制化的负载均衡算法,然后通过配置的方式加载到 Spring Cloud 中,示例代码如下所示:
@Configuration
public class LoadBalanceConfig{
@Autowired
IClientConfig config;
@Bean
@ConditionalOnMissingBean
public IRule customRule(IClientConfig config) {
return new RandomRule();
}
}显然该配置类的作用是使用 RandomRule 替换 Ribbon 中的默认负载均衡策略 RoundRobin。
解题要点
关于负载均衡和远程调用的整合过程是一道经典的面试题,理论知识和工程实践都有涉及,我经常拿这道题来考察候选人。就考查内容而言,这道题所涵盖的知识面要求很广,需要面试者对负载均衡、远程调用以及主流的分布式服务框架本身的功能特性都有一定的了解。
而从提问方式上讲,这个面试主题往往会直接从具体的工具框架的特性进行切入,考查面试者对框架原理的理解,正如本讲中重点介绍的 Spring Cloud 和 @LoadBalanced 注解。乍一看,这类面试题感觉无从下手,因为 @LoadBalanced 注解在使用过程中并没有提供太多的配置项供开发人员进行设置,我们也就很难联想到其背后所具备的负载均衡机制。
但事实上,在这个注解背后隐藏着一个很重要的技术组件,即拦截器。通过在某一个注解中添加拦截功能,然后把一些非功能性需求通过拦截器进行实现,这是 Spring 等优秀开源框架中所经常使用的一种开发技巧,也是面试官考查面试者对开源框架理解能力的一个常见维度。在回答这道面试题时,我们就需要从拦截器的角度出发,把 RestTemplate 和 Ribbon 组件结合起来进行分析。至于负载均衡算法本身,反而不是这道面试题考查的重点,我们只要点到即可。
小结与预告
通过今天内容的介绍,我们明确作为一款负载均衡工具,要做的事情无非是从服务列表中选择一个服务进行调用。为了实现这个过程,我们需要提供入口供客户端请求进行使用。而 Spring Cloud 为我们提供了一种非常友好的实现方式,开发人员只需要通过一个简单的 @LoadBalanced 注解就能自动在调用过程中集成负载均衡机制。今天的内容对 @LoadBalanced 注解以及背后的整个负载均衡实现流程做了原理分析。通过这种方式,我们也加深了对“如何在远程调用中集成负载均衡机制”这个问题的理解程度。
在前面的内容中,我们已经看到 Spring Cloud 内置了一组丰富的负载均衡算法,而这些负载均衡算法能够根据需要帮助我们自动找到最佳的目标服务。事实上,任何一款分布式服务框架都提供了各种不同类型的负载均衡算法供开发人员进行选择。那么,如何实现这些常见的负载均衡算法?这就是下一讲要讨论的内容。
负载均衡:如何实现常见的负载均衡算法?
上一讲我们分析了在远程调用过程中整合负载均衡机制的实现过程。在这种场景下,我们将多个服务实例集中在一起,每一次请求都可以由集群中的某一个服务实例进行响应。
那么,具体某一个请求到底应该是由哪个服务实例来响应最为合适呢?这个话题看上去很简单,实际上却有点复杂,涉及到服务请求的路由机制。
而在分布式系统中,上一讲中引入的负载均衡就是最常见也是最具代表性的一种路由机制。为了对请求进行合理的分发,我们需要提供一组负载均衡算法,那么常见的负载均衡算法有哪些?它们又应该如何实现呢?这是一道非常典型的面试题,本讲内容将围绕这一主题展开讨论。
问题背景
我们先来看这个问题背后的示意图,如下图所示:
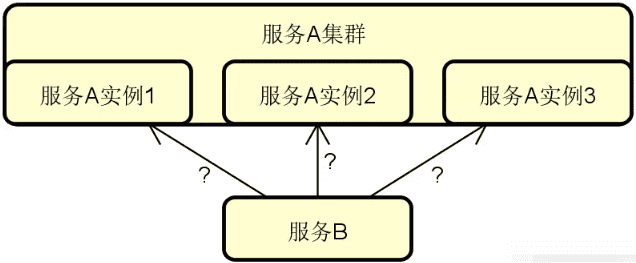
显然,我们需要明确从服务 B 发出的请求最终会由服务 A 所提供的具体哪一个实例来进行处理,这是负载均衡算法的作用。上图所示的基本架构虽然简单,但围绕该图,我们可以延伸出一系列的扩展性话题,包括:
- 负载均衡算法应该位于上图中的哪个位置?是在服务 B 中,还是应该有专门存储这些算法的其他组件?
- 服务 A 的某个实例如果出现了问题,服务 B 还能对它进行访问吗?
- 服务 A 各个实例的当前负载肯定不一样,服务 B 基于什么原则选择最合适的目标实例呢?
- 如何防止对服务 A 实例的访问过程是不均衡的,从而导致服务 A 的某个实例压力太大?
这些扩展性话题才是面试官想要真正考查的知识点,而对于这些知识点的掌握程度也体现了你和其他候选人之间的水平差异。
我们可以沿着面试官的考查思路,梳理一组与负载均衡算法相关的一组常见面试题,包括:
- 从你自己所理解的角度出发,你认为负载均衡算法可以分成哪些类型?
- 如果想要在常见的静态负载均衡算法中嵌入动态特性,你有什么思路?
- 你能列举常见的负载均衡算法以及它们的特性吗?
- Dubbo 包含了哪些负载均衡算法?
- Spring Cloud 内置了哪些负载均衡算法?
- Dubbo 框架在实现负载均衡机制时提供了哪些优化特性?
- 一致性哈希算法的实现过程是怎么样的?
可以看到,针对负载均衡算法的提问形式灵活多样。面试官既可以考查一些基本概念,也可以抛出一些发散性问题。同时,针对具体框架中负载均衡算法的实现方式也会经常出现在面试题中。
问题分析
对于上述问题而言,我认为回答的思路还是比较明确的,主要就是对主流负载均衡算法需要有全面的了解。这部分属于理论知识,考查方式比较固定,很难有创新和变化,应对策略上主要以记忆为主。相比到目前为止我们已经介绍的各讲内容,可以说,针对负载均衡算法的回答方式是最直接的。
然后,无论你现在使用的是哪种分布式服务框架,都需要把它与常见的负载均衡算法结合起来进行掌握。在面试过程中,你可以基于自己擅长的框架来分析具体的算法实现过程。同时,很多时候我们也需要结合上一讲中讨论的话题,把负载均衡算法与远程调用过程结合起来一起讨论。
技术体系
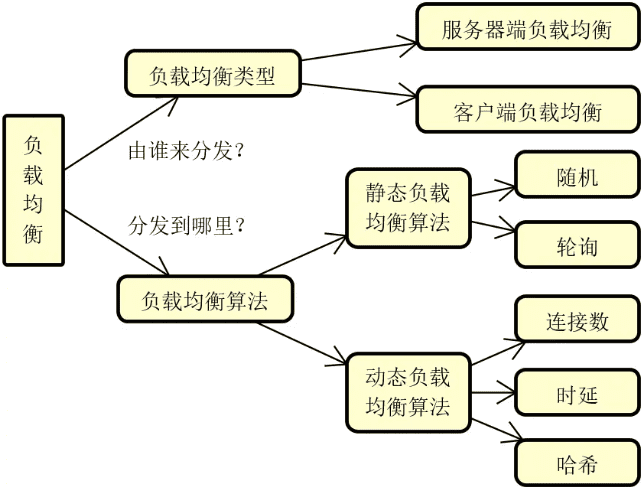
在进行具体的工具介绍和源码分析之前,我们首先对负载均衡的类型以及相应的基本策略做简要介绍。
负载均衡的类型
负载均衡主要包括服务器端负载均衡和客户器端负载均衡两大类。我们先来看服务器端负载均衡,它的结构如下图所示:
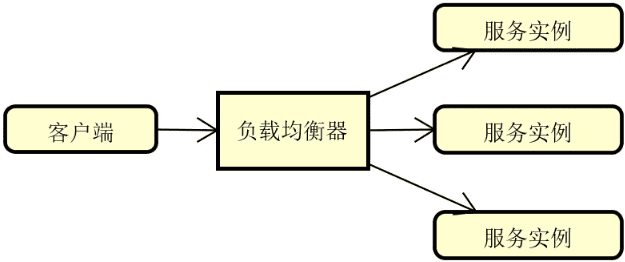
可以看到,所谓的服务器端负载均衡指的就是在客户端和各个服务实例之间存在一个独立的负载均衡器,所有的请求都将通过这个负载均衡器进行转发并嵌入负载均衡算法。业界关于这种负载均衡器的实现工具也很多,最常见的就是 Nginx。
我们换一种思路,把上图中负载均衡器所具备的功能放到客户端中,那么就诞生了另一种负载均衡机制,即客户端负载均衡。这时候,负载均衡算法的执行流程发生在客户端本地,如下图所示:
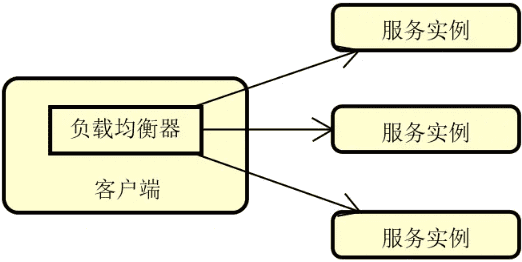
客户端负载均衡应用广泛,例如目前主流的微服务架构实现框架 Spring Cloud、Dubbo 等都内置了完整的客户端负载均衡模块。而像老牌的分布式缓存 Memcache 同样也是这一负载均衡策略的典型应用。
我们来对上述这两种负载均衡机制做一个对比,会发现客户端负载均衡不需要架设专门的服务器组件,负载均衡算法的执行过程被分摊到了每个客户端内部,不会造成明显的单点瓶颈。当然,因为每个客户端自己都需要维护一套服务实例信息,所以需要确保服务实例的变更能够及时通知到各个客户端。
负载均衡算法和策略
无论使用哪种负载均衡机制,负载均衡算法决定了最终的请求分发效果。常见的负载均衡算法也可以分成两大类,即静态负载均衡算法和动态负载均衡算法。
静态负载均衡
对于静态负载均衡而言,经典的算法包括各种随机(Random)和轮询(Round Robin)算法。
-
随机算法
随机算法是最简单也是最常用的负载均衡算法之一,该算法就是使用一个随机数来决定具体的目标服务实例。
假设我们持有一个保存所有服务的 serverList 列表,那么只用 JDK 中自带的 Random 工具类就可以实现一个基本的随机算法,如下所示:
java.util.Random random = new java.util.Random(); int randomPosition = random.nextInt(serverList.size()); return serverList.get(randomPosition);随机算法足够简单,但有时候并不能满足我们的需求。例如,如果在集群中存在一些性能有差异的服务器,为了充分利用那些高性能的服务器,可以提升这些服务器的访问权重,这时候就可以引入用加权随机(Weight Random)算法。
假设存在一个 serverWeightMap 保存着服务器地址与权重之间的对应关系,类似
("192.168.10.100", 1)、("192.168.10.105", 3)这样的结构,那么实现加权随机的一种简单策略就是构建一个新的 serverList 列表,并根据服务权重的数量来添加重复数量的服务提供者地址(这样权重越高的服务被选中的概率就会越大),然后再使用随机算法进行选择,示例代码如下所示:Set<String> keySet = serverWeightMap.keySet(); Iterator<String> iterator = keySet.iterator(); List<String> serverList = new ArrayList<String>(); while (iterator.hasNext()) { String server = iterator.next(); int weight = serverWeightMap.get(server); for (int i = 0; i < weight; i++) { serverList.add(server); } } java.util.Random random = new java.util.Random(); int randomPosition = random.nextInt(serverList.size()); return serverList.get(randomPosition); -
轮询算法
所谓轮询,就是一个循环访问所有服务器列表的过程。在循环过程中,如果发现某台服务器可用就把请求分发给它。如果一个循环下来还是没有找到合适的服务器,那么就继续进行新的一轮循环,直到找到目标服务器。
轮询算法的一种简单的实现方法如下所示:
String server = null; synchronized(position) { if (position > serverList.size()) { position = 0; } server = serverList.get(position); position++; } return server;类似加权随机算法,我们也可以实现加权轮循(Weighted Round Robin)算法。
动态负载均衡算法
对于负载均衡算法而言,权重本质上也是一个可以动态变化的参数,所以也可以基于权重构建动态负载均衡算法。
典型的动态负载均衡算法实现过程都没有那么简单,常见的包括最少连接数算法、源 IP 哈希算法、服务调用时延算法等。
-
最少连接数算法
所谓最少连接数(Least Connection)算法,就是根据当前服务器的连接数量来决定目标服务器。在系统运行过程中,连接数显然是一个不断在变化的参数,我们可以选择那些连接数较少的服务来接收新的请求。
因此,当执行分发策略时,我们会根据在某一个特定的时间点下服务实例的最新连接数来判断是否执行客户端请求。而在下一个时间点时,服务实例的连接数一般都会发生相应的变化,对应的请求处理也会做相应的调整。
-
源 IP 哈希算法
在日常开发过程中,有时候我们希望实现这样一种分发效果:来自同一个客户端的请求总是发送到某一个固定的服务器,这时候就可以引入源 IP 哈希(Source IP Hash)算法,该算法会根据请求的 IP 地址来决定目标服务器。只要源 IP 地址不变,那么负载均衡的结果也是固定的。
源 IP 哈希算法一种实现方案如下所示:
String remoteIp = getRemoteIp(); int hashCode = remoteIp.hashCode(); int serverListSize = serverList.size(); int serverPos = hashCode % serverListSize; return serverList.get(serverPos); -
服务调用时延算法
服务调用时延(Service Invoke Delay)算法的动态性来自于服务的调用延迟。针对每一台服务器,我们都可以计算一段时间内所有请求的服务调用时延。有了这个参数之后,就可以执行各种计算策略进一步决定选择哪一台服务器来对请求做出响应。
针对前面介绍的各个负载均衡算法,我们可以通过如下所示的一张思维导图来进行总结:
源码解析
有了理论知识,我们接下来讨论负载均衡的实际应用。诸如最少连接数算法、服务调用时延算法等动态负载均衡算法在设计和实现上都比较复杂,我们重点来看一下主流开源框架中对它们的实现机制。在接下来的内容,我们以 Dubbo 框架为例展开讨论。
Dubbo 负载均衡整体结构
在 Dubbo 中,专门提供了一个 LoadBalance 接口来提供负载均衡能力,如下所示:
@SPI(RandomLoadBalance.NAME)
public interface LoadBalance {
@Adaptive("loadbalance")
<T> Invoker<T> select(List<Invoker<T>> invokers, URL url, Invocation invocation) throws RpcException;
}可以看到 LoadBalance 接口只有一个方法,即在一批 Invoker 列表中选择其中一个 Invoker 进行返回。这里,我们可以从该接口上的 @SPI(RandomLoadBalance.NAME) 注解中看到 Dubbo 默认加载的是 RandomLoadBalance 类,即随机负载均衡。除了 RandomLoadBalance 类之外,Dubbo 还提供了其他多种负载均衡策略,整体的类层结构如下图所示:
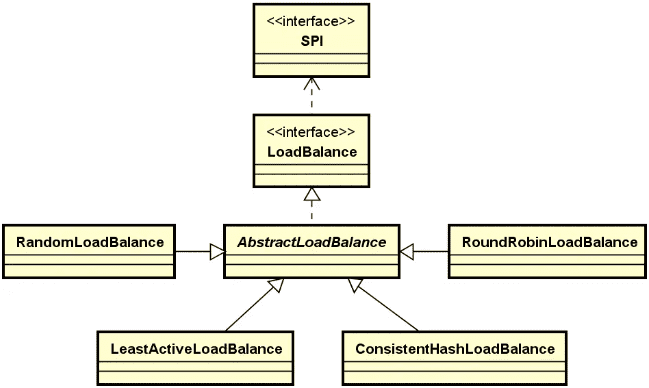
从上图中,我们看到存在一个 AbstractLoadBalance 抽象类,它实现了 LoadBalance 的 select 方法,如下所示:
public <T> Invoker<T> select(List<Invoker<T>> invokers, URL url, Invocation invocation) {
if (invokers == null || invokers.size() == 0)
return null;
if (invokers.size() == 1)
return invokers.get(0);
return doSelect(invokers, url, invocation);
}显然,从设计模式上讲,这里采用的是经典的模板方法。通过模板方法,具体负载均衡算法由 AbstractLoadBalance 子类中的 doSelect 方法进行实现。
同时,我们在 AbstractLoadBalance 中还看到了如下所示的 getWeight 方法。从方法命名上看,该方法用来计算权重,如下所示:
protected int getWeight(Invoker<?> invoker, Invocation invocation) {
// 从 URL 中获取权重
int weight = invoker.getUrl().getMethodParameter(invocation.getMethodName(), Constants.WEIGHT_KEY, Constants.DEFAULT_WEIGHT);
if (weight > 0) {
long timestamp = invoker.getUrl().getParameter(Constants.REMOTE_TIMESTAMP_KEY, 0L);
if (timestamp > 0L) {
int uptime = (int) (System.currentTimeMillis() - timestamp);
// 从 URL 中获取预热时间
int warmup = invoker.getUrl().getParameter(Constants.WARMUP_KEY, Constants.DEFAULT_WARMUP);
if (uptime > 0 && uptime < warmup) {
// 计算预热权重
weight = calculateWarmupWeight(uptime, warmup, weight);
}
}
}
return weight;
}可以看到代表权重的 weight 参数是从 URL 中传入的。而基于上述代码,我们发现这里的处理逻辑显然并没有那么简单,而是用到了所谓的预热(Warmup)机制。我们看到 Dubbo 首先会获取服务启动时间,然后再与预热时间进行比较。如果启动时间小于预热时间,则会调用 calculateWarmupWeight 方法来重新计算预热权重。
从代码逻辑上看,预热权重最小为 1,并在预热时间内随启动时间逐渐增加。这样设计的原因在于:JVM 从启动成功到处于最佳状态需要一段时间,在这段时间内虽然服务可以接收请求,但显然不应该接收过多请求。所以,Dubbo 通过预热机制确保在预热时间内该服务受到一定的保护,直到其处于最佳运行状态。
预热机制在 Dubbo 的多个负载均衡算法中都得到了应用,是一种实现上的技巧,为我们设计类似的应用场景提供了一定的参考价值。
Dubbo 负载均衡算法实现示例
接下来,就让我们看看 Dubbo 中使用预热机制的场景和方式。我们重点介绍 LeastActiveLoadBalance 类,这是一种典型的动态负载均衡算法。
LeastActiveLoadBalance 继承自 AbstractLoadBalance 类,并实现了如下所示的 doSelect 方法。该方法比较长,我们对代码进行了部分裁剪。
@Override
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
// 获取所有的 invoker 并执行计算
for (int i = 0; i < length; i++) {
Invoker<T> invoker = invokers.get(i);
// 通过 RpcStatus 获取当前这个 invoker 并发数
int active = RpcStatus.getStatus(invoker.getUrl(), invocation.getMethodName()).getActive();
// 通过预热机制计算权重值
int afterWarmup = getWeight(invoker, invocation);
// 发现最小的活跃数,重新开始计算
if (leastActive == -1 || active < leastActive) {
// 记录 leastActive 为当前的活跃数,并重置最小计数,基于当前最小计数重新计数
// …
} else if (active == leastActive) {
// 当前 invoker 的活跃数与最小活跃数相等,则记录权重
// …
}
}
// 如果我们恰好有一个调用程序具有最少的活动值,那么直接返回这个调用程序
if (leastCount == 1) {
return invokers.get(leastIndexs[0]);
}
// 如果每个 invoker 有不同的权重
if (!sameWeight && totalWeight > 0) {
// 在总权重范围内随机一个值
int offsetWeight = random.nextInt(totalWeight) + 1;
for (int i = 0; i < leastCount; i++) {
// 获取 i 位置的那个最小活跃在 invokers 里面的位置信息
int leastIndex = leastIndexs[i];
offsetWeight -= getWeight(invokers.get(leastIndex), invocation);
if (offsetWeight <= 0) {
// 返回这个位置
return invokers.get(leastIndex);
}
}
}
// 具有相同权重或者是总权重 = 0 的话就均匀返回
return invokers.get(leastIndexs[random.nextInt(leastCount)]);
}在上述代码中,我们对关键流程添加了注释。该算法首先会对所有的 Invoker 进行轮询,找出所有活跃数最小的集合。如果这个集合的数量只有 1,那么就可以直接返回当前的 Invoker。如果集合中所有 Invoker 的权重相同,那么随机返回一个。而如果这些条件都不满足,那么就获取一个具有最小活跃数的 Invoker。
为了实现扩展性,Dubbo 提供了 SPI 机制,允许开发人员自定义负载均衡算法,我们会在后面介绍微内核架构和 SPI 机制时给出一个简单的案例。你也可以根据自己的需要尝试实现新的负载均衡算法。
解题要点
在分布式系统面试中,负载均衡是一道高频面试题。针对常见的负载均衡算法以及它们的特性,面试官考查的是候选人对分布式系统基本概念的理解。因为负载均衡的各种算法以及特性相对固定,所以这类题的考点是非常明确的。
在回答这类面试题时,需要把握两点。首先,我们要介绍负载均衡算法的分类,即静态负载均衡和动态负载均衡。其次,我们需要列举常见负载均衡算法,并基于自己的理解分析这些算法的功能特性。针对随机、轮询等静态负载均衡算法,我们的回答思路是给出基本的设计策略和所能达到的效果,以及如何将这些静态负载均衡算法转换为动态负载均衡算法的实现方法。因为静态负载均衡算法相对都比较简单,所以这部分内容不是回答的重点。我们需要详细介绍的是一致性哈希、最少连接数等动态负载均衡的实现原理。
另一方面,关于负载均衡算法的考查,基于具体开源框架内部的实现细节进行提问也是另一种比较常见的方式。例如,如果被问到类似 Dubbo 框架在实现负载均衡机制时提供了哪些优化特性? 这样的问题,回答起来是有难度的,因为它考查的并不仅仅是对 Dubbo 中所提供的负载均衡算法的描述,而更多的是问到了框架的底层设计思想和实现原理,需要面试者对 Dubbo 的源码有较深程度的理解,并能抓住细节。在回答上,就需要提到 Dubbo 中的“预热”机制,该机制的目的是确保服务在刚启动的一段时间内得到保护,避免因为负载均衡导致出现不可用的情况。在回答这道题时,这些内容背后的设计思想都应该被介绍到。
小结与预告
本讲内容梳理了分布式系统开发过程中所采用的负载均衡算法。在 Spring Cloud 中所实现的核心负载均衡算法包括随机、轮询、加权响应时间、并发量最小优先等,而 Dubbo 中则提供了随机、轮询、最少活跃调用数和一致性哈希等算法。可以看到,这两个框架在实现主流算法的同时,也根据框架自身的特点提供了一些比较有特色的策略。当然,这两个框架也都内置了扩展入口供开发人员实现自定义的负载均衡算法。
在介绍完负载均衡之后,我们接下来要进入到“服务容错”这一技术组件的讨论。服务容错的实现方式有很多,其中集群的构建为容错机制提供了天然的基础。那么,什么是集群容错?现实中又有哪些常见的集群容错策略呢?下一讲将对这些问题展开详细的分析。
服务容错:什么是集群容错?有哪些集群容错策略?
在前面两讲内容中,我们对远程过程调用中的负载均衡机制进行了详细的讨论。而在介绍负载均衡的实现策略时,我们也提到了集群这一概念。集群的构建一方面能够为实现负载均衡提供基础,另一方面,它也能够有效应对服务访问出错的场景,这就是集群容错。
在分布式系统运行过程中,远程调用发生失败的现象不可避免。为了应对服务访问失败,集群容错是一种简单高效的技术组件。
那么,什么是集群容错?常见的又有哪些集群容错策略呢?这一话题也是分布式服务相关的一道高频面试题,本讲内容将对这一主题展开全面的讨论。
问题背景
在分布式系统中,对于服务提供者和消费者而言实际上存在一种依赖关系。一方面,每个服务自身可能会发生异常情况,更为重要的,这种依赖关系会导致系统中的其他服务也发生调用失败,如下图所示:
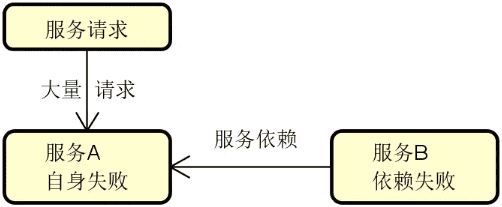
那么问题就来了,一旦出现上图中的失败场景,我们有什么应对策略呢?这是开发任何一个分布式系统必须要考虑的问题,也是面试官非常喜欢考查的一个问题。
就技术体系而言,我们可以把应对远程调用失败场景的各种手段和方法统称为服务容错(Fault Tolerance),而集群容错是服务容错的其中一种实现方式。我们知道,所谓集群,就是同时存在一个服务的多个实例。一旦我们访问其中一个实例出现问题,原则上可以访问其他实例来获取结果。
围绕这个过程,技术上有很多值得面试官考查的点,包括:
- 如何判断集群中当前有哪些服务实例是不可用的?
- 如果某一个服务实例不可用,选择下一个服务实例的策略有哪些?
- 如果访问所选择的下一个服务实例仍然失败,我们应该怎么做?
- 为了快速判断集群中某个服务是否存在可用的示例,有什么办法?
当然,和负载均衡一样,主流的分布式服务框架也都内置了集群容错机制。例如 Dubbo 框架就包含一组非常常用的集群容错实现策略。在面试过程中,针对具体框架中集群容错的底层实现原理进行讨论的场景并不少见。
问题分析
对于集群容错,我们首先还是有必要分析远程调用发生依赖失败的影响,或者说我们需要引入集群容错机制的原因,这里就引出一个非常适合作为面试话题来展开的概念,即 雪崩效应(Avalanche Effect)。雪崩效应是我们引入容错思想和模式的根本需求。以我的面试经历而言,雪崩效应在分布式系统相关面试场景中出现的频次比较高,在介绍具体容错机制之前,先来对这个概念进行展开有助于提升候选人给到面试官的第一印象。
回答这一问题的第二个要点是对集群容错的各种实现策略的详细分析。这部分内容属于理论知识体系,需要进行记忆。幸好常见的集群容错实现策略并不是很多,因此掌握起来并不困难。
最后,我们还是需要理论联系实际。集群容错的几种代表性实现策略在 Dubbo 等主流的开源框架都有体现。在面对面试官时,基于具体的框架底层实现原理来展示自己对集群容错机制的掌握程度无疑是一种加分项。
技术体系
正如前面提到的,服务依赖失败是我们在设计分布式系统时所需要重点考虑的服务可用性问题,因为服务依赖失败会造成失败扩散,从而形成服务访问的雪崩效应。让我们先从这个过程开始讲起。
雪崩效应
下图展示了雪崩效应的示意图,可以看到 A、B、C、D、E 这 5 个服务存在依赖关系,服务 A 为服务提供者,服务 B 为服务 A 的消费者,服务 C、D 和 E 则是服务 B 的消费者。现在,假如服务 A 变成不可用,就会引起服务 B 的不可用,并将这种不可用性逐渐扩散到服务 C、D 和 E 时, 从而造成了整个服务体系发生雪崩。
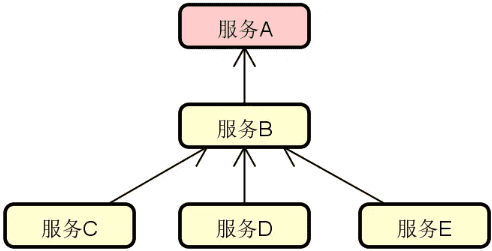
服务雪崩的产生是一种扩散效应,我们可以对上图中的现象进行剥离,先从服务 A 和服务 B 这两个服务之间的交互进行切入。下图展示了雪崩效应产生的三个阶段,即首先服务提供者 A 发生不可用,然后服务消费者 B 不断进行重试加大了访问流量,最后导致服务 B 自身也不可用。
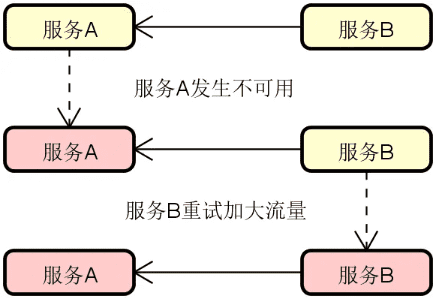
在上图中,通过用户不断提交服务请求或代码逻辑自动重试等手段,服务 B 会进一步加大对服务 A 的访问流量。因为服务 B 使用同步调用,会产生大量的等待线程占用系统资源。一旦线程资源被耗尽,服务 B 本身也将处于不可用状态。这一过程在整个服务访问链路上进行扩散,就形成了雪崩效应。
显然,应对雪崩效应的切入点不在于服务提供者,而在于服务消费者。我们不能保证所有服务提供者都不会失败,但是我们要想办法确保服务消费者不受已失败的服务提供者的影响,或者说需要将服务消费者所受到的这种影响降到最低,这就是服务容错的本质需求。而集群容错可以很好地应对这一需求。
集群容错的策略
在上一讲中,我们已经介绍了集群和客户端负载均衡,从服务容错的角度讲,负载均衡不失为是一种可行的容错策略。而我们今天要介绍的集群容错则是在负载均衡的基础上添加了各种容错策略,包括常见的 Failover(失效转移)、Failback(失败通知)、Failsafe(失败安全)和 Failfast(快速失败) 以及不大常见的 Forking(分支)和 Broadcast(广播) 等。我们一一来看一下。
Failover 是最常见、最实用的集群容错策略。Failover 即失效转移,当发生服务调用异常时,重新在集群中查找下一个可用的服务实例。为了防止无限重试,通常对失败重试最大次数进行限制,如下图所示:

相较 Failover,Failback 则采用了不同的实现方式,它会记录每一次失败的请求,然后再基于一定的策略执行重试操作。显然,这种容错策略适合于那种时效性不高的操作,常见的包括发送短信等消息通知类业务。
Failsafe 的意思是失败安全,该策略并不会对所发生的异常做直接的干预,而是将它们记录下来,确保后续可以根据日志记录找到引起异常的原因并解决。
还有一种比较容易混淆的策略称为 Failfast,该策略在获取服务调用异常时立即报错。显然,Failfast 已经彻底放弃了重试机制,等同于没有容错,一般用于非幂等性的写入操作。另一方面,在特定场景中可以使用该策略确保非核心业务服务只调用一次,为重要的核心服务节约宝贵时间。
以上三种集群容错策略之间的区别可以参考下图:
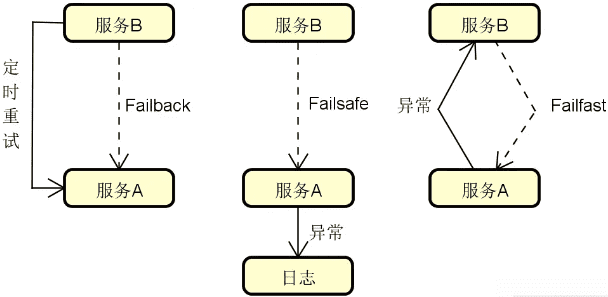
除了这些常见的集群容错机制之外,在一些分布式服务框架中,还实现了一些特殊的策略,例如提供分支调用机制的 Forking 策略和提供广播机制的 Broadcast 策略。这些策略的使用场景比较少,这里不做具体展开。
源码解析
Dubbo 中的集群
服务容错的实现方法和策略有很多,我们接下来重点讨论 Dubbo 中主要采用的集群容错实现策略和底层原理。
Dubbo 中的整个集群结构如下图所示。这张图比较复杂,涉及到 Dubbo 中关于集群管理和服务调用的诸多概念。为了讨论集群容错,我们必须首先理解这种图中的相关概念,进而把握 Dubbo 对集群的抽象。
上图展现了 Dubbo 中的几个重要技术组件,我们一一来展开。
- Invoker:在 Dubbo 中,Invoker 是一个核心概念,代表的就是一个具体的可执行对象。
- Directory:即目录,代表一个集合,内部包含了一组 Invoker 对象。
- Router:即路由器,根据路由规则在一组 Invoker 中选出符合规则的一部分 Invoker。
- LoadBalance:即负载均衡,对经过 Router 过滤之后的一部分 Invoker 执行各种负载均衡算法,从而确定一个具体的 Invoker。
- Cluster:即集群,从 Directory 中获取一组 Invoker,并对外伪装成一个 Invoker。这样,我们在使用 Cluster 时就像是在使用一个 Invoker 一样,而在这背后则隐藏了容错机制。
基于上述分析,今天内容所要介绍的重点是 Cluster。我们首先来看看 Dubbo 中 Cluster 接口的定义,该接口只包含一个 join 方法,如下所示:
@SPI(FailoverCluster.NAME)
public interface Cluster {
@Adaptive
<T> Invoker<T> join(Directory<T> directory) throws RpcException;
}Cluster 接口中包含另一个与集群相关的重要概念,即前面提到的 Directory。Directory 本质上代表多个 Invoker,我们需要知道可以通过它获取一个有效 Invoker 的列表。
换一个角度,Dubbo 中的 Cluster 也相当于是一种代理对象,它在 Directory 的基础上向开发人员暴露一个具体的 Invoker,而在暴露这个 Invoker 的过程中,万一发生了异常情况,Cluster 就会自动嵌入集群容错机制。那么,Cluster 是如何做到这一点的呢?
在 Dubbo 中,实际上提供了一组不同类型的 Cluster 对象,而每一个 Cluster 对象就代表着一种具体的集群容错机制,如下图所示:
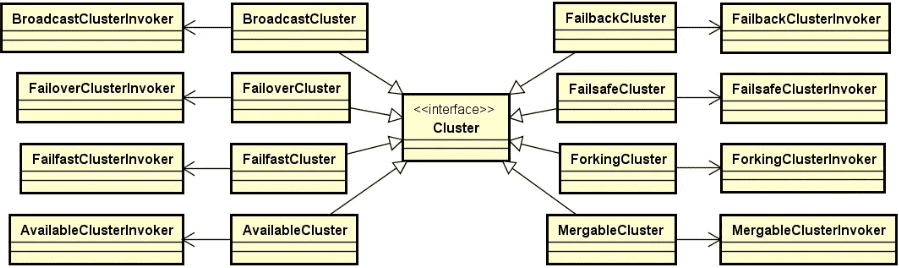
上述方案中,Dubbo 默认使用的是 FailoverCluster。我们来看一下这个默认实现,如下所示:
public class FailoverCluster implements Cluster {
public final static String NAME = "failover";
public <T> Invoker<T> join(Directory<T> directory) throws RpcException {
return new FailoverClusterInvoker<T>(directory);
}
}可以看到该类非常简单,join 方法只是根据传入的 Directory 构建一个新的 FailoverClusterInvoker 实例。而查看其他的 Cluster 接口实现,可以发现它们的处理方式与 FailoverCluster 类似,都是返回一个新的 Invoker。
Dubbo 中的集群容错机制
显然,想要理解 Dubbo 中的集群容错机制,重点是要分析上图中所示的各种 ClusterInvoker 对象。
这里,我们同样选择默认的 FailoverClusterInvoker 作为分析入口。在深入 FailoverClusterInvoker 之前,我们发现该类存在一个基类,即 AbstractClusterInvoker,而 AbstractClusterInvoker 又实现了 Invoker 接口,它们之间的关系如下图所示:
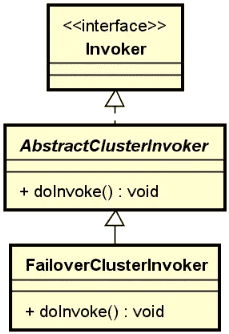
从设计模式角度讲,AbstractClusterInvoker 采用的是很典型的模板方法设计模式。模板方法设计模式的一般实现过程就是为整个操作流程提供一种框架代码,然后再提取抽象方法供子类进行实现。上图中就展示了模板方法的设计思想。
AbstractClusterInvoker 的实现逻辑也是类似,它的主要步骤包括从 Directory 获得 Invoker 列表、基于 LoadBalance 实现负载均衡,并基于 doInvoke 方法完成在远程调用中嵌入容错机制。
这里的 doInvoke 就是模板方法,需要 FailoverClusterInvoker 等子类分别实现,如下所示:
public abstract class AbstractClusterInvoker<T> implements ClusterInvoker<T> {
protected abstract Result doInvoke(Invocation invocation, List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException;
}AbstractClusterInvoker 类的代码有点长,但理解起来并不是很复杂。通过观察该类中的代码实现,可以看到存在一批以 select 结尾的方法,包括 select、doselect、reselect 以及 LoadBalance 本身的 select 方法。我们基于这些 select 方法梳理整体的处理流程,并给出如下所示的伪代码:
select() {
checkSticky(); // 粘滞连接
doselect() {
loadbalance.select();
reselect() {
loadbalance.select();
}
}
}上述伪代码清晰展示了这些 select 方法的嵌套过程,从而能够更好地帮助你梳理代码执行流程。
首先,select 方法的第一部分内容提供了 粘滞连接 机制。所谓粘滞连接(Sticky Connection),就是为每一次请求维护一个状态,确保始终由同一个服务提供者对来自同一客户端的请求进行响应。这点和我们在上一讲中提到的源 IP 哈希负载均衡算法比较类似,你可以做一些回顾。在 Dubbo 中,使用粘滞连接的目的是减少重复创建连接的成本,提高远程调用的效率。我们可以通过 URL 传入的 sticky 参数对该行为进行控制。
处理完粘滞连接之后,select 方法就借助于 doselect 方法执行下一步操作。doselect 方法执行了一系列的判断来最终明确目标 Invoker 对象。首先,我们需要判断当前是否存在可用的 Invoker 对象,如果没有则直接返回。如果有,那么就分如下几种情况:
- 如果只有一个 Invoker 对象,那么该 Invoker 对象就是目标 Invoker 对象;
- 如果有两个 Invoker 对象,则使用轮询机制选择其中一个进行返回;
- 如果有两个以上的 Invoker 对象,这时候就会借助于 LoadBalance 的 select 方法,通过负载均衡算法来最终确定一个目标 Invoker 对象。
下图展示了这个执行过程:
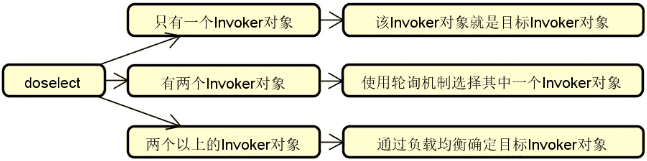
在获取了目标 Invoker 对象之后,Dubbo 并不会直接就使用这个对象,因为我们需要考虑该对象的可用性。如果该 Invoker 对象不可用或者已经使用过,那么就需要通过 reselect 方法重新进行选择。而如果在 Invoker 列表中已经没有可用的 Invoker 对象了,那么也就只能直接使用当前选中的这个 Invoker 对象。下图进一步展示了 Invoker 对象的可用性判断逻辑:
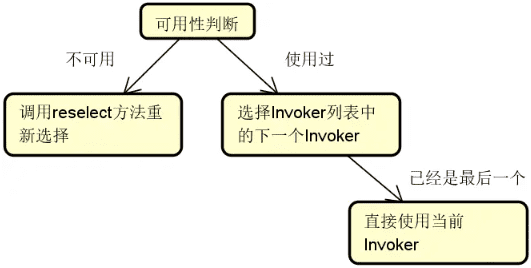
至于 reselect 方法,它的主要实现过程同样也是借助于 LoadBalance 的 select 方法完成对 Invoker 的重新选择。Dubbo 会使用一个标志位对传递给 LoadBalance 的 Invoker 对象的可用性进行过滤,然后将过滤之后且未被选择的 Invoker 对象列表交给 LoadBalance 执行负载均衡。
以上几个方法中,只有 select 方法的修饰符是 protected 的,可以被 AbstractClusterInvoker 的各个子类根据需要进行直接调用。显然,因为 AbstractClusterInvoker 提供了模板方法,因此它的子类势必是在 doInvoke 方法中调用这些 select 方法。
我们来看一下 FailoverClusterInvoker 的 doInvoke 方法,这个方法的执行逻辑同样不是很复杂。Failover 的意思很简单,就是失败重试,所以可以想象 doInvoke 方法中应该包括一个重试的循环操作。通过翻阅代码,我们确实发现了这样一个 for 循环,裁剪后的代码结构如下所示:
for (int i = 0; i < len; i++) {
// 由于 Invoker 对象列表可能已经发生变化,所以在执行重试操作前需要进行重新选择
if (i > 0) {
// 验证当前 Invoker 对象是否可用
checkWhetherDestroyed();
// 重新获取所有服务提供者
copyinvokers = list(invocation);
// 重新检查这些 Invoker 对象
checkInvokers(copyinvokers, invocation);
}
// 通过父类的 select 方法获取 invoker
Invoker<T> invoker = select(loadbalance, invocation, copyinvokers, invoked);
// …
try {
// 发起远程调用
Result result = invoker.invoke(invocation);
return result;
} catch (RpcException e) {
// 如果是业务异常,直接抛出
}
// …
}
// 如果 for 循环执行完毕还是没有找到一个合适的 invoker,则直接抛出异常
throw new RpcException();上述代码中的循环次数来自于 URL 传入的重试次数,默认重试次数是 2。在重试之前,由于 Invoker 对象列表可能已经发生变化,所以需要对当前 Invoker 对象是否可用进行验证,并根据需要进行重新选择。注意到在每一次循环中,我们首先调用父类 AbstractClusterInvoker 中的 select 方法,并将该方法返回的 Invoker 对象保存到一个 invoked 集合中,表示该 Invoker 对象已经被选择和使用。
一旦确定了目标 Invoker 对象,我们就可以通过该对象所提供的 invoke 方法执行远程调用。调用过程可能成功、也可能失败,而失败的结果也分两种情况,如果是业务失败则直接抛出异常,反之我们就继续执行循环。如果整个循环都结束了还是没有成功地完成调用过程,那么最终也会抛出异常。
至此,基于 FailoverClusterInvoker 的集群容错机制讲解完毕。Dubbo 中的其他集群容错实现方案交由你自行进行理解和分析。
解题要点
服务容错在当下的分布式系统开发过程中已经属于是一种标准组件,所以在面试过程中也经常出现。关于服务容错的概念和实现策略,需要面试者具备针对性的知识体系。
从解决思路上讲,回答这类问题可以分成两个阶段。
第一个阶段是先解释什么是服务容错。我们需要明确由于存在服务自身失败以及网络瞬态等因素,为了确保服务访问过程的可靠性,服务容错是必不可少的。然后重点是要提到服务的雪崩效应,即在分布式环境下,由于服务依赖失败导致整个服务访问链路不可用。那么雪崩效应究竟是怎么形成的呢?就是因为服务没有做到容错而导致的。
第二阶段,我们需要进一步掌握服务容错实现层面的知识点。对于开发人员而言,相对于原理部分的内容,具体的实现过程反而更加容易把握,多少都能回答一些。但这道题想要回答得有体系化有一定难度,能够体现出不同面试者之间的水平差异。针对集群容错的实现,包括 Failover(失效转移)、Failback(失败通知)、Failsafe(失败安全)和 Failfast(快速失败)等多种实现策略。这些策略本身都并不是很复杂,也没有太多的难点,唯一需要注意的地方在于知识点比较细而多。回答过程中需要按照一定的逻辑进行展开,避免概念之间产生混淆。
小结与预告
本讲内容对集群容错的设计思想和实现策略进行了详细的展开。集群容错的实现策略有很多,我们基于 Dubbo 给出了该框架中内置的几种实现方案的底层原理。
请注意,集群容错只是服务容错的其中一种实现方式。主流的实现方式还包括服务熔断。服务熔断的实现需要引入熔断器的概念。那么,什么是熔断器?它又是如何实现服务容错的呢?在下一讲中,我们将基于 Spring Cloud 框架讨论熔断器的实现过程。
服务容错:熔断器的基本结构是怎么样的?如何实现?
在上一讲中,我们详细介绍了集群容错的概念以及实施策略。通过构建集群机制来实现服务容错是分布式服务构建过程中的一种常见技术手段,但并不是唯一的技术手段。围绕服务容错,还存在一个面试过程中经常会出现的话题,这就是本讲内容要介绍的服务熔断。
服务熔断的具体表现形式是熔断器。那么,熔断器的基本结构是怎么样的?它又是如何实现的呢?本讲内容将围绕这一问题展开讨论。
问题背景
除了上一讲介绍的集群容错,熔断(Circuit Breaker)也是很实用的一种容错机制。在日常开发过程中,如果你使用的是像 Spring Cloud 这样的主流分布式服务框架,那么系统所产生的每一次远程调用的背后都内置了熔断机制,只是你自己可能并没有注意到,或者甚至都没有认识到有这样一个概念。
正是因为服务熔断的实现是一个自动化的过程,而使用方式上也不需要开发人员有太多参与,所以熔断机制往往是一个面试过程中经常被考查的问题。一方面在于熔断机制非常重要,另一方面也可以通过这个问题很好地区分候选人的知识广度和深度。 我作为面试官,经常会对候选人提出这个问题,而得到的回答往往不尽如人意。
从面试角度讲,关于熔断机制有很多种具体的问法,面试官往往会采用这样的方式来考查候选人:
- 熔断器的状态有哪些?相互之间是如何转换的?
- 在系统运行时,如何有效地收集和统计运行时数据?
- 你使用过的熔断器有哪些?它的基本原理是怎么样的?
- 如果让你来设计并实现一个简单的熔断机制,你会怎么做?
上述问题虽然各有侧重点,但对于熔断机制而言,考查的重点还是候选人在工程实践的基础上所掌握的技术原理。
问题分析
熔断这个概念实际上并不难理解,类似于日常生活中经常会碰到的电路自动切断机制。我们知道在电路系统中,当电流过大时保险丝就会被融化从而隔断了整个电路回路。类比分布式服务,当系统产生大量异常时,我们也应该隔断整个服务调用链路,避免服务的不断重试触发雪崩效应。
那么服务熔断是如何做到的呢?我们需要明确,对于服务消费者发起的每一次远程调用请求,熔断器都需要进行监控和记录。如果调用的响应时间过长,服务熔断器就应该中断本次调用并直接返回。请注意服务熔断器判断本次调用是否应该快速失败是有状态的,也就是说它会对一段时间的调用结果进行统计,如果统计的结果触发了事先设置好的阈值(类似电路系统中保险丝的过载等级),那么服务熔断机制就会被触发,反之将继续执行后续的远程调用。
通过上述分析,我们可以梳理出如下技术上的要点。
- 状态性:通过合理的状态切换来控制是否对请求进行熔断。
- 运行时数据:收集服务运行时数据并进行统计分析,为阈值判断提供依据。
- 阈值控制:各个状态切换的控制开关。
通过对上述要点的分析,这道题的回答思路就有了,而回答好这道题的关键就是要对上述要点背后的技术原理进行系统的阐述。接下来,让我们来对具体的技术体系展开讨论。
技术体系
基于熔断器的设计理念,我们对熔断过程进行进行抽象和提炼,可以得到如下图所示的熔断器基本结构。
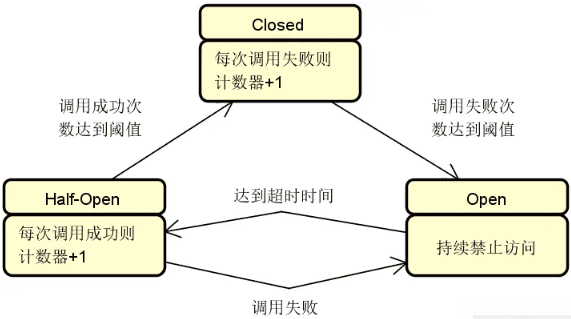
可以看到,上图所展示的结构简明扼要地给出了熔断器内部所具备的状态机,该状态机包含三个状态,即 Closed(关闭)、Open(打开)和 Half-Open(半开)。
- Closed: 这是熔断器的默认状态。在该状态下,相当于熔断器没有发挥任何效果,所有的请求可以得到正常的响应。但是,在熔断器内部还是会对所有的调用过程进行监控,如果有异常发生则会进行不断累加。
- Open: 这是熔断器的打开状态。在该状态下,相当于熔断器对所有的请求进行了隔断,来自服务消费者的请求不会触达到服务的提供者。同时,在熔断器内部也会启动一个计时器,当处于该状态达到一定时间时,熔断器会进入到半开状态。
- Half-Open: 这是熔断器的半开状态。所谓半开,指的是熔断器会允许一部分请求通过,然后再对这些请求的响应结果进行统计。如果这些请求的成功比例达到一定的阈值,则会把熔断器设回到关闭状态,反之则进入打开状态。
关于熔断器的组成和状态我们已经明确了,但显然还有很多细节是缺失的。如果你只是用这些内容来回答面试问题,应该可以拿到 60 分,但剩下的 40 分才是更好地拉开你和其他候选人之间差距的关键。为了让你更好地理解熔断器的实现原理,接下来,我们讨论如何自己实现一个包含这三个状态的熔断器。
首先,我们需要定义一个枚举类 State,代码如下:
public enum State {
CLOSED,
OPEN,
HALF_OPEN
}然后,我们定义代表熔断器的 CircuitBreaker 接口,如下所示:
public interface CircuitBreaker {
// 成功的响应,会对熔断器状态进行重置
void recordSuccess();
// 失败的响应,根据需要对状态进行设置
void recordFailure(String response);
// 获取熔断器的当前状态
String getState();
// 设置熔断器状态
void setState(State state);
// 对远程服务发起请求
String attemptRequest() throws RemoteServiceException;
}对于 CircuitBreaker 接口的实现过程是我们讨论的重点。为了实现对熔断器状态的合理控制,我们首先需要定义一系列的中间变量,如下所示:
// 远程调用的超时时间
private final long timeout;
// 重试时间间隔
private final long retryTimePeriod;
// 最近一次的调用失败时间
long lastFailureTime;
// 最近一次的失败响应结果
private String lastFailureResponse;
// 累计失败次数
int failureCount;
// 失败率阈值
private final int failureThreshold;
// 熔断器状态
private State state;
// 类似无限大的一个未来时间
private final long futureTime = 1000000000000;当我们发起一个远程调用时,我们需要基于调用结果合理设置熔断器的状态,代码如下所示:
public String attemptRequest() throws RemoteServiceException {
evaluateState();
if (state == State.OPEN) {
// 如果熔断式处于打开状态,就直接返回失败结果
return this.lastFailureResponse;
} else {
try {
// 执行远程调用
var response = service.call();
// 远程调用成功
recordSuccess();
return response;
} catch (RemoteServiceException ex) {
// 远程调用失败
recordFailure(ex.getMessage());
throw ex;
}
}
}我们继续来实现当调用成功和失败时,对应的 recordSuccess 和 recordFailure 方法的执行逻辑,代码如下所示:
// 调用成功,失败次数清零,最近失败时间设置成无限大,并把熔断器状态设置成关闭
public void recordSuccess() {
this.failureCount = 0;
this.lastFailureTime = System.nanoTime() + futureTime;
this.state = State.CLOSED;
}
// 调用失败,失败次数加 1,最近失败时间设置成当前时间,并把失败结果设置成最近一次调用失败的响应
public void recordFailure(String response) {
failureCount = failureCount + 1;
this.lastFailureTime = System.nanoTime();
this.lastFailureResponse = response;
}当系统运行一段时间之后,我们如何来获取熔断器的当前状态呢?可以实现如下所示的 getState 方法:
public String getState() {
// 如果失败次数大于阈值
if (failureCount >= failureThreshold) {
if ((System.nanoTime() - lastFailureTime) > retryTimePeriod) {
// 如果失败的累计时间已经超过了所允许的重试时间间隔,状态即为半熔断(相当于此时已经过了重试时间,需要打开半开状态)
state = State.HALF_OPEN;
} else {
// 反之,熔断器应该为开启状态
state = State.OPEN;
}
} else {
// 熔断器为打开状态
state = State.CLOSED;
}
return state.name();
}对应的,如果我们想要直接对熔断器状态进行设置,可以使用如下所示的 setState 方法:
public void setState(State state) {
this.state = state;
switch (state) {
case OPEN: // 设置开启状态
this.failureCount = failureThreshold;
this.lastFailureTime = System.nanoTime();
break;
case HALF_OPEN: // 设置半开状态
this.failureCount = failureThreshold;
this.lastFailureTime = System.nanoTime() - retryTimePeriod;
break;
default: // 默认为关闭状态
this.failureCount = 0;
}
}可以看到,这里我们也只是通过对熔断器的几个核心变量设置合适的值来更新熔断器的最新状态。
以上代码示例可以帮助你更好地理解一个熔断器的内部实现原理,也可以帮助你回答类似“如果让你来实现一个简单的熔断机制,你会怎么做?”这种开放式问题。但是,这个毕竟只是一个示例。要想完整理解熔断器的实现过程,还是需要我们来对主流分布式服务框架中的原理展开解析。
源码解析
在 Spring Cloud 中,专门为开发人员提供了具备服务熔断功能的 Spring Cloud Circuit Breaker 组件。从命名上看,Spring Cloud Circuit Breaker 是对熔断器的一种抽象,支持不同的熔断器实现方案。在 Spring Cloud Circuit Breaker 中,内置了四种熔断器,如下图所示:
上图中的 Netflix Hystrix 显然来自于 Netflix OSS,Resilience4j 是受 Hystrix 项目启发所诞生的一款新型的容错库,Sentinel 从定位上讲是一款包含了熔断降级功能的高可用流量防护组件,而最后的 Spring Retry 是 Spring 自研的重试和熔断框架。针对以上四种熔断器,Spring Cloud Circuit Breaker 提供了统一的 API。
Spring Cloud Circuit Breaker 组成结构
为了在应用程序中创建一个熔断器,我们可以使用 Spring Cloud Circuit Breaker 中的工厂类 CircuitBreakerFactory,该工厂类的定义如下:
public abstract class CircuitBreakerFactory<CONF, CONFB extends ConfigBuilder<CONF>> extends AbstractCircuitBreakerFactory<CONF, CONFB> {
public abstract CircuitBreaker create(String id);
}可以看到这是一个抽象类,只有一个 create 方法用来创建 CircuitBreaker。CircuitBreaker 是一个接口,约定了熔断器应该具有的功能,该接口定义如下所示:
public interface CircuitBreaker {
default <T> T run(Supplier<T> toRun) {
return run(toRun, throwable -> {
throw new NoFallbackAvailableException("No fallback available.", throwable);
});
};
<T> T run(Supplier<T> toRun, Function<Throwable, T> fallback);
}这里用到了函数式编程的一些语法,但我们从方法定义上还是可以明显看出包含了 run 和 fallback 这两个方法。其中的 Supplier 包含了你希望运行在熔断器中的业务代码,而 Function 则代表着回退(Fallback)方法。如果你熟悉 Netflix Hystrix 中的 HystrixCommand,你会发现两者之间存在明显的对应关系。
在 Spring Cloud Circuit Breaker 中,分别针对 Hystrix、Resilience4j、Sentinel 和 Spring Retry 这四款框架提供了 CircuitBreakerFactory 抽象类的子类。一旦在代码工程的类路径中添加了相关的 starter,系统就会自动创建 CircuitBreaker。也就是说 CircuitBreakerFactory.create 方法会实例化对应框架的一个 CircuitBreaker 实例。
在引入具体的开发框架之后,下一步工作就是对它们进行配置。在 CircuitBreakerFactory 的父类 AbstractCircuitBreakerFactory 中,我们发现了如下所示的两个抽象方法:
// 针对某一个 id 创建配置构造器
protected abstract CONFB configBuilder(String id);
// 为熔断器配置默认属性
public abstract void configureDefault(Function<String, CONF> defaultConfiguration);这里用到了大量的泛型定义,我们可以猜想,在这两个抽象方法的背后,Spring Cloud Circuit Breaker 会针对不同的第三方框架提供不同的配置实现过程。我们在接下来的内容中会基于具体的框架对这一过程做展开讨论。
让我们来到 Hystrix 框架,来看看在 Spring Cloud Circuit Breaker 中是如何使用统一编程模式完成对该框架的集成。我们首先关注实现了 CircuitBreaker 接口的 HystrixCircuitBreaker 类,如下所示:
public class HystrixCircuitBreaker implements CircuitBreaker {
private HystrixCommand.Setter setter;
public HystrixCircuitBreaker(HystrixCommand.Setter setter) {
this.setter = setter;
}
@Override
public <T> T run(Supplier<T> toRun, Function<Throwable, T> fallback) {
HystrixCommand<T> command = new HystrixCommand<T>(setter) {
@Override
protected T run() throws Exception {
return toRun.get();
}
@Override
protected T getFallback() {
return fallback.apply(getExecutionException());
}
};
return command.execute();
}
}不难想象,这里应该构建了一个 HystrixCommand 对象,并在该对象原有的 run 和 getFallback 方法中封装了 CircuitBreaker 中的统一方法调用,而最终实现熔断操作的还是 Hystrix 原生的 HystrixCommand。
然后,我们接着来看 HystrixCircuitBreakerFactory,这个类的实现过程也简洁明了,如下所示:
public class HystrixCircuitBreakerFactory extends CircuitBreakerFactory<HystrixCommand.Setter, HystrixCircuitBreakerFactory.HystrixConfigBuilder> {
// 实现默认配置
private Function<String, HystrixCommand.Setter> defaultConfiguration = id -> HystrixCommand.Setter.withGroupKey(
HystrixCommandGroupKey.Factory.asKey(getClass().getSimpleName())).andCommandKey(HystrixCommandKey.Factory.asKey(id));
public void configureDefault(Function<String, HystrixCommand.Setter> defaultConfiguration) {
this.defaultConfiguration = defaultConfiguration;
}
public HystrixConfigBuilder configBuilder(String id) {
return new HystrixConfigBuilder(id);
}
// 创建熔断器
public HystrixCircuitBreaker create(String id) {
Assert.hasText(id, "A CircuitBreaker must have an id.");
HystrixCommand.Setter setter = getConfigurations().computeIfAbsent(id, defaultConfiguration);
return new HystrixCircuitBreaker(setter);
}
// 创建配置构造器
public static class HystrixConfigBuilder extends AbstractHystrixConfigBuilder<HystrixCommand.Setter> {
public HystrixConfigBuilder(String id) {
super(id);
}
@Override
public HystrixCommand.Setter build() {
return HystrixCommand.Setter.withGroupKey(getGroupKey()).andCommandKey(getCommandKey()).andCommandPropertiesDefaults(getCommandPropertiesSetter());
}
}
}上述代码基本就是对原有 HystrixCommand 中关于服务分组等属性的简单封装,你可以结合接下来要介绍的 Hystrix 框架熔断机制内容做进一步理解。
Hystrix 熔断机制
在 Hystrix 中,最核心的就是 HystrixCircuitBreaker 接口,该接口代表了对熔断器的抽象过程,如下所示:
public interface HystrixCircuitBreaker {
public boolean allowRequest();
public boolean isOpen();
void markSuccess();
}可以看到 HystrixCircuitBreaker 接口只有三个方法。在 Hystrix 中,该接口的实现类是 HystrixCircuitBreakerImpl。
我们首先来看最重要的 allowRequest 方法,该方法用来判断每个请求是否可被执行。allowRequest 实际上是对 isOpen 方法做了一层封装,在通过调用 isOpen 来触发熔断器的计算逻辑之前,先根据 HystrixCommandProperties 中的配置信息来判断是否强制开启熔断器,具体实现如下所示:
public boolean allowRequest() {
if (properties.circuitBreakerForceOpen().get()) {
return false;
}
if (properties.circuitBreakerForceClosed().get()) {
isOpen();
return true;
}
return !isOpen() || allowSingleTest();
}接下来的 isOpen 方法用来获取熔断器的当前状态。请注意,熔断器中关于阈值判断的一系列处理逻辑都位于该方法中,如下所示:
public boolean isOpen() {
if (circuitOpen.get()) {
return true;
}
HealthCounts health = metrics.getHealthCounts();
// 检查是否达到最小请求数,如果未达到的话即使请求全部失败也不会熔断
if (health.getTotalRequests() < properties.circuitBreakerRequestVolumeThreshold().get()) {
return false;
}
// 检查错误百分比是否达到设定的阀值,如果未达到的话也不会熔断
if (health.getErrorPercentage() < properties.circuitBreakerErrorThresholdPercentage().get()) {
return false;
} else {
// 如果错误率过高, 进行熔断,并记录下熔断时间
if (circuitOpen.compareAndSet(false, true)) {
circuitOpenedOrLastTestedTime.set(System.currentTimeMillis());
return true;
} else {
return true;
}
}
}最后,我们来到用来关闭熔断器的 markSuccess 方法。显然,该方法在熔断器处于半开状态下进行使用,我们可以通过该方法将熔断器设置为关闭状态。这时候,熔断器要做的一件事情就是重置对请求的统计指标,如下所示:
public void markSuccess() {
if (circuitOpen.get()) {
if (circuitOpen.compareAndSet(true, false)) {
metrics.resetStream();
}
}
}HystrixCircuitBreaker 接口的这三个方法的执行逻辑实际上都不复杂,HystrixCircuitBreaker 通过一个 circuitOpen 状态位控制着整个熔断判断流程,而这个状态位本身的状态值则取决于系统目前的运行时数据。
解题要点
在分布式系统开发过程中,服务熔断的实现需要引入熔断器的概念,事实上像 Spring Cloud 等很多开源框架都内置了熔断器的实现组件。我在面试中发现很多开发人员已经在使用这些组件了,但并不清楚其背后的设计思想和原理。所以,这道题也是比较典型的从应用到原理的反向考查类的面试题。
从解题思路上讲,目前业界主流的熔断器实现模型基本都是类似的。就知识体系而言,要注意的是在熔断器内部实现过程中,并不是只有熔断和非熔断这两个简单状态,而是会引入一个半熔断的状态,通过对当前服务所处理请求的情况进行统计分析,熔断器会基于一定的阈值动态完成这些状态之间的自动切换。
另一方面,面试官在考查候选人能力的一大关注点还是实践能力,所以可以结合具体工具的使用过程来阐述熔断器的核心概念。在日常开发过程中,熔断器的使用方式主要是依赖于一系列的配置项。例如基于 Resilience4j 来使用 Spring Cloud Circuit Breaker 时,典型的配置项如下所示:
resilience4j:
circuitbreaker:
configs:
default:
ringBufferSizeInClosedState: 10 # 熔断器关闭时的缓冲区大小
ringBufferSizeInHalfOpenState: 4 # 熔断器半开时的缓冲区大小
waitDurationInOpenState: 20000 # 熔断器从打开到半开需要的时间
failureRateThreshold: 80 # 熔断器打开的失败阈值
recordExceptions: # 记录的异常
- com.example.resilience4j.exceptions.BusinessBException
- com.example.resilience4j.exceptions.BusinessAException
ignoreExceptions: # 忽略的异常
- com.example.resilience4j.exceptions.BusinessAException
instances:
aServiceCircuitBreaker:
baseConfig: default
bServiceCircuitBreaker:
baseConfig: default
waitDurationInOpenState: 5000
failureRateThreshold: 20这些配置信息可以分为两部分,一部分是默认配置,一部分是专属于某一个服务的特定配置。这里也展示了用来打开熔断器的失败阈值 failureRateThreshold、熔断器从打开到半开需要的时间 waitDurationInOpenState 等配置参数,以及针对异常类型的精细化控制过程。
最后,在回答这道题时,一种比较好的解题思路是结合某个熔断器开源框架来分析它的内部实现原理,这是一个很大的加分项。
小结与预告
服务熔断在分布式服务构建过程中是一种标配组件,例如在 Spring Cloud 中专门提供了一个 SpringCloudApplication 注解(如下所示),而在该注解中就把用来启用熔断器的 @EnableCircuitBreaker 和用来启用服务发现机制的 @EnableDiscoveryClient 以及 Spring Boot 的基础注解 @SpringBootApplication 放在一起,确保所有分布式服务都内置了服务熔断机制。
@SpringBootApplication
@EnableDiscoveryClient
@EnableCircuitBreaker
public @interface SpringCloudApplication服务熔断的概念和原理理解起来都有一定的复杂度。在本讲内容中,我们从熔断器的基本结构开始讲起,详细分析了它在 Spring Cloud 的实现过程。同时,我们还自己实现了一个简单而又完整的熔断器示例,帮助你对服务熔断的实现过程有更为感性的认识。就算你平时没有专门针对熔断器做过系统学习,相信通过本讲内容的介绍也能帮助你顺利应对技术面试。
掌握了服务熔断机制之后,下一讲我们将讨论另一个确保服务高可用的技术组件,即服务降级。和服务熔断一样,我们也可以采用不同的技术手段来对服务进行降级。那么,服务降级的常见实现策略有哪些呢?我们下一讲再聊。
服务降级:服务降级的常见实现策略有哪些?
在上一讲中,我们介绍了基于熔断器的设计思想和实现方式。和集群容错一样,服务熔断也是一种常见的服务容错机制,也可以用来确保服务的可用性。而为了确保核心服务的可用性,有时候我们就会故意对那些不重要的服务执行下线操作,从而确保系统中有限的资源都应用到核心服务上。这就引出了在分布式系统构建过程中非常重要的一个技术组件,即服务降级。
那么,什么是服务降级?又有那些常见的服务降级实现策略呢?这是面试过程中的一个常见考点,也是本讲内容的重点。
问题背景
我们先来看这个问题的背景。举个例子,在下图中存在服务 A 和服务 B 这两个服务。其中服务 B 是核心服务,而服务 A 是可以降级的非核心服务,服务 B 会依赖服务 A。

现在,当访问服务 B 的流量迎来高峰时,系统中的资源即将被耗尽,服务 B 的可用性即将出现问题。这时候,我们可以对服务 A 执行降级操作,也就说把服务 A 下线。通过这种方式,原本被服务 A 所占用的资源就可以用来处理面向服务 B 的请求。但是,问题就来了,服务 A 一旦下线,服务 B 在访问服务 A 时应该如何处理呢?基本的策略就是“快速失败”,即在服务 B 向服务 A 执行调用的链路中直接获取一个返回值,而不执行真正的远程调用。
显然,想要实现上述效果并不容易,我们需要考虑如何在服务 A 已经下线的情况下,确保服务 B 能够得到一个快速失败的结果。由此,我们可以引出与服务降级相关的一系列问题,包括:
- 系统中存在很多服务,你怎么判断哪些服务是可以降级的呢?
- 快速失败的表现形式有哪些?
- 想要实现服务降级,你有哪些设计思路?
- 什么是服务回退?如何实现服务回退?
- Dubbo 框架是如何实现服务降级的?
- Spring Cloud 框架是如何实现服务降级的?
上述问题都是面试官在面试过程中经常会提出的考查点,我们需要对这些考查点进行系统分析。
问题分析
所谓服务降级,是指在某些系统核心服务的访问压力剧增的情况下,根据当前业务情况及流量对一些服务进行有策略的快速失败处理,以此避免服务之间的调用依赖影响到其他核心服务。
在面试过程中,首先需要用自己的语言对服务降级的基本概念和设计理念进行阐述,我们可以结合问题背景部分所举的例子进行展开。
应对这类问题的第二点思路是对服务分级机制的讨论。既然服务可以降级,那么势必需要对服务进行分级。通常,等级越低的服务越应该被降级。我们可以结合日常的场景对服务等级进行分析。
第三点,也是最重要的一点,是服务降级的实现策略。目前,在主流的开源框架中,关于如何实现服务降级有两大类策略,即:
- 模拟(Mock)机制
- 回退(Fallback)机制
明确了服务降级的实现策略,最后的一点就是围绕具体的开源框架,给出这些实现策略的底层实现机制。
通过上述分析,我们发现服务降级是一套独立而又完整的技术组件,既包含了分布式系统设计上的一些方法论,也和具体的工程实践紧密相关。
接下来,让我们先从方法论开始讲起,梳理服务降级相关的技术体系。
技术体系
通过前面内容的介绍,我们已经理解了服务降级的基本概念和设计思想。从技术体系而言,关于服务降级我们要明确两个维度的内容。第一个维度是如何对服务进行分级管理,另一个维度就是具体的降级实现策略。
我们先来讨论第一个维度。服务降级在实现上一般需要对业务的重要性进行区分,也就是需要明确服务分级,具体的服务分级方法因业务场景和需求而定。对每个服务进行等级管理之后,降级操作一般是从等级最低的的服务开始。
关于服务分级,业界并没有统一的标准。在本讲中,我们介绍一种三级分类方法,如下图所示:
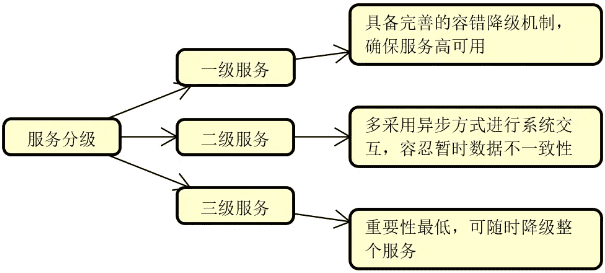
围绕服务分级,我们给出一个案例。下图展示了在移动医疗系统中基于服务分级思想所构建的无线网关业务,无线网关用于上传来自无线网络的数据并进行相应的处理。对于这样一个网关系统而言,网关的连接管理和数据上报是优先级最高的业务功能,因为缺少这些功能,网关也就不能正常工作。数据上报之后,对数据进行分析是收集网关数据的目的所在,但数据分析服务可以离线处理,并不一定需要保证服务 100% 的在线率。其他的诸如服务监控、反垃圾和后台配置则属于辅助性功能,相应的优先级也就最低。
显然,这里我们以对用户的影响程度为标准对服务等级进行了划分。
介绍完服务等级的划分方式,我们来讨论第二个维度,即服务降级的实现策略。在问题分析部分,我们已经提到了两种主流的降级机制,即模拟和回退。
Mock 并不是一个新概念,通常用于测试领域。首先,非常明确的一点,Mock 机制的作用就是完成对系统中组件与组件之间的有效隔离。在服务访问过程中,我们通常关注的是目标服务本身的功能和行为,对于该服务涉及到的一些依赖,我们仅仅关注它们在整个服务访问中的交互过程,比如是否调用、何时调用、调用的参数和返回值、调用过程中出现的各种异常等。至于调用过程中具体执行的业务逻辑,对于调用结果而言并不重要。
基于这种设计思想,我们就可以通过 Mock 对象来模拟真实对象的调用结果,如下图所示:
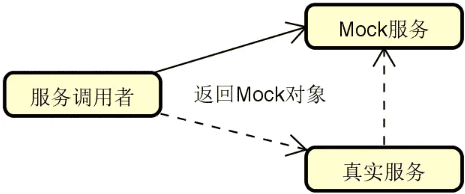
服务降级的另一种主流实现策略是服务回退。为了实现对服务的降级,服务端会准备一个本地的 Fallback 函数,该函数会在每次调用时返回一个缺省值,如下图所示:
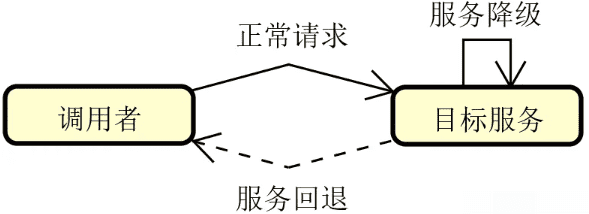
源码解析
接下来,我们就将基于 Dubbo 和 Spring Cloud 这两款开源框架分别给出服务降级的实现方式。虽然这两种框架采用不同的实现方式,但其设计思想本质上是类似的。
Dubbo 中的服务降级
Dubbo 中的 Mock 机制
Dubbo 通过 Mock 来实现服务降级的过程和测试领域的 Mock 有异曲同工之处。在 Dubbo 中,可以在配置服务引用时提供 Mock 机制,存在几种配置方法,这里参考 Dubbo 官网中的示例。
首先,我们可以在配置文件中添加如下所示的配置项:
<dubbo:reference interface="com.foo.BarService" mock="true" />如果采用这种配置,那么该 Mock 类的命名必须是接口名 + Mock,在这个示例中,即 BarServiceMock。我们可以提供如下所示的实现:
public class BarServiceMock implements BarService {
public String sayHello(String name) {
return "降级数据";
}
}同时,我们也可以提供如下所示的配置项,指定 Mock 的实现类。
<dubbo:reference interface="com.foo.BarService" mock="com.foo.BarServiceMock" />当然,如果 Mock 方法的逻辑非常简单,我们也可以直接将实现写在配置项中。例如,如下所示的配置标明 Mock 方法直接返回 null。
<dubbo:reference interface="com.foo.BarService" mock="return null" />通过上述配置方法,在服务调用过程中,返回的就是一个事先提供的 Mock 对象,而不会对服务提供者发起真实请求。
Mock 还存在一些高级用法,如下图所示:
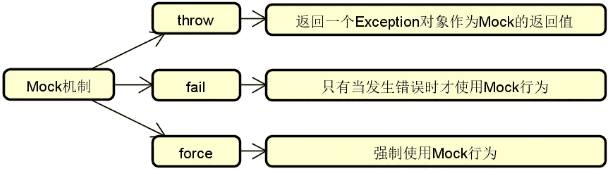
在执行 Mock 的过程中,如果我们希望抛出一个异常而不是返回正常的 Mock 值,那么可以使用 throw 配置项。而上图中的 fail 配置项用于指定当远程调用过程中发生错误时才会返回 Mock 对象。对应的,force 配置项用于指定在任何情况下都将返回 Mock 对象。
现在,让我们回到 Dubbo 中的 Cluster 接口。我们知道该接口存在一批实现类。在这些实现类中,存在一个命名上比较特殊的 MockClusterWrapper 类,该类恰恰就是用于实现 Mock 机制,如下所示:
public class MockClusterWrapper implements Cluster {
private Cluster cluster;
public MockClusterWrapper(Cluster cluster) {
this.cluster = cluster;
}
public <T> Invoker<T> join(Directory<T> directory) throws RpcException {
return new MockClusterInvoker<T>(directory, this.cluster.join(directory));
}
}与其他 Cluster 接口的实现类不同,MockClusterWrapper 内部同时持有一个 Cluster 接口,相当于是对 Cluster 接口的一种包装(Wrapper),所以该类取名为 MockClusterWrapper。而该类的 join 方法中即根据传入的 Directory 构建一个 MockClusterInvoker 类。显然,Mock 的核心逻辑应该位于 MockClusterInvoker 类中,让我们来一起看一下。
MockInvoker 和 MockClusterInvoker
同样,我们也知道在 Dubbo 中存在一批 ClusterInvoker 实现类。在这些实现类中,构造函数只传入一个 Directory 对象。而 MockClusterInvoker 的构造函数则包含两个参数,除了 Directory 对象还有一个 Invoker 对象。因此,MockClusterInvoker 天生就包含了 Invoker 对象。
MockClusterInvoker 的 invoke 方法执行流程如下所示:
public Result invoke(Invocation invocation) throws RpcException {
Result result = null;
// 获取输入参数
String value = directory.getUrl().getMethodParameter(invocation.getMethodName(), Constants.MOCK_KEY, Boolean.FALSE.toString()).trim();
if (value.length() == 0 || value.equalsIgnoreCase("false")) {
// 如果没有 Mock 键,则不执行 Mock
result = this.invoker.invoke(invocation);
} else if (value.startsWith("force")) {
// …
// 如果以 force 开头,直接 Mock,不发起远程调用请求
result = doMockInvoke(invocation, null);
} else {
// 如果以 fail 开头,进入失败 Mock,即正常发起远程调用请求,如果失败则抛出了非业务异常
try {
result = this.invoker.invoke(invocation);
} catch (RpcException e) {
if (e.isBiz()) {
// 如果是业务异常,直接抛出
throw e;
} else {
//…
// 如果捕获到非业务异常,则调用 doMockInvoke 方法返回结果
result = doMockInvoke(invocation, e);
}
}
}
return result;
}上述代码实际上就是三个分支流程,分别对应没有 Mock 配置、以 force 开头的配置和以 fail 开头的配置这三种场景。
- 如果没有 Mock 配置,就不执行 Mock;
- 如果是以 force 开头,那么就直接返回 Mock 对象而不发起远程调用请求;
- 如果以 fail 开头,意味着进入失败 Mock 处理流程,即正常发起远程调用请求,如果失败则抛出了非业务异常。
因为 MockClusterInvoker 中自身包含有一个 Invoker 对象,因此直接就可以通过该 Invoker 对象执行远程调用。如果这个异常是业务异常,就直接抛出交由上游代码进行处理。而如果捕获到非业务异常,则会调用 doMockInvoke 方法返回结果。
接下来就需要看一下这个 doMockInvoke 方法的执行逻辑。该方法核心逻辑之一是获取 MockInvoker 并执行它的 invoke 方法,这部分实现如下所示:
List<Invoker<T>> mockInvokers = selectMockInvoker(invocation);
if (mockInvokers == null || mockInvokers.size() == 0) {
minvoker = (Invoker<T>) new MockInvoker(directory.getUrl());
} else {
minvoker = mockInvokers.get(0);
}
result = minvoker.invoke(invocation);我们看到,这里会通过 selectMockInvoker 方法获取 Mock 类型的 Invoker。而如果没有找到想要的 Invoker,则会自己创建一个 MockInvoker。
MockInvoker 中最重要的就是 invoke 方法,该方法包含了一系列判断,核心逻辑如下所示:
public Result invoke2(Invocation invocation) throws RpcException {
// 如果是空的 return 配置
if (Constants.RETURN_PREFIX.trim().equalsIgnoreCase(mock.trim())) {
// 直接返回空的 RpcResult
} else if (mock.startsWith(Constants.RETURN_PREFIX)) { // 如果是包含返回值的 return 配置
// 解析 Mock 对象,构建 RpcResult 并返回
} else if (mock.startsWith(Constants.THROW_PREFIX)) { // 如果是 throw 配置
if (condition) {
// 抛出 Mock 异常
} else {
// 抛出业务异常
}
} else { // 如果是自定义 Mock 类
// 调用 Mock 类的 invoke 方法并返回
Invoker<T> invoker = getInvoker(mock);
return invoker.invoke(invocation);
}
}这段方法针对 return 配置和 throw 配置的处理都比较简单,而如果是业务异常我们也是采用直接抛向上游代码。这里的关键是如何获取自定义 Mock 类的实例,这里用到了 getInvoker 方法,该方法的核心就是如下所示的这两行代码:
T mockObject = (T) mockClass.newInstance();
invoker = proxyFactory.getInvoker(mockObject, (Class<T>) serviceType, url);这里看到了熟悉的 ProxyFactory 接口,这是 Dubbo 中实现动态代理的核心接口。现在我们明确了,上述代码基于反射机制获取自定义 Mock 类实例,然后通过动态代理创建 Invoker。
Spring Cloud 中的服务降级
和 Dubbo 相比,Spring Cloud 采用了另一种完全不同的机制来实现服务降级,这就是回退机制。在接下里的内容中,我们将对回退机制的使用方式和设计理念做一定分析。
Spring Cloud 中的回退机制
在 Spring Cloud 中,我们可以基于 Spring Cloud Circuit Breaker 提供的回退机制来实现服务降级。在开发过程上,我们只需要提供一个回退方法实现并进行配置即可。这里同样也给出对应的实现方式。
我们举个例子,假设系统中存在一个代表用户业务的用户服务,那么当访问这个服务时,我们就可以实现回退方法。在回退方法的实现过程中,唯一需要注意的就是该回退方法的参数和返回值必须与真实的方法完全一致。
如下所示的就是回退方法的一个示例:
private UserMapper getUserFallback(String userName) {
UserMapper fallbackUser = new UserMapper(0L,"no_user","not_existed_user");
return fallbackUser;
}我们可以基于 Spring Cloud Circuit Breaker 实现服务回退,开发流程也比较固化。首先,我们需要创建一个 CircuitBreaker 实例,然后实现具体的业务逻辑并提供一个回退方法,最后执行 CircuitBreaker 的 run 方法,示例代码如下所示:
// 创建 CircuitBreaker
CircuitBreaker circuitBreaker = circuitBreakerFactory.create("user");
// 封装业务逻辑
Supplier<UserMapper> supplier = () -> {
return userClient.getUserByUserName(userName);
};
// 初始化回退函数
Function<Throwable, UserMapper> fallback = t -> {
UserMapper fallbackUser = new UserMapper(0L,"no_user","not_existed_user");
return fallbackUser;
};
// 执行业务逻辑
circuitBreaker.run(supplier, fallback);上述示例代码可以根据具体需求进行调整并嵌入到各种业务场景中。
基于拦截器实现回退
限于篇幅关系,我们在这里主要探讨如何实现一个降级体系的设计思路。服务降级的目标就是一旦出现异常确保能够正确回退,这让我们首先想到了可以通过引入 AOP 机制来对异常进行拦截。一旦拦截成功,那么就可以嵌入自定义的回退方法并执行该方法中的回退逻辑。整个设计思路下图所示:
事实上, Spring Cloud Circuit Breaker 中的 Fallback 概念和 Dubbo 中 Mock 的概念异曲同工。两者都是实现服务降级的常用技术手段。
解题要点
针对服务降级,在面试过程中,相比 Mock 机制,我认为回退机制被问题的频率会更高,是我们重点需要掌握的知识点。事实上,服务回退在分布式系统构建过程中并不能算是一个非常独立的知识点,而是属于服务降级体系下的一个具体实现策略。所以,需要面试者具有比较广的知识面,并能从概念到实现过程上对服务回退有一定的了解。
事实上,服务回退的概念并不难理解。在传统开发模式下,我们在系统发生异常时通常都会返回一个默认的提示信息。服务回退与这种处理方式是类似的,本质上就是一个回调处理机制,能够针对某个方法提供缺省的返回值。在实施过程中,常见的做法是对业务方法提供一个对应的回退方法,回退方法的参数和返回值必须与真实的方法完全一致,这样确保系统获取到缺省的返回值之后还能够正常运行。
关于服务降级的相关问题,还有一种开放式的提问方式,比方说 如果让你来实现一个服务回退机制,你会怎么做?。有时候,面试官很难从那些概念类的标准答案中看出不同面试者的水平差异,这时候就可以通过类似本题的方式进行考查。
从考查难度而言,这种开放式的面试题对面试者而言有利有弊。一方面,这种面试题没有标准答案,面试者可以自由发挥,只要做到自圆其说就行。另一方面,这种面试题可以会让面试者感到无从下手,从而导致没有很好的回答思路。
从设计思想上讲,我们可以基于拦截器来实现服务回退机制。在这套自定义的实现机制中,通过引入 AOP 对异常进行拦截。一旦拦截成功,那么就可以嵌入自定义的回退方法并执行该方法中的回退逻辑。事实上,在 Spring Cloud 等主流开源框架中,也正是基于类似的机制提供了服务回退功能。在回答这道面试题时,我们可以首先阐述自己的设计思想,然后结合开源框架给出具体的实现原理。
小结与预告
本讲是远程过程调用中所要介绍的最后一个技术组件,我们对服务降级展开了讨论。
服务降级的常见实现模式包括模拟和回退两种。这两种实现模式体现的都是一种自动化的处理策略,当服务响应出现问题时能够返回一个处理结果,从而避免对目标服务执行真正的远程调用。
从下一讲开始,我们将进入到与微服务架构相关技术组件的讨论。我们首先要讨论的是注册中心,而注册中心也有多种实现方式。下一讲的主题是:如何设计一款具备实时通知能力的注册中心模型?我们下一讲再聊。
注册中心:如何设计一款具备实时通知能力的注册中心模型?
通过前面几讲内容的介绍,我们已经掌握了与远程过程调用相关的各个技术组件。在分布式系统中,远程过程调用解决的就是两个服务之间的点对点调用过程。显然,想要完成这个调用过程,服务消费者首先得知道目标服务提供者的地址信息。这个地址信息是服务实例信息中的一个元数据,其他的元数据还包括服务的上线时间、可用状态等。
如何对这些元数据进行有效管理是分布式系统构建过程中不得不考虑的一个问题,特别是在服务实例数量非常庞大的场景下。这就引出了本讲将要介绍的一个新的技术组件,即注册中心。
注册中心的实现模型有多种,今天我们介绍其中的一种,即:如何设计一款具备实时通知能力的注册中心模型?围绕这个问题的讨论也经常出现在面试过程中,让我们一起来看一下。
问题背景
在分布式系统中,通常会存在几十个甚至上百个服务,开发人员可能甚至都无法明确系统中到底有哪些服务正在运行。另一方面,我们很难同时确保所有服务都不出现问题,也很难保证当前的服务部署方式不做调整和优化。由于自动扩容、服务重启等因素,服务实例的运行时状态也会经常变化。通常,我们把这些服务实例的运行时状态信息统称为服务的元数据(Metadata)。关于元数据这个词,我们已经在介绍服务发布流程时提到过,你可以做一些回顾。
既然服务数量的增加以及服务实例的变化都不可避免,那么,有什么好的办法能够做到对这些服务实例进行有效的管理呢?这实际上就是一个服务治理的问题。
我们需要管理系统中所有服务实例的运行时状态,并能够把这些状态的变化同步到各个服务中。就技术组件而言,我们可以通过引入注册中心轻松实现对大规模服务的高效治理。在日常开发过程中,注册中心的应用方式都是非常简单的。但从面试角度讲,这些应用方式显然不是考查的目标。面试官更多地会从设计原理和底层实现机制的角度来考查候选人对注册中心实现模型的理解程度。
我们来梳理一下关于注册中心的一些常见问题:
- 为什么我们需要在分布式系统中引入注册中心?它有什么好处?
- 你能描述注册中心的基本组成结构吗?
- 如果让你设计一个注册中心,你会选择什么框架来进行实现?
- 一旦服务提供者的状态发生变化,我们希望这些状态信息能够在服务消费者中得到实时更新,你可以采用什么样的实现机制?
上面这些问题都比较经典,我经常会拿这些问题来考查候选人。另一方面,你可能会觉得这些问题比较难以回答,但它们背后的知识体系却是每个开发人员都应该掌握的。
让我们先对这些问题做一些分析和展开。
问题分析
注册中心是我们引入的第一个微服务架构技术组件。为什么我们需要专门提取微服务架构技术组件,就是为了应对大规模分布式系统的构建需求。
如果一个分布式系统的服务数量达到一定的规模,就需要引入专门的组件来对这些服务的元数据进行管理。而这种管理过程显然应该具备一定的机制和策略,所以我们需要设计一个模型,这就是注册中心模型。关于注册中心模型的讨论是我们应对这类面试题的第一个要点。
应对这类面试题的第二个要点是深入注册中心的实现原理,其中最核心的一个问题就是:如果服务提供者的元数据发生了变化,如何实时地通知到各个服务消费者呢?这是我们要回答的第二个要点。
最后,我们明确注册中心本身是一种架构设计上的模型和机制,需要依托于具体的框架才能得以实现。因此,我们需要基于具体的开源框架来对前面提出的核心问题进行分析,并阐述底层的实现原理。
业界可以用来实现注册中心的框架有很多,一方面我们可以选择自己比较擅长的框架展开讨论。另一方面,我也建议你直接从 Dubbo 等主流的开源框架入手,来看看它们具体是如何设计和实现的。
技术体系
在分布式系统中,我们引入注册中心的目的是实现服务的自动注册和发现机制。围绕这两个操作,我们可以先来探讨注册中心所应该具备的模型结构。
注册中心模型
注册中心保存着各个服务实例的元数据,涉及的角色包括如下三种。
- 注册中心:提供服务注册和发现能力。
- 服务提供者:将自身注册到注册中心,供服务消费者进行调用。
- 服务消费者:从注册中心获取服务提供者的元数据,并发起远程调用。
上述三个角色比较简单,但注册中心的具体组成结构还是有一些额外的特性。首先,注册中心本身可以认为是一种服务器,它也提供了对应的客户端组件。各个服务需要嵌入客户端组件才能完成与注册中心服务器之间的交互。然后,为了提高访问效率,服务的消费者一般都会构建一个本地缓存,用来保存那些已经访问过的服务实例元数据。
下图展示了服务与注册中心的交互过程:
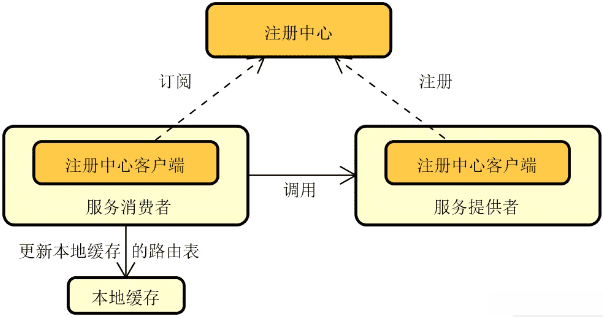
在上图中,基本的工作流程通过操作语义即可理解。但有一个问题需要解决,即一旦服务的运行时状态发生了变更,我们如何有效获取这些变更信息呢?这就需要在注册中心中进一步引入变更通知机制,如下图所示:
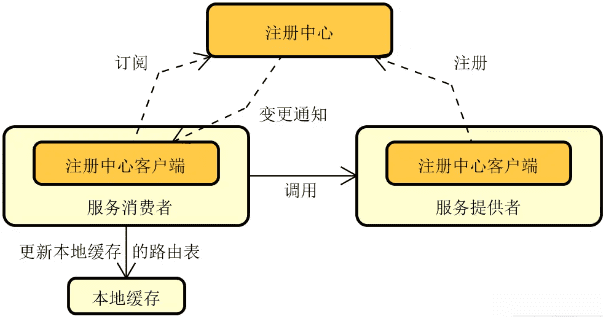
从设计理念上讲,我们希望这种来自注册中心的变更通知能够实时地同步到服务消费者,这时候就可以引入推送思想。那么,如何具体实现推送呢?我们可以采用监听机制。所谓监听机制,指的就是服务消费者对位于注册中心的元数据添加监听器,一旦元数据发生变化,就可以触发监听器中的回调函数。
我们可以在回调函数中对已变更的元数据执行任何操作,如下所示:
可以看到,服务消费者可以对具体的服务实例节点添加监听器,当这些节点发生变化时,注册中心就能触发监听器中的回调函数确保更新通知到每一个服务消费者。显然,使用监听和通知机制具备实时的数据同步效果。
注册中心实现工具
以上关于注册中心的讨论为我们提供了理论基础。根据这些理论基础,业界也诞生了很多具体的实现工具,常见的包括 Consul 、Zookeeper、Eureka 和 Nacos 等。我们无意对这些工具做一一展开。在本讲中,我们将基于 Zookeeper 来具体分析注册中心的实现模型。Zookeeper 是基于监听和通知机制的典型框架。
从物理结构上讲,Zookeeper 就是一个目录树,包含了一组被称为 ZNode 的节点,它的基本结构如下图所示:
在上图中,size 节点位于 /business/product/size 路径,节点 C 可以存储数据 350,而节点 /D/order/1 可能存储着类似 {"id":"1","itemName":"Notebook","price":"4000",createTime="2022-06-16 22:39:15"} 等复杂数据结构和信息。Zookeeper 中所有数据通过 ZNode 的路径被引用。
Zookeeper 特性很多,我们可以从注册中心的基本实现需求出发,结合模型及其操作来把握用于构建注册中心的相关技术。
首先,Zookeeper 专门设计并实现了一个监听器组件。我们可以在任何一个 ZNode 上添加监听器,并实现对应的回调函数,从而确保服务器端的变化能够通过回调机制通知到客户端。
另一方面,Zookeeper 中也提供了临时节点的概念。所谓临时节点,指的是只要客户端与 Zookeeper 的连接发生中断,那么这个节点就会自动消失。显然,临时节点的这种特性可以用于控制该节点所包含的服务定义元数据的时效性。
ZNode 是 Zookeeper 中可以用代码进行控制的主要实体。对 ZNode 的基本操作包括节点创建 create、删除 delete、获取子节点 getChildren 以及获取和设置节点数据的 getData/setData 方法。操作 Zookeeper 的客户端组件包括自带的 ZooKeeper API 和第三方 zkClient、Curator 等,这些客户端都对 Zookeeper 连接资源管理和对 ZNode 节点的各项操作做了不同程度的封装。
Zookeeper 中涉及的主要操作如下表所示,在源码解读过程中,我们会发现对 Zookeeper 的控制基本都是对这些操作的封装和应用。
| 操作 | 描述 |
|---|---|
| create | 在 ZooKeeper 命名空间的指定路径中创建一个 ZNode |
| delete | 从 ZooKeeper 命名空间的指定路径中删除一个 ZNode |
| exists | 检查路径中是否存在 ZNode |
| getChildren | 获取 ZNode 的子节点列表 |
| getData | 获取与 ZNode 相关的数据 |
| setData | 将数据设置/写入 ZNode 的数据字段 |
| getACL | 获取 ZNode 的访问控制列表(ACL)策略 |
| setACL | 在 ZNode 中设置访问控制列表(ACL)策略 |
| sync | 将客户端的 ZNode 视图与 ZooKeeper 同步 |
介绍完注册中心模型以及 Zookeeper 框架,让我们回到 Dubbo。作为一款主流的分布式服务框架,Dubbo 也内置了一整完整的注册中心实现方案,默认采用的就是 Zookeeper。
源码解析
在 Dubbo 内部,提供了 Multicas、Zookeeper、Redis、Nacos、Consul、Etcd3 等一大批注册中心实现方式。我们先从它的注册中心模型开始讲起。
Dubbo 注册中心模型
Dubbo 中的注册中心代码位于 dubbo-registry 工程中,其中包含了一个 dubbo-registry-api 工程,该工程包含了 Dubbo 注册中心的抽象 API,而剩下的 dubbo-registry-default、dubbo-registry-zookeeper、dubbo-registry-nacos 等工程则是这些 API 的具体实现,分别对应前面提到的各种注册中心实现方式。我们同样无意对所有这些注册中心实现方式做详细展开,而是重点关注抽象 API 以及基于 Zookeeper 的实现方式。
我们首先来看一下 dubbo-registry-api 工程,这里面最核心的就是如下所示的 RegistryService 接口:
public interface RegistryService {
// 注册
void register(URL url);
// 取消注册
void unregister(URL url);
// 订阅
void subscribe(URL url, NotifyListener listener);
// 取消订阅
void unsubscribe(URL url, NotifyListener listener);
// 根据 URL 查询对应的注册信息
List<URL> lookup(URL url);
}请注意,RegistryService 所有操作的对象都是 URL,而订阅相关的操作中还附加了监听器 NotifyListener,确保变更信息的推送。从命名上我们已经可以初步猜想 Dubbo 在注册信息变更时采用的就是监听和通知机制。通过确认 NotifyListener 接口的定义更加明确了我们的猜想,因为该接口中只有一个 notify 方法,用于将发生变更的注册信息以 URL 的形式进行通知,如下所示:
public interface NotifyListener {
void notify(List<URL> urls);
}我们再来看 RegistryFactory 接口,如下所示。这里的 @SPI("dubbo") 注解我们会在后面介绍微内核模式时进行介绍,代表默认情况下使用 Dubbo 自身的注册中心。
@SPI("dubbo")
public interface RegistryFactory {
Registry getRegistry(URL url);
}从接口的命名上可以看出 RegistryFactory 是 Dubbo 中创建注册中心的工厂类,通过对 RegistryFactory 的实现,Dubbo 提供了 Zookeeper、Redis 等几种不同的注册中心实现方案。
可以说 Dubbo 中关于注册中心 API 层的抽象简单而清晰,比较适合先用来做对全局代码结构的把握。在这层 API 抽象之下,我们重点介绍 ZookeeperRegistry 和 ZookeeperRegistryFactory。
Zookeeper 注册中心实现过程
让我们来到 Dubbo 源码,来看一下 ZookeeperRegistry 的实现过程,而 ZookeeperRegistry 中最重要的就是它的构造函数,如下所示:
public ZookeeperRegistry(URL url, ZookeeperTransporter zookeeperTransporter) {
// ...
// 建立与 Zookeeper 的连接
zkClient = zookeeperTransporter.connect(url);
// 添加状态监听器
zkClient.addStateListener(new StateListener() {
public void stateChanged(int state) {
if (state == RECONNECTED) {
try {
recover();
} catch (Exception e) {
logger.error(e.getMessage(), e);
}
}
}
});
}可以看到,这里执行了两个操作,一个是与 Zookeeper 建立连接,另一个就是添加了用于断线重连的状态监听器。根据对 Zookeeper 基本操作的了解和掌握,上述实现过程都是使用 Zookeeper 时的常规步骤。
为了理解这段代码,我们需要明确另外两个核心对象的创建过程,这两个核心对象分别是 ZookeeperTransporter 和 ZookeeperClient。我们发现 ZookeeperTransporter 是在 ZookeeperRegistryFactory 工厂类创建 ZookeeperRegistry 时带进来的,如下所示:
public class ZookeeperRegistryFactory extends AbstractRegistryFactory {
private ZookeeperTransporter zookeeperTransporter;
public void setZookeeperTransporter(ZookeeperTransporter zookeeperTransporter) {
this.zookeeperTransporter = zookeeperTransporter;
}
public Registry createRegistry(URL url) {
return new ZookeeperRegistry(url, zookeeperTransporter);
}
}ZookeeperTransporter 本身是一个接口,定义也比较简单,就是根据传入的 URL 创建与 Zookeeper 服务器的连接并获取一个 ZookeeperClient 对象,如下所示:
@SPI("zkclient")
public interface ZookeeperTransporter {
@Adaptive({ Constants.CLIENT_KEY, Constants.TRANSPORTER_KEY })
ZookeeperClient connect(URL url);
}另一方面,在 ZookeeperClient 接口的定义中包含了注册中心运行过程中所有的数据操作,如创建和删除路径、获取子节点、添加和删除 Listener、获取 URL 等实现发布订阅模式的入口。这些方法名与 Zookeeper 原生操作基本一致,如下所示:
public interface ZookeeperClient {
void create(String path, boolean ephemeral);
void delete(String path);
List<String> getChildren(String path);
List<String> addChildListener(String path, ChildListener listener);
void removeChildListener(String path, ChildListener listener);
void addStateListener(StateListener listener);
void removeStateListener(StateListener listener);
boolean isConnected();
void close();
URL getUrl();
}目前可以与 Zookeeper 服务器进行交互的客户端有很多,Dubbo 中提供了对 Zkclient 和 Curator 这两个客户端工具的集成,对应的 Transporter 和 ZookeeperClient 实现类见下图。Dubbo 使用 Zkclient 作为其默认实现。
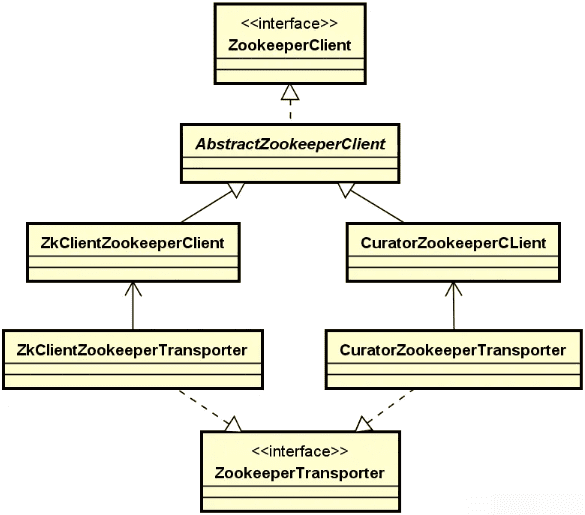
接下来终于到了分析注册中心具体操作的时候了,ZookeeperRegistry 提供了 doRegister、doUnregister、doSubscribe 和 doUnsubscribe 方法分别对应注册/取消注册、订阅/取消订阅这四个具体操作。
我们首先来看一下注册方法 doRegister,如下所示:
protected void doRegister(URL url) {
try {
zkClient.create(toUrlPath(url),
url.getParameter(Constants.DYNAMIC_KEY, true));
} catch (Throwable e) {
// ...
}
}不难看出,注册操作的实现方式就是在 Zookeeper 中创建一个节点。请注意,默认创建的节点都是临时节点,当连接断开之后会自动删除。对应的,我们也不难想象取消注册的实现方式就是删除这个临时节点,如下所示:
protected void doUnregister(URL url) {
try {
zkClient.delete(toUrlPath(url));
} catch (Throwable e) {
// ...
}
}我们再来看订阅过程。在订阅 URL 过程中,Dubbo 将传入的回调接口 NotifyListener 转换成 Zookeeper 中的 ChildListener,并主动根据服务提供者 URL 调用 NotifyListener。
doSubscribe 方法比较长,我们提取其中的核心代码,如下所示:
ChildListener zkListener = listeners.get(listener);
if (zkListener == null) {
// 添加子节点监听器
listeners.putIfAbsent(listener, new ChildListener() {
public void childChanged(String parentPath, List<String> currentChilds) {
for (String child : currentChilds) {
child = URL.decode(child);
if (!anyServices.contains(child)) {
anyServices.add(child);
subscribe(url.setPath(child).addParameters(Constants.INTERFACE_KEY, child, Constants.CHECK_KEY, String.valueOf(false)), listener);
}
}
}
});
zkListener = listeners.get(listener);
}可以看到,Dubbo 会订阅父级目录, 而当有子节点发生变化时就会触发 ChildListener 中的回调函数,该回调函数会对该路径下的所有子节点执行 subscribe 操作。
而取消订阅 URL 的过程实际上只是去掉 URL 上已经注册的监听器,doUnsubscribe 方法如下所示:
protected void doUnsubscribe(URL url, NotifyListener listener) {
ConcurrentMap<NotifyListener, ChildListener> listeners = zkListeners.get(url);
if (listeners != null) {
ChildListener zkListener = listeners.get(listener);
if (zkListener != null) {
// 取消子节点监听器
zkClient.removeChildListener(toUrlPath(url), zkListener);
}
}
}到此为止,ZookeeperRegistry 类中的构造函数和核心方法已经分析完毕。你看到这里可能会好奇,doRegister、doUnregister、doSubscribe 和 doUnsubscribe 这四个方法是在哪里被调用的呢?毕竟 ZookeeperRegistry 本来应该实现的是 RegistryService 接口中的 register、unregister、subscribe 和 unsubscribe 方法才对。
通过阅读代码,我们发现 ZookeeperRegistry 并不是 RegistryService 的直接实现类,从类层结构上,ZookeeperRegistry 扩展了 FailbackRegistry,而 FailbackRegistry 又扩展了 AbstractRegistry,注意 FailbackRegistry 和 AbstractRegistry 都是抽象类。而前面提到的这些方法在 RegistryService 不同层级的实现类中被调用,这里面涉及到的类层结构如下图所示:
我们继续往下看,发现真正调用 doRegister、doUnregister、doSubscribe 和 doUnsubscribe 这四个方法的地方分别是在 FailbackRegistry 对应的 register、unregister、subscribe 和 unsubscribe 方法中,这点自然比较好理解。但我们发现这四个方法还同时出现在 FailbackRegistry 的 retry 方法中。事实上,在 FailbackRegistry 构造函数中会创建一个定时任务,每隔一段时间执行该 retry 方法。
在这个 retry 方法,以注册场景为例(其他场景也类似),我们从注册失败的集合中获取 URL,然后对每个 URL 执行 doRegister 操作从而实现重新注册,如下所示:
if (!failedRegistered.isEmpty()) {
Set<URL> failed = new HashSet<URL>(failedRegistered);
if (failed.size() > 0) {
try {
for (URL url : failed) {
try {
// 重新注册
doRegister(url);
failedRegistered.remove(url);
} catch (Throwable t) {
// ...
}
}
} catch (Throwable t) {
// ...
}
}
}在 RegistryService 还有最后一个 lookup 方法,其作用是根据 URL 查询对应的注册信息。基于 Zookeeper,这个方法的实现也比较简单,我们只需要通过 Zookeeper 提供的 getChildren 方法获取某个 ZNode 的子节点即可,这里不做展开,你可以参加 Dubbo 源码进行学习。
解题要点
关于注册中心的基本模型是回答任何与这一主题相关面试题的基本要点。这部分内容属于理论知识,内容也比较固定。我们可以从注册中心的诞生背景、作用、组成结构等方面进行展开,并重点提及数据变更通知特性,这一特性体现了不同注册中心之间在设计理念和运行机制上的差别。
然后,关于注册中心的实现,我们需要结合具体场景和诉求来讨论。本讲中我们讨论的是 具备实时通知能力的注册中心模型,因此关注的是那些具有实时数据监听和推送功能的开源框架,例如 Zookeeper。Zookeeper 是一款非常经典的分布式协调框架,也是 Dubbo 框架的默认注册中心实现工具,所以在讨论过程中实际上也需要对 Dubbo 框架有足够的掌握。
从注册中心的实现类型而言,Zookeeper 是基于推送机制完成注册信息变更通知的代表性框架。Zookeeper 能够做到这一点是因为它内置了功能强大的监听器。当 Zookeeper 客户端通过会话机制与服务器建立连接并维持心跳检测之后,任何对 Zookeeper 节点的新增、更新和删除操作都会触发监听器上的回调函数,从而完成服务定义的动态更新。这是基于 Zookeeper 实现一款注册中心的核心流程。当然,我们在回答这道题时,也可以从 Zookeeper 中对服务注册信息的定义、存储等方面做进一步展开。
小结与预告
作为总结,我们明确注册中心就是这样一种服务治理工具:管理系统中所有服务实例的运行时状态,并能够把这些状态的变化同步到各个服务中。注册中心的实现有不同的策略,业界也诞生了一批不同类型的注册中心实现工具。本讲所阐述的 Zookeeper 是其中的代表性框架之一,具备实时通知能力。
请注意,并不是所有的注册中心都采用的是和 Zookeeper 一样的监听和推送机制,我们也可以采用定时更新策略来获取注册中心中最新的元数据。那么,如果采用定时更新策略来设计注册中心,这个过程有哪些注意点呢?这就是下一讲要讨论的内容。
注册中心:如果采用定时更新策略来设计注册中心,有哪些注意点?
上一讲我们进入到了注册中心这一技术组件的讨论,我们给出了注册中心的基本模型,并基于 Zookeeper 框架分析了 具备实时通知能力的注册中心 的实现方式。
本讲继续讨论注册中心,并关注另一种实现方式,即采用定时更新策略的注册中心。可以说,这两种注册中心的设计思想和实现方式完全不同。
那么,如果我们采用的是定时更新策略,应该如何获取最新的服务实例元数据呢?本讲内容将围绕这个话题进行展开。在日常开发过程中,关于定时更新策略的应用场景实际上非常多,也是面试过程中经常会出现的考查点。因此,本讲内容中所介绍的实现过程中也有很多值得深入分析和学习的开发和面试技巧。
问题背景
与注册中心相关的问题背景,我们在上一讲中已经介绍了很多,这里不再重复展开。在本讲中,因为我们是围绕 如果采用定时更新策略来设计注册中心 这一话题进行展开,所以这里也列举在面试过程中与这个话题相关的一些常见面试题:
- 如果采用轮询机制来获取注册中心中的数据,你会选择什么样的实现技术?
- 在定时更新过程中,客户端如何判断位于注册中心中的数据已经发生了变化?
- 注册中心中的服务实例信息怎么存储才合理?
- 如果想要提高定时获取注册中心中数据的效率,你有什么策略?
可以看到,虽然我们讨论的都是注册中心,但是从面试角度讲,不同的注册中心实现方式,对应的面试题也会采用不同的切入点。
问题分析
关于这类面试题的回答思路和上一讲中介绍的内容是类似的,你可以回顾上一讲中问题分析部分,这里不做重复展开。但是,因为本讲关注的是采用定时更新策略的注册中心实现方式,所以需要基于这点进行具体分析。和推送机制不同,定时策略在设计和实现上需要考虑以下几点。
- 定时策略:基于什么样的时机触发轮询操作?
- 同步数据:同步什么样的数据?同步多少数据?
- 同步效率:如何降低轮询过程中不必要的性能损耗?
请注意,在基于推送机制构建注册中心的实现过程中,上述问题都是不需要考虑的。根本原因在于推送是一种被动式的处理机制,注册中心的客户端不需要关注什么时候会推送,而只需要在合适的时机触发回调函数即可。而定制更新策略则不同,体现的一种主动式的处理机制,注册中心的客户端在与服务器进行交互的过程中不得不考虑上述问题。而这些问题的背后,也包含了对应的技术实现方式,让我们一起来看一下。
技术体系
如果我们采用定时更新策略,那么从架构设计上讲,比较容易想到的方式是采用轮询机制。轮询机制是一种主动拉取策略,即服务的消费者定期调用注册中心提供的元数据获取接口获取最新的服务实例列表并更新本地缓存,如下图所示:
在上图中,我们看到轮询机制实现上就是一个定时器,需要考虑定时的频率以确保数据同步的时效性。
针对上图中的执行流程,我们要引出的一款注册中心实现工具是 Netflix 的 Eureka。Eureka 的基本架构由 Eureka 服务器、服务提供者和服务消费者这 3 个逻辑角色所组成,并与上一讲中介绍的服务注册中心模型具有高度一致性。虽然 Eureka 2.0 经历了诸多变故之后目前处于停止更新状态,但作为一款经典的基于轮询机制来实现服务实例状态同步的开源框架,其内部的设计思想和底层原理还是值得我们深入分析,尤其是在缓存设计和增量获取更新内容等方面的实现技巧对于日常开发过程而言也非常具有参考价值,我们可以基于这些技巧来应对类似场景下的实现需求。
我们在对 Eureka 进行进一步展开,可以得到如下图所示的注册中心模型图:
在上图中,Eureka 有以下几个操作与服务治理直接相关。
- 服务注册(Register):将各种元数据注册到注册中心。
- 服务续约(Renew):发送定时心跳进行续约。
- 服务下线(Cancel):客户端主动下线。
- 服务剔除(Eviction):客户端在长时间没有续约的情况下被动下线。
另外,遵循上一讲中给出的注册中心的基本模型,Eureka 客户端也具备本地缓存机制。Eureka 在实现这一过程中使用了非常巧妙的实现方法,我们在后续内容中会具体展开。
在介绍 Eureka 时,我们采用的思路与上一节中介绍 Zookeeper 不同。在介绍 Zookeeper 时,我们更多的是从 Zookeeper 这一特定工具本身出发进行展开,而这里我们的切入点是注册中心各个角色本身的特点以及它们之间的交互流程。我们首先来看 Eureka 服务器端的工作原理。
源码解析
Eureka 服务器端基本原理
对于 Eureka 服务器端,我们关注两个方面,即服务实例元数据的存储和缓存。
如同讨论 Zookeeper 一样,对于一个注册中心而言,我们首先需要关注它的数据存储方法。在 Eureka 中,用于保存服务实例信息的数据结构实际上是一个双层的 HashMap,采用的是 JDK 中线程安全的 ConcurrentHashMap,如果用图形化的表达方式来展示这种数据结构,可以参考下图:
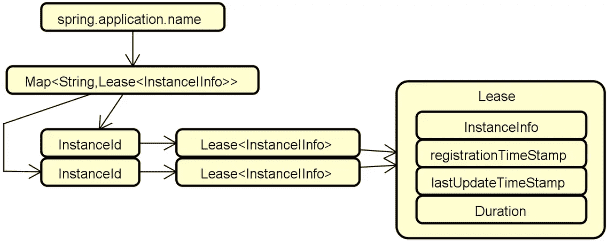
可以看到,Eureka 按照应用名称(spring.application.name)和服务实例 Id(instanceId)来构建两层结构。然后,Eureka 使用了 Lease(租约)这个概念来对服务的元数据进行抽象。围绕 Lease,Eureka 提供了如下所示的 LeaseManager 接口来对其进行管理,该接口的方法与前面介绍的几个核心操作是一一对应的。
public interface LeaseManager<T> {
// 服务注册
void register(T r, int leaseDuration, boolean isReplication);
// 服务下线
boolean cancel(String appName, String id, boolean isReplication);
// 服务续约
boolean renew(String appName, String id, boolean isReplication);
// 服务剔除
void evict();
}本质上,LeaseManager 中的各个方法的执行流程都只是围绕双层的存储结构展开操作而已,比较类似。我们这里选择用于执行服务注册操作的 register 方法进行展开,register 方法非常长,我们对源码进行裁剪,得出如下所示的重点处理流程:
public void register(InstanceInfo registrant, int leaseDuration, boolean isReplication) {
try {
read.lock();
// 从已存储的 registry 获取一个服务定义
Map<String, Lease<InstanceInfo>> gMap = registry.get(registrant.getAppName());
REGISTER.increment(isReplication);
if (gMap == null) {
// 初始化一个 Map<String, Lease<InstanceInfo>>,并放入 registry 中
}
// 根据当前注册的 ID 能找到对应的 Lease
Lease<InstanceInfo> existingLease = gMap.get(registrant.getId());
if (existingLease != null && (existingLease.getHolder() != null)) {
// 如果能找到,根据时间确定以哪个实例为准
} else {
// 如果找不到,设置续约数量及其阈值参数
}
// 创建一个新 Lease 并放入 Map 中
Lease<InstanceInfo> lease = new Lease<InstanceInfo>(registrant, leaseDuration);
if (existingLease != null) {
lease.setServiceUpTimestamp(existingLease.getServiceUpTimestamp());
}
gMap.put(registrant.getId(), lease);
synchronized (recentRegisteredQueue) {
// 同步更新 recentRegisteredQueue
}
// 处理服务的 InstanceStatus
registrant.setActionType(ActionType.ADDED);
// 更新服务最新更新时间
registrant.setLastUpdatedTimestamp();
// 刷新缓存
invalidateCache(registrant.getAppName(), registrant.getVIPAddress(), registrant.getSecureVipAddress());
} finally {
read.unlock();
}
}可以看到,整个 register 方法完成的就是对 Map 中数据的更新过程,这里我们针对服务注册的各个核心操作添加了注释。需要注意的是,在更新完 Map 中数据之后,Eureka 还会通过 invalidateCache 执行刷新缓存操作,这就引出我们接下来要讨论的话题,即 Eureka 服务缓存机制。
Eureka 服务器端组件的另一个核心功能是提供服务列表,为了提高性能,服务列表在 Eureka 服务器会缓存一份,并通过一定的定时机制进行更新。
在 Eureka 中,ApplicationResource 类提供了根据应用获取注册信息的入口。我们来看该类的 getApplication 方法,核心代码如下所示:
Key cacheKey = new Key(
Key.EntityType.Application,
appName,
keyType,
CurrentRequestVersion.get(),
EurekaAccept.fromString(eurekaAccept)
);
String payLoad = responseCache.get(cacheKey);
// ....可以看到这里是构建了一个 cacheKey,并直接调用了 responseCache.get(cacheKey) 方法来返回一个字符串并构建响应。从命名上看,不难想象这里使用了缓存机制。在 ResponseCache 的 get 方法中,我们发现它使用了如下所示的处理策略:
Value getValue(final Key key, boolean useReadOnlyCache) {
Value payload = null;
try {
if (useReadOnlyCache) {
final Value currentPayload = readOnlyCacheMap.get(key);
if (currentPayload != null) {
payload = currentPayload;
} else {
payload = readWriteCacheMap.get(key);
readOnlyCacheMap.put(key, payload);
}
} else {
payload = readWriteCacheMap.get(key);
}
} catch (Throwable t) {
logger.error("Cannot get value for key : {}", key, t);
}
return payload;
}可以看到上述代码中有两个缓存,一个是 readOnlyCacheMap,一个是 readWriteCacheMap。其中 readOnlyCacheMap 就是一个 JDK 中的 ConcurrentMap,而 readWriteCacheMap 则是 Guava Cache 库中的 LoadingCache 类型。
把缓存设计为一个只读的 readOnlyCacheMap 以及一个可读写的 readWriteCacheMap,这是一种设计上的技巧,可以更好地分离职责。但因为两个缓存中保存的实际上是同一份数据,所以,我们在不断更新 readWriteCacheMap 的同时,也需要确保 readOnlyCacheMap 中的数据得到同步。为此 ResponseCacheImpl 提供了一个定时任务 CacheUpdateTask,如下所示:
private TimerTask getCacheUpdateTask() {
return new TimerTask() {
@Override
public void run() {
for (Key key : readOnlyCacheMap.keySet()) {
try {
CurrentRequestVersion.set(key.getVersion());
Value cacheValue = readWriteCacheMap.get(key);
Value currentCacheValue = readOnlyCacheMap.get(key);
if (cacheValue != currentCacheValue) {
// 更新 readOnlyCacheMap
readOnlyCacheMap.put(key, cacheValue);
}
} catch (Throwable th) {
// ...
}
}
}
};
}显然,这个定时任务主要是从 readWriteCacheMap 更新数据到 readOnlyCacheMap。
Eureka 客户端基本原理
介绍完服务器端基本原理,我们来看 Eureka 客户端组件的实现方式。服务的提供者和消费者都是注册中心的客户端,其中服务的提供者主要完成服务注册等操作,这部分的内容主要依赖于前面介绍的服务端能力,我们不再具体展开。在接下来的内容中,我们重点关注的是服务的消费者如何定时获取位于服务器上的服务实例信息,以及如何构建属于它自身的本地缓存。
对于 Eureka 而言,作为客户端核心组件的 DiscoveryClient 类具备缓存功能。DiscoveryClient 中的 initScheduledTasks 方法用于初始化各种调度任务,对于缓存刷新而言,调度器的初始化过程如下所示:
if (clientConfig.shouldFetchRegistry()) {
int registryFetchIntervalSeconds = clientConfig.getRegistryFetchIntervalSeconds();
int expBackOffBound = clientConfig.getCacheRefreshExecutorExponentialBackOffBound();
scheduler.schedule(
new TimedSupervisorTask(
"cacheRefresh",
scheduler,
cacheRefreshExecutor,
registryFetchIntervalSeconds,
TimeUnit.SECONDS,
expBackOffBound,
new CacheRefreshThread()
),
registryFetchIntervalSeconds,
TimeUnit.SECONDS
);
}显然,这里启动了一个调度任务并通过一个 CacheRefreshThread 线程完成具体操作,系统默认是每隔 30 秒刷新本地存储的服务实例数据。在这个线程中,我们发现在进行一系列的校验之后,最终调用了 DiscoveryClient 中的 fetchRegistry 方法完成对服务注册信息的获取。该方法如下所示(为了简单起见,对代码进行了部分裁剪,只保留主流程):
private boolean fetchRegistry(boolean forceFullRegistryFetch) {
try {
// 获取应用
Applications applications = getApplications();
if (condition) { // 如果满足全量拉取条件
// 全量拉取服务实例数据
getAndStoreFullRegistry();
} else {
// 增量拉取服务实例数据
getAndUpdateDelta(applications);
}
// 重新计算和设置一致性 hashcode
applications.setAppsHashCode(applications.getReconcileHashCode());
}
// 刷新本地缓存
onCacheRefreshed();
// 基于缓存中的实例数据更新远程实例状态
updateInstanceRemoteStatus();
// 注册表拉取成功后返回 true
return true;
}上述代码中带注释的几个方法都非常有用,因为 getAndStoreFullRegistry 方法的逻辑相对比较简单,我们将重点介绍 getAndUpdateDelta 方法,以便学习在 Eureka 中如何实现增量数据更新的设计技巧。裁剪之后的 getAndUpdateDelta 方法代码下所示:
private void getAndUpdateDelta(Applications applications) throws Throwable {
long currentUpdateGeneration = fetchRegistryGeneration.get();
Applications delta = null;
// 通过 eurekaTransport.queryClient 获取增量信息
EurekaHttpResponse<Applications> httpResponse = eurekaTransport.queryClient.getDelta(remoteRegionsRef.get());
if (httpResponse.getStatusCode() == Status.OK.getStatusCode()) {
delta = httpResponse.getEntity();
}
if (delta == null) {
// 如果增量信息为空,就直接发起一次全量更新
getAndStoreFullRegistry();
} else if (fetchRegistryGeneration.compareAndSet(currentUpdateGeneration, currentUpdateGeneration + 1)) { // 通过 CAS 来确保请求的线程安全性
String reconcileHashCode = "";
if (fetchRegistryUpdateLock.tryLock()) {
try {
// 用 Eureka 返回的增量数据和本地数据做合并操作
updateDelta(delta);
// 用合并了增量数据之后的本地数据来生成一致性 hashcode
reconcileHashCode = getReconcileHashCode(applications);
} finally {
fetchRegistryUpdateLock.unlock();
}
} else {
// ...
}
// 比较本地数据中的 hashcode 和来自服务器端的 hashcode
if (!reconcileHashCode.equals(delta.getAppsHashCode()) || clientConfig.shouldLogDeltaDiff()) {
// 如果 hashcode 不一致,就触发远程调用进行全量更新
reconcileAndLogDifference(delta, reconcileHashCode);
}
} else {
// ...
}
}结合 Eureka 服务器端基本原理,我们知道 Eureka 服务器端会保存一个服务注册列表的缓存。在 Eureka 官方文档中提到 Eureka 服务器会把更新数据保留 3 分钟,而 Eureka 客户端通过前面介绍的定时机制会每隔 30 秒刷新本地缓存。原则上,只要 Eureka 客户端不停地获取服务器端的更新数据,就能保证自己的数据和 Eureka 服务器端的保持一致。但如果客户端在 3 分钟之内没有获取更新数据,就会导致自身与服务器端的数据不一致。
为了解决这个问题,Eureka 采用了一种叫做一致性 HashCode(ReconcileHashCode) 的实现机制。Eureka 服务器端每次返回的增量更新数据中都会带有一个 HashCode,Eureka 客户端用本地服务实例信息算出的 HashCode 应该和 Eureka 服务器返回的一致,若不一致就证明增量更新出现了问题,导致客户端和服务器端上的服务实例信息不一致了,此时需要全量更新。
在 Eureka 中,计算一致性 HashCode 的方法如下所示,可以看到这一方法基于服务实例信息完成一个 String 类型的 HashCode 计算过程。
public static String getReconcileHashCode(Map<String, AtomicInteger> instanceCountMap) {
StringBuilder reconcileHashCode = new StringBuilder(75);
for (Map.Entry<String, AtomicInteger> mapEntry : instanceCountMap.entrySet()) {
reconcileHashCode.append(mapEntry.getKey()).append(STATUS_DELIMITER).append(mapEntry.getValue().get())append(STATUS_DELIMITER);
}
return reconcileHashCode.toString();
}作为总结,Eureka 客户端缓存定时更新的流程下所示,可以看到它与服务注册的流程基本一致。也就是说在 Eureka 中,服务提供者和服务消费者作为 Eureka 服务器的客户端采用了同一套体系完成与服务器端的交互。
Eureka 客户端和服务器端的差异化信息计算和获取过程,是这种更新机制所必须要考虑的问题,也是我们自己在设计类似场景时的注意点。我们可以从上述实现原理中掌握优秀开源框架底层的开发技巧。
解题要点
对于本讲中所讨论的话题,面试过程中第一个需要明确的要点就是基于定时更新机制的注册中心实现机制。相较上一讲介绍的推送机制,定时更新机制的概念容易理解,基本的实现策略也比较简单。通常,我们采用一些定时器实现工具和框架对位于服务器上的服务实例信息进行轮询即可。
但是需要注意,定时更新机制有它自身的复杂度,我们需要综合考虑定时策略、同步数据、同步效率等问题,这些问题是这种机制所特有的,在面试过程中需要重点对这些机制展开讨论。这是面试官的考查重点,也能很好展现候选人的竞争力。对于这些机制的讨论,我们可以分成两个步骤,首先阐述这些机制背后的设计思想,然后再来结合具体框架给出底层的实现原理分析。
至于具体的开源框架,和上一讲中所提到的 Zookeeper 相比,定时更新机制类框架采用的是另一套完全不同的实现策略。我们在回答过程中需要基于特定的技术要点来进行分析。
举例来说,针对 Eureka 客户端从服务器端获取注册信息 这一特定的细节,回答难度实际上很大。而至于为什么要问这一特定细节,在于 Eureka 在实现这一细节上提供了一种处理增量数据的开发技巧和工程实践,值得我们深入学习和应用。我们知道,当执行轮询操作时,需要考虑的一大问题就是如何高效地从服务端获取最新的服务实例信息。为了提高效率、降低网络通信的开销,一般都会考虑引入 增量 数据获取的设计思想,Eureka 也采用了这种机制。具体来讲,Eureka 采用了一种叫做一致性 HashCode 的实现机制。
如果我们能够结合本讲中介绍的这种增量式数据获取方式,那么相信能够获得面试官的更多认同。这也是我在具体面试过程中的一条经验,即对于那些普通的知识点,建议不用过多展开,但我们可以多围绕框架本身所具备的一些特有的设计和开发技巧给出自己的分析和总结。
小结与预告
本讲介绍了实现注册中心的另一种常见的策略,即基于定时更新策略来实现客户端与服务端之间元数据的有效同步。这是很多注册中心所采用的实现策略,设计思想简单,应用也很广泛。我们结合老牌的注册中心开源框架 Eureka 对这一主题进行了详细展开,并分析了该框架在实现这一主题过程中所具备的开发技巧。一方面,这些开发技巧是面试过程中的回答要点,另一方面,我们也可以结合具体的场景把这些开发技巧应用到日常开发过程中。
在分布式系统中,当服务的数量达到一定规模时,我们就不建议客户端对这些服务直接发起远程请求了。这时候,我们可以引入服务网关这一技术组件。那么,如何实现一款高性能服务网关?下一讲将围绕这个话题展开讨论。
服务网关:如何实现一款高性能服务网关?
在上一讲中,我们引入了注册中心这一技术组件来构建分布式系统。通过注册中心,我们可以对系统中存在的服务进行有效治理。一旦服务得到了治理,下一步就可以对这些服务发起访问了。
这个过程并不复杂,但也没有我们想象的那么简单,因为客户端请求和服务端所提供的访问入口之间需要进行粒度匹配、路由、安全等一系列控制。为了实现这些控制,服务网关(Gateway) 也就应运而生了。
那么,什么是服务网关?如何构建一款高性能服务网关?这是面试过程中的常见话题。本讲内容将给出这些问题的具体答案。
问题背景
在分布式架构中,如果客户端和各个服务直接进行交互,可能会出现很多问题。通常,每个服务的职责在于提供某一个业务领域的访问入口,而客户端则一般都需要整合多项业务数据。这就会导致客户端的请求和服务提供的访问入口在粒度上是不一致,导致客户端不得不发送多个请求才能获取所想要的数据。另一方面,在这种场景下,如果某个服务发生了调整,很可能会导致客户端需要做相应的调整,这显然是不合理的。
下图展示了服务版本升级的一种演进结构:
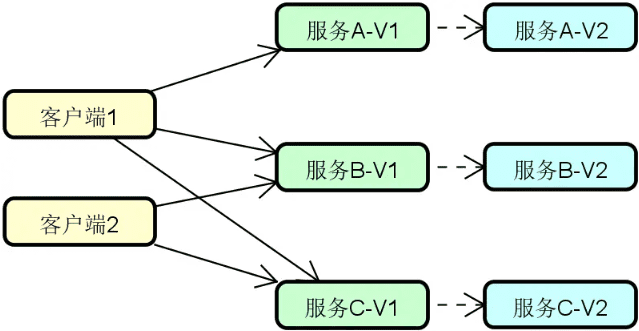
在这样的背景下,我们可以根据需要在客户端和服务端之间架设一层服务网关,从而满足前面提到的各种需求。而在分布式系统的构建过程中,一个核心要点就是需要确保所有来自客户端的请求都通过服务网关再路由和转发到后端服务,这样我们就可以在网关层对请求本身进行统一的处理。
从架构设计角度讲,服务网关的出现有其必然性。而围绕服务网关的构建过程,也存在一些我们不得不去思考的问题。这些问题是面试过程中考查的重点,常见的包括:
- 服务网关存在的必要性和作用是什么?
- 服务网关的基本结构是怎么样的?
- 服务网关如何实现请求的路由和转发?
- 你熟悉的服务网关工具有哪些?各自有什么功能上的特性?
- 如果让你在服务网关中添加安全性控制机制,你会怎么做?
- 如果想要在网关层对请求进行限流,可以采用怎么样的实现方式?
上述问题都很经典,是面试过程中的常考题,需要你引起重视。接下来,我们从面试角度出发对这些问题做进一步分析。
问题分析
在当下的分布式系统开发过程中,服务网关已经成为必不可少的一个技术组件。关于服务网关的相关工具和框架也层出不穷。虽然,每个网关工具在部署和使用方式上各有不同,但它们的架构本质上是非常类似的。和前面介绍的注册中心相比,服务网关在定位上更偏向是一种底层的中间件,通用性很强,所以我们可以比较容易地对它的作用、组成结构以及功能特性进行抽象和提炼。这部分内容更多的是理论知识,需要候选人熟练掌握。
掌握了概念之后,接下来就是具体的开源框架。
对于服务网关而言,实际上它所具备的核心功能还是请求转发机制,所以,很多请求响应类的框架所要面临的技术难点服务网关同样也需要面对。典型的就是性能问题,如何构建高性能的请求转发机制是我们在分析具体网关框架时的一个切入点,也是面试过程中的常见考点。
最后,服务网关类的面试题经常会考查候选人对某一个特定功能特性的掌握程度,比方说网关的路由机制、安全性机制、限流机制等。候选人在回答这些问题时,需要结合自己擅长的框架做深入的研究,并能够从原理出发给出自己的总结和思考。
在本讲中,我们将要深入分析的是 Spring Cloud 家族的 Spring Cloud Gateway 框架。而在此之前,让我们先从服务网关的基本概念开始讲起。
技术体系
服务网关的概念本质上不难理解,从设计模式上讲,我们也可以把服务网关看作是门面(Facade)模式的一种具体表现形式。门面模式的作用就是把复杂度屏蔽在系统内部,从而降低耦合度,如下图所示:
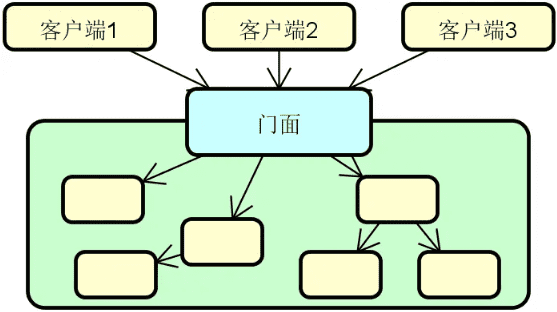
既然是一种门面,那么网关中显然不应该包含任何与业务相关的处理逻辑。那么,服务网关的核心作用究竟有哪些呢?主要包括三部分,即解耦、适配和数据聚合。
-
解耦:从技术架构而言,任何组件之间的交互都应该具备较低的耦合度。正如我们在问题背景部分所讨论的,客户端请求和服务端访问入口之间的依赖关系需要确保独立,即服务端背后的功能演进和版本升级过程对于客户端而言应该是透明的。考虑到分布式系统中往往存在大量服务,解耦也是我们在服务体系过程中的一项核心目标。
-
适配:在分布式系统中,客户端的类型也是多样的。当我们面对多个不同类型的客户端时,考虑到页面展示上的差异性,往往需要针对特定的客户端请求提供特定的响应结果,哪怕这些请求属于同一业务场景。
举个例子,分页是一种常见的数据返回效果,但不同客户端对分页数量的要求可能就是不一样的,如下图所示:
![2024 11 15 11 53 01]()
-
数据聚合:对来自不同服务的数据进行聚合并统一返回给客户端,这种聚合过程视场景而定,可以在一次请求中返回一组业务数据,从而降低客户端访问服务端的次数,提升系统的性能。
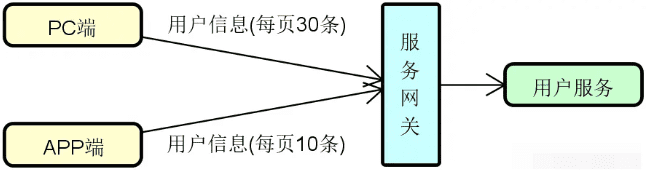
介绍完网关的作用,我们接下来看它所具备的基本结构和功能,如下图所示:
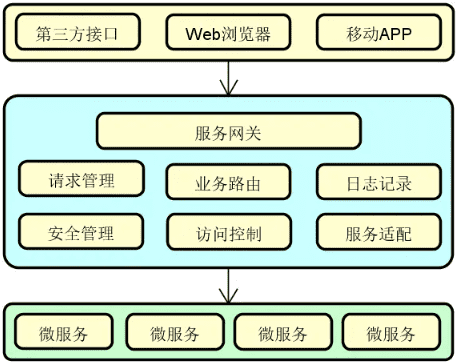
总体而言,服务网关为分布式环境下的请求处理过程提供了强大的定制化技术能力,常见的扩展性、伸缩性、安全性和可用性等架构设计上的技术点在网关中都能得到体现。
从扩展性和伸缩性角度讲,网关提供了服务路由支持,我们可以在网关层添加各种路由规则,确保来自客户端的请求能够以合适的方式发送到目标服务。在这个过程中,我们可以很轻松地实现请求转发、系统扩容等操作。
一般而言,对于来自客户端的任何请求都需要考虑安全性,而服务网关最适合来完成这部分操作。实现访问安全性的前提是用户认证,我们可以在网关层添加各种身份认证、黑白名单、Token 校验等常见的安全性控制手段。
最后,我们需要强调一下服务网关所具备的访问控制功能。在高并发系统中,我们通常会采用限流和降级等手段来防止服务出现不可用。这时候,我们就可以在服务网关上设置对应阈值或规则,从而确保来自客户端的请求不会流转到后台服务。
源码解析
介绍完服务网关的作用和结构之后,我们接下来讨论具体的实现工具。这里,我们来到 Spring 家族中的 Spring Cloud Gateway 框架,这是目前最主流的服务网关之一。
Spring Cloud Gateway 架构
Spring Cloud Gateway 的核心功能是对 Web 请求进行路由和过滤,其内部大量依赖于 Spring 中的响应式 Web 框架 WebFlux。
在接下来的内容中,我们先来分析 Spring WebFlux 技术栈,然后在此基础上引出 Spring Cloud Gateway 的整体架构。针对 Spring Cloud Gateway 这款框架,我建议你把它和 WebFlux 对比起来一起分析,这是一种非常有效的学习方法。
虽然 WebFlux 和 WebMVC 是两个时代的技术体系,但事实上,Spring 也为传统 WebMVC 中的 HandlerMapping、HandlerAdapter 等组件提供了对应的响应式版本。这也体现了 Spring 所采用的一种设计理念,即充分利用现有组件进行增强,而不是轻易地替换。
我们知道传统的 Servlet API 是阻塞式的,所以我们需要引入 ServerHttpRequest 和 ServerHttpResponse 这两个对象。在 WebFlux 中,它们分别代表着请求和响应本身。类似的,作为请求处理的核心组件,我们也需要引入一个新的过滤器链 WebFilterChain,定义如下所示:
public interface WebFilterChain {
Mono<Void> filter(ServerWebExchange exchange);
}请注意,我们在这里并没有看到 ServerHttpRequest 和 ServerHttpResponse 这两个对象。实际上,上述代码中的 ServerWebExchange 内置了这两个对象,相当于是一个请求上下文。另一方面,我们发现 filter 方法返回的是一个 Mono 对象,也就意味着整个调用链路使用了响应式编程的开发模式。
前面提到,HandlerMapping、HandlerAdapter 等核心对象在 WebFlux 中都能找到对应的实现,我们接下来看一下它们的定义,如下所示:
public interface HandlerMapping {
Mono<Object> getHandler(ServerWebExchange exchange);
}
public interface HandlerAdapter {
Mono<HandlerResult> handle(ServerWebExchange exchange, Object handler);
}类似的,WebMVC 中的 RequestMappingHandlerMapping 和 RequestMappingHandlerAdapter 等对象也同样存在响应式版本。但是请注意,WebFlux 还专门提供了一套新的技术组件用来提供函数式编程的开发模式,这套组件就是 RouterFunctionMapping 和 HandlerFunctionAdapter。
整个 WebFlux 的架构如下图所示:
对 WebFlux 有了基本认识之后,我们来讨论 Spring Cloud Gateway。就请求响应模式而言,可以说 Spring Cloud Gateway 和 WebFlux 采用的是完全一样的处理方式。但 Spring Cloud Gateway 内部也提出了两个核心概念,一个是过滤器(Filter),一个是谓词(Predicate),它的整体架构如下图所示:
Spring Cloud Gateway 中的过滤器和 WebFlux、WebMVC 中的过滤器是同一个概念,都可以用于在响应 HTTP 请求之前或之后修改请求本身及对应的响应结果,区别在于两者的类型和实现方式。
而所谓谓词,本质上是一种判断条件,用于将 HTTP 请求与路由进行匹配。Spring Cloud Gateway 内置了大量的谓词组件,可以分别基于 HTTP 请求的消息头、请求路径等常见的路由媒介进行自动匹配以便决定路由结果。
Spring Cloud Gateway 工作流程
Spring Cloud Gateway 中的核心概念就是路由和过滤,我们通过谓词判断获取 Web 请求的路由,然后基于一组过滤器执行过滤,并最终输出结果。在讨论具体的过滤器实现过程之前,我们先来关注整个请求处理流程。
我们知道 Spring MVC 中有一个核心类 DispatcherServlet,而 WebFlux 中对应的核心类是 DispatcherHandler,该类充当着所有请求的入口,如下图所示:
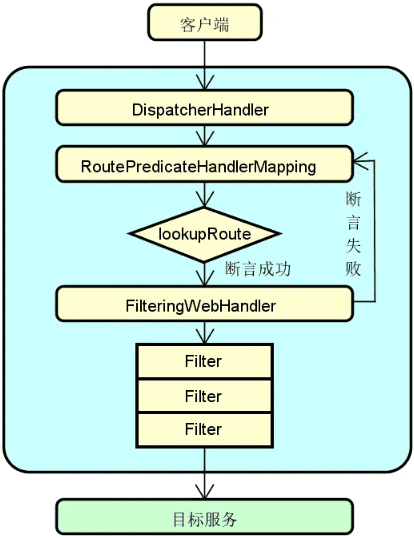
上图中,DispatcherHander 的 handler 方法用来匹配不同的 HandlerMapping 并处理请求,如下所示:
@Override
public Mono<Void> handle(ServerWebExchange exchange) {
if (this.handlerMappings == null) {
return createNotFoundError();
}
return Flux.fromIterable(this.handlerMappings)
.concatMap(mapping -> mapping.getHandler(exchange))
.next()
.switchIfEmpty(createNotFoundError())
// 这里根据获取到的 handler 进行处理
.flatMap(handler -> invokeHandler(exchange, handler))
.flatMap(result -> handleResult(exchange, result));
}这时候,DispatcherHander 就能在一组 handlerMappings 找到 RoutePredicateHandlerMapping,而这个 RoutePredicateHandlerMapping 也是在自动配置类 GatewayAutoConfiguration 中进行装配的,如下所示:
public class GatewayAutoConfiguration {
@Bean
public RoutePredicateHandlerMapping routePredicateHandlerMapping(FilteringWebHandler webHandler, RouteLocator routeLocator, GlobalCorsProperties globalCorsProperties, Environment environment) {
return new RoutePredicateHandlerMapping(webHandler, routeLocator, globalCorsProperties, environment);
}
}虽然在 DispatcherHander 的 handler 方法中,使用的是响应式编程的代码语法,但整个流程和 Spring MVC 中的处理机制非常类似。而在 RoutePredicateHandlerMapping 中,通过 getHandlerInternal 方法获取了当前请求的路由信息并放入了上下文中。注意到在这个方法中存在一个 lookupRoute 方法,该方法用来查找真正的路由信息,如下所示:
protected Mono<Route> lookupRoute(ServerWebExchange exchange) {
return this.routeLocator.getRoutes()
.concatMap(
route -> Mono.just(route).filterWhen(r -> {
exchange.getAttributes().put(GATEWAY_PREDICATE_ROUTE_ATTR, r.getId());
// 根据断言获取到真正的 Route
return r.getPredicate().apply(exchange);
})
.doOnError()
.onErrorResume(e -> Mono.empty())
)
.next()
.map(route -> {
// ...
// 自定义的路由校验方法入口
validateRoute(route, exchange);
return route;
});
}显然,这里通过断言来获取路由信息。一旦获取路由信息之后,下一步就是加载各种过滤器了,这时候就来到了 FilteringWebHandler。该类实现了 WebHandler 接口,并在它的构造函数中通过一个 loadFilters 方法加载过滤器,如下所示:
public class FilteringWebHandler implements WebHandler {
protected static final Log logger = LogFactory.getLog(FilteringWebHandler.class);
private final List<GatewayFilter> globalFilters;
public FilteringWebHandler(List<GlobalFilter> globalFilters) {
this.globalFilters = loadFilters(globalFilters);
}
// 将传入的 GlobalFilter 转化为 GatewayFilter
private static List<GatewayFilter> loadFilters(List<GlobalFilter> filters) {
return filters.stream().map(filter -> {
GatewayFilterAdapter gatewayFilter = new GatewayFilterAdapter(filter);
if (filter instanceof Ordered) {
int order = ((Ordered) filter).getOrder();
return new OrderedGatewayFilter(gatewayFilter, order);
}
return gatewayFilter;
}).collect(Collectors.toList());
}
// …
}可以看到,上述 loadFilters 方法的作用就是将传入的 GlobalFilter 转化为 GatewayFilter,关于这两类过滤器我们后面还会介绍。
我们接着来看 FilteringWebHandler 的 handle 方法,如下所示:
@Override
public Mono<Void> handle(ServerWebExchange exchange) {
// 从 ServerWebExchange 获取 Route
Route route = exchange.getRequiredAttribute(GATEWAY_ROUTE_ATTR);
// 从 Route 获取到 Filter
List<GatewayFilter> gatewayFilters = route.getFilters();
// 将 GlobalFilter 和路由的 Filter 合并
List<GatewayFilter> combined = new ArrayList<>(this.globalFilters);
combined.addAll(gatewayFilters);
// 对 Filter 排序
AnnotationAwareOrderComparator.sort(combined);
// 创建 FilterChain 并执行过滤
return new DefaultGatewayFilterChain(combined).filter(exchange);
}上述方法中的几个步骤都很明确,而这里出现的 DefaultGatewayFilterChain 就是一种过滤器链,用来基于该链中的各个过滤器执行过滤操作,具体如下所示:
@Override
public Mono<Void> filter(ServerWebExchange exchange) {
return Mono.defer(() -> {
if (this.index < filters.size()) {
GatewayFilter filter = filters.get(this.index);
DefaultGatewayFilterChain chain = new DefaultGatewayFilterChain(this, this.index + 1);
return filter.filter(exchange, chain);
} else {
return Mono.empty();
}
});
}显然,DefaultGatewayFilterChain 是一种典型的管道过滤器架构模式的应用方式,关于这一架构模式我们在后面还会有详细的讨论。
在 Spring Cloud Gateway 中内置了许多过滤器,这些过滤器可以分成两大类,即 GatewayFilter 和 GlobalFilter,正如我们在前面的 FilteringWebHandler 中所看到的。其中,GatewayFilter 通过配置作用于每次路由,而 GlobalFilter 则作用于所有的请求。当一个请求被匹配到对应路由时,会将 GlobalFilter 和已绑定路由的 GatewayFilter 合并到一起。所有的过滤器都实现了 org.springframework.core.Ordered 接口,因此会根据过滤器的 Order 值进行排序。
在这里,我们无意对所有的过滤器做一一展开,而是挑选其中具有代表性的一个过滤器,并对它的实现过程进行分析,从而帮助你更好地理解过滤器的具体运行原理。
这里我们以 RouteToRequestUrlFilter 为例来分析过滤器的实现机制,该过滤器用于根据 RouteUri 生成请求的真正 URL,并放入请求上下文中供后续 Filter 使用。RouteToRequestUrlFilter 的 filter 方法如下所示:
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
Route route = exchange.getAttribute(GATEWAY_ROUTE_ATTR);
if (route == null) {
return chain.filter(exchange);
}
// 获取请求的 URI
URI uri = exchange.getRequest().getURI();
// 判断是否包含诸如 % 等的编码部分内容
boolean encoded = containsEncodedParts(uri);
// 获取 Route 的 uri
URI routeUri = route.getUri();
// 判断是否为其他类型的协议,如果是则根据特定协议生成 URI
if (hasAnotherScheme(routeUri)) {
// 将当前请求的 schema 放入上下文中
exchange.getAttributes().put(GATEWAY_SCHEME_PREFIX_ATTR, routeUri.getScheme());
routeUri = URI.create(routeUri.getSchemeSpecificPart());
}
// 如果 RouteUri 以 lb 开头,则请求中必须带有 host,否则直接抛出异常
if ("lb".equalsIgnoreCase(routeUri.getScheme()) && routeUri.getHost() == null) {
throw new IllegalStateException("Invalid host: " + routeUri.toString());
}
// 生成请求 URL,并放入上下文中
URI mergedUrl = UriComponentsBuilder
.fromUri(uri)
.scheme(routeUri.getScheme())
.host(routeUri.getHost())
.port(routeUri.getPort())
.build(encoded)
.toUri();
exchange.getAttributes().put(GATEWAY_REQUEST_URL_ATTR, mergedUrl);
return chain.filter(exchange);
}我们在上述方法的关键代码语句中添加了注释。可以看到,一个典型的过滤器的实现过程基本就是从 ServerWebExchange 上下文中获取路由,然后根据路由中的详细信息来执行对应的操作。
解题要点
对于服务网关而言,面试过程中关于网关基本概念的考查相对比较简单,我们不做展开。
在准备面试的过程中,建议你熟练掌握至少一种服务网关的具体实现工具,例如本讲中介绍的 Spring Cloud Gateway 就是 Spring 家族自研的网关,内置了 Spring 框架自带的功能特性,非常适合进行系统的学习。和其他服务网关的实现机制类似,Spring Cloud Gateway 也是管道过滤器架构模式的一种典型应用,因此它的整体处理流程势必涉及到过滤器、过滤器链等组件。另一方面,因为 Spring Cloud Gateway 是 Spring 家族中的一员,其处理流程也依赖于 Spring 框架对 Web 请求和响应过程的抽象,这就需要引出 DispatcherHandler、RoutePredicateHandlerMapping 和 FilteringWebHandler 等一系列核心组件。
从回答思路上讲,我们也可以基于这些组件从两个维度来阐述请求处理流程,一个是 Spring MVC 以及 WebFlux 中对 Web 请求的通用处理流程,另一个就是 Spring Cloud Gateway 内置的路由和过滤器维度。
在本讲中,限于篇幅,我们没有对 Spring Cloud Gateway 所提供的限流等功能进行展开。但从面试点角度讲,对于这些具体功能特性的考查会比较综合,难度也比较大。
一方面需要面试者对 Spring Cloud Gateway 作为服务网关的一些基本功能进行阐述,另一方面也需要面试者理解分布式环境下限流的概念和常见实现机制,以及 Spring Cloud Gateway 中的具体做法。以限流为例,因为考查的知识点比较多,所以我们重点把握几点。
- 我们明确 Spring Cloud Gateway 中实现限流的工具是过滤器,而且是一种 GatewayFilter。
- 我们明确这个过滤器实现限流时采用的是令牌桶算法。
- Spring Cloud Gateway 实现令牌桶算法借助的工具是 Redis。
- Redis 是通过一系列 Rua 脚本来完成令牌的申请和释放。
- 我们需要明确通过 Spring Cloud Gateway 实现限流的做法是使用配置项,可以把重点的配置项做展开。
这样,面试过程中涉及到的知识点就都已经介绍到了。关于这些特定的功能特性,你需要在本讲内容的基础上自己做进一步的学习和提升。
作为扩展类话题,我们也可以对响应式编程做一些展开。响应式编程虽然已经出来有几年了,但在业务系统开发过程中应用并不广泛,目前主要还是为了满足高性能等技术需求,像 Spring Cloud Gateway 这种网关类消息中间件就是其最好的应用场景之一。虽然是一种新技术,但响应式编程也不是一种完全颠覆式的技术体系,而是在现有的异步调用、观察者模式、发布-订阅模式等的基础上发展起来的一种编程模式,能够为系统带来即时响应性。
虽然,在本讲内容中,我们没有对响应式编程进行过多的展开,但对于技术原理型面试而言,对核心的新技术进行阐述无疑也是面试过程中的一个亮点。
小结与预告
本章内容围绕服务网关展开讨论。在分布式架构中,服务网关的出现有其必然性。而以 Spring Cloud Gateway 为代表的实现技术在提供高性能的同时也丰富了作为服务网关的核心功能。我们重点对 Spring Cloud Gateway 中的基本架构、服务路由以及过滤器机制进行了详细的探讨。
介绍完服务网关,我们下一个要引入的技术组件是配置中心。作为一个独立的服务端组件,配置中心需要完成与各个服务之间的交互,并统一管理这些服务中所有的配置信息。那么,配置中心和各个服务之间的这种交互过程是如何实现的呢?下一讲我们将围绕这个话题展开讨论。
配置中心:配置中心和各个服务之间是如何交互的?
在上一讲中,我们详细讨论了服务网关这一分布式系统构建过程中必不可少的技术组件。我们知道随着服务数量的增多,在客户端和服务端之间应该架设一层网关来确保对请求进行路由和转发。事实上,针对配置信息的有效管理也是系统开发过程中的基本要求,这点对于分布式系统而言尤为明显。
为了更好地管理系统中的各种配置信息,我们需要引入一个新的技术组件,即配置中心。和服务网关一样,配置中心同样也是一个独立的服务器组件。
那么,问题就来了,原本分散在各个服务中的配置信息如何集中到配置中心进行统一管理呢?配置中心和各个服务之间又是如何交互的呢?在本讲内容中,我们将围绕这些问题展开讨论,并提供对应的面试题和开源框架原理分析。
问题背景
试想一下,在一个分布式系统中,势必存在多个服务,而这些服务一般都会构建开发、测试和生产等多套环境,每套环境都是一个集群。而针对不同的环境,我们都会采用一套不同的配置体系。那么如何保证多个环境中的这些配置信息都能在各个服务实例中进行实时的同步更新呢?
显然,把配置信息分散在各个服务中交由它们自己管理是不合适的,我们需要引入一个集中式管理的工具。这个工具就是分布式系统中所必备的一个技术组件,即配置中心。有了配置中心之后,所有分散在各个服务、各个环境中的配置信息都将被收拢到配置中心进行统一管理,如下图所示:
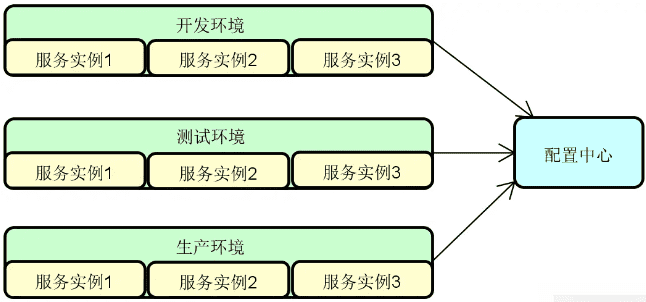
针对上图,实际上我们已经可以梳理一组在日常面试过程中经常出现的话题,包括:
- 配置中心如何区分来自不同环境的配置信息,并自动进行隔离?
- 配置中心采用什么样的存储方式来保存配置信息?
- 配置中心的基本组成结构是怎么样的?
- 各个服务如何从配置中心中获取最新的配置信息?
- 如果让你来设计一款配置中心,你会怎么做?
- 你知道 Spring Cloud Config 中客户端和服务端之前的交互流程是怎么样的吗?
上述问题体现的都是与配置中心相关的、比较常见的一些考查方式。就考查内容上而言,也主要包括两个维度,一个是理论知识,一个是具体工具框架的应用实践。
问题分析
关于系统中配置信息的管理,常见的做法是把它们存放在配置文件中。在单块系统中,普通的配置文件能够满足需求,围绕配置文件展开的配置管理工作通常不会有太大挑战。但在分布式系统中,配置文件的管理就会暴露出一些问题。针对这类问题,我们首先需要梳理配置中心的概念、在分布式系统中的定位,以及配置信息的分类和配置管理的需求等。
基于配置中心的实现需求,业界存在一批典型的分布式配置中心实现工具,常见的包括 Etcd、Consul、Disconf、Diamond、Nacos 以及 Spring Cloud Config。显然,不同的工具具有不同的设计原理和实现机制。在面试过程中,候选人可以挑选自己最擅长的一个工具展开具体的讨论。
最后,也是最重要的,就是配置中心与服务之间的交互关系。以我的经验,但凡涉及到配置中心的考查,这个问题是大概率要碰到的。任何一款配置中心实现框架都提供了一整套完善的集成机制,确保分布式系统中的各个服务能够快速高效地访问配置中心中的配置信息。而且,这个过程对于开发者而言通常是透明的,这就导致我们对这部分工作机制缺乏必要的认知,面试结果上也往往回答得不理想。
讲到这里,你可能会问,配置中心到底长得怎么样呢?在接下来的内容中,我们先来梳理配置中心的基本模型。
技术体系
每一个分布式系统都应该有一个配置中心,下图展示了配置中心的定位以及它所应具备的基本结构:
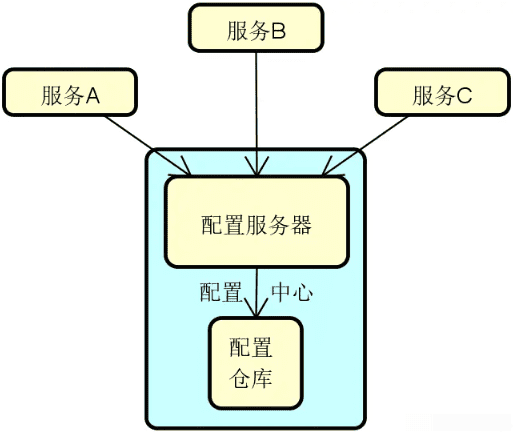
在上图中,我们看到配置中心由两个核心组件构成,分别是配置仓库和配置服务器。
-
配置仓库
配置中心中的所有配置信息都存放在一个配置仓库(Repository)中。配置仓库的实现方式有很多,我们可以采用 SVN 和 Gitlab 等具备版本控制功能的第三方工具,也可以自建一个具有持久化或内存存储功能的存储媒介。通常,开发人员通过配置管理和持续交付的各项模式和实践,并借助于特定工具完成配置仓库中配置信息的更新。
-
配置服务器
配置服务器封装对配置仓库的相关操作,充当配置仓库的管理者角色。和系统中的其他服务一样,它在物理上也是一个能够独立运行的服务,提供了对外的访问入口。当需要使用配置信息的服务启动时,这些服务就会使用这些访问入口获取存储在配置仓库中的各种配置信息。
显然,配置服务器需要屏蔽不同配置仓库实现在技术上的差异;另一方面,配置服务器也需要提供一种通知机制,确保配置仓库中的配置信息变化之后能够告知各个服务。关于这个问题实现起来比较复杂,我们放在下一讲中做专题讲解。
介绍完配置中心的基本结构之后,我们接下来讨论作为一个配置中心所应具备的核心功能,包括隔离性、一致性和安全性。
针对配置信息的管理,做到隔离性是最基本的要求。所谓隔离性,指的就是特定配置项只能用于特定环境中,不同环境中的配置项不应该相互混淆,如下图所示:
一致性的讨论对象是集群环境,即在一个集群环境中的所有服务都应该使用同一份完全相同的配置信息,针对配置信息的操作结果对于这些服务而言应该是完全一致的,如下图所示:
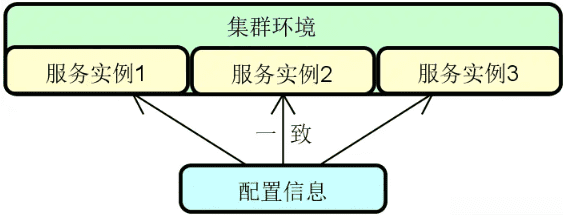
最后的安全性比较容易理解,即只有在通过合法的授权之后,开发人员才能访问配置中心中的关键配置内容,从而避免敏感信息的泄露。我们需要讨论两个维度,一个维度是从配置服务器的角度出发确保位于服务器上的配置信息不被随意访问,另一个维度则是从数据传输的角度出发确保敏感配置信息得到应有的保护。
在接下来的内容中,我们继续介绍 Spring Cloud 框架,并选择 Spring 家族自研的 Spring Cloud Config 配置中心展开讨论。Spring Cloud Config 使用起来非常简洁,也便于管理,对于所有的配置数据都开放了一套完整的 RESTful API,任何系统都可以基于 HTTP 协议来访问配置仓库中的配置数据,从而构建满足多样化需求的管理界面。
源码解析
在 Spring Cloud Config 中,整体结构分成非常清晰的两部分,即代表服务器端组件的 Spring Cloud Config Server 和代表客户端组件的 Spring Cloud Config Client,我们先从服务器端开始讲起。
Spring Cloud Config Server 工作机制
对于 Spring Cloud Config 而言,它把所有的配置信息抽象为一种 Environment(环境),而存储这些配置信息的地方就称为 EnvironmentRepository。
EnvironmentRepository 就是最常用的基于配置仓库的配置中心实现方案的具体体现。EnvironmentRepository 接口定义如下所示:
public interface EnvironmentRepository {
Environment findOne(String application, String profile, String label);
}可以看到这个接口非常简单,基于上述 findOne 方法定义以及对配置中心基本模型的了解,我们发现 Spring Cloud Config 中把配置信息抽象为如下三个维度进行管理
- 应用 (application)
- 环境 (profile)
- 版本 (label)
通过这三个维度,我们就可以确定一份唯一的配置数据。
EnvironmentRepository 的实现类非常多,那么我们选择哪一个 EnvironmentRepository 来作为切入点呢?这个问题实际上不难回答,因为 Spring Cloud Config 为我们提供了一个默认的 EnvironmentRepositoryConfiguration,即 DefaultRepositoryConfiguration,如下所示:
@Configuration
@ConditionalOnMissingBean(value = EnvironmentRepository.class, search = SearchStrategy.CURRENT)
class DefaultRepositoryConfiguration {
@Autowired
private ConfigurableEnvironment environment;
@Autowired
private ConfigServerProperties server;
@Autowired(required = false)
private TransportConfigCallback customTransportConfigCallback;
@Bean
public MultipleJGitEnvironmentRepository defaultEnvironmentRepository(MultipleJGitEnvironmentRepositoryFactory gitEnvironmentRepositoryFactory, MultipleJGitEnvironmentProperties environmentProperties) throws Exception {
return gitEnvironmentRepositoryFactory.build(environmentProperties);
}
}可以看到,这里出现了一个 MultipleJGitEnvironmentRepository,而 MultipleJGitEnvironmentRepository 则继承了抽象类 JGitEnvironmentRepository。不难看出,Spring Cloud Config 底层默认使用的 EnvironmentRepository 就是我们所熟悉的 Git。
在 JGitEnvironmentRepository 抽象类中,提供了大量针对第三方 Git 仓库的操作代码,这些都不是理解配置中心的重点内容,这里不做展开。我们只需要明白,无论采用 Git、SVN 等具体哪一种配置仓库的实现方式,最终我们处理的对象都是位于本地文件系统中的配置文件。为了理解这点,我们需要围绕 MultipleJGitEnvironmentRepository 类从底向上回顾整个类层结构,如下图所示:
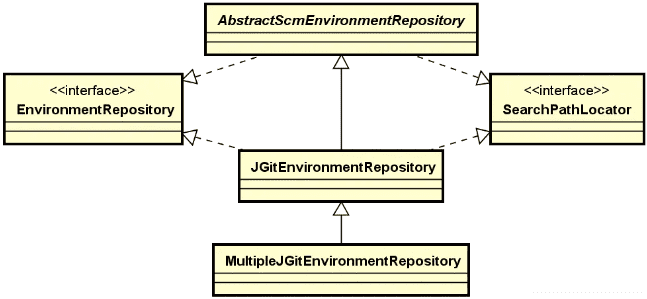
从类的命名和职责上讲,AbstractScmEnvironmentRepository 是 JGitEnvironmentRepository 的父类,其主要目的是建立能够在本地进行配置信息管理所需要的文件环境,它的 findOne 方法如下所示:
public synchronized Environment findOne(String application, String profile, String label) {
NativeEnvironmentRepository delegate = new NativeEnvironmentRepository(getEnvironment(), new NativeEnvironmentProperties());
Locations locations = getLocations(application, profile, label);
delegate.setSearchLocations(locations.getLocations());
Environment result = delegate.findOne(application, profile, "");
result.setVersion(locations.getVersion());
result.setLabel(label);
return this.cleaner.clean(result, getWorkingDirectory().toURI().toString(),getUri());
}这里出现了一个 NativeEnvironmentRepository,从命名上我们不难看出这个 EnvironmentRepository 操作的对象是本地文件。我们同样关注它的 findOne 方法,如下所示(简单起见做了裁剪):
@Override
public Environment findOne(String config, String profile, String label) {
SpringApplicationBuilder builder = new SpringApplicationBuilder(PropertyPlaceholderAutoConfiguration.class);
ConfigurableEnvironment environment = getEnvironment(profile);
builder.environment(environment);
builder.web(WebApplicationType.NONE).bannerMode(Mode.OFF);
// 获取配置信息的参数
String[] args = getArgs(config, profile, label);
// 设置监听器用于监听配置文件的变化
builder.application().setListeners(Arrays.asList(new ConfigFileApplicationListener()));
ConfigurableApplicationContext context = builder.run(args);
environment.getPropertySources().remove("profiles");
try {
return clean(new PassthruEnvironmentRepository(environment).findOne(config, profile, label));
} finally {
context.close();
}
}从代码结构上,我们看到 NativeEnvironmentRepository 最终委托 PassthruEnvironmentRepository 完成了配置文件的读取,然后通过 clean 方法完成本地文件地址与远程仓库之间地址的转换。同时,这里用到了 Spring Boot 自带的 ConfigFileApplicationListener 来监听配置文件的变化。
讲到这里,我们已经明确了 EnvironmentRepository 的设计和实现过程,接下来我们要讨论如何将配置信息的访问入口暴露给各个服务。
在 Spring Cloud Config 中,通过 EnvironmentRepository 获取的配置信息最终通过 EnvironmentController 暴露给客户端应用程序进行调用,如下所示:
@RestController
@RequestMapping(method = RequestMethod.GET, path = "${spring.cloud.config.server.prefix:}")
public class EnvironmentController {
private EnvironmentRepository repository;
private ObjectMapper objectMapper;
}可以看到它的关键成员变量有两个,即 EnvironmentRepository 和 ObjectMapper。前者是具体某一个 EnvironmentRepository 的实例,而 ObjectMapper 则用于序列化。
EnvironmentController 提供了多种获取配置信息的方法,这些方法主要就是前面介绍的 application、profile、label 这三个(或者更少)参数,其中最重要的方法就是如下所示的 defaultLabel 方法和 labelled 方法,这些方法暴露了获取配置的最常用的一组 HTTP 端点。
@RequestMapping("/{name}/{profiles:.*[^-].*}")
public Environment defaultLabel(@PathVariable String name, @PathVariable String profiles) {
return labelled(name, profiles, null);
}
@RequestMapping("/{name}/{profiles}/{label:.*}")
public Environment labelled(@PathVariable String name, @PathVariable String profiles, @PathVariable String label) {
Environment environment = this.repository.findOne(name, profiles, label);
if (!acceptEmpty && (environment == null || environment.getPropertySources().isEmpty())) {
throw new EnvironmentNotFoundException("Profile Not found");
}
return environment;
}可以看到,在 labelled 方法中,会调用 EnvironmentRepository 的 findOne 方法来加载配置,然后返回给配置的消费者,即 Spring Cloud Config 的客户端服务。
Spring Cloud Config Client 工作机制
使用过 Spring Cloud Config 的同学也都知道,想要在一个服务中集成配置中心,只需在 Spring Boot 的配置文件中添加对服务器地址的引用即可。当然,前提是在类路径中添加对 Spring Cloud Config 的引用。那么,为什么只要添加了引用,就会在服务启动时自动获取远程的配置信息呢?这就是我们接下来需要回答的问题。
在介绍 Spring Cloud Config 时,我们将采用反推的方法,即从获取服务器端配置信息的入口开始,逐步引出这个问题的答案。
我们首先找到的是 ConfigServicePropertySourceLocator 类,因为我们在这个类中发现了一个 getRemoteEnvironment 方法。显然,作为客户端组件,Spring Cloud Config Client 的主要职责就是获取服务器端提供的配置项信息。我们已经知道在 Spring Cloud Config Server 中提供了一个 EnvironmentController 来暴露配置信息,那么在客户端中势必存在一个入口来获取这些配置信息。
这个入口就是 getRemoteEnvironment 方法,如下所示(简单起见做了裁剪):
private Environment getRemoteEnvironment(RestTemplate restTemplate, ConfigClientProperties properties, String label, String state) {
// 根据服务器端点的 URL 准备参数
String path = "/{name}/{profile}";
String name = properties.getName();
String profile = properties.getProfile();
String token = properties.getToken();
int noOfUrls = properties.getUri().length;
// 处理 URL 中的 label
Object[] args = new String[] { name, profile };
if (StringUtils.hasText(label)) {
if (label.contains("/")) {
label = label.replace("/", "(_)");
}
args = new String[] { name, profile, label };
path = path + "/{label}";
}
ResponseEntity<Environment> response = null;
for (int i = 0; i < noOfUrls; i++) {
// 准备用于安全访问的 Credentials 信息
Credentials credentials = properties.getCredentials(i);
String uri = credentials.getUri();
String username = credentials.getUsername();
String password = credentials.getPassword();
try {
HttpHeaders headers = new HttpHeaders();
addAuthorizationToken(properties, headers, username, password);
if (StringUtils.hasText(token)) {
headers.add(TOKEN_HEADER, token);
}
if (StringUtils.hasText(state) && properties.isSendState()) {
headers.add(STATE_HEADER, state);
}
headers.setAccept(Collections.singletonList(MediaType.APPLICATION_JSON));
// 通过 RestTemplate 执行远程访问
final HttpEntity<Void> entity = new HttpEntity<>((Void) null, headers);
response = restTemplate.exchange(uri + path, HttpMethod.GET, entity, Environment.class, args);
}
// 省略 catch 处理和空值校验
Environment result = response.getBody();
return result;
}
return null;
}上述代码虽然有点长,但我们对照 EnvironmentController 端点的实现方法,很容易理解它的执行流程就是通过 RestTemplate 发起一个 HTTP 请求。请求对象的构建需要获取 application、profile、label 等参数,而请求结果则通过 JSON 反序列化为一个 Environment 对象。我们通过这个 Environment 对象就能获取所有相关的配置数据。
明白了获取远程配置信息的处理方式,我们来反推 getRemoteEnvironment 方法的触发过程。我们通过代码的调用路径,发现在一个 locate 方法中使用到了这个方法。而讲到这个方法就必须介绍 Spring Cloud 中的一个重要的工具类 PropertySourceLocator。
在 Spring Cloud 中,PropertySourceLocator 接口定义如下,只包含前面提到的一个 locate 方法,如下所示:
public interface PropertySourceLocator {
PropertySource<?> locate(Environment environment);
}PropertySourceLocator 接口位于 spring-cloud-context 代码工程中的 org.springframework.cloud.bootstrap.config 包下。当我们看到类的命名以及结合服务启动时自动获取配置信息这一主题应该能够联想到,PropertySourceLocator 肯定被内嵌在一个配置类中,我们在 PropertySourceLocator 接口所在的包结构中找到了 PropertySourceBootstrapConfiguration。这个类实际上非常好找,因为在同一个包结构中一共也只有三个类。
PropertySourceBootstrapConfiguration 中的实现过程如下所示(代码做了裁剪):
@Configuration
@EnableConfigurationProperties(PropertySourceBootstrapProperties.class)
public class PropertySourceBootstrapConfiguration implements ApplicationContextInitializer<ConfigurableApplicationContext>, Ordered {
private List<PropertySourceLocator> propertySourceLocators = new ArrayList<>();
public void setPropertySourceLocators(Collection<PropertySourceLocator> propertySourceLocators) {
this.propertySourceLocators = new ArrayList<>(propertySourceLocators);
}
@Override
public void initialize(ConfigurableApplicationContext applicationContext) {
// ...
ConfigurableEnvironment environment = applicationContext.getEnvironment();
for (PropertySourceLocator locator : this.propertySourceLocators) {
PropertySource<?> source = null;
// 调用各个 PropertySourceLocator 的 locate 方法
source = locator.locate(environment);
// ...
}
// ...
}
// 省略了其他变量和方法
}显然,PropertySourceBootstrapConfiguration 实现了 ApplicationContextInitializer 接口的 initialize 方法。请注意,在 Spring Boot 中,所有 ApplicationContextInitializer 接口的实现类都会在应用程序启动时自动加载。所以上述代码会随着应用启动而运行,通过遍历 propertySourceLocators 的 locate 方法来读取远程服务配置信息。
在 PropertySourceBootstrapConfiguration 类中,注意到 propertySourceLocators 数组是通过 setPropertySourceLocators 方法直接进行注入的,显然我们需要找到注入 ConfigServicePropertySourceLocator 的入口。正如前文中我们通过 PropertySourceLocator 找到 PropertySourceBootstrapConfiguration 一样,在 ConfigServicePropertySourceLocator 类的同一个包结构中,我们也找到了 ConfigServiceBootstrapConfiguration 配置类,并在该类中发现了如下所示的 configServicePropertySource 方法:
@Bean
@ConditionalOnMissingBean(ConfigServicePropertySourceLocator.class)
@ConditionalOnProperty(value = "spring.cloud.config.enabled", matchIfMissing = true)
public ConfigServicePropertySourceLocator configServicePropertySource(ConfigClientProperties properties) {
ConfigServicePropertySourceLocator locator = new ConfigServicePropertySourceLocator(properties);
return locator;
}不难看出,上述方法创建了一个新的 ConfigServicePropertySourceLocator 实例。也就是说当类路径中包含 ConfigServiceBootstrapConfiguration 类时,就会自动实例化一个 ConfigServicePropertySourceLocator。这里就充分应用了 Spring Boot 的自动配置机制,可以通过查看 META-INF/spring.factories 中的配置类进行确认,如下所示:
# Bootstrap components
org.springframework.cloud.bootstrap.BootstrapConfiguration=\
org.springframework.cloud.config.client.ConfigServiceBootstrapConfiguration,\
org.springframework.cloud.config.client.DiscoveryClientConfigServiceBootstrapConfiguration可以看到,这里的 BootstrapConfiguration 配置项中包含了 org.springframework.cloud.config.client.ConfigServiceBootstrapConfiguration 类的定义。
至此,围绕 Spring Cloud Config Client 如何在启动时自动获取 Server 所提供的配置信息的整体流程已经介绍完毕,我们可以通过下图所示的全局蓝图进行梳理和总结:
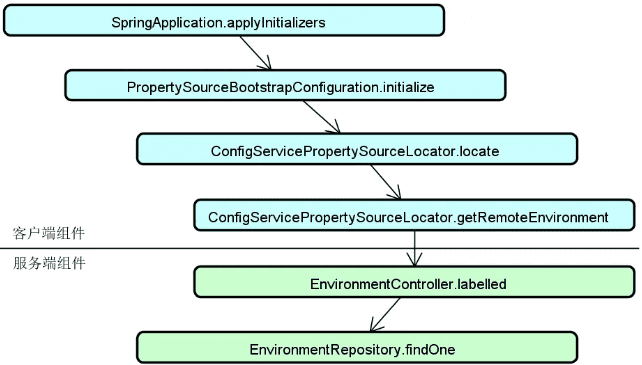
解题要点
关于配置中心相关的面试题,首要的一个解题要点就是要明确配置中心应该具备哪些核心的功能,或者说配置中心在设计上应该有哪些需求。表面上,这是一道开放式的面试题,让面试者自己来给出配置中心的需求。但事实上,这道题的考查点还是相对固化的,需要面试者把平时在使用过程中关于配置中心的几点核心述求说明清楚。面试者可以基于自己的理解做一些发挥,但发挥的点应该也是围绕这些核心述求进行展开。
对于一个配置中心而言,考虑到它的定位和作用,我们势必需要保证各种配置信息在各个环境中是相互隔离的,而这种隔离性则会导致数据的不一致,所以配置信息的一致性也是基本需求。对于面向生产环境的配置信息而言,我们还需要考虑安全性。这样,我们就梳理出了隔离性、一致性和安全性这几个核心诉求。当然,对于分布式环境下的配置信息管理,易管理性也是一项可以提到的诉求。
对配置中心常见实现工具的介绍是面试过程中的另一个要点。面试官不会要求候选人对所有的配置中心工具都了如指掌,但我们需要熟练掌握至少一款开源框架。如果你比较擅长 Spring,那么本讲所介绍的 Spring Cloud Config 就是一个不错的选择。无论你选择哪一款工具来进入深入学习,都需要围绕整个配置信息流转的工作流程来系统把握配置中心的客户端和服务端组件之间的交互过程,明确配置信息的存储媒介和方式,以及前面提到的各种需求的实现方式。
本质上,不同配置中心工具的设计思想是基本一致的。只要掌握了一款工具的底层实现原理,针对其他工具的使用方式以及实现机制的学习过程也会变得比较容易。这也可以说是技术类内容在学习上的一条客观规律。
小结与预告
配置中心是分布式架构中的一个基础组件,而业界关于如何实现配置中心也有一些基本的模型和工具。在本讲内容中,我们针对配置中心实现需求梳理了配置中心所必须要考虑的组成结构和功能特性,并重点对 Spring 家族中的 Spring Cloud Config 展开了详细分析。
在今天的内容中,我们也留下了一个伏笔:如果位于服务器端的配置信息发生了变更,如何确保这种变更能够实时的通知到客户端服务?这是一个比较复杂的话题,也是一个热门的面试题,让我们在下一讲中对它进行系统分析和讨论。
配置中心:配置信息有变更时,如何实现热更新?
在上一讲中,我们详细介绍了配置中心的设计思想和组成结构,并基于 Spring 家族的 Spring Cloud Config 框架阐述了配置中心与各个服务之间的交互过程,理解了配置中心存储配置信息的方式,以及各个服务从配置中心中读取这些配置信息的工作原理。
事实上,围绕配置中心,配置信息的传递有两个方向,一个是服务从配置中心进行拉取,另一个则是配置中心主动推送给各个服务,如下图所示:
上图中,数据推送主要发生在配置信息发生变更的场景,这也是面试过程中的一个高频问题,即位于配置中心的配置信息一旦有变更,应该如何确保各个服务实现热更新。本讲内容将围绕这一问题展开讨论。
问题背景
在日常开发过程中,配置信息的热更新是一个实战性很强的问题。对于任何一个分布式服务系统而言,避免不了需要对配置信息做一些调整,例如根据业务需要添加一些新的配置项等。如果配置信息一有更新,就需要重启服务器,这显然是不可取的。所以,如何确保在服务不重启的前提下实现配置信息的热更新是开发人员都需要掌握的基本技能,自然也是面试官重点会考查的一个话题。
针对这一话题,常见的面试问题包括:
- Spring Cloud Config 是如何实现配置信息热更新的?
- 如果让你设计一款通用的配置信息动态更新机制,你有什么思路?
- 什么是 WebHook 机制?你能描述它的常见应用场景吗?
- 基于推模式和拉模式,你应该如何分别设计配置信息的更新机制?
- 客户端想要知道服务器端的数据是否发生变化,有哪些实现方法?
- 配置中心如何从注册中心中获取最新的服务实例信息?
虽然提问方式有所不同,但上述这些面试题本质上都是围绕 数据热更新 这一技术主题所延伸出来的话题。然而,我在面试过程中发现,开发人员普遍对配置信息的热更新机制缺乏必要的了解,甚至不够重视。导致这一现象的部分原因是配置中心的构建和维护工作往往是由运维人员在负责,普通开发人员没有机会去深入理解配置中心的工作原理。另一方面,因为目前市面上主流的配置中心实现工具(例如 Spring Cloud Config、Nacos 等)都内置了完善的热更新机制,该机制对开发人员是透明的,也会导致我们对这部分功能缺乏对应的认知。
如果你是一名中级开发人员,想要往高级开发甚至架构师方向发展,那么我认为不能只停留在使用工具的层次,而是应该深入框架的原理,做到触类旁通。而这一问题考查的正是开发人员对框架底层原理的掌握程度。回答好这一问题有助于拉开你和其他候选人之间的差距。
问题分析
通过上一讲内容的介绍,我们已经知道各个服务会在启动时从配置中心获取配置,然后缓存到本地。而一旦服务启动成功,无论配置中心中的配置信息如何变更,作为配置中心客户端的各个服务都不会再次主动获取配置信息,而是会利用位于本地的缓存配置。那么问题就来了,这些服务如何能够实时获取更改后的配置呢?
在前面的讨论中,我们提到了一个词叫触类旁通。实际上,作为分布式服务系统的重要组成部分,配置中心的结构和原理与注册中心比较类似。像分布式协调框架 ZooKeeper 即可以构建注册中心,也可以用来实现配置中心。因此,我们在分析配置中心的热更新机制时,可以把它和注册中心做一些类比。
在介绍注册中心的服务实例更新机制时,我们提到了有两种方案可以做到注册中心与各个服务之间的信息同步,分别是基于拉模式的定时更新策略,以及基于推模式的监听器机制。类似地,我们可以把这两种思路也应用到配置中心中,来具体分析它们的可行性。
现在,针对这一问题我们已经具备基本的思路了。当然,不同的工具有不同的实现方式。针对配置中心,我们将继续基于 Spring Cloud Config 来讨论热更新机制。Spring Cloud Config 作为 Spring 家族的一员,很多功能特性与 Spring 框架息息相关,值得我们对它的技术体系做深入理解。
技术体系
基于以上分析,针对配置中心热更新问题,从技术体系上讲,我们有如下三种处理方法。
-
重启服务。 因为各个服务在启动时会重新获取服务器端配置,所以重启服务能实现配置信息的及时更新,但正如前面所提到的,这显然不是一种合理的方法。
-
使用 Spring Boot Actuato 组件。 这是 Spring Boot 提供的一个专门用来监测和管理系统运行时状态的组件。Actuator 是一种集成化组件,可以获取应用系统的运行时数据和配置信息并进行统计分析。
当在代码类路径中引入 spring-boot-starter-actuator 依赖并启动 Spring Boot 应用程序时,我们会在启动日志里发现自动添加了 info、health、refresh 等众多 HTTP 端点。通过调用
/actuator/refresh端点就可以刷新服务的配置信息,从而实现不重启 Spring Boot 应用的配置热更新。这种方案采用的就是典型的拉模式。这是一种简单有效的处理方式,但并不是最好的处理方式。因为针对每个微服务一般都会存在多个运行时实例,这样就需要把客户端的
/actuator/refresh端点逐个进行调用,这点显然也不是很合理。而且,这种方案属于客户端自身行为,跟配置服务器端没有关系。 -
集成 Spring Cloud Bus 组件。 当我们在 Spring Cloud Config 服务器端代码工程的类路径中添加 Spring Cloud Bus 的引用并启动应用程序之后,Spring Boot Actuator 就为我们提供了
/actuator/bus-refresh端点,通过访问该端点就可以达到对客户端所有服务实例的配置信息进行自动更新的效果。在这种方案中,服务端会主动通知所有客户端进行配置信息的更新,这样我们就无需关注各个客户端,而只对服务端进行操作即可。显然,这里用到的是基于推模式的动态监听机制。
通过对上述实现方案的分析,我们可以明确第三种方案是我们需要回答的重点。在这种方案中,整个实现过程我们至少要搞清楚三大问题,即:
- 如何自动调用服务器端所暴露的
/actuator/bus-refresh端点? - 客户端如何得知服务器端的配置信息已经更新?
- 客户端如何实时获取服务器端所更新的配置信息?
源码解析
针对以上这三个问题,接下来我们将结合 Spring Cloud Config 源码逐一展开讨论。
如何自动调用服务器端所暴露的 /actuator/bus-refresh 端点?
在现代软件开发过程中,开放式平台是一种常见的软件服务形态。我们可以把 Spring Cloud Config Server 所提供的 HTTP 端点视为一种开放式的接口,以供 Git 等第三方工具进行访问和集成。这样,我们把服务器端 /actuator/bus-refresh 端点对外进行暴露,然后第三方工具通过这个暴露的端点进行集成。
例如,在 GitHub 中就设计了一种 Webhook 机制,并提供了用户界面供我们配置所需要集成的端点以及对应的操作,操作方法如下图所示(该图来自 GitHub 官方网站):
我们可以在上图的 Payload URL 中设置 /actuator/bus-refresh 端点地址。所谓的 Webhook,实际上就是一种回调。通过 Webhook,当我们提交代码时,GitHub 就会自动调用所配置的 HTTP 端点。也就是说,可以根据配置项信息的更新情况自动实现对 /actuator/bus-refresh 端点的访问。基于 GitHub 的配置仓库实现方案,我们可以得到如下图所示的系统结构:
客户端如何得知服务器端的配置信息已经更新?
接下来我们关注第二个问题,即客户端如何得知服务器端的配置信息已经更新?
我们首先需要明确,在调用了 /actuator/bus-refresh 端点之后,系统内部发生了什么事情。这里我们需要快速浏览 Spring Cloud Bus 中的代码工程,发现在 org.springframework.cloud.bus.endpoint 包下存在一个 RefreshBusEndpoint 端点类,如下所示:
@Endpoint(id = "bus-refresh")
public class RefreshBusEndpoint extends AbstractBusEndpoint {
public RefreshBusEndpoint(ApplicationEventPublisher context, String id) {
super(context, id);
}
@WriteOperation
public void busRefreshWithDestination(@Selector String destination) {
publish(new RefreshRemoteApplicationEvent(this, getInstanceId(), destination));
}
@WriteOperation
public void busRefresh() {
publish(new RefreshRemoteApplicationEvent(this, getInstanceId(), null));
}
}显然,RefreshBusEndpoint 类对应于我们前面访问的 /bus-refresh 端点。可以看到,Spring Cloud Bus 在这里做的事情仅仅只是发布了一个新的 RefreshRemoteApplicationEvent 事件。
既然发送了事件,我们就需要寻找该事件的监听者。我们在 Spring Cloud Bus 的 org.springframework.cloud.bus.event 包下找到了 RefreshRemoteApplicationEvent 事件的监听器 RefreshListener,如下所示:
public class RefreshListener implements ApplicationListener<RefreshRemoteApplicationEvent> {
private static Log log = LogFactory.getLog(RefreshListener.class);
private ContextRefresher contextRefresher;
public RefreshListener(ContextRefresher contextRefresher) {
this.contextRefresher = contextRefresher;
}
@Override
public void onApplicationEvent(RefreshRemoteApplicationEvent event) {
Set<String> keys = contextRefresher.refresh();
log.info("Received remote refresh request. Keys refreshed " + keys);
}
}从类的定义中,我们可以看到该监听器就是用来处理 RefreshRemoteApplicationEvent 事件,其在 onApplicationEvent 方法中同样也是调用了 ContextRefresher 中的 refresh 方法进行配置属性的刷新。
请注意,RefreshRemoteApplicationEvent 是一个远程事件,将通过消息中间件进行发送,并被 Spring Cloud Config 客户端所监听,处理流程如下图所示:
客户端如何实时获取服务器端所更新的配置信息?
最后需要明确的第三个问题是,客户端如何获取服务器端所更新的配置信息?这就需要梳理 Spring Cloud Config Server 与注册中心之间的关系。
我们在上一讲分析配置中心的基本模型时提到,配置中心作为整个微服务架构运行所需的基础服务,需要确保其可用性。因为配置服务本身也是一个独立的微服务,所以 Spring Cloud Config 实现高可用的方式很简单。跟其他微服务一样,也可以把自己注册到注册中心上,让其他服务提供者或消费者通过注册中心进行服务发现和获取。
显然,在这种方式下,基于注册中心的服务治理机制同时提供了服务器端的负载均衡和客户端的配置功能,从而也就间接实现了高可用性。从另一个角度,我们也可以理解为可以通过注册中心获取所有 Spring Cloud Config 服务的实例,从而在分布式环境下为获取配置信息提供了一种简便的手段。
Spring Cloud Config 提供了一个工具类 ConfigServerInstanceProvider 来完成与注册中心之间的交互,如下所示:
public class ConfigServerInstanceProvider {
private static Log logger = LogFactory.getLog(ConfigServerInstanceProvider.class);
private final DiscoveryClient client;
public ConfigServerInstanceProvider(DiscoveryClient client) {
this.client = client;
}
@Retryable(interceptor = "configServerRetryInterceptor")
public List<ServiceInstance> getConfigServerInstances(String serviceId) {
logger.debug("Locating configserver (" + serviceId + ") via discovery");
// 根据 serviceId 获取服务实例列表
List<ServiceInstance> instances = this.client.getInstances(serviceId);
if (instances.isEmpty()) {
// 如果服务实例列表为空则抛出异常
}
return instances;
}
}在这里,我们看到了熟悉的 DiscoveryClient,DiscoveryClient 通过同样熟悉的 getInstances 方法从注册中心中获取 Spring Cloud Config 服务实例,如下所示:
List<ServiceInstance> instances = this.client.getInstances(serviceId);ConfigServerInstanceProvider 的调用者是 DiscoveryClientConfigServiceBootstrapConfiguration。如果系统中生成了 ContextRefreshedEvent 事件就会触发如下所示的 refresh 方法(部分代码做了裁剪):
private void refresh() {
try {
String serviceId = this.config.getDiscovery().getServiceId();
List<String> listOfUrls = new ArrayList<>();
// 根据 serviceId 获取配置服务实例列表
List<ServiceInstance> serviceInstances = this.instanceProvider.getConfigServerInstances(serviceId);
for (int i = 0; i < serviceInstances.size(); i++) {
ServiceInstance server = serviceInstances.get(i);
String url = getHomePage(server);
// 处理安全机制
if (server.getMetadata().containsKey("password")) {
String user = server.getMetadata().get("user");
user = user == null ? "user" : user;
this.config.setUsername(user);
String password = server.getMetadata().get("password");
this.config.setPassword(password);
}
// 构建配置文件的访问地址列表
if (server.getMetadata().containsKey("configPath")) {
String path = server.getMetadata().get("configPath");
if (url.endsWith("/") && path.startsWith("/")) {
url = url.substring(0, url.length() - 1);
}
url = url + path;
}
listOfUrls.add(url);
}
// 设置配置文件地址列表
String[] uri = new String[listOfUrls.size()];
uri = listOfUrls.toArray(uri);
this.config.setUri(uri);
}
}在上述 refresh 方法中可以看到,Spring Cloud Config 首先会获取配置文件中的 spring.cloud.config.discovery.serviceId 配置项所指定的服务实例 id,然后根据 serviceId 从 ConfigServerInstanceProvider 中获取注册服务的实例对象集合 serviceInstances,最后循环遍历 serviceInstances 来更新存储在内存中的配置属性值。通过上述流程,我们确保位于客户端中的配置信息得到了实时的更新。
解题要点
关于配置中心的热更新机制是一道比较典型的技术原理类面试题。同样,这道题之所以典型也是因为很多开发人员只停留在对具体工具的使用上,而并不清楚其背后的设计思想和原理。我在面试过程中,能够碰到让我满意的回答并不多。
从解题思路上讲,如果你对配置中心本身并没有太多概念,那么这道题有一定的难度。没有一些基础知识,光靠凭空想象是很难梳理热更新背后的实现原理的。所以在日常开发过程中,对于那些构成分布式服务系统的基础技术组件,就算不需要自己动手进行开发或维护,还是需要专门做一些了解。这也是你和普通开发人员的一个重要区别。
另一方面,配置中心的热更新是一个相对复杂的过程,考查的知识点也比较多。例如,以本讲介绍的 Spring Cloud Config 为例,就涉及到 Spring 内置的事件通知和上下文刷新机制、Spring Boot Actuator、Spring Cloud Bus 等工具框架。同时,Spring Cloud Config 还会基于注册中心获取各个配置服务实例并动态更新其位于内存中的配置信息。我们在回答过程中,对这些组件都应该有所提及,从而向面试官展示自己的知识广度。
在本讲的问题分析部分,我们实际上也提到了可以类比注册中心来学习配置中心。对于配置中心而言,具体的实现工具和框架是比较丰富的,常见的就包括 Etcd、Consul、Disconf、Diamond、Nacos 以及 Spring 家族的 Spring Cloud Config。而这些工具在实现过程中可能各有差别,但在设计思想上基本都是一致的。技术体系之间的相通性也是我们回答技术原理类面试题的一个有效抓手。如果你掌握了某一种配置中心实现工具的基本原理,那么即使没有使用过其他工具,面对类似本讲中提出的问题也能够做到触类旁通。至于如何基于技术体系相通性来应对技术原理类面试,本课程后面还会有专题进行讨论。
小结与预告
作为一个典型的技术原理类问题,本讲内容基于 Spring Cloud Config 框架剖析了实现配置信息热更新的工作原理。我们抛出了三个与这个主题相关的核心问题,然后基于源码对这些问题都做了一一解答。
事实上,Spring Cloud Config 作为 Spring 自研的配置中心框架,其内部大量使用了 Spring 框架现有的功能特性,这点与我们学习其他配置中心的实现工具不同。我们需要首先对 Spring 容器相关的知识体系有足够的了解,才能更好地理解 Spring Cloud Config 的设计和实现方式。
讨论完配置中心之后,下一讲我们将面对一个新的问题,即链路跟踪。在分布式服务系统构建过程中,链路跟踪同样是一个基础技术组件。那么,如何对服务链路进行有效监控呢?我们下一讲再聊。
链路跟踪:如何对服务链路进行有效监控?
通过前面几讲内容的介绍,我们已经掌握了注册中心、服务网关、配置中心等一系列技术组件。基于这些组件,我们可以构建完整而强大的分布式系统。
在分布式系统中,一组独立的服务相互协作完成特定的业务功能。而服务之间的调用不可避免会出现各种问题,这时候就需要引入分布式链路跟踪机制来定位和解决这些问题。
那么,如何对服务链路进行有效监控呢?业界关于分布式链路跟踪也有统一的规范以及代表性的实现框架。本讲内容将围绕这些规范和框架展开详细的讨论。
问题背景
在分布式系统中,我们基于业务划分服务,并对外暴露服务访问接口。试想这样一个场景,如果我们发现某一个业务接口在访问过程中发生了错误,一般的处理过程就是快速定位到问题所发生的服务并进行解决。但在现实的中大型系统中,一个业务接口背后可能会调用一批其他业务体系中的业务接口或基础设施类的底层接口,这时候我们如何能够做到快速定位问题呢?
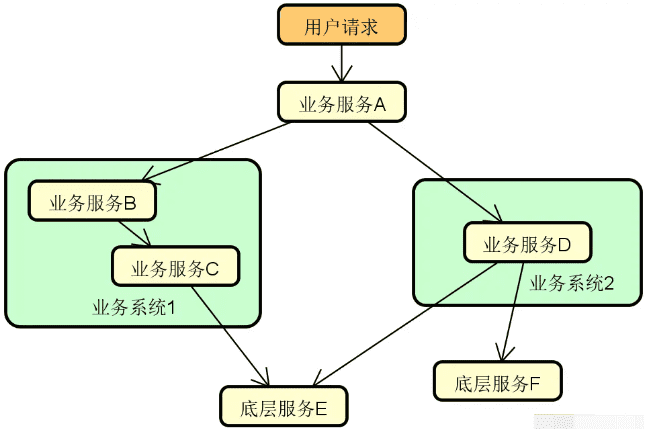
传统的做法是通过查阅服务器的日志来定位问题,但在中大型系统中,这种做法可操作性并不强,主要原因在于我们很难找到包含错误日志的那台服务器。一方面,开发人员可能都不知道整个服务调用链路中具体有几个服务,也就无法找到是哪个服务发生了错误。就算找到了目标服务,在分布式集群的环境下,我们也不建议直接通过访问某台服务器来定位问题。服务监控的需求就应运而生。
从上述描述中,我们不难看出服务监控是分布式系统的基础需求之一。可以说,链路跟踪是构建分布式系统过程中必不可少的一个技术组件。因此,在面试过程中,面试官也会经常对这一主题进行考查,常见的提问方式包括:
- 在服务监控领域,Trace 和 Span 分别代表什么含义?
- 你能描述分布式服务链路跟踪的基本原理吗?
- 针对一个完整的远程调用请求和响应过程,应该如何计算所消耗的时间?
- 如果想要获取可视化的链路跟踪数据,可以采用什么工具和框架?
- 如果你想在服务调用链路中添加自定义的性能指标,有什么实现方案?
服务监控相关的面试题提问方式实际上还是比较固定的,让我们对这类问题做进一步分析。
问题分析
对于服务监控类的面试题而言,我们的切入点主要在于两个方面,一方面是分布式服务跟踪的基本原理,另一方面则是目前主流的实现工具和框架。
关于分布式服务跟踪和监控的运行原理,实际上并不是特别复杂,我们首先需要引入两个基本概念,即 Trace 和 Span。
其中,Trace 代表一次请求和响应过程中的整个调用链路,而 Span 则代表这个链路中的一段跨度。显然,Trace 和 Span 是一对多的关系。通过将一个个具体的 Span 聚合起来,我们就可以构建出一条完整的链路并进行有效的跟踪。围绕这两个概念,我们可以进一步引出链路跟踪过程中的 4 种关键事件并开展性能分析。这是回答这类面试题的第一点思路。
回答这类面试题的第二点思路是将这些原理应用到具体的框架中。这里可以选择一些主流的开源框架展开讨论,例如本讲中要介绍的 Spring Cloud Sleuth。对于这些工具,一方面我们需要对调用链路中所生成的监控数据进行收集和分析,另一方面也需要介绍一些可视化的工具来展示这些数据分析的结果。在面试过程中,面试官一般都会考查候选人对工具框架的具体掌握程度,需要我们对它们的功能特性有全面的了解。
最后,我们再次回到实践。一旦掌握分布式服务跟踪原理和相关的工具,我们就可以按照自身的需要来定制化链路构建过程。这在我经历的面试过程中也是经常会被考查的一个问题点。面试官喜欢基于这种面试主题中对候选人的工程实践能力进行充分的考查,这就需要开发人员能够结合具体的场景给出工具应用的方式,最好能够总结一定的最佳实践。
技术体系
分布式服务跟踪基本原理
我们先来分析一下分布式服务跟踪的基本原理,这里需要引入两个 Id,即 TraceId 和 SpanId,它们分别代表一个全局唯一的 Trace 和 Span。
TraceId 即跟踪 Id。在分布式架构中,每个请求会生成一个全局的唯一性 Id,通过这个 Id 可以串联起整个调用链。也就是说,当请求在分布式系统内部流转时,系统需要始终保持传递该唯一性 Id,直到请求返回。这个唯一性 Id 就是 TraceId。
除了 TraceId 外,我们还需要 SpanId,SpanId 一般被称为跨度 Id。所谓跨度,就是调用链路中的其中一段时间,具有明确的开始和结束这两个节点,这样通过计算开始时间和结束时间之间的时间差,我们就能明确调用过程在这个 Span 上所产生的时间延迟。
通过前面的介绍,我们不难理解 TraceId 和 SpanId 之间是一对多的关系,即在一个调用链路中只会存在一个 TraceId,但会存在多个 SpanId。这样多个 SpanId 之间就会有父子关系,即链路中的前一个 SpanId 是后一个 SpanId 的父 SpanId,如下图所示:
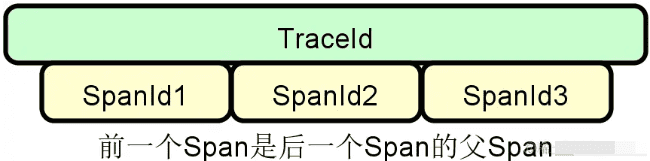
理解了 TraceId 和 SpanId 的概念之后,我们就需要对整个分布式调用链路进行进一步拆分,从而细化控制的粒度。业界一般通过四种不同的注解(Annotation)记录每个服务的客户端请求和服务器响应过程。这里的注解实际上代表的就是链路中所发生的关键事件。
- cs 注解: cs 代表 Client Send,即客户端发送请求,启动整个调用链路。
- sr 注解: sr 代表 Server Receive,即服务端接收请求。显然
(sr - cs)值代表请求从客户端到服务器端所需要的网络传输时间。 - ss 注解: ss 代表 Server Send,即服务端把请求处理结果返回给客户端,
(ss - sr)值代表服务器端处理该请求所需要的时间。 - cr 注解: cr 代表 Client Receive,即客户端接收到服务端响应,结束调用链路。
(cr - sr)值代表响应结果从服务器端传输到客户端所需要的时间。
下面结合一张示意图来进一步解释这四种注解之间的关联关系:
有了这四个注解之后,我们就可以使用它们来量化整个服务调用链路,从而找出潜在的问题。这里同样给出一个示意图:
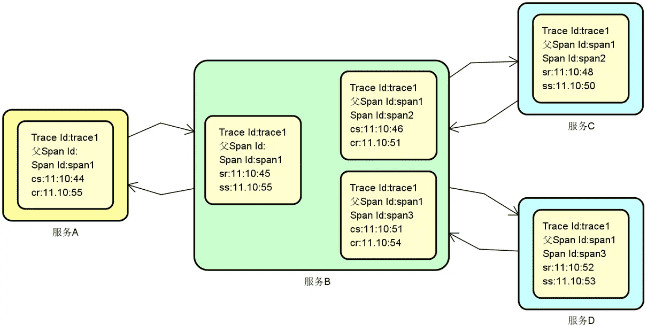
在上图中,我们看到这次请求的 TraceId 是 trace1,而 SpanId 根据不同的服务会发生变化。这里的四种注解构成了客户端和服务器对一次请求处理的闭环。对于服务 A 而言,cs 是 11:10:44,cr 是 11:10:55,也就说该次服务请求经由服务 A 的整个调用链路时间是 11s(11:10:44~11:10:55),显然这个响应时间非常长。
显然,通过这些注解我们就可以发现服务调用链路中存在的问题,目前主流的服务监控实现工具都对这些注解做了支持和封装。
Spring Cloud 中的服务监控
通过前面所介绍的服务监控基本原理,我们明确了分布式环境下服务跟踪的载体,即 TraceId 和 SpanId。而在 Spring Cloud 中也存在一个组件能够帮忙我们自动生成 TraceId 和 SpanId,这个组件就是 Spring Cloud Sleuth。
接下来,我们来看一下 Spring Cloud Sleuth 中链路跟踪的表现形式,如下所示的是一个具体的示例:
INFO [userservice,81d66b6e43e71faa,6df220755223fb6e,true] 18100 --- [nio-8082-exec-8] c.s.user.controller.UserController: Get user by UserName from userservice instance我们关注于上述日志信息中的斜体部分内容,可以看到包括了四段内容,即服务名称、TraceId、SpanId 和 Zipkin 标志位,它是格式如下所示:
[服务名称, TraceId, SpanId, Zipkin 标志位]显然,第一段中的 userservice 代表着该服务的名称,使用的就是在 Spring Boot 应用中 spring.application.name 配置项所指定的服务名称。考虑到服务跟踪的需求,为服务指定一个统一而友好的名称是一项最佳实践。
第二段中的 TraceId 代表一次完整请求的唯一编号,上例中的 81d66b6e43e71faa 就是该次请求的唯一编号。在诸如 Zipkin 等可视化工具中,可以通过 TraceId 查看完整的服务调用链路。
在一个完整的服务调用链路中,每一个服务之间的调用过程都可以通过 SpanId 进行唯一标识,例如上例中位于第三段的 6df220755223fb6e。所以 TraceId 和 SpanId 是一对多的关系,即一个 TraceId 一般都会包含多个 SpanId,每一个 SpanId 都从属于特定的 TraceId。当然,也可以通过 SpanId 查看某一个服务调用过程的详细信息。
最后的第四段代表 Zipkin 标志位,该标志位用于识别是否将服务跟踪信息同步到 Zipkin。Zipkin 是一个可视化工具,可以将服务跟踪信息通过一定的图形化形式展示出来。
源码解析
在本讲的源码解析部分,我们一方面分析 Spring Cloud Sleuth 生成和传递 Span 的实现原理。另一方面,我们也将基于更为底层的 Brave 框架给出创建自定义 Span 的实现方法。
基于 Spring Cloud Sleuth 生成和传递 Span
在一次远程调用中,对于服务提供者而言,服务的消费者相当于是它的客户端。而对于调用过程中的其他服务,这个服务消费者也可能是它们的服务提供者。因此,取决于在链路中的具体位置,不同服务可能会扮演不同的角色,如下图所示:
针对上图,我们第一步需要讨论的是在服务调用过程中如何生成 Span。在 Spring Cloud Sleuth 中,生成 Span 的过程发生在对请求进行拦截的过程中,这个拦截器就是 LazyTracingFilter。
我们来看位于该拦截器中与创建 Span 相关的实现方式,如下所示:
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
HttpServletRequest req = (HttpServletRequest) request;
HttpServletResponse res = servlet.httpServletResponse(response);
// 从请求中获取现有 Span 或创建新的 Span
Span span = handler.handleReceive(new HttpServletRequestWrapper(req));
// 为 Span 添加额外属性
request.setAttribute(SpanCustomizer.class.getName(), span);
request.setAttribute(TraceContext.class.getName(), span.context());
// 保存当前的 Span 信息,用于将这些信息通过过滤器链继续向下传递
CurrentTraceContext.Scope scope = currentTraceContext.newScope(span.context());
try {
chain.doFilter(req, res);
} catch (Throwable e) {
//...
} finally {
// ...
// scope.close();
}
}请注意,Spring Cloud Sleuth 在底层实际上是借助于 Brave 这个框架来实现 Span 的创建和传递,所以这里出现了很多与这个框架相关的代码。
考虑到在一个服务调用链路中,当前的服务消费者对于其他服务而言也可能是服务的提供者。所以,我们会首先判断 Brave 框架中当前的跟踪上下文 TraceContext 是否为空,如果不为空就说明这个服务消费者是其他服务的提供者,我们可以通过 Tracer 的 joinSpan 方法把当前已经存在的 Span 加入到该上下文中。反之则说明这个服务消费者是整个调用链路的第一个服务,我们会通过 Tracer 的 nextSpan 方法创建一个新的 Span,如下所示:
Span nextSpan(TraceContextOrSamplingFlags extracted, HttpServerRequest request) {
Boolean sampled = extracted.sampled();
if (sampled == null && (sampled = sampler.trySample(request)) != null) {
extracted = extracted.sampled(sampled.booleanValue());
}
// 判断是否新建一个 Span
return extracted.context() != null
? tracer.joinSpan(extracted.context())
: tracer.nextSpan(extracted);
}这里的 Tracer 是 Brave 框架所提供的一个工具类,具备一组用于完成与 Span 相关的各种属性和操作的方法,我们在本讲后续内容中还会对该类做进一步展开讨论。
当我们已经获取一个有效的 Span 对象之后,就可以对它做一些必要的赋值操作,然后保存这个 Span。这样,这个 Span 中的信息就可以通过过滤器链继续在调用链路中向下传递。这个过程也是通过一个拦截器来完成的,这个拦截器就是 TracingClientHttpRequestInterceptor,我们来看它的拦截实现方式,如下所示:
@Override
public ClientHttpResponse intercept(HttpRequest req, byte[] body, ClientHttpRequestExecution execution) throws IOException {
HttpRequestWrapper request = new HttpRequestWrapper(req);
// 将 Span 信息注入到 HTTP 请求中
Span span = handler.handleSend(request);
ClientHttpResponse response = null;
Throwable error = null;
try (CurrentTraceContext.Scope ws = currentTraceContext.newScope(span.context())) {
// 发送请求、获取响应
response = execution.execute(req, body);
return response;
} catch (Throwable e) {
// ...
} finally {
// 创建事件
handler.handleReceive(new ClientHttpResponseWrapper(request, response, error), span);
}
}你可能会问,Span 信息是如何传递给下一个服务的呢?答案就在这个 HttpClientHandler.handleSend 方法中,该方法如下所示:
public Span handleSend(HttpClientRequest request, Span span) {
// ...
// 将 Span 信息注入到 HTTP 消息头
defaultInjector.inject(span.context(), request);
// 创建事件
return handleStart(new HttpClientRequest.ToHttpAdapter(request), request.unwrap(), span);
}可以看到,这里出现了一个注入器组件 Injector,该组件会将一个 Span 中相关的 SpanId、TraceId、ParentId 等信息注入到 HTTP 请求的消息头中,从而确保这些信息能够随着 HTTP 请求的发送传递到下一个服务中。
请注意,这里出现的 handleReceive 和 handleStart 方法分别用于记录 Span 的关键事件。从命名上,我们不难理解 handleReceive 用于处理 cr 事件,而 handleStart 则用来处理 cs 事件。通过这种方式,当请求在某一个服务中被处理完成,相应的事件也会被记录下来。
使用 Brave 创建自定义 Span
在前面的内容中,我们已经提到了通过 Brave 框架来生成 Span 的实现方法。同样的,如果想要在访问链路中创建自定义的 Span,需要对 Brave 框架所提供的功能有足够的了解。
我们首先来关注 Brave 中的 Span 类,该类的方法列表如下所示:

注意到 Span 是一个抽象类,在上面的方法列表中,我们也看到该类的几乎所有方法都是抽象方法,需要子类进行实现。在 Brave 中,该抽象类的子类就是 RealSpan。RealSpan 中的 start 方法如下所示:
@Override
public Span start(long timestamp) {
synchronized (state) {
state.startTimestamp(timestamp);
}
return this;
}这里的 state 是一个可变的 MutableSpan,而上述 start 方法就是为这个 MutableSpan 设置了开始时间。可以想象,对应的 finish 方法也会为 MutableSpan 设置结束时间,如下所示:
@Override
public void finish(long timestamp) {
if (!pendingSpans.remove(context)) return;
synchronized (state) {
state.finishTimestamp(timestamp);
}
finishedSpanHandler.handle(context, state);
}对于关闭 Span 的操作而言,上述方法还添加了一个 Handler 以便执行回调逻辑,这也是非常常见的一种实现技巧。
我们接着来看另一个非常有用的 annotate 方法,如下所示:
@Override
public Span annotate(long timestamp, String value) {
if ("cs".equals(value)) {
synchronized (state) {
state.kind(Span.Kind.CLIENT);
state.startTimestamp(timestamp);
}
} else if ("sr".equals(value)) {
synchronized (state) {
state.kind(Span.Kind.SERVER);
state.startTimestamp(timestamp);
}
} else if ("cr".equals(value)) {
synchronized (state) {
state.kind(Span.Kind.CLIENT);
}
finish(timestamp);
} else if ("ss".equals(value)) {
synchronized (state) {
state.kind(Span.Kind.SERVER);
}
finish(timestamp);
} else {
synchronized (state) {
state.annotate(timestamp, value);
}
}
return this;
}基于前面讨论的四种监控事件,我们不难理解上述代码的作用就是为这些事件指定类型以及时间,从而为构建监控链路提供基础。
RealSpan 中最后一个值得介绍的方法是如下所示的 tag 方法:
@Override
public Span tag(String key, String value) {
synchronized (state) {
state.tag(key, value);
}
return this;
}该方法为 Span 打上一个标签,其中两个参数分别代表标签的 Key 和 Value,开发人员可以根据需要对任何一个 Span 添加自定义的标签体系。
了解了 Span 的定义之后,我们就来讨论如何在业务代码中创建自定义 Span 的方法,这时候就需要引入前面已经给出的 Tracer 类,我们同样挑选几个常见的方法进行展开。
首先,我们来看如何通过 Tracer 创建一个新的根 Span,可以通过如下所示的 newTrace 方法进行实现:
public Span newTrace() {
return _toSpan(newRootContext());
}这里用到了一个用于保存跟踪信息的 TraceContext 上下文对象,对于根 Span 而言,这个 TraceContext 就是全新的上下文,没有父 Span。而这里的 _toSpan 方法则最终构建了一个前面提到的 RealSpan 对象。
Span _toSpan(TraceContext decorated) {
if (isNoop(decorated)) return new NoopSpan(decorated);
PendingSpan pendingSpan = pendingSpans.getOrCreate(decorated, false);
return new RealSpan(decorated, pendingSpans, pendingSpan.state(), pendingSpan.clock(), finishedSpanHandler);
}这里多了一个新建的对象叫 PendingSpan,该对象用于收集一条 Trace 上暂时被挂起的未完成的 Span。
一旦创建了根 Span,我们就可以在这个 Span 上执行 nextSpan 方法来添加新的 Span,如下所示:
public Span nextSpan() {
TraceContext parent = currentTraceContext.get();
return parent != null ? newChild(parent) : newTrace();
}这里获取当前 TraceContext,如果该上下文不存在,就通过 newTrace 方法来创建一个新的根 Span;如果存在,则基于这个上下文并调用 newChild 方法来创建一个子 Span。newChild 方法也比较简单,如下所示:
public Span newChild(TraceContext parent) {
if (parent == null) throw new NullPointerException("parent == null");
return _toSpan(nextContext(parent));
}当然,在很多场景下,我们需要获取当前的 Span,这时候就可以使用 Tracer 类所提供的 currentSpan 方法,如下所示:
public Span currentSpan() {
TraceContext currentContext = currentTraceContext.get();
return currentContext != null ? toSpan(currentContext) : null;
}基于 Tracer 提供的这些常见方法,我们可以梳理在业务代码中添加一个自定义 Span 的模版方法,如下所示:
@Service
public class MyService {
@Autowired
private Tracer tracer;
public void perform() {
Span newSpan = tracer.nextSpan().name("spanName").start();
try {
// 执行业务逻辑
} finally{
newSpan.tag("key", "value");
newSpan.annotate("myannotation");
newSpan.finish();
}
}
}在上述代码中,我们注入了一个 Tracer 对象,然后通过 nextSpan 方法创建并启动了一个名称为“spanName”的新 Span。这是在业务代码中嵌入自定义 Span 的一种常用实现方法。当我们执行完各种业务逻辑之后,可以分别通过 tag 方法和 annotate 方法添加标签和定义事件,最后通过 finish 方法关闭 Span。这段模板代码可以直接引入到日常的开发过程中。
解题要点
构建服务监控和链路跟踪在分布式系统开发过程中是一项基础设施类工作,而我们可以借助于类似 Spring Cloud Sleuth 这样的框架来轻松完成这项工作。Spring Cloud Sleuth 内置了日志采集和分析机制,能够帮忙我们自动建立 TraceId 和 SpanId 之间的关联关系。对于这些工具和框架的介绍是应对这类面试题的第一个要点,也是最基本的要求。在日常开发过程中,很多开发平台已经帮我们内置了对这些工具的支持,但我们还是需要多接触一下这方面的技术组件。
就面试官的考查方式而言,先从框架应用开始聊起,然后再切入到框架基本原理的讨论是一种常见的提问方式。因此,我们需要对具体框架中所涉及的实现原理做进一步展开。
这里有两个要点,一方面我们需要介绍分布式服务跟踪的设计思想和基本概念,这部分包括如何基于 Trace 和 Span 构建服务链路的整个过程。另一方面,我们需要结合具体的框架来分析这些概念如何在现实中进行落地,这部分可以重点对本讲中介绍的 Brave 框架进行讨论。
最后,关于链路跟踪,我们还可以介绍与可视化相关的一些话题,例如 Zipkin 的基本架构、Spring Cloud Sleuth 如何与 Zipkin 进行集成等。作为加分项,这些内容可以展示候选人所具备的知识体系。
小结与预告
链路跟踪是一个理论和实践紧密结合的综合性话题,本讲内容对这个话题背后所涉及的核心概念和基本原理都做了详细的介绍。同时,我们基于 Spring Cloud 中的 Spring Cloud Sleuth 以及业界主流的 Brave 框架分析了对应的实现方式。
讨论完服务监控之后,下一讲我们将讨论消息通信机制。在分布式系统中,消息通信也是一个基础的技术组件,业界也存在一批不同的消息中间件,这些中间件在使用方式上不尽相同。那么,作为基础设施类组件,我们如何设计跨消息中间件的统一消息通信平台?这是下一讲要展开的内容。
消息通信:如何设计跨消息中间件的统一消息通信平台?
在上一讲中,我们解决了分布式系统构建过程中的一个重要问题,即如何对整个服务链路进行有效的监控。基于 Spring Cloud Sleuth 框架,我们发现可以利用 Brave、Zipkin 等一组业务主流的第三方组件来实现这一目标。
在本讲内容中,我们也将采用类似的讲解思路,来对 Spring Cloud 中另一款强大的框架展开讨论,这款框架就是 Spring Cloud Stream。
Spring Cloud Stream 是 Spring 家族提供的消息通信框架,而消息通信也是我们在分布式系统构建过程中的一个重要技术组件。然而,和普通的消息中间件不同,Spring Cloud Stream 为开发人员提供的是一种跨消息中间件的统一消息通信平台。
那么,它是如何做到这一点的呢?这是一个很好的面试题,本讲内容将围绕这一问题展开讨论。
问题背景
我们知道,在分布式系统设计和开发过程中,服务与服务之间可以通过 RPC 实现交互。但是,RPC 虽然实现起来比较简单,但却是一种耦合度较高的实现技术。为了降低服务与服务之间的耦合度,有时候我们需要引入消息通信机制,采用异步的方式来完成不同服务之间的交互。
讲到这里,你可能会说,这不就是消息中间件能解决的问题吗?答案是肯定的,但还不够。
我们知道常见的消息通信规范以及中间件有很多种,代表性的规范有 JMS 和 AMQP,对应的实现框架包括 ActiveMQ 和 RabbitMQ 等,而 Kafka、RocketMQ 等工具并不遵循特定的规范但也提供了消息通信的实现方案。显然,这些中间件的使用方式是完全不同的。
那么,如何屏蔽这些中间件在使用上的差别,从而为开发人员提供一套统一且高效的消息发送和接收 API,这是我们今天要讨论的问题,如下图所示:
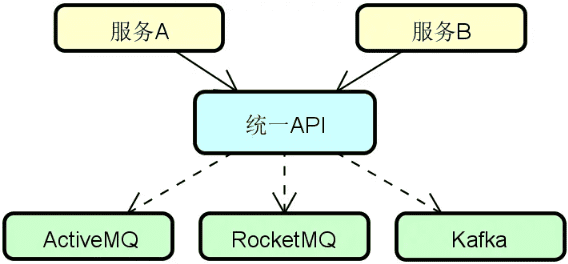
在面试过程中,我也经常拿这个问题来考查候选人,发现大家都没有很好的回答思路,可以说这是一个比较有挑战的话题。围绕这个话题,我们还可以有以下几种提问方式:
- 消息通信机制如何实现服务与服务之间的解耦?
- 如果让你设计一套统一的消息发送和消费的 API,你会怎么考虑?
- Spring Cloud Stream 的基本架构是怎么样?
- Spring Cloud Stream 与 Spring Integration 之间是什么关系?
- Spring Cloud Stream 是如何完成与 Kafka、RocketMQ 等不同中间件之间的无缝集成?
上述问题的考查点并不在于某一个消息中间件,而是站在通用性和统一性的角度来看问题,所以难度很大,需要候选人具备较强的抽象能力。而通过学习 Spring Cloud Stream 这种优秀的开源框架,可以帮助你构建这种抽象能力。
接下来,让我们再对这些问题做进一步分析。
问题分析
想要回答这类面试题,首先我们需要对消息中间件本身有足够的了解,这是设计跨消息中间件的统一消息通信平台的前提。在本讲中,这部分内容我们不会做重点展开,需要你事先做一些学习。
围绕统一消息平台的设计和实现,我们接下来要明确的是所采用的技术体系。目前,针对这个主题,我们可以参考和借鉴的框架并不多,而 Spring 家族中的 Spring Cloud Stream 是其中的代表。
Spring Cloud Stream 对整个消息发布和消费过程做了高度抽象,并提供了一系列核心组件,包括 Binder、Channel、Source 和 Sink 等。
最后,让我们基于具体框架来分析底层的实现原理。在 Spring Cloud Stream 中,真正完成与对不同消息中间件之间的集成的是 Binder 组件。而不同的消息中间件具有不同的 API,所以在 Binder 组件的设计和实现过程中,一方面需要考虑抽象,另一方面也需要针对不同中间件的特性来完成底层的交互过程。这部分内容是我们需要掌握的重点,值得深入进行学习,对于自身架构设计能力的提升有很大帮助。
技术体系
Spring 家族中的消息通信解决方案
在 Spring 家族中,与消息通信机制相关的框架有三个,分别是 Spring Messaging、Spring Integration 和 Spring Cloud Steam。
事实上,Spring Cloud 中的 Spring Cloud Stream 是基于 Spring Integration 实现了消息发布和消费机制并提供了一层封装,很多关于消息发布、消费的概念和实现方法本质上都是依赖于 Spring Integration。而在 Spring Integration 的背后,则依赖于 Spring Messaging 组件来实现消息处理机制的基础设施。
这三个框架之间的依赖关系如下图所示:
从依赖关系上讲,Spring Messaging 是 Spring 家族中处理消息通信的底层框架。而 Spring Integration 在定位上属于一种企业服务总线,依赖于 Spring Messaging。因此,我们先来介绍 Spring Messaging。
Spring Messaging 是 Spring 框架内置的一个模块,提供了最基本的消息通信 API,其中,消息这个概念由 Message 接口进行表示,包括一个消息头 Header 和一个消息体 Payload,如下所示:
public interface Message<T> {
T getPayload();
MessageHeaders getHeaders();
}而消息通道 MessageChannel 的定义也比较简单,只包含了一个用来发送消息的 send 方法,如下所示:
public interface MessageChannel {
long INDEFINITE_TIMEOUT = -1;
default boolean send(Message<?> message) {
return send(message, INDEFINITE_TIMEOUT);
}
boolean send(Message<?> message, long timeout);
}Spring Messaging 把通道抽象成两种基本的表现形式,即支持轮询的 PollableChannel 和实现发布-订阅模式的 SubscribableChannel,这两个通道都继承自具有消息发送功能的 MessageChannel,如下所示:
public interface PollableChannel extends MessageChannel {
Message<?> receive();
Message<?> receive(long timeout);
}
public interface SubscribableChannel extends MessageChannel {
boolean subscribe(MessageHandler handler);
boolean unsubscribe(MessageHandler handler);
}注意到对于 PollableChannel 而言才有 receive 的概念,代表通过轮询操作主动获取消息的过程。而 SubscribableChannel 则是通过注册回调函数 MessageHandler 来实现事件响应。MessageHandler 接口定义如下所示:
public interface MessageHandler {
void handleMessage(Message<?> message) throws MessagingException;
}在 Spring 家族中,Spring Integration 是对 Spring Messaging 的扩展,提供了对《企业集成模式:设计、构建及部署消息通信解决方案》一书中各种企业集成模式的支持,通常被认为是一种 ESB(Enterprise Service Bus,企业服务总线)框架。而 Spring Cloud Stream 则是 Spring Integration 的一种增强。
我们先来看一下 Spring Cloud Stream 中与 Spring Integration 相关的内容。
在 Spring Cloud Stream 中,存在一组 Source 和 Sink 接口,其中 Source 接口的定义如下所示。注意到这里通过 Spring Messaging 提供的 MessageChannel 来对外发送消息。
public interface Source {
String OUTPUT = "output";
@Output(Source.OUTPUT)
MessageChannel output();
}类似的,Sink 接口定义如下所示,通过 Spring Messaging 中的 SubscribableChannel 实现对来自外部消息的接收。
public interface Sink {
String INPUT = "input";
@Input(Source.INPUT)
SubscribableChannel input();
}Spring Cloud Stream 基本架构
Spring Cloud Stream 对整个消息发布和消费过程做了高度抽象,并提供了一系列核心组件。我们先来介绍基于 Spring Cloud Stream 构建消息通信机制的基本工作流程。
区别于直接使用 RabbitMQ、Kafka 等消息中间件,Spring Cloud Stream 在消息生产者和消费者之间添加了一种桥梁机制,所有的消息都将通过 Spring Cloud Stream 进行发送和接收,如下图所示:
在上图中,我们不难看出 Spring Cloud Stream 具备四个核心组件,分别是 Binder、Channel、Source 和 Sink,其中 Binder 和 Channel 成对出现,而 Source 和 Sink 分别面向消息的发布者和消费者。
-
Source 和 Sink
在 Spring Cloud Stream 中,Source 组件是真正生成消息的组件,相当于是一个输出(Output)组件。而 Sink 则是真正消费消息的组件,相当于是一个输入(Input)组件。根据我们对事件驱动架构的了解,对于同一个 Source 组件而言,不同的服务可能会实现不同的 Sink 组件,分别根据自身需求进行业务上的处理。
-
Channel
Channel 的概念比较容易理解,就是常见的通道,这里不再展开。
-
Binder
Spring Cloud Stream 中最重要的概念就是 Binder。所谓 Binder,顾名思义就是一种黏合剂,将业务服务与消息通信系统黏合在一起。通过 Binder,我们可以很方便地连接消息中间件,可以动态地改变消息的目标地址、发送方式,而不需要了解各种消息中间件在实现上的差异。
关于 Binder 是如何与不同的消息中间件进行整合的实现原理,我们在接下来的内容中进行详细展开。
源码解析
Spring Cloud Stream 中的 Binder
基于 Spring Cloud Stream,我们知道在发送和接收消息时,需要使用 @EnableBinding 注解。我们可以在 @EnableBinding 注解中指定一个 Source 或 Sink 接口。
在 Spring Cloud Stream 中,BindableProxyFactory 是一个用于初始化由 @EnableBinding 注解所提供接口的工厂类,该类的定义如下所示:
public class BindableProxyFactory implements MethodInterceptor, FactoryBean<Object>, Bindable, InitializingBean注意到 BindableProxyFactory 同时实现了 MethodInterceptor 接口和 Bindable 接口。其中,前者是 AOP 中的方法拦截器,而后者是一个标明能够绑定 Input 和 Output 的接口,如下图所示:
我们先来看 MethodInterceptor 接口中用于实现拦截的 invoke 方法,如下所示:
@Override
public synchronized Object invoke(MethodInvocation invocation) throws Throwable {
Method method = invocation.getMethod();
// 从缓存中获取目标对象
Object boundTarget = targetCache.get(method);
if (boundTarget != null) {
return boundTarget;
}
// 获取 Input 接口
Input input = AnnotationUtils.findAnnotation(method, Input.class);
if (input != null) {
String name = BindingBeanDefinitionRegistryUtils.getBindingTargetName(input, method);
boundTarget = this.inputHolders.get(name).getBoundTarget();
targetCache.put(method, boundTarget);
return boundTarget;
}
// 获取 Output 接口,和获取 Input 接口实现方式类似
else {
// ...
}
return null;
}这里的逻辑比较简单,可以看到 BindableProxyFactory 保存了一个缓存对象 targetCache,如果所调用方法已经存在于缓存中,则直接返回目标对象。反之,会根据 @Input 和 @Output 注解从 inputHolders 和 outputHolders 中获取对应的目标对象并放入缓存中。至于这里提到的这个目标对象,暂时可以把它理解为就是一种 MessageChannel 对象。
然后我们来看 Bindable 接口,该接口提供了对 Input 和 Output 的绑定和解绑操作,而这些操作是通过 Binder 接口来完成的。Binder 接口分别提供了绑定生产者和消费者的方法,如下所示:
public interface Binder<T, C extends ConsumerProperties, P extends ProducerProperties> {
// 绑定生产者
Binding<T> bindProducer(String name, T outboundBindTarget, P producerProperties);
// 绑定消费者
Binding<T> bindConsumer(String name, String group, T inboundBindTarget, C consumerProperties);
}在 Spring Cloud Stream 中,Binder 接口的类层关系如下所示,注意到这里还展示了 RabbitMessageChannelBinder 类,这个类在接下来讲到 Spring Cloud Stream 与 RabbitMQ 的集成过程时会具体展开。

针对 Binder 接口的实现过程,Spring Cloud Stream 首先提供了一个 AbstractBinder,这是一个抽象类。AbstractBinder 的子类是 AbstractMessageChannelBinder,它同样也是一个抽象类。我们来看它的 doBindProducer 方法,并对该方法中的核心语句进行提取和整理,如下所示:
@Override
public final Binding<MessageChannel> doBindProducer(final String destination, MessageChannel outputChannel, final P producerProperties) throws BinderException {
// …
// 发送到 outputChannel 通道的消息会被 SendingHandler 进行处理
((SubscribableChannel) outputChannel).subscribe( new SendingHandler(producerMessageHandler, ...);
// 基于 outputChannel 构建 Binding
Binding<MessageChannel> binding = new DefaultBinding<MessageChannel>(destination, null, outputChannel, producerMessageHandler instanceof Lifecycle ? (Lifecycle) producerMessageHandler : null) {
// …
};
return binding;
}上述代码的核心逻辑在于,通过 Source 发送的消息会被 outputChannel 这个通道传递出去,而负责处理这些消息的是 SendingHandler,它是一个 Spring Messaging 模块中的 MessageHandler。
这里要注意的是,SendingHandler 会使用 Spring Messaging 组件中的 Message 消息对象,而 Spring Cloud Stream 会把这个 Message 消息对象转换成对应中间件的消息数据格式并进行发送。
下面转到消息消费的场景。针对消息消费,我们可以使用 @StreamListener 注解。如果在一个方法上添加了 @StreamListener 注解,那么这个方法就可以用来接收消息,如下所示:
@StreamListener("input")
public void handleMessage(MyMessage myMessage)基于 @StreamListener 注解,在 Spring Cloud Stream 中存在一个 StreamListenerMessageHandler 类,用于订阅 inputChannel 消息通道中传入的消息并进行消费。
作为总结,我们可以用如下所示的流程图来概括整个消息发送和消费流程:
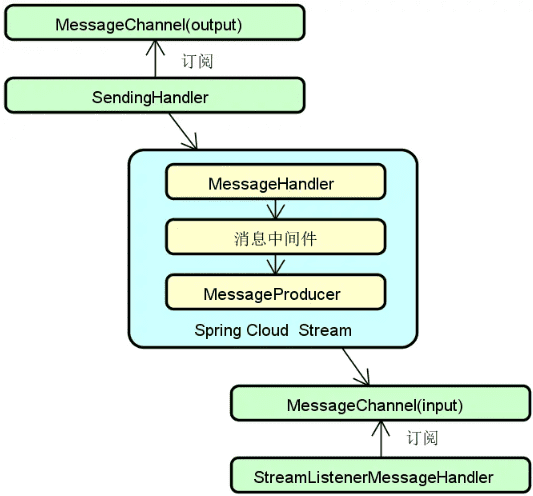
到目前为止,Spring Cloud Stream 通过 Binder 组件分别完成了对 RabbitMQ 以及 Kafka 的集成。在接下来的内容中,我们将以 RabbitMQ 为例,给出 Spring Cloud Stream 集成 RabbitMQ 的实现过程。
Spring Cloud Stream 集成 RabbitMQ
Spring Cloud Stream 团队提供了 spring-cloud-stream-binder-rabbit 作为与 RabbitMQ 集成的代码工程。这个代码工程只有四个类,我们需要重点关注的就是实现了 AbstractMessageChannelBinder 中几个抽象方法的 RabbitMessageChannelBinder 类。
首先我们找到 RabbitMessageChannelBinder 中的 createProducerMessageHandler 方法,我们知道该方法用于完成消息的发送。我们在 createProducerMessageHandler 中找到了以下核心代码:
final AmqpOutboundEndpoint endpoint = new AmqpOutboundEndpoint(buildRabbitTemplate(producerProperties.getExtension(), errorChannel != null));
endpoint.setExchangeName(producerDestination.getName());首先,在 buildRabbitTemplate 方法中,我们看到了 RabbitTemplate 的构建过程。RabbitTemplate 是 Spring Amqp 组件提供的专门用于封装与 RabbitMQ 底层交互 API 的模板类。在构建 RabbitTemplate 的整个过程中,涉及到设置与 RabbitMQ 相关的 ConnectionFactory 等众多参数。
然后,我们发现 RabbitMessageChannelBinder 也是直接集成了 Spring 中用于整合 AQMP 协议的 AmqpOutboundEndpoint,该类来自于 Spring Integration 框架,并提供了如下所示的 send 方法进行消息的发送:
private void send(String exchangeName, String routingKey, final Message<?> requestMessage, CorrelationData correlationData) {
if (this.amqpTemplate instanceof RabbitTemplate) {
// 实现消息格式的转换
MessageConverter converter = ((RabbitTemplate) this.amqpTemplate).getMessageConverter();
org.springframework.amqp.core.Message amqpMessage = MappingUtils.mapMessage(...);
// ...
// 实现消息发送
((RabbitTemplate) this.amqpTemplate).send(exchangeName, routingKey, amqpMessage, correlationData);
}
else {
// 实现消息转换和发送
this.amqpTemplate.convertAndSend(exchangeName, routingKey, requestMessage.getPayload(), message -> {
getHeaderMapper().fromHeadersToRequest(requestMessage.getHeaders(), message.getMessageProperties());
return message;
});
}
}可以看到这里依赖于 Spring Amqp 提供的 AmqpTemplate 接口实现消息发送,而 RabbitTemplate 是 AmqpTemplate 的一个实现类。同时,我们还注意到这里通过 MessageConverter 工具类完成了从 org.springframework.messaging.Message 到 org.springframework.amqp.core.Message 这两个消息数据结构之间的转换。
介绍完消息发送,接下来我们来看消息的消费。
RabbitMessageChannelBinder 中与消息消费相关的是 createConsumerEndpoint 方法。类似的,这个方法中也大量使用了 Spring Amqp 和 Spring Integration 中的工具类。该方法最终返回的是一个 AmqpInboundChannelAdapter 对象。在 Spring Integration 中,AmqpInboundChannelAdapter 是一种 InboundChannelAdapter,代表面向输入的通道适配器,提供了消息监听功能,如下所示:
protected class Listener implements ChannelAwareMessageListener, RetryListener {
@Override
public void onMessage(final Message message, final Channel channel) throws Exception {
// 省略相关实现
}
}在这个 onMessage 方法内部,最关键的是用于创建消息的 createMessage 方法,如下所示:
private org.springframework.messaging.Message<Object> createMessage(Message message, Channel channel) {
// 创建消息体
Object payload = AmqpInboundChannelAdapter.this.messageConverter.fromMessage(message);
// 创建消息头
Map<String, Object> headers = AmqpInboundChannelAdapter.this.headerMapper.toHeadersFromRequest(message.getMessageProperties());
// ...
// 创建消息
final org.springframework.messaging.Message<Object> messagingMessage = getMessageBuilderFactory()
.withPayload(payload)
.copyHeaders(headers)
.build();
return messagingMessage;
}显然,在这个 createMessage 方法中,我们完成了消息数据格式从 org.springframework.amqp.core.Message 到 org.springframework.messaging.Message 的反向转换。
解题要点
针对 Spring 框架,关于消息通信机制也是一个非常好的面试考查点,因为 Spring 框架对消息发送和接收过程进行了抽象,这种抽象很有参考价值。虽然这类面试题中规中矩,但回答起来也有一定的难度,原因在于在 Spring 框架中,关于消息通信机制的实现组件并不是只有一个,所有想要完整阐述其对消息发送和接收的抽象过程需要比较广的知识体系。
可以说针对类似这样的出题方式,要求面试者对主流开源框架有较高的理解程度。在 Spring 框架中,关于消息通信的实现组件和框架主要有三个,即位于 Spring 内核中的 Spring Messaging 组件,以及独立的 Spring Integration 和 Spring Cloud Stream 框架。
其中,Spring Messaging 是 Spring 家族中处理消息通信的底层框架。而 Spring Integration 在定位上属于一种企业服务总线,依赖于 Spring Messaging。Spring Cloud Stream 是 Spring Integration 的一种增强,同时与 Spring Boot 体系进行了融合。
从设计抽象角度讲,Spring Messaging 组件提供了用于消息通信最基本的消息(Message)、消息通道(MessageChannel)等概念的定义,Spring Integration 框架则在此基础上给出了一套完整的 ESB 解决方案。而本讲重点阐述的 Spring Cloud Stream 框架在定位上则是一种平台,完成了与各个消息中间件的无缝集成。
关于如何构建一个统一化的消息通信平台,Spring Cloud Stream 是我们值得深入分析和研究的一个框架。对于消息通信而言,我们需要分别实现消息的发布者和消费者。在 Spring Cloud Stream 中分别是 Source 和 Sink 组件。而消息的传递显然应该用到通道,所以 Spring Cloud Stream 也包含了 Channel 组件。最后,作为 Spring Cloud Stream 框架在设计上的一大特色,Binder 组件专门用于屏蔽与各种消息中间件之间的技术差异,为开发者提供统一的 API。
这样,我们就把 Spring Cloud Stream 中的四个核心组件都梳理了一遍,分别是 Binder、Channel、Source 和 Sink。在回答这类问题时,可以围绕 Spring Cloud Stream 的基本架构把这些组件都介绍到,并重点对 Binder 组件做细化阐述。
小结与预告
本讲讨论了分布式系统中与消息通信相关的话题,但我们的切入点并不是消息通信本身,而是关注如何构建一个跨消息中间件的统一消息通信平台。与前面几讲的行文思路不同,我们在引入 Spring Cloud Stream 时并不是直接介绍它的实现原理,而是从 Spring 家族中所具备的各种消息通信组件和框架开始,引出 Spring Cloud Stream 的基本架构。然后,作为一款平台型的开源框架,我们重点对 Spring Cloud Stream 如何与各个消息中间件之间实现整合的过程做了源码级的深入分析。
从下一讲开始,我们将进入到一个新的模块的讲解,这个模块包含了一组通用型的技术组件。我们要引入的第一个通用型技术组件是动态代理。那么,动态代理在分布式服务中起到什么作用?这就是下一讲要展开的内容。
动态代理:动态代理在分布式服务中起到什么作用?
在上一讲中,我们介绍了消息通信这个在分布式系统构建过程中非常常用的技术组件,这也是我们针对分布式系统讨论的最后一个专用技术组件。
从本讲开始,我们将进入到另一类技术组件的讲解,这类技术组件并不局限于只能用于分布式系统的构建过程,而是具有更大的通用性和灵活性。首先,我们要引入的是动态代理机制。
在系统设计过程中,对象之间相互依赖会造成耦合度过高,我们需要引入一个中间类来消除或缓解在直接访问目标对象时所带来的问题。但是对于发起访问的对象而言,通常希望这个中间类的存在是无感知的,这时候我们就可以引入动态代理机制。
那么,问题就来了,作为一种通用型的技术组件,动态代理在分布式系统构建过程中起到什么作用呢?本讲内容将和你一起探讨这个话题。
问题背景
在系统设计领域,代理(Proxy)是一种常见的技术组件,主要目的就是在访问目标对象之前添加一层代理对象,用于消除或缓解在直接访问目标对象时带来的问题。
而在现实应用中,代理机制也非常常见,可以说处处是代理。举一个简单的场景,假设我们需要在服务层组件中调用数据访问层组件,并记录一个操作日志。通常,服务层组件有很多方法,而对所有方法操作都需要添加日志。显然,在每个方法中手工调用同一个日志方法不是一种很好的解决方案,会造成代码冗余,增加维护成本。这个时候,代理机制就可以派上用场了。
我们可以构建一个代理对象,然后由这个代理对象统一实现日志记录操作,如下图所示:

可以看到,通过代理机制,一个对象就可以在承接另一个对象功能的基础之上,同时添加新的功能。相比直接在原有对象中嵌入代码,代理机制为我们提供了更为优雅的解决方案。
可能你看了前面这段描述之后,会觉得代理机制很简单,但事实并非如此,你可以先来看一下下面这些现实中的面试题:
- 静态代理和动态代理的本质区别是什么?
- 你了解的动态代理实现技术有哪些?
- 你知道哪些场景中用到了动态代理机制吗?
- JDK 自带的动态代理机制组成结构是怎么样的?
- Dubbo 中的远程调用本地化机制背后使用的是什么技术?
- 为什么 MyBatis 中的 Mapper 接口没有实现类但却能提供 SQL 执行功能?
- 如果让你实现类似动态代理的执行效果,你有什么思路?
事实上,代理机制背后的应用场景以及实现原理是面试过程中非常高频的一类面试题,可以考查的范围非常广,对候选人的要求也很高。
问题分析
在分布式系统构建过程中,动态代理是一种非常通用的实现机制,被广泛应用于 Dubbo 和 MyBatis 等各种开源框架中。面试过程中,面试官也通常会基于这些框架来考查候选人对这一技术组件的掌握程度。
那么,我们应该如何掌握与代理机制相关的解题思路呢?这里我总结了三点思路。
首先,就理论知识而言,我们需要明确代理机制的概念和分类。关于代理机制的概念,你可以结合设计模式中的代理模式一起进行理解。而关于代理机制的分类,一般认为具体的表现形式有两种,一种是静态代理机制,一种是动态代理机制。面试过程中,关于静态代理机制只需要简单介绍即可,重点要做展开的是动态代理机制。
然后,我们需要对动态代理机制的主流实现技术展开讨论。在 Java 的世界中,想要实现动态代理,主要有三种实现方式,即 JDK 自带的代理类以及第三方的 Cglib 和 Javassist。这些实现技术的使用方式大致相同,但背后的原理却各有特点。候选人至少需要对其中的一种实现方式有深入的理解,建议可以从 JDK 自带的代理类进行切入。
最后,明确了概念和技术之后,接下来就是具体的应用场景了。可以说,动态代理机制在各个主流的开源框架中应用非常广泛。因为它是一种通用型的技术组件,所以可以根据不同的应用场景解决不同的问题。这里也需要候选人对主流开源框架中涉及到动态代理的常见应用场景和实现方式有足够的了解。
技术体系
通过问题背景部分所介绍的应用场景,实际上我们可以梳理代理机制中存在的三种不同的角色,即抽象角色、代理角色和真实角色,如下图所示:
可以看到,代理角色和真实角色一样实现了抽象角色,但是它是真实角色的一种代理。通过代理角色,开发人员可以在真实角色的基础上添加各种定制化的处理逻辑。
上图展示代理机制中的三种角色及其对应的职责,转化为面向对象领域的表现形式,就是如下图所示的类层结构:
上图中,代理接口扮演的就是抽象角色,而代理类和委托类则分别充当了代理角色和真实角色,请注意它们都实现了代理接口。
前面已经提到,代理机制在具体实现上一般有两种方式,一种是静态代理机制,一种是动态代理机制。在 Dubbo、MyBatis 等常见开源框架中,这两种实现方式都有应用。本讲内容重点对动态代理展开讨论,主要因为动态代理理解和实现起来相对比较复杂,而且在 Dubbo、MyBatis 等框架中的应用方式和实现过程也值得我们学习和模仿。
在接下来的内容中,我们就以 JDK 自带的代理类为例给出具体的实现方式。
现在假设存在一个 Account 接口,然后需要在调用其 open 方法的前后记录日志。显然,通过静态代理完全能做到这一点,而使用 JDK 自带的动态代理也并不复杂。在 JDK 自带的动态代理中存在一个 InvocationHandler 接口,我们首先要做的就是提供该接口的一个实现类,如下所示:
public class AccountHandler implements InvocationHandler {
private Object obj;
public AccountHandler(Object obj) {
super();
this.obj = obj;
}
@Override
public Object invoke(Object proxy, Method method, Object[] arg) throws Throwable {
Object result = null;
doBefore();
result = method.invoke(obj, arg);
doAfter();
return result;
}
public void doBefore() {
System.out.println("开户前");
}
public void doAfter() {
System.out.println("开户后");
}
}可以看到 InvocationHandler 中包含一个 invoke 方法,我们必须实现这一方法。在这一方法中,我们通常需要调用 method.invoke 方法执行原有对象的代码逻辑,然后可以在该方法前后添加相应的代理实现。在上述代码中,我们只是简单打印了日志。
然后,我们编写测试类来应用上述 AccountHandler 类,如下所示:
public class AccountTest {
public static void main(String[] args) {
Account account = new RealAccount("tianyalan");
InvocationHandler handler = new AccountHandler(account);
Account proxy = (Account)Proxy.newProxyInstance(account.getClass().getClassLoader(), account.getClass().getInterfaces(), handler);
proxy.open();
}
}Proxy.newProxyInstance 方法的作用就是生成代理类,当该方法被调用时,RealAccount 类的实例被传入。然后执行到代理类的 open 方法时,AccountHandler 中的 invoke 方法就会被执行,从而触发代理逻辑。这里的类层结构如下图所示:
仔细分析上述代码结构,可以发现其遵循设计并实现业务接口 -> 实现 Handler -> 创建代理类这一实现流程,然后在 Handler 中构建具体的代理逻辑。
上述流程展示了基本的代理机制实现过程。我们可以联想一下很多基于 AOP 机制的拦截器实际上就是类似的流程。
源码解析
在本讲的源码解析部分,我们将分别基于 Dubbo 框架和 MyBatis 框架来深入分析在主流开源框架中动态代理机制的应用场景和实现原理。
Dubbo 远程访问中的代理机制
当使用 Dubbo 进行远程服务调用时,我们所做的事情就是在配置文件或代码中添加对某个服务的引用,整个过程让人感觉并没有执行任何与远程方法调用相关的网络连接、数据传输、序列化等操作,这就是所谓的远程调用本地化。远程调用本地化得以实现的背后用到的实际上就是动态代理机制。
在 Dubbo 中,我们知道执行远程调用的是 Invoker 对象。因此,当该对象被创建出来之后,我们就需要为它生成对应的代理对象,完成这一操作的是 ProxyFactory 工厂类,该工厂类的 getProxy 方法如下所示:
public interface ProxyFactory {
@Adaptive({Constants.PROXY_KEY})
<T> T getProxy(Invoker<T> invoker) throws RpcException;
@Adaptive({Constants.PROXY_KEY})
<T> Invoker<T> getInvoker(T proxy, Class<T> type, URL url) throws RpcException;
}在 Dubbo 中,ProxyFactory 的直接实现类是 AbstractProxyFactory。该类是一个抽象类,除了为每个服务自动添加回声(Echo)功能之外,还预留了一个 getProxy 抽象方法供子类进行实现。
在 Dubbo 中存在两个 ProxyFactory 的实现类,即 JavassistProxyFactory 和 JdkProxyFactory。其中的 JdkProxyFactory 的实现比较典型,接下来我们就对 JdkProxyFactory 进行展开,该类的 getProxy 方法如下所示:
public <T> T getProxy(Invoker<T> invoker, Class<?>[] interfaces) {
return (T) Proxy.newProxyInstance(Thread.currentThread().getContextClassLoader(), interfaces, new InvokerInvocationHandler(invoker));
}这里看到了熟悉的 Proxy.newProxyInstance 方法,这是典型的 JDK 动态代理的用法。根据传入的接口获得动态代理类,当调用这些接口的方法时都会转而调用 InvokerInvocationHandler。基于 JDK 动态代理的实现机制,可以想象 InvokerInvocationHandler 类必定实现了 InvocationHandler 接口,如下所示:
public class InvokerInvocationHandler implements InvocationHandler {
private final Invoker<?> invoker;
public InvokerInvocationHandler(Invoker<?> handler) {
this.invoker = handler;
}
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
String methodName = method.getName();
Class<?>[] parameterTypes = method.getParameterTypes();
if (method.getDeclaringClass() == Object.class) {
return method.invoke(invoker, args);
}
if ("toString".equals(methodName) && parameterTypes.length == 0) {
return invoker.toString();
}
if ("hashCode".equals(methodName) && parameterTypes.length == 0) {
return invoker.hashCode();
}
if ("equals".equals(methodName) && parameterTypes.length == 1) {
return invoker.equals(args[0]);
}
return invoker.invoke(new RpcInvocation(method, args)).recreate();
}
}可以看到,这里只是把方法的执行转向了 invoker.invoke 方法。关于 Invoker 的介绍不是本讲内容的重点,我们已经在前面介绍服务调用时对其进行了详细的展开,你可以做一些回顾。
MyBatis 数据访问中的代理机制
在 MyBatis 中,应用动态代理的场景实际上非常多,我们无意对所有的场景都一一展开。这里列举一个最典型的应用场景,即 Mapper 层的动态代理,用于根据 Mapper 层接口获取 SQL 执行结果。
在开始介绍 MyBatis 中的代理机制之前,我们先来回顾一下 MyBatis 的执行主流程,如下图所示。可以看到 MyBatis 是通过 MapperProxy 动态代理 Mapper。
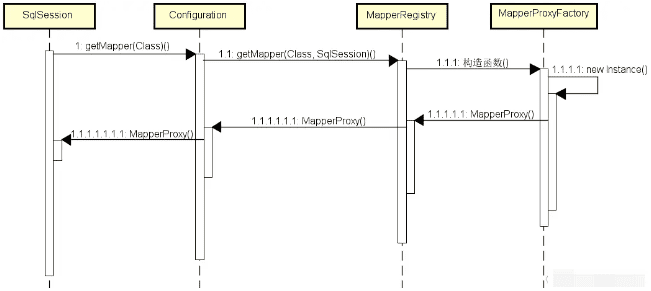
使用过 MyBatis 的同学应该都接触过这样一种操作,我们只需要定义 Mapper 层的接口而不需要对其进行具体的实现,该接口却能够正常调用并完成 SQL 执行等一系列操作,听起来很神奇,这是怎么做到的呢?让我们梳理一下整个调用流程。
在使用 MyBatis 时,业务层代码中调用各种 Mapper 的一般做法是通过 SqlSession 这个外观类,如下所示:
TestMapper testMapper = sqlSession.getMapper(TestMapper.class);作为外观类,DefaultSqlSession 把这一操作转移给了 Configuration 对象,该对象中的 getMapper 方法如下所示:
@Override
public <T> T getMapper(Class<T> type) {
return configuration.getMapper(type, this);
}让我们来到这里出现的 MapperRegistry 类,会发现真正负责创建 Mapper 实例对象的是 MapperProxyFactory 类。请注意,mapperProxyFactory.newInstance 方法的传入参数是一个 SqlSession,如下所示:
public T newInstance(SqlSession sqlSession) {
final MapperProxy<T> mapperProxy = new MapperProxy<>(sqlSession, mapperInterface, methodCache);
return newInstance(mapperProxy);
}这里引出了另一个核心类 MapperProxy,从命名上看,我们可以猜想该类就是一个代理类,因此势必使用了前面介绍的某种动态代理技术。可以先看一下 MapperProxy 类的签名,如下所示:
public class MapperProxy<T> implements InvocationHandler, Serializable显然,这里用到的是 JDK 自带的基于 InvocationHandler 的动态代理实现方案,因此,在 MapperProxy 类中同样肯定存在一个 invoke 方法,如下所示:
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
} else if (method.isDefault()) {
return invokeDefaultMethod(proxy, method, args);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
final MapperMethod mapperMethod = cachedMapperMethod(method);
return mapperMethod.execute(sqlSession, args);
}对于执行 SQL 语句的方法而言,MapperProxy 会把这部分工作交给 MapperMethod 处理。而在 MapperMethod 的 execute 方法中,我们传入了 SqlSession 以及相关的参数。在这个 execute 方法内部,根据 SQL 命令的不同类型(insert、update、delete、select)分别调用 SqlSession 的不同方法。
目前为止,我们看到了 MapperProxy 类实现 InvocationHandler 接口,但还没有看到 Proxy.newProxyInstance 方法的调用,该方法实际上也同样位于 MapperProxyFactory 类中,该类还存在一个 newInstance 重载方法,通过传入 mapperProxy 的代理对象最终完成代理方法的执行,如下所示:
protected T newInstance(MapperProxy<T> mapperProxy) {
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface }, mapperProxy);
}作为总结,我们梳理了 MyBatis 中 Mapper 层动态代理相关类的类层结构,如下图所示:
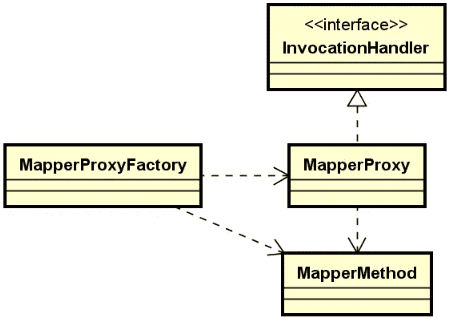
总体而言,基于代理机制,MyBatis 中 Mapper 层的接口调用过程还是比较简单明确的,这里采用的实现方案也比较经典,相关的类层结构设计也可以用作日常开发工作的参考。
解题要点
关于动态代理的实现技术是面试过程中的一个要点。动态代理是代理机制的主要实现方式,相比静态代理更为复杂也更为实用。常见的动态代理实现技术包括 JDK 自带的代理类、第三方的 Cglib 和 javassist。在回答该题时,这三个名词是一定要点到的,至于具体的细节,视面试的进展可以合理进行展开,包括给出一些自己开发过程中的实践体会,或者部分核心类的介绍。针对这道题而言,我们关注的是动态代理的技术本身,而不是应用的方式和场景。在准备这类面试题时,我们可以事先对动态代理的三种实现方式做一些示例代码,从而确保自己先有一个感性的认识。
针对具体框架的应用场景和实现机制的考查,是与动态代理机制相关的另一个面试要点,我也经常拿这些问题来面试不同层级的候选人。例如,对 Dubbo 而言,存在两种动态代理的实现机制,即 JDK 和 Javassist。尽管默认采用的是后者,但由于 Javassist 的实现过程过于复杂,一般不大适合作为一个面试题进行考查,所以更多的时候我们还是会拿 JDK 中的动态代理机制来进行讨论。
在回答这种问题上,第一步肯定是回答关于动态代理实现机制本身的内容,例如这里我们就需要对 JDK 中的 InvocationHandler 接口和 Proxy 静态类做详细的介绍。然后,针对 Dubbo 框架,我们也要明确所有的远程调用过程都是封装在一个个的 Invoker 对象中,所以动态代理的目的实际上就是把本地代码的调用过程转移到对 Invoker 对象的使用上,这是我们在回答类似问题上的基本思路。
Dubbo 中动态代理的整个执行流程还是比较清晰和明确的,在理解上建议关注于各个接口方法的输入输出参数,尤其是 Invoker 对象的使用方式。
再比如说,类似“在 MyBatis 中,为什么我们只需要定义 Mapper 层的接口而不需要对其进行具体的实现就能完成正常的 SQL 执行过程?”这样的问题也很经典,经典之处在于一般的开发人员很难通过题目中的描述明确问题的考点。
实际上,该题考查的还是代理机制。而从问题的问法上是基于 Mybatis 这个框架,但问题本身是跟 MyBatis 没有关系的,关注的是“没有具体实现的接口如何完成方法调用”这个本质问题。我们要理理思路来慢慢解开这道题的回答内容。
首先,我们明确通过 MyBatis 可以提供一系列的自定义 Mapper 接口,我们使用这些接口定义就可以执行数据库的查询、更新等操作。这是框架应用上的具体做法,相信所有用过 MyBatis 的同学都能明确这一点。然后,我们再次明确,通过接口定义就能提供方法调用的基本原理就是对这些接口进行了动态代理。只要明确了这一点,就可以把动态代理的相关内容嫁接到这个问题上,从而完成该问题的回答。
小结与预告
本章介绍动态代理的基本概念、应用场景、组成结构以及技术实现方式。这些内容在 Dubbo 和 MyBatis 框架中都得到了应用,其中 Dubbo 主要使用动态代理实现远程方法的调用,而 MyBatis 则基于它来完成数据访问。
介绍完动态代理,下一讲我们要讨论的是缓存机制。在分布式系统构建过程中,缓存也是一个通用型的技术组件,其应用方式也比较多样化。那么,如何在数据访问过程中嵌入缓存机制?我们下一讲再聊。
应用缓存:如何在数据访问过程中嵌入缓存机制?
在上一讲中,我们介绍了动态代理这一通用型的技术组件。本讲继续围绕通用型技术组件展开讨论,我们将要介绍的是缓存机制。
想要理解缓存的设计策略,我们一般都会从应用层缓存的角度切入来具体探讨如何使用缓存的方法。缓存的作用在于减少数据的访问时间和计算时间,表现为将来自持久化或其他外部系统的数据转变为一系列可以直接从内存获取的数据结构的过程。
那么,针对分布式系统,如何在数据访问过程中嵌入缓存机制?这是开发人员都需要面对的一种场景,也是面试过程中的高频话题。本讲内容将和你一起探讨应用缓存的实现机制和底层原理。
问题背景
缓存技术在分布式系统的开发过程中应用非常广泛,开发人员可以使用位于应用程序内部的本地缓存,也可以使用位于独立服务器上的分布式缓存。在日常开发中,缓存的应用通常都是分层级的,我们会综合使用多级缓存来提高目标对象访问的效率和性能。
想要理解缓存的设计策略,我们一般都会基于一定的缓存架构体系展开讨论。在日常面试过程中,关于缓存的讨论也会涉及到一系列与设计思想和应用方式相关的话题,常见的包括:
- 缓存的基本结构是怎么样的?
- 你怎么理解多级缓存的概念和作用?
- 如果让你设计一个基础的缓存,你会怎么做?
- Mybatis 中包含哪些具体的缓存结构,各自有什么特点?
- Mybatis 中的缓存数据是如何进行分级管理的?
- Mybatis 的二级缓存与一级缓存有什么关联关系?
事实上,缓存的基本原理都是类似的,都是一种空间换时间的实现方案。但是,在现实中,我们通常会引入多级缓存的技术手段来对缓存数据进行更为合理和有效的管理,这也是我们在学习主流开源框架时要特别注意的技术点。
问题分析
让我们对缓存相关的问题做一些分析和展开。缓存是一项实现技术丰富、表现形式也比较多样的技术组件。在本讲中,我们关注的是应用程序内部的本地缓存实现策略。针对这种场景,最简单的缓存实现策略就是基于 JDK 中的某种数据结构来提供 CRUD 入口。但正如前面所提到的,现实中的缓存实现策略往往没有那么简单,多级缓存的设计思想普遍存在。
因此,在应对这类面试题时,我们需要从多级缓存的设计思想出发梳理对应的组成结构和实现策略。这是应对这类面试题的第一点思路。
有了理论基础之后,我们就可以采用一定的数据结构或工具来实现多级缓存。而目前主流的开源框架中也不乏实现多级缓存的经典场景,尤其是那些与数据库访问相关的 ORM(Object Relational Mapping,对象关系映射)框架。以常见的 Mybatis 框架而言,就内置了由一级缓存和二级缓存所构成的一整套多级缓存机制。
通过对框架源码的学习,我们就能掌握应对上述面试题的回答技巧。同时,这些多级缓存机制的实现原理也为我们应对类似的应用场景提供了很好的参考。
技术体系
关于缓存的设计策略是一个比较大的话题,而缓存的分层思想是其中的一个核心设计思想。本节内容先从经典的缓存分层架构出发,分析应用层缓存的分级管理模式。
缓存的核心作用在于降低获取目标数据所需的时间,具体表现上,通常是把来自持久化或其他外部系统的数据转变为一系列可以直接从内存获取的数据结构的过程。
在学习互联网系统中的主流架构时,我们经常会看到类似如下所示的架构图:

在上图中,在 Nginx、Redis 等组件中都可以存在缓存机制,我们无意对所有缓存机制进行展开,本讲关注的是上图中应用程序层的缓存。这里的应用程序泛指诸如 Tomcat、Undertow 等应用程序容器,也包括像 Spring、Dubbo、Mybatis 等的开源框架,以及我们自己开发的业务系统。
如果我们分析应用层所具备的缓存实现技术,都可以抽象出通用的缓存结构,下图就是一种常见的缓存表现形式:
在上图中,数据表示为 Key-Value 对,然后我们对 Key 施加一定的算法获取其哈希值。有了这个哈希值,我们就可以找到目标 Value 所在的位置并获取值。
各类缓存实现工具,尽管其支持的数据结构以及数据在内存中的分配和查找方式有所不同,但基本结构模型都与上图类似。从该图中,我们也认识到缓存本质上是一种空间换时间的做法。
现在,我们已经明确了单级缓存的基本结构,让我们对上图进行扩展和延伸,把讨论范围扩大到多级缓存。如果对应用程序层的缓存进行进一步分析,我们发现同样存在分级模式,这种分级模式通常包括两级,即一级缓存和二级缓存,如下图所示:
简单来说,常见的一级缓存就是指一次请求(Request)级别或者说会话(Session)级别的缓存。针对第一次查询操作,我们会把从数据库中获取的数据放在会话中。针对后续的查询操作,我们就可以直接从会话中拿到目标数据并直接返回。
而二级缓存的范围则更大一点,它是一种全局作用域的缓存。只要应用程序处于运行状态,那么所有请求和会话都可以使用。
多级缓存代表着一种架构设计的方法论,在多款开源框架中都有对应的实现方案。接下来,我们将基于 Mybatis 框架来分析它的一级缓存和二级缓存。
源码解析
Mybatis 一级缓存
Mybatis 的一级缓存是二级缓存的基础,我们需要深入理解一组 Cache 对象,以及这些 Cache 对象与 SQL 执行器(Executor)之间的交互关系。
在 Mybatis 中,存在如下所示的一个 Cache 接口,代表了对缓存操作最高层次抽象。
public interface Cache {
String getId();
void putObject(Object key, Object value);
Object getObject(Object key);
Object removeObject(Object key);
void clear();
int getSize();
default ReadWriteLock getReadWriteLock() {
return null;
}
}Cache 接口中的方法都是自解释的,而围绕该接口的类层结构如下图所示。在该图中,Cache 接口代表一种抽象,而位于图中央的 PerpetualCache 代表该接口的具体实现类。
上图中的多数缓存实现类也都是自解释的,通过名称基本可以判断出它们的功能。而当我们想使用各种缓存类时,可以通过如下所示的装饰方法完成缓存对象的创建:
Cache cache = new XXXCache(new PerpetualCache("cacheid"))如果把这里的 XXXCache 替换成 FifoCache 就代表着这个新创建的 Cache 对象具备了 FIFO 功能。其他缓存类的使用方法也是一样。
事实上,除了 PerpetualCache 类之外,Mybatis 其他的缓存实现类都是 Cache 的装饰器。而 PerpetualCache 是 Mybatis 中默认使用的缓存类型,如下所示:
public class PerpetualCache implements Cache {
private final String id;
private Map<Object, Object> cache = new HashMap<>();
public PerpetualCache(String id) {
this.id = id;
}
// 省略 getter/setter
// ...
}可以看到,整个 PerpetualCache 类的代码结构非常简单,除了一个 id 属性之外,代表缓存的 cache 属性只是一个 HashMap,是一种典型的基于内存的缓存实现方案。这里的几个方法也比较简单,所有对缓存的操作实际上就是对 HashMap 的操作。
我们知道在 Mybatis 中存在一个配置项,用于指定一级缓存默认开启的级别,如下所示:
<setting name="localCacheScope" value="SESSION"/>在 Mybatis 中一级缓存又可以分为两个级别,即 SESSION 级和 STATEMENT 级,它们之间的区别在于缓存范围的大小。对于 STATEMENT 级别而言,缓存的作用范围就是当前 SQL;而如果是 SESSION 级,则查询结果一直会位于该会话中。但是,要注意由于一级缓存是独立存在于每个 Session 内部的,因此,如果我们创建了不同的 Session,那么它们之间会使用不同的缓存。
例如,完全一样的一个操作,如果在两个不同的 Session 中执行,那就意味着存在两份一样的缓存数据,但分别位于两个 Session 中,彼此之间不会共享,如下图所示:
介绍完一级缓存的基本概念和组成结构,是时候回到 SqlSession 了,让我们回顾一下 DefaultSqlSession 中最具代表性的 selectList 方法,如下所示:
@Override
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
MappedStatement ms = configuration.getMappedStatement(statement);
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
// ...
} finally {
ErrorContext.instance().reset();
}
}SqlSession 使用了经典的外观模式,背后真正执行查询操作的是 Executor,而 Executor 又使用了模板方法模式,它的 query 方法如下所示:
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
// ...
// 强制清空一级缓存
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
// 查询数据库
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// 如果是 STATEMENT 级,清空一级缓存
clearLocalCache();
}
}
return list;
}上述方法的实现逻辑有点复杂,首先我们来看最后一个 if 判断,可以看到如果一级缓存被设置为 STATEMENT 级,那么该方法会清空当前的本地缓存。这点跟前面的讨论一致。
然后我们回到方法开头,这里会判断 queryStack 是否为 0,如果该值是 0 且当前的 SQL 语句中对 isFlushCacheRequired 参数进行了设置,那就会把 Session 中的 localCache 清空。请注意,Mybatis 一级缓存的启动过程不需要任何配置,它是强制开启的,我们无法关闭。但是通过动态 SQL 的 isFlushCacheRequired 参数可以强制清除所有一级缓存。
通过查看定义,我们发现这个 localCache 就是一个 PerpetualCache 对象。如果这里没有从 localCache 获取到目标数据,就会调用 queryFromDatabase 方法查询数据库,如下所示:
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}显然,一旦完成数据库查询,我们会将从数据库中获取的数据保存在 localCache 中。而如果你查看 BaseExecutor 的 update、commit 和 close 方法,会发现这些方法在执行完毕之后都会清空一级缓存。
Mybatis 二级缓存
通过前面的介绍,我们发现 Mybatis 的一级缓存本质上就是一个 HashMap。Mybatis 没有对 HashMap 的大小进行管理,也没有缓存更新和过期的概念。这是因为一级缓存只发生在一次请求或一次会话中,生命周期非常短,不需要添加复杂的控制逻辑。
接下来让我们继续研究 Mybatis 中的另一种缓存表现形式,即二级缓存。相较一级缓存,Mybatis 的二级缓存使用方法有所不同,代码结构和类层关系也要更加复杂一些。
与一级缓存不同,Mybatis 的二级缓存默认是不启用的,我们需要设置对应的配置项才能让它发挥作用。
<setting name="cacheEnabled" value="true"/>下图展示了 Mybatis 中二级缓存的生效范围。请注意,二级缓存是与命名空间(Namespace)强关联的,即如果在不同的命名空间下存在相同的查询 SQL,这两者之间也是不共享缓存数据的。在 Mybatis 中,Configuration 管理着所有的配置信息,所以所有的二级缓存相当于全部位于 Configuration 之内,如下图所示:

回到代码,我们在 org.apache.ibatis.cache 包下试图寻找关于二级缓存的相关实现。但是,我们什么也没有找到。我们可以想象一下二级缓存实际上是跟 SQL Mapper 紧密相关的,因为命名空间位于 Mapper 中。所以,相关代码是否是与 Mapper 实现放在一起呢?答案是肯定的,我们在 org.apache.ibatis.mapping 包下找到了这么一个类:CacheBuilder。
从命名上看,CacheBuilder 类的作用就是构建一个 Cache,这个过程通过它的 build 方法实现,该方法代码如下所示:
public Cache build() {
// 设置缓存默认实现
setDefaultImplementations();
Cache cache = newBaseCacheInstance(implementation, id);
// 设置缓存属性
setCacheProperties(cache);
if (PerpetualCache.class.equals(cache.getClass())) {
for (Class<? extends Cache> decorator : decorators) {
cache = newCacheDecoratorInstance(decorator, cache);
setCacheProperties(cache);
}
// 对缓存执行装饰
cache = setStandardDecorators(cache);
} else if (!LoggingCache.class.isAssignableFrom(cache.getClass())) {
cache = new LoggingCache(cache);
}
return cache;
}我们先来看该方法的第一句,即调用 setDefaultImplementations 方法,该方法设置默认的缓存实现,这时候创建的实际上就是一个 PerpetualCache 类。然后,遍历装饰类接口,通过 setStandardDecorators 方法对 PerpetualCache 添加对各种装饰类的包装,从而构建出 PerpetualCache → LruCache → ScheduledCache → SerializedCache → LoggingCache → SynchronizedCache 这样一个装饰链,装饰器模式在这里得到了完美的应用,
现在,各种缓存装饰类的创建方法有了,那么谁来用呢?让我们跟踪 CacheBuilder 类的使用者。在 Mybatis 中,只有一个地方调用了 CacheBuilder 类,这就是 MapperBuilderAssistant 类。
在该类中存在一个 useNewCache 方法,如下所示:
public Cache useNewCache(
Class<? extends Cache> typeClass,
Class<? extends Cache> evictionClass,
Long flushInterval,
Integer size,
boolean readWrite,
boolean blocking,
Properties props
) {
Cache cache = new CacheBuilder(currentNamespace)
.implementation(valueOrDefault(typeClass, PerpetualCache.class))
.addDecorator(valueOrDefault(evictionClass, LruCache.class))
.clearInterval(flushInterval)
.size(size)
.readWrite(readWrite)
.blocking(blocking)
.properties(props)
.build();
configuration.addCache(cache);
currentCache = cache;
return cache;
}可以看到,二级缓存被成功创建并保存在 configuration 对象中,接下来讨论如在查询过程中使用二级缓存。
首先明确一点,在 Mybatis 中,如果开启了二级缓存,那么所有的 SQL 执行过程都将由 CachingExecutor 负责。顾名思义,CachingExecutor 是带有缓存机制的 Executor,我们对 Executor 已经有了足够的了解,所以直接来看它的 query 方法,如下所示:
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
// 获取缓存对象
Cache cache = ms.getCache();
if (cache != null) {
// ...
}
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}在该方法体的第一行代码中,我们通过 MappedStatement 获取的 Cache 对象就是前面保存在 Configuration 中的 Cache 对象。
解题要点
关于 Mybatis 中缓存机制的面试题,一般都会考查所谓的一级缓存和二级缓存。从考点上,因为比较容易混淆,我们首先需要明确这两种缓存的区别,可以从缓存的作用范围进行记忆,作用范围小的是一级,反之是二级。同时,我们也要明确,这种面试题往往会考查实现原理而不仅是简单应用,因为在 Mybatis 中缓存的应用更多是被动触发的,而不是由开发人员主动进行控制的。
Mybatis 中的一级缓存实际上就是一个 HashMap,并没有太多涉及到缓存管理方面的操作。同时,我们需要解释一下一级缓存与 BaseExecutor 之间的关系,在 Executor 执行具体的查询操作时,就会使用到一级缓存。如果缓存中找不到对应数据才会执行数据库查询。作为加分项,这里可以重点解释一下 Mybatis 中 CacheKey 的实现方法,这也是 Mybatis 框架本身在设计上的一大亮点。这些内容,确实需要结合源代码才能够理解的更加清晰明白,建议大家还是要阅读 PerpetualCache、BaseExecutor 等核心类中的代码执行主流程。
相较一级缓存,二级缓存更为复杂,因为需要更多关注于缓存对象的生命周期以及具体的缓存策略。有时候,这个考点也可以和装饰器模式结合在一起进行考查。针对二级缓存,我们也是从应用方法上进行切入。二级缓存的启动需要我们通过配置项进行控制,而它的作用范围则取决于 Mybatis 的命名空间定义。
在实现原理上,针对二级缓存的回答内容需要包含两个要点。第一个要点是通过装饰器模式来构建具体种类的缓存对象,这块我们可以结合设计模式相关内容进行展开;第二个要点是它与 CachingExecutor 之间的交互关系。
小结与预告
本讲内容关注于分布式系统构建过程中不可缺少的一个技术组件,即缓存。
缓存是一个比较复杂的话题,也具有非常多的应用场景。针对应用层缓存,我们通常采用的是分级模式,从而更好地实现对缓存对象的存储和管理。同时,我们以 Mybatis 框架为例分析了它所具备的分级缓存模式。在 Mybatis 中,存在一级缓存和二级缓存。其中,一级缓存的作用范围较小,只能应用于请求级别或会话级别。而二级缓存具备更大作用范围,能够在应用程序级别确保目标对象得到缓存。我们对这两种缓存机制的底层实现原理都进行了详细的展开。
从资源管理角度讲,缓存也是一种有效管理资源的技术手段。而除了缓存,业界也存在一些专门用来管理资源的技术组件,资源池就是其中的代表。那么,什么是池化操作?如何实现一个资源池?我们下一讲将对这些问题展开详细的讨论。
资源管理:什么是池化操作?如何实现一个资源池?
在上一讲中,我们介绍了缓存这一技术组件,并重点对多级缓存的设计思想和实现策略进行了详细的展开。本质上,缓存体现的是一种对资源利用效率进行合理管理的技术手段。
资源管理对于软件系统开发而言是一个很大的话题,同时也是一个很通用的话题。在本讲内容中,我们继续围绕资源管理这一话题进行展开,并聚焦于资源池这一技术组件。
那么,什么是池化操作?如何实现一个资源池?让我们带着这些问题来学习本讲内容。
问题背景
对于任何类型的应用程序而言,开发人员所处理的对象本质上都是各种资源(Resource)。所谓资源,在软件架构设计和实现过程中有很多表现形式,例如数据库会话、网络连接、分布式服务和组件等都可以认为是系统的资源,都需要进行管理,而性能、可伸缩性、灵活性则是资源管理的基本需求。
我们知道资源本质上代表着一种系统运行的成本,我们需要尽量减少这种成本。那么,如何有效管理资源呢?就分布式系统开发而言,我们通常都可以引入资源池的概念和实现机制。
资源池是一个最常见、也是最通用的资源管理技术组件。围绕这个技术组件,面试官也会提出各种问题来考查候选人,常见的提问方式包括:
- 你能列举你所知道的资源池应用场景吗?它们各自有什么需求特点?
- 如果让你自己实现一个资源池,你会怎么做?
- 如果资源池中已经没有资源了,资源池应该怎么做?
- 数据库连接池有哪些核心参数?
- 你知道 Mybatis 是如何有效管理数据库连接的吗?
- 你能简要描述 Mybatis 中对数据库连接对象 Connection 的管理过程?
虽然具体的资源池表现形式有多种,但基本的组成结构和实现原理大同小异。接下来,我们围绕这些问题来对资源池的概念和特性做进一步分析。
问题分析
在计算机编程领域中,池(Pool)是一种对资源的抽象方法,代表一组可以使用的资源,但这些资源不能随时被创建和释放。在架构模式中,也存在一种资源池(Resource Pool)模式。客户端向资源池请求资源,在获取到资源之后就可以用它来完成特定的任务。一旦任务完成,这个资源又可以被回收到资源池继续进行使用。
一个典型的资源池的组成结构如下图所示:
基于资源池的基本结构,我们可以进一步分析它的应用场景。作为一种通用的技术组件,资源池的应用场景包括以下几类:
- 管理那些初始化代价非常大的对象;
- 面向请求资源的频率很高且使用资源总数较低的业务处理过程;
- 当系统面临性能问题时用来降低访问时间的延迟。
资源池的主要特点在于节省了创建资源实例的开销和时间,但存储空间会随着对象的增多而增大。当我们面对资源池相关的面试问题时,我们首先需要基于日常开发过程中最常见,或者是自己平时最擅长的一种具体的资源池进行展开。例如,任何一个应用程序都需要访问数据库,也就需要引入数据库连接池(Connection Pool)。连接池就是一项适合进行深入挖掘的资源池技术。我们需要明确它的基本工作流程以及核心功能特性。
一旦明白了连接池等具体资源池的工作流程和功能特性,我们就可以基于具体某一款开源框架来深入分析底层的设计方法和实现原理。这部分内容同样需要候选人平时有足够的积累,并在面试过程中能够以自己的语言进行总结和提炼。
技术体系
在接下里的内容中,我们将基于 Mybatis 框架来对连接池这一代表性的资源池展开讨论。在介绍 Mybatis 数据库连接池之前,我们有必要对连接池的实现机制有个总体的把握。因此,我们先来全面梳理连接池的工作流程和核心要素,然后在此基础上详细阐述 Mybatis 中对数据库连接对象 Connection 的获取过程。
一个连接池的基本工作流程包含三个环节,即连接池的创建、管理和关闭。但作为一项应用广泛的池化技术,连接池在每一个环节也有一些自身的特点。
在连接池中,对连接的管理策略是重点,也在很大程度上决定了不同连接池之间在实现上的差别。
常见的实现策略是这样:当客户端请求连接时,首先查看连接池中是否有空闲连接,如果存在空闲连接,则将连接分配给客户端使用;如果没有空闲连接,则查看当前所开的连接数是否已经达到最大连接数,如果没达到就重新创建一个连接给到请求的客户端;如果达到就按设定的最大等待时间进行等待,如果超出最大等待时间,则抛出异常给客户端。整个流程如下图所示:
围绕上述介绍的连接池的管理方式,我们可以抽象出一些控制参数,常见的参数包括最小空闲连接数(MinIdle)、最大空闲连接数(MaxIdle)、连接池最大活跃连接数(MaxActive)、最大超时时间(MaxTimeout)等。
对于连接池而言,性能是我们选择不同实现工具的首要考虑因素。基于已知内容,我们可以进一步分析连接池内连接的分配和释放对系统性能的影响:
- 如果将总连接数的上限设置得过大,可能因连接数过多而导致数据库僵死,系统整体性能下降;
- 如果总连接数上限过小,则无法完全发挥数据库的性能,浪费数据库资源。
另一方面:
- 如果将空闲连接的上限设置得过大,则会浪费系统资源来维护这些空闲连接;
- 如果空闲连接上限过小,当出现瞬间的峰值请求时,系统的快速响应能力就比较弱。
所以在设置数据库连接池的这些参数时,需要进行测试和权衡,不同的实现方案会有不同的考虑。
介绍完连接池的基本概念之后,接下来我们将花较大的篇幅来介绍 Mybatis 中的数据库连接池,以帮助你理解池化技术在开源框架中的实际应用。
源码解析
与上一讲介绍 Mybatis 缓存时采用的自下而上(即从底层实现类 PerpetualCache 出发向上游逐层分析直到系统的访问入口 SqlSession)的分析方法不同,我们将采用自上而下的策略来介绍数据库连接池,即从如何获取连接 Connection 对象开始逐步分析其背后的池化操作。
我们在介绍 Mybatis 缓存时,已经明确了 DefaultSqlSession 会调用 CachingExecutor,然后 CachingExecutor 是 BaseExecutor 的实现类,而 BaseExecutor 实现了 Executor 接口,该接口提供了多种用于数据 CRUD 的方法。有了这层调用链,我们可以想象,为了获取与数据库访问相关的 Connection,入口应该位于 BaseExecutor 中的几个与数据库访问直接相关的方法中。
我们直接来到 BaseExecutor 的子类 SimpleExecutor 中的 doQuery 方法。在该方法中我们看到了一个 prepareStatement 方法,进一步猜想获取 Connection 应该是在这一方法中。让我们来看一下这个方法的实现过程,如下所示:
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
Connection connection = getConnection(statementLog);
stmt = handler.prepare(connection, transaction.getTimeout());
handler.parameterize(stmt);
return stmt;
}果然,在这里我们看到了获取 Connection 对象的 getConnection 方法,该方法如下所示:
protected Connection getConnection(Log statementLog) throws SQLException {
Connection connection = transaction.getConnection();
if (statementLog.isDebugEnabled()) {
return ConnectionLogger.newInstance(connection, statementLog, queryStack);
} else {
return connection;
}
}我们发现 getConnection 实际上是 Transaction 接口的一个方法。除了 getConnection 方法之外,Transaction 作为事务类还包含 commit 和 rollback 等事务处理相关方法。在 Mybatis 中,Transaction 接口有两个实现类,即 JdbcTransaction 和 ManagedTransaction。无论哪种方案,我们在各自的 getConnection 方法中都能看到如下所示的语句:
this.connection = this.dataSource.getConnection();显然,我们是通过 DataSource 来获取 Connection 对象。以执行查询操作的 query 方法为例,获取 Connection 对象的整体工作流程如下图所示:
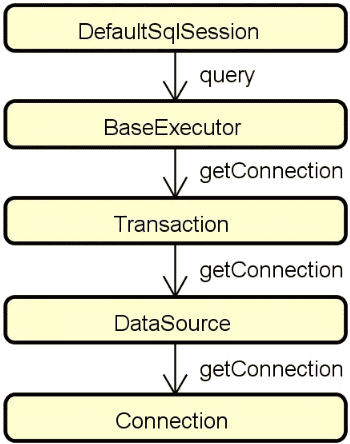
PooledDataSource
DataSource 是 JDBC 中定义的接口,Mybatis 实现了该接口,并提供了三种实现方案,相关的工厂类和实例类类层关系如下图所示:
在上图中,我们重点要介绍的是 PooledDataSource,但也会涉及一部分 UnpooledDataSource 的内容,因为 PooledDataSource 也是构建在 UnpooledDataSource 的基础之上。
在 PooledDataSource 类中,首先我们看到的是一组连接池的参数,如下所示:
protected int poolMaximumActiveConnections = 10;
protected int poolMaximumIdleConnections = 5;
protected int poolMaximumCheckoutTime = 20000;
protected int poolTimeToWait = 20000;
protected int poolMaximumLocalBadConnectionTolerance = 3;
protected String poolPingQuery = "NO PING QUERY SET";
protected boolean poolPingEnabled;
protected int poolPingConnectionsNotUsedFor;这里出现了最大空闲连接数(poolMaximumIdleConnections)、连接池最大持有连接数(poolMaximumActiveConnections)、最大存在时间(poolMaximumCheckoutTime)等核心参数,我们在前面介绍连接池的工作流程时都提到过这些参数,然后我们来看 PooledDataSource 的 getConnection 方法,如下所示:
@Override
public Connection getConnection(String username, String password) throws SQLException {
return popConnection(username, password).getProxyConnection();
}我们继续跟进,来到这里的 popConnection 方法,该方法非常长,但结构比较清晰。如果我们对连接池的管理方法有一定了解的话,理解这段代码难度并不大。为了更好地把握代码结构,我们对该方法的代码进行裁剪,只关注于主要的分支和流程,如下所示:
private PooledConnection popConnection(String username, String password) throws SQLException {
while (conn == null) {
synchronized (state) {
if (!state.idleConnections.isEmpty()) {
// 如果 idle 列表不为空,表示有可用连接,直接选取第一个元素
conn = state.idleConnections.remove(0);
} else {
// 连接池没有可用连接的场景
if (state.activeConnections.size() < poolMaximumActiveConnections) {
// 如果 active 列表没有满,直接创建新连接
conn = new PooledConnection(dataSource.getConnection(), this);
} else {
// active 已经满了
// 获得使用最久的连接,判断是否已经超时
PooledConnection oldestActiveConnection = state.activeConnections.get(0);
long longestCheckoutTime = oldestActiveConnection.getCheckoutTime();
if (longestCheckoutTime > poolMaximumCheckoutTime) {
// 已经超时,将原连接废弃并建立新连接
conn = new PooledConnection(oldestActiveConnection.getRealConnection(), this);
} else {
// 如果没有超时,则进行等待,并计算时间累加
state.wait(poolTimeToWait);
}
}
}
if (conn != null) {
// 如果获取到了连接,则验证该连接是否有效
if (conn.isValid()) {
// 如果连接有效,更新该链接相关参数和状态
} else {
// 如果连接无效,且无效连接数量超过上限则抛异常
}
}
}
}
if (conn == null) {
// 如果最终无法获取有效连接,则同样抛异常
}
return conn;
}在上述代码中,我们添加了很多注释来解释用于获取 Connection 的 popConnection 方法的整体流程,而不关心具体细节,整体流程如下图所示:
在整体流程上,当 Mybatis 执行查询时会首先从 idleConnections 列表中申请一个空闲的连接,只有当 idleConnections 列表为空时才会创建新连接。当然,PooledDataSource 并不允许无限创建新连接。当连接池中连接达到一定数量时,即使 idleConnections 列表为空,也不会再继续创建新连接,而是从 activeConnections 列表中找出使用最久的一个连接,判断其是否超时。如果超时,则将该连接废弃并创建新连接,否则线程会一直等待直到连接池中有新的可用连接。
但是,我们还是注意到这里有一个 PooledConnection 类,通过 PooledDataSource 获取的连接就是这个类。该类是 Mybatis 自己设计的一个 Connection 类,让我们来看一下。
在 PooledConnection 中我们首先应该注意到的是它的两个变量,即 realConnection 和 proxyConnection,它们的类型都是 Connection。从命名上看,其中的 realConnection 是真正通过 JDBC 驱动类建立的连接,而 proxyConnection 是一个代理连接,也是 PooledDataSource 返回的连接。
PooledConnection 本身就实现了 JDK 的 InvocationHandler 接口,并提供了如下所示的 invoke 方法实现:
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
String methodName = method.getName();
if (CLOSE.hashCode() == methodName.hashCode() && CLOSE.equals(methodName)) {
dataSource.pushConnection(this);
return null;
}
try {
if (!Object.class.equals(method.getDeclaringClass())) {
checkConnection();
}
return method.invoke(realConnection, args);
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}这里的逻辑主要是 DataSource 的 pushConnection 方法。我们采用与 popConnection 方法相同的方式来介绍 pushConnection 方法,如下所示:
protected void pushConnection(PooledConnection conn) throws SQLException {
synchronized (state) {
// 从 active 列表中移除该连接
state.activeConnections.remove(conn);
// 如果是有效连接
if (conn.isValid()) {
// 如果满足 idle 列表没有填满且类型符合期望
if (state.idleConnections.size() < poolMaximumIdleConnections && conn.getConnectionTypeCode() == expectedConnectionTypeCode) {
state.accumulatedCheckoutTime += conn.getCheckoutTime();
// 则创建一个新的连接并放入 idle 列表中
PooledConnection newConn = new PooledConnection(conn.getRealConnection(), this);
// 唤醒线程
state.notifyAll();
} else {
// 如果不满足判断条件,则说明该连接已经不需要存储,直接关闭真正连接
conn.getRealConnection().close();
}
} else {
// 如果是无效连接,则记录
}
}
}结合 popConnection 方法,pushConnection 方法的整体执行流程也在意料之中。这里唯一需要注意一点在于 state.notifyAll 语句,该语句与 popConnection 方法中用于等待线程的 state.wait 语句相对应,从而唤醒了线程。这样,当 SQL 执行完成时,PooledDataSource 也不会直接关闭线程,而是将其加入到 idleConnections 中并唤醒所有等待线程。
UnpooledDataSource
接下来我们来讨论 UnpooledDataSource。在 Mybatis 中,PooledDataSource 实际上也是依赖 UnpooledDataSource 来创建真正的连接,这点通过 PooledDataSource 类的构造函数可以得到印证,如下所示:
public PooledDataSource(String driver, String url, String username, String password) {
dataSource = new UnpooledDataSource(driver, url, username, password);
expectedConnectionTypeCode = assembleConnectionTypeCode(dataSource.getUrl(), dataSource.getUsername(), dataSource.getPassword());
}所以,PooledDataSource 中的 dataSource 变量实际上就是一个 UnpooledDataSource 对象。在 PooledDataSource 中 的 popConnection 方法中,我们看到如下所示的语句:
conn = new PooledConnection(dataSource.getConnection(), this);这里通过 UnpooledDataSource 获取了 Connection 并构建 PooledConnection 对象,所以前面提到的 PooledConnection 中的 realConnection 对象实际就是来自 UnpooledDataSource。
我们有必要进一步分析一下 UnpooledDataSource 中获取 Connection 的过程。我们跟踪 UnpooledDataSource 的 getConnection 方法,找到如下所示的 doGetConnection 方法:
private Connection doGetConnection(Properties properties) throws SQLException {
initializeDriver();
Connection connection = DriverManager.getConnection(url, properties);
configureConnection(connection);
return connection;
}可以看到,这里回归到了熟悉的 JDBC,实际上就是基于 JDBC 中的 DriverManager 工具类来获取 Connection。
解题要点
以我的经历,有时候在面试时会出现类似 如果让你实现一个简单的资源池,你会怎么做? 这种开放式问题。这类问题对于面试者而言有利有弊,有利的点在于本身就没有标准答案,自由发挥的空间比较大,很多时候可以做到自圆其说。不利的点在于需要有比较好的反应能力,能够快速地针对某个具体问题给出灵活的解决方案,而不是像存粹考查知识体系的问题那样给出固定的回答即可。
针对这道开放式问题,在回答上一般会有三个要点。我们首先需要简要阐述资源池的作用和基本结构,这块偏理论知识,点到就好。然后,我们明确对于池化操作而言,最终都需要有个存储容器来保存池化最新,所以需要在 JDK 容器中选择一种作为方案。最后,我们需要设计如何对资源池中对象进行操作的方法,这些方法需要考虑到线程的安全性。上述三个要点对于类似的问题都是可以直接套用的。
针对具体的开发框架,面试官经常可能会抛出类似 简要描述 Mybatis 中对数据库连接对象 Connection 的管理过程? 这样的问题。这种问题问的是 Connection 的管理过程,本质上还是在考查大家对连接池的理解程度,因为 Connection 的管理就是通过连接池来完成的。对于普通的应用场景而言,Connection 的管理对于开发人员是透明的,所以该题的考点有一定难度,需要面试者对 Mybatis 内部实现原理有深入的理解。
在解答思路上,我认为这道题的主要挑战是梳理 Connection 在使用上的整个流程,该流程涉及到两大方面,即获取 Connection 和释放 Connection。为此,Mybatis 中分别提供了 popConnection 和 pushConnection 方法。这两个方法是需要明确点到的,这是一个要点。另一方面,在连接池的管理上,获取和释放 Connection 的过程并不是很复杂,无非就是要做很多判断和异常处理,但如何确保并发访问下新连接的创建和访问是一个难题,需要指出 Mybatis 在多线程处理上的实现方式,这是该问题的第二个要点。
本讲详细介绍了 Mybatis 中 PooledConnection 类的设计思想和实现方法,同时也给出了 popConnection 和 pushConnection 这两个核心方法的流程细节,方便你进行学习。
小结与预告
本讲主要关注于资源池模式本身的概念、模型和实现过程,并引出了数据库连接池这一典型的资源池应用方式。和上一讲一样,我们结合 Mybatis 框架具体分析了该框架中如何实现数据库连接池的设计理念和详细过程。
从下一讲开始中,我们将转换视角,讨论与系统扩展性相关的话题。扩展性是一个很通用的话题,涉及面很广。下一讲,我们先来考虑开发框架本身的扩展性,我们将围绕框架与框架之间的集成过程来分析扩展性的表现形态和实现方式。
框架集成:如果需要实现两个框架之间的集成,有什么办法?
在上一讲中,我们分析了以数据库连接池为代表的资源池的设计思想和实现方式。而在本讲内容中,我们将讨论一个非常常见但又不被开发人员所感知的技术组件,这就是框架集成组件。这里的框架集成,指的是第三方框架与 Spring 框架之间的集成。在现实开发环境中,无论使用的是 Dubbo 还是 Mybatis 框架,你会发现它们的使用方式和 Spring 框架是完全一致的。
作为一个通用型的开发框架,Spring 为我们提供了非常强大的扩展功能。那么,这些扩展功能是如何运作的?如果需要实现两个框架之间的集成,我们又有什么办法呢?这是一个实战性非常强的话题,本讲内容将围绕这一话题展开讨论。
问题背景
在 Java 的世界中,我们知道 Spring 是当下最主流的开发框架,没有之一。而在使用 Dubbo、Mybatis 等开源框架时,我们发现可以采用和 Spring 完全一样的方式来使用它们,如下图所示:
可能你在平时的使用过程中并没有意识到这一点,但仔细想一想,你会觉得这是一件比较神奇的事情。本来就是不同的框架,怎么能够无缝地集成在一起呢?
无论从面试角度,还是日常开发角度,这都是一个值得分析和探讨的话题。因为我们自己也可能需要开发类似 Dubbo、Mybatis 这样的第三方框架,然后完成与 Spring 框架的集成。显然,这是一类偏向于实践的话题,因此,面试官也会更多地从应用的角度出发来考查候选人,常见的提问方式包括:
- 你能列举 Spring 框架所提供的常见启动扩展点,以及它们的使用方式吗?
- Spring 中 Bean 中的 Constructor、@PostConstruct 以及 InitializingBean 这三者之间的执行顺序是怎么样的?
- 如何基于 Spring Boot 的自动配置原理实现一个 starter 组件?
- 你能描述 Dubbo 框架的启动过程吗?
- Mybatis Spring Boot Starter 的运行机制是怎么样的?
要想回答上述面试题,就需要我们掌握 Spring 框架中内置了一组功能非常强大的扩展机制。通过这些扩展机制,可以实现我们想要的集成效果。接下来,让我们对这些问题做进一步分析。
问题分析
目前,很多主流的开源框架都提供了自身针对 Spring 框架的系统集成模块,包括我们前面几讲介绍的 Dubbo 和 Mybatis 框架。同样的,如果我们自己实现一款开源框架,也可以利用 Spring 所提供的扩展性来完成与它的集成过程。这里,我们可以把 Spring 框架本身做一个细分,如下图所示:
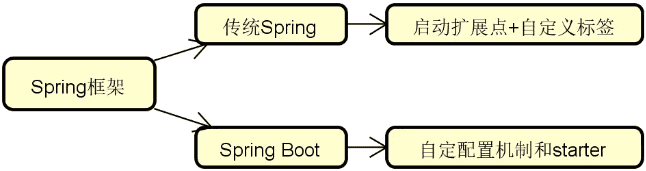
从扩展性的角度讲,传统 Spring 提供了两大类扩展功能,一类是启动过程中的各种扩展点,另一类则是 Spring 内置的自定义标签体系,我们可以通过 XML Scheme 的命名空间机制来实现与 Spring 的集成。
另一方面,Spring Boot 作为 Spring 框架的升级,也提供了功能强大的自动配置机制,我们也可以通过编写自定义的 starter 组件来完成与 Spring Boot 的集成。
技术体系
就目前的应用场景而言,Spring Boot 是 Java 世界中最主流的开发框架,开发自定义 starter 组件是主流的框架集成实现方案。因此,在接下来的内容中,我们重点对 Spring Boot 的自动配置机制做详细的展开。而针对传统 Spring 框架,只会简要介绍一些常见的启动扩展点机制。
Spring 启动扩展点
就技术体系而言,让我们先从传统 Spring 框架的一组启动扩展点开始讲起。事实上,在 Spring 中,启动扩展点的数量非常多,这里只挑选一组最常用的进行介绍,包括 InitializingBean、FactoryBean 以及 ApplicationListener。
在 Spring 中,InitializingBean 的作用是在 Bean 的初始化时,允许开发人员添加一些定制化处理逻辑,该接口定义如下所示:
public interface InitializingBean {
void afterPropertiesSet() throws Exception;
}我们看到 InitializingBean 接口只有一个方法,即 afterPropertiesSet 方法。从命名上看,这个方法应该作用于属性被设置之后。也就是说,该方法的初始化会晚于属性的初始化。
接下来要介绍的 FactoryBean 接口相信你不会陌生,它的定义如下所示:
public interface FactoryBean<T> {
T getObject() throws Exception;
Class<?> getObjectType();
boolean isSingleton();
}实际上,FactoryBean 是 Spring 框架中非常核心的一个接口,负责从容器中获取具体的 Bean 对象。
ApplicationEvent 和 ApplicationListener 是 Spring 框架中实现事件驱动编程的核心类。如果在一个 JavaBean 中实现了 ApplicationListener 接口,那么一旦有任何一种 ApplicationEvent 被发布,这个 Bean 将自动触发监听器处理程序。ApplicationListener 接口定义如下所示:
public interface ApplicationListener<E extends ApplicationEvent> extends EventListener {
void onApplicationEvent(E event);
}我们知道在 Spring 上下文对象 ApplicationContext 的整个生命周期中,每一个阶段或操作的开始和结束都可以触发一种事件。基于 ApplicationListener 这个监听器接口,我们就可以处理各种自定义的 ApplicationEvent。
Spring Boot 自动配置
Spring Boot 的自动配置功能强大,但也有一定的复杂度,让我们通过 @SpringBootApplication 注解来深入理解其背后的实现原理。
通过查看 @SpringBootApplication 注解的定义,我们发现该注解实际上是一个复合注解,由 @SpringBootConfiguration、@ComponentScan 和 @EnableAutoConfiguration 所组成。我们知道 @ComponentScan 是传统 Spring 框架中就内置的注解,而 @SpringBootConfiguration 注解也很简单,实际上只是对 Spring 框架中另一个常用组件 @Configuration 的一种包装,本身没有定义任何内容。
所以,我们接下来重点剖析 @EnableAutoConfiguration 注解,该注解定义如下所示。
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@AutoConfigurationPackage
@Import(AutoConfigurationImportSelector.class)
public @interface EnableAutoConfiguration {
String ENABLED_OVERRIDE_PROPERTY = "spring.boot.enableautoconfiguration";
Class<?>[] exclude() default {};
String[] excludeName() default {};
}可以看到,这里出现了一个新的注解,即 @AutoConfigurationPackage。从命名上讲, @AutoConfigurationPackage 注解的作用就是自动对某一个代码包进行配置。
另一方面,我们还看到通过 @Import 注解引入了一个 AutoConfigurationImportSelector 类。从命名上,我们也不难理解该类的作用是完成对导入的配置信息的自动选择。该类的核心方法 getCandidateConfigurations 实现了这一目标,如下所示:
protected List<String> getCandidateConfigurations(AnnotationMetadata metadata, AnnotationAttributes attributes) {
List<String> configurations = SpringFactoriesLoader.loadFactoryNames(getSpringFactoriesLoaderFactoryClass(), getBeanClassLoader());
// ...
return configurations;
}这里引出了在 Spring Boot 中真正负责加载配置信息的 SpringFactoriesLoader 类。这些类之间的交互关系如下图所示:
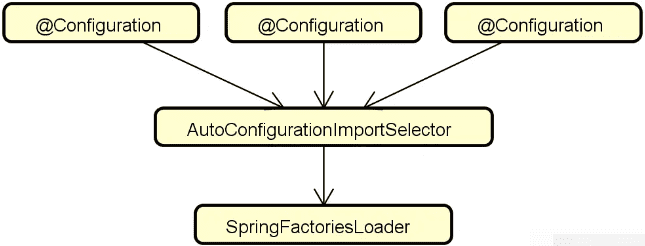
显然,想要完成配置信息的自动选择,我们首先需要执行配置文件的加载操作,这部分功能是由 SpringFactoriesLoader 来完成的。SpringFactoriesLoader 也是 Spring Boot 自动配置得以实现的关键组件。
SpringFactoriesLoader 类似 JDK 中的 SPI 机制所使用的 ServiceLoader 类,区别只是在于配置文件的存放位置和配置项对应的键值定义。在 SpringFactoriesLoader 中,我们需要通过 META-INF/spring.factories 目录来获取服务定义文件,并通过 EnableAutoConfiguration 这个健值来获取具体的配置信息。
下图展示了 SpringFactoriesLoader 和 ServiceLoader 之间的区别:
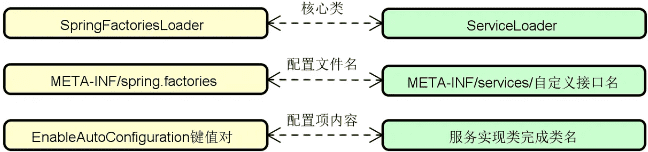
SpringFactoriesLoader 基于上图中指定的配置文件名和键值获取对应的配置信息,然后基于这些配置信息来实例化配置类,Spring Boot 通过反射机制实现了这一目标。SpringFactoriesLoader 类中的 loadSpringFactories 方法展示了这一过程,如下所示:
private static Map<String, List<String>> loadSpringFactories(@Nullable ClassLoader classLoader) {
// 从缓存中获取配置内容,如果存在则直接返回
try {
// 基于 ClassLoader 从 META-INF/spring.factories 获取配置文件资源地址 URL
while (urls.hasMoreElements()) {
// 获取配置文件资源
// 加载配置项
for (Map.Entry<?, ?> entry : properties.entrySet()) {
// 组装配置项 Key-Value
}
// 把配置信息放入缓存
// 返回结果
}
}
}我们在 spring-boot-autoconfigure 工程中所使用的 spring.factories 配置文件中知道了如下所示配置项:
# Auto Configure
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
org.springframework.boot.autoconfigure.admin.SpringApplicationAdminJmxAutoConfiguration,\
org.springframework.boot.autoconfigure.aop.AopAutoConfiguration,\
org.springframework.boot.autoconfigure.amqp.RabbitAutoConfiguration,\可以看到在 org.springframework.boot.autoconfigure.EnableAutoConfiguration 配置项中定义了各种以 -AutoConfiguration 结尾的配置类。通过 SpringFactoriesLoader,Spring Boot 就能做到在服务启动的过程中把它们加载到容器中并实现自动化配置。
源码解析
在介绍完理论知识之后,让我们回到实践。我们将分别分析 Mybatis Spring 的启动过程以及 Mybatis Spring Boot Starter 的实现原理。
Mybatis Spring 启动过程
mybatis-spring 框架完成了 Mybatis 与 Spring 之间的集成。打开 mybatis-spring 代码工程,我们快速寻找实现了 Spring 扩展点的类,这个类并不难找,它就是 SqlSessionFactoryBean 类。
很典型的,SqlSessionFactoryBean 实现了 FactoryBean、InitializingBean 和 ApplicationListener 这三个扩展点接口,其定义如下所示(列举了部分重要的变量):
public class SqlSessionFactoryBean implements FactoryBean<SqlSessionFactory>, InitializingBean, ApplicationListener<ApplicationEvent> {
// ...
private Configuration configuration;
private SqlSessionFactoryBuilder sqlSessionFactoryBuilder = new SqlSessionFactoryBuilder();
private SqlSessionFactory sqlSessionFactory;
private String environment = SqlSessionFactoryBean.class.getSimpleName();
// ...
}我们还是按照既有的思路,先来看看这些扩展点如何完成 Spring 与 Mybatis 框架之前的整合。首先,我们来看 InitializingBean 接口的实现,即如下所示的 afterPropertiesSet 方法(代码做了裁剪):
@Override
public void afterPropertiesSet() throws Exception {
// ...
this.sqlSessionFactory = buildSqlSessionFactory();
}显然,对于 SqlSessionFactoryBean 而言,主要职责就是完成 SqlSessionFactory 的构建,这也是这个类的类名由来,而完成这个操作的最合适的阶段就是 Bean 生命周期中的 InitializingBean 阶段。我们来看一下这里的 buildSqlSessionFactory 方法的具体实现过程,这个方法非常长,但代码结构比较简单。我们抛开大量的代码细节,使用如下所示的代码来展示这个方法的结构:
protected SqlSessionFactory buildSqlSessionFactory() throws IOException {
Configuration configuration;
XMLConfigBuilder xmlConfigBuilder = null;
if (this.configuration != null) {
// 如果当前的 configuration 不为空,则直接使用该对象
configuration = this.configuration;
// ...
} else if (this.configLocation != null) {
// 如果配置文件地址 configLocation 不为空,则通过 XMLConfigBuilder 进行解析并创建 configuration
xmlConfigBuilder = new XMLConfigBuilder(this.configLocation.getInputStream(), null, this.configurationProperties);
configuration = xmlConfigBuilder.getConfiguration();
} else {
// 如果以上两种情况都不满足,则创建一个新的 configuration 对象并进行参数赋值
configuration = new Configuration();
// ...
}
// 设置 objectFactory 等各种 Mybatis 运行时所需的配置信息
// ...
// 基于 configuration 通过 SqlSessionFactoryBuilder 构建 SqlSessionFactory
return this.sqlSessionFactoryBuilder.build(configuration);
}关于 SqlSessionFactoryBuilder,我们知道该类会创建一个 DefaultSqlSessionFactory,可以通过 DefaultSqlSessionFactory 进而获取 SqlSession 对象的实例。
然后,我们来关注 SqlSessionFactoryBean 实现的 FactoryBean 接口,从接口的泛型定义上,我们明白它的 getObject 方法应该返回的是一个 SqlSessionFactory 对象,如下所示:
@Override
public SqlSessionFactory getObject() throws Exception {
if (this.sqlSessionFactory == null) {
afterPropertiesSet();
}
return this.sqlSessionFactory;
}可以看到,这里的实现过程非常简单,如果目标 sqlSessionFactory 还没有被创建,就直接调用了前面介绍的 afterPropertiesSet 方法完成该对象的创建并返回。
最后,我们需要关注的是 onApplicationEvent 方法,这是 ApplicationListener 接口的具体实现,用来对 Spring 中所生成的 ApplicationEvent 进行响应,如下所示:
@Override
public void onApplicationEvent(ApplicationEvent event) {
if (failFast && event instanceof ContextRefreshedEvent) {
this.sqlSessionFactory.getConfiguration().getMappedStatementNames();
}
}就场景而言,这个方法的作用是在接收到代表容器刷新的 ContextRefreshedEvent 事件时,重新获取各种 MappedStatement。这里通过调用 Configuration 的 getMappedStatementNames 方法完成这一操作,如下所示:
public Collection<MappedStatement> getMappedStatements() {
buildAllStatements();
return mappedStatements.values();
}再往下看,就到了 Mybatis 内部的实现细节了,我们不再展开。至此,SqlSessionFactoryBean 中与 Spring 框架集成的相关内容就介绍到这里。通过 SqlSessionFactoryBean,我们就可以获取 SqlSessionFactory 对象,这是 Mybatis 框架启动过程的主要目标。
Mybatis Spring Boot Starter
基于前面介绍的 Spring Boot 中应用程序的自动配置机制,我们来做一些实践,通过剖析 Mybatis Spring Boot Starter 的启动过程来加深对所介绍内容的理解。
在 mybatis-spring-boot-starter 中存在几个代码工程,我们重点关注 mybatis-spring-boot-autoconfigure 工程。而在这个代码工程中,最重要的显然就是 MybatisAutoConfiguration 类。对于 Spring Boot 中的 -AutoConfiguration 类,我们首先需要重点关注的是类定义上的注解,如下所示:
@org.springframework.context.annotation.Configuration
@ConditionalOnClass({ SqlSessionFactory.class, SqlSessionFactoryBean.class })
@ConditionalOnSingleCandidate(DataSource.class)
@EnableConfigurationProperties(MybatisProperties.class)
@AutoConfigureAfter(DataSourceAutoConfiguration.class)
public class MybatisAutoConfiguration implements InitializingBean {
// ...
}我们看到这里用到了 @ConditionalOnClass 和 @ConditionalOnSingleCandidate 这两个注解,它们就是 Spring Boot 中的条件注解。在介绍 MybatisAutoConfiguration 之前,有必要对这些注解做一定展开。
我们在前面的介绍中已经了解到以 -AutoConfiguration 结尾的自动配置类数量会很多,在一个应用程序的开发过程中,我们通常不会全部使用到。这时候就需要引入一种机制来对这些自动配置类进行过滤。为此,Spring Boot 提供了一组 @ConditionalOn 系列条件注解。通这些注解,我们就可以基于特定的条件来选择性地加载某些配置类。
在 Spring Boot 中常见的条件注解可以参考下图:
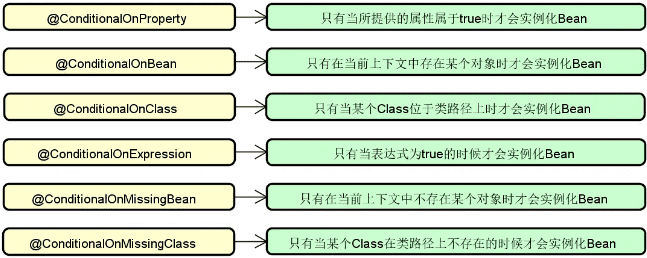
在前面介绍的 MybatisAutoConfiguration 类上,我们发现了 @ConditionalOnClass 和 @ConditionalOnSingleCandidate 这两个条件注解。基于这两个条件注解,我们可以明确 MybatisAutoConfiguration 能够实例化的前提有两个,一个是类路径中存在 SqlSessionFactory 和 SqlSessionFactoryBean,另一个是容器中只存在一个 DataSource 实例。两者缺一不可,这是一种常用的自动配置控制技巧。
然后,我们在 MybatisAutoConfiguration 类上看到了一个 @EnableConfigurationProperties 注解。通过这个注解,所有添加了 @ConfigurationProperties 注解的配置类就会自动生效。这里的 @EnableConfigurationProperties 注解中指定的是 MybatisProperties 类,该类定义了 Mybatis 运行时所需要的各种配置信息,而我们在 MybatisProperties 类上确实也发现了 @ConfigurationProperties 注解,并指定了 prefix 为 mybatis,如下所示:
@ConfigurationProperties(
prefix = "mybatis"
)
public class MybatisProperties {
// ...
}最后,在 MybatisAutoConfiguration 类上还存在一个 @AutoConfigureAfter 注解,这个注解可以根据字面意思进行理解,即在完成某一个类的自动配置之后再执行当前类的自动配置,这个需要提前装配的类指的就是 DataSourceAutoConfiguration。
理解了 @ConditionalOnClass、@EnableConfigurationProperties 和 @AutoConfigureAfter 等一系列注解之后,我们回过头来再看 MybatisAutoConfiguration 类的代码结构就显得比较简单明了。MybatisAutoConfiguration 类中核心方法之一就是如下所示的 sqlSessionFactory 方法:
@Bean
@ConditionalOnMissingBean
public SqlSessionFactory sqlSessionFactory(DataSource dataSource) throws Exception {
SqlSessionFactoryBean factory = new SqlSessionFactoryBean();
factory.setDataSource(dataSource);
factory.setVfs(SpringBootVFS.class);
if (StringUtils.hasText(this.properties.getConfigLocation())) {
factory.setConfigLocation(this.resourceLoader.getResource(this.properties.getConfigLocation()));
}
applyConfiguration(factory);
// 省略一系列配置项设置方法
return factory.getObject();
}显然,这里基于前面介绍的 SqlSessionFactoryBean 构建了 SqlSessionFactory 实例。注意到在该方法上同样添加了一个 @ConditionalOnMissingBean 注解,标明只有在当前上下文中不存在 SqlSessionFactoryBean 对象时才会执行上述方法。
接下来,我们需要在 META-INF/spring.factories 文件中明确指定自动配置类。根据 Spring Boot 自动配置机制的原理,对于 mybatis-spring-boot-autoconfigure 工程而言,这个配置项内容应该是这样:
# Auto Configure
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
org.mybatis.spring.boot.autoconfigure.MybatisAutoConfiguration至此,整个 Mybatis Spring Boot Starter 的介绍就告一段落。作为总结,我们可以把创建一个 Spring Boot Starter 的过程抽象三个步骤,如下图所示:
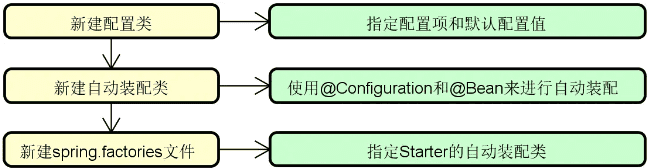
在日常开发过程中,基于上述三个步骤,我们就可以参考 Mybatis Spring Boot Starter 的实现方式来设计并开发自定义的 starter 组件。
解题要点
正如在问题背景部分中给出的常见面试题所示,面试官在面试过程中往往不会直接问 Mybatis 与 Spring 框架是如何集成 这样的问题,而是会考查具体的知识点,例如抛出 Spring 中 Bean 中的 Constructor、@PostConstruct 以及 InitializingBean 这三者之间的执行顺序是怎么样的? 类似的问题。这是一类比较好的面试题,我作为面试官也经常会用这种类型的题目考查面试者对于 Spring 中一些基本实现机制的理解程度。
从考点上讲,一方面这道题的知识点比较丰富,涉及到对 Spring 框架中的一些核心概念;另一方面,这道题也具有一定的综合性,要求面试者在理解这些核心概念的基础上能够用自己的表达方式串接起来。
针对这一问题,我们首先应该对 Spring 中 @PostConstruct 注解和 InitializingBean 接口的作用和应用场景有明确的认识,最好有一定的实践基础,在回答这个问题时先说明这一点。然后,在介绍了应用方式的基础上,我们需要深入这些注解和方法的背后,进一步介绍 BeanPostProcessor 等 Spring 内部的实现接口及其实现过程。整个回答过程中涉及的概念和对象可能有点多,注意侧重点和回答问题的节奏。有些地方不用说得过细,只需要围绕“执行顺序”这一核心考点进行展开即可,避免陷入细节而导致问题回答思路上的混乱。
随着 Spring Boot 成为日常开发的主流框架,Spring Boot 的自动配置机制也变成了一个经典问题。但凡是使用过 Spring Boot 的候选人,我一般都会通过这个问题来考查对方的知识体系。自动配置是 Spring Boot 最核心的机制,该问题的考点明确,问题的答案也很明确,大家通过记忆以及加上自己的一些理解进行解答即可。
从回答思路上,Spring Boot 的自动配置机制涉及的知识点包括两大部分内容。首先我们需要介绍 @SpringBootApplication 注解及其背后的三大注解 @SpringBootConfiguration、@EnableAutoConfiguration 和 @ComponentScan,这几个注解必须点到。然后,随着对这些注解的深入阐述,我们需要再引出具有与 SPI 实现机制类似功能的 SpringFactoriesLoader 类,该类包含了自动配置相关的一些配置项处理方式。本讲详细阐述了 Spring Boot 自动配置机制的实现原理,从源码角度分析了为什么 Spring Boot 能够做到自动配置。文中所述的知识体系都可以用来回答这个问题。由于内容比较多,回答过程中还是建议需要把握节奏,避免过多嵌入细节。
小结与预告
在本讲内容中,我们首先介绍的是 Spring 框架中的几个核心扩展点,这些扩展点是 Dubbo 和 Mybatis 等开源框架与 Spring 进行集成的主要入口。然后,Spring Boot 的自动配置原理也是我们需要掌握的内容,因为它们被广泛地应用到与 Spring Boot 框架的集成过程中。围绕前面介绍的这些内容,我们基于 Mybatis 框架讲解了 Mybatis Spring、Mybatis Spring Boot Starter 等专用于两者之间集成的框架实现原理。
很多时候我们需要对框架的功能进行完善和升级,这时候就需要框架本身具备高度的可扩展性。针对这一点,业界也存在一些主流的架构模式可以用来实现这一目标,其中最具代表性的就是微内核架构。下一讲我们就将结合 Dubbo 等具体框架围绕“为什么很多开源框架都会内置一套微内核架构?”这一话题展开详细的分析。
组件扩展:为什么很多开源框架都会内置一套微内核架构?
在上一讲中,我们讨论了框架与框架之间如何进行集成的实现过程,也引出了框架扩展性这一话题。
对于软件开发而言,扩展性是一个永恒的话题,实现系统可扩展的方法有很多。而本讲要介绍的微内核架构模式就是其中一种非常具有代表性的架构模式,除了我们熟悉的 Dubbo,还有 SkyWalking、ShardingSphere 等一系列主流的开源框架都应用了这一架构模式。
那么,什么是微内核架构?为什么很多开源框架都会内置一套微内核架构?作为非常经典的一类面试题,本讲内容将和你一起分析和探讨这一组件背后的设计理念以及在开源框架中的具体实现方式。
问题背景
在日常开发过程中,你应该经常会遇到这样的需求:针对某个业务场景,我们希望在系统中添加一种新的处理逻辑,但又不想对现有的系统造成影响。从架构设计上讲,这是一种典型的系统扩展性需求。
从扩展性的实现策略上讲,插件式系统是我们追求的一个目标。我们希望打造如下图所示的效果,调用者能够通过基于配置的插件机制动态获取它想要的任何插件。
上图看似简单,但想要打造功能完备的插件式系统并不容易。我们知道很多编程语言具有动态加载机制。基于编程语言的动态加载机制,我们就可以实现插件化系统,在配置时而非编译时连接类。同时,通过引入工厂模式和配置化思想,我们也可以在动态加载机制上实现更为完善的自定义封装。
这些都是系统设计上的理念,但在面试过程中,面试官会考查得更加直接、更为细节,常见的提问方式包括:
- 为了实现系统扩展性,你有哪些思路?
- 微内核架构的基本组成架构是怎么样的?
- Dubbo 框架采用了什么技术实现方式来确保它具有高度的可扩展性?
- Dubbo 框架为开发人员提供了哪些扩展点?
- 如果想要在 Dubbo 中实现一个自定义的扩展点,你有什么办法?
- SPI 是什么概念?我们如何使用 SPI 机制?
- Dubbo 中的 SPI 机制与 JDK 中的 SPI 机制有什么区别?
基于上述问题,我们需要引出本讲要讨论的主题,即微内核架构。这是一种应用非常广泛的架构模式,也是面试过程中出现频率非常高的一个技术组件。
接下来,我们来对这类问题做一些分析和展开。
问题分析
微内核架构有时候就直接被称为插件架构,它在组成结构上包含两部分组件,即内核系统和插件。
这里的内核系统用来定义插件的实现规范,并管理着插件的生命周期;而各个插件是相互独立的组件,各自根据实现规范完成某项业务功能,并嵌入到内核系统中,如下图所示:

基于微内核架构,当系统中的某个组件需要进行修改时,要做的只是创建一个新的组件并替换旧组件,而不需要改变原有组件的实现方式,更加不需要调整整个系统架构。
那么这里的插件具体指的是什么呢?这就需要我们引入一个新的概念,即 SPI,英文全称叫 Service Provider Interface,也就是服务提供接口。可以认为 SPI 就是应对系统扩展性的一个个扩展点,也是我们对系统中所应具备的扩展性的抽象。
插件化实现机制说起来简单,做起来却不容易,我们需要考虑两方面内容。一方面,我们需要梳理系统的变化并把它们抽象成一个个 SPI 扩展点。另一方面,当我们实现了这些 SPI 扩展点之后,就需要构建一个能够支持这种可插拔机制的具体实现,从而提供一种 SPI 运行时环境。如下图所示:
接下来,我们就来一起讨论与微内核架构相关的具体技术体系。
技术体系
微内核架构在 Dubbo 等主流开源框架中应用非常广泛。这些框架采用的实现方式也都比较类似,基本思路就是引入前面提到的 SPI 机制。
那么,怎么实现 SPI 机制呢?事实上,JDK 已经内置了一套实现 SPI 机制的开发组件。基于这套组件,想要实现 SPI,具体来说要完成三个步骤,如下图所示:
对于 SPI 而言,我们需要设计一个服务接口,并根据业务场景提供不同的实现类。然后,我们在 Java 代码工程的 META-INF/services 目录中创建一个以服务接口命名的文件,并配置对应的想要使用的实现类。在代码工程中执行这些步骤,最终我们可以得到一个包含 SPI 类和配置的 JAR 包。
而对于 SPI 的使用者,就可以通过 JAR 包中 META-INF/services/ 目录下的配置文件找到具体的实现类名并进行实例化。
上图中的后面两个步骤实际上都是为了遵循 JDK 中 SPI 的实现机制而进行的配置工作。
接下来,我们可以通过简单的代码示例来演示这些步骤。
让我们来模拟这样一个应用场景,一般业务系统中都会涉及日志组件,我们希望对业界主流的日志工具做一层包装,以便支持日志组件的灵活应用。那么,基于 SPI 的约定,我们将创建一个单独的工程 log-spi 来存放服务接口,并给出接口定义,请注意这个服务接口的完整类路径为 com.spi.LogProvider,接口中只包含一个以 Info 级别记录日志信息的简单方法,如下所示:
package com.spi;
public interface LogProvider {
// 记录 Info 日志
public void info(String info);
}假设系统在设计之初使用的是 log4j 日志库。然后我们需要实现这个服务接口,这里创建另一个代码工程 log-log4j 用来提供基于 log4j 日志库的实现,请注意,这个实现类的名称是 Log4jProvider,如下所示:
public class Log4jProvider implements LogProvider {
@Override
public void info(String info) {
System.out.println("Log4j:" + info);
}
}接下来的这个步骤很关键,我们需要创建一个以 LogProvider 这个接口对应的完整类路径命名的文件,并放在 META-INF/services/ 目录下。在这个文件中,我们指定该接口的实现类为前面已经创建的 Log4jProvider,如下图所示:
最后,我们创建一个外部工程来调用服务接口,首先需要将 log-log4j 所生成的 JAR 包添加到这个外部工程中的类路径中。然后,我们使用 JDK 中 ServiceLoader 工具类来完成对 LogProvider 实例的加载。在这里,我们通过该工具类的 load 方法获取所有的 LogProvider 实例,然后遍历这些实例并调用服务接口方法,如下所示:
import java.util.ServiceLoader;
import com.spi.LogProvider;
public class Main {
public static void main(String[] args) {
ServiceLoader<LogProvider> loader = ServiceLoader.load(LogProvider.class);
for (LogProvider provider: loader) {
System.out.println(provider.getClass());
provider.info("testInfo");
}
}
}运行这段代码,我们会得到系统的输出。可以看到这里获取的是针对 log4j 的 Log4jProvider 类中的具体方法实现,表示整个 SPI 实例的加载过程是正常的,如下所示:
class com.spi.Log4jProvider
Log4j:testInfo请注意,在上面这个 main 函数中,我们并没有引入任何与 Log4jProvider 相关的包结构,但在运行过程中,却实现了对 Log4jProvider 类的动态调用,这是微内核架构的核心特征,对组件之间的依赖关系进行了解耦,从而确保了系统的扩展性。
现在,让我们来考虑这样一种场景。随着工具的更新或者架构的调整,我们需要提供一套基于 logback 日志库的日志实现来替换现有的基于 log4j 的方案。基于扩展性考虑,最好的办法是提供另一个 SPI 实例。这样,我们创建新的一个代码工程 log-logback,并完成与 log-log4j 代码工程一样的开发工作。然后,我们把 log-logback 所生成的 JAR 包添加到外部工程的类路径中并去除原有 log-log4j 的 JAR 包,完成这些操作之后,我们再来执行前面的 main 函数,得到的就是来自 LogbackProvider 类中的输出结果,如下所示:
class com.spi.LogbackProvider
Logback:testInfo当然,你可以根据需要提供任何 LogProvider 接口的实现类并动态集成到系统的执行流程中。请注意,无论是添加、替换或者移除具体的 SPI 实现,对于原有的外部工程而言,我们并没有做任何的代码调整。这就满足了我们在本讲开头提到的扩展性的设计理念,即在现有系统中添加新的组件时,不会对现有的系统造成影响。
至此,完整的 SPI 提供者和使用者的实现过程演示完毕。这个示例非常简单,但却是 Dubbo 中实现微内核架构的基础。接下来,就让我们把话题转换到 Dubbo,看看 Dubbo 中应用 SPI 机制的具体方法。
源码解析
微内核模式在 Dubbo 中的应用
Dubbo 中应用微内核模式的方法也是基于 SPI,但 Dubbo 对 JDK 中的 SPI 机制做了优化,并添加了一些扩展功能。
首先,Dubbo 提供了一个 @SPI 扩展点注解,该注解是理解 Dubbo SPI 机制的基础。在 Dubbo 中,只有添加了 @SPI 注解的接口类才会去查找扩展点实现。
我们随处可以看到 @SPI 注解的应用场景。例如,以常见的 Protocol 接口为例,在该接口上使用的就是 @SPI("dubbo") 注解,代表该接口是一个扩展点,同时该扩展点的默认实现是 DubboProtocol,如下所示:
@SPI("dubbo")
public interface Protocol我们已经知道 JDK 只会把 SPI 配置存放在 META-INF/services/ 这个目录下,而 Dubbo 则提供了三个类似这样的目录,如下图所示:
作为示例,我们继续围绕 Dubbo 中的 Protocol 接口展开讨论。针对 Protocol 接口,Dubbo 提供了包括 GrpcProtocol、DubboProtocol 在内的多个实现类,并通过 SPI 机制完成对具体某种实现方案的加载过程。让我们分别来到提供这些实现类的代码工程 dubbo-rpc-grpc 和 dubbo-rpc-dubbo,会发现在 META-INF/dubbo/internal/ 目录下都包含了一个 com.apache.dubbo.rpc.Protocol 配置文件。
其中,dubbo-rpc-grpc 工程的代码结构如下图所示:
类似的,dubbo-rpc-dubbo 工程的代码结构如下图所示:
我们分别打开这两个工程的 com.apache.dubbo.rpc.Protocol 配置文件,可以发现它们分别指向了 org.apache.dubbo.rpc.protocol.grpc.GrpcProtocol 和 org.apache.dubbo.rpc.protocol.dubbo.DubboProtocol 类,如下所示:
// dubbo-rpc-grpc 工程
grpc=org.apache.dubbo.rpc.protocol.grpc.GrpcProtocol
// dubbo-rpc-dubbo 工程
dubbo=org.apache.dubbo.rpc.protocol.dubbo.DubboProtocol当 Dubbo 在引用具体某一个代码工程时,就可以通过该工程中的配置项找到 Dubbo 接口对应的扩展点实现。
接下来,就让我们深入探讨 Dubbo 中扩展点的加载机制,为了加载扩展点,Dubbo 专门提供了一个 ExtensionLoader 类,如果我们想要获取 DubboProtocol 的实现类,可以使用如下代码:
DubboProtocol dubboProtocol = ExtensionLoader.getExtensionLoader(Protocol.class).getExtension(DubboProtocol.NAME);我们来看一下 getExtension 方法的细节,该方法的具体实现过程如下所示:
public T getExtension(String name) {
if (name == null || name.length() == 0) {
throw new IllegalArgumentException("Extension name == null");
}
if ("true".equals(name)) {
return getDefaultExtension();
}
Holder<Object> holder = cachedInstances.get(name);
if (holder == null) {
cachedInstances.putIfAbsent(name, new Holder<Object>());
holder = cachedInstances.get(name);
}
Object instance = holder.get();
if (instance == null) {
synchronized (holder) {
instance = holder.get();
if (instance == null) {
instance = createExtension(name);
holder.set(instance);
}
}
}
return (T) instance;
}我们看到这里用到了缓存,该方法会首先检查缓存中是否已经存在扩展点实例,如果没有则通过 createExtension 方法进行创建。我们一路跟踪 createExtension 方法,发现它又调用了 getExtensionClasses 方法,而 getExtensionClasses 方法内部又使用了 loadExtensionClasses 方法。在 loadExtensionClasses 方法中,我们终于看到了熟悉的 SPI,该方法如下所示:
private Map<String, Class<?>> loadExtensionClasses() {
final SPI defaultAnnotation = type.getAnnotation(SPI.class);
if (defaultAnnotation != null) {
// 确定缓存名称
}
Map<String, Class<?>> extensionClasses = new HashMap<String, Class<?>>();
loadFile(extensionClasses, DUBBO_INTERNAL_DIRECTORY);
loadFile(extensionClasses, DUBBO_DIRECTORY);
loadFile(extensionClasses, SERVICES_DIRECTORY);
return extensionClasses;
}在这里,我们注意到调用了三次 loadFile 方法,分别对应 META-INF/ 目录下的三个子目录。在 loadFile 方法中,可以看到 Dubbo 是直接通过 Class.forName 的反射机制加载这些 SPI 的扩展类,并进行缓存。
Dubbo 中的扩展点
在 Dubbo 中存在一大批扩展点,这些扩展点对应于 RPC 架构中的不同组件。事实上,很多 Dubbo 内置的功能组件也都被设计成了扩展点,从而可以被框架的开发人员按需进行替换。
要想知道 Dubbo 中到底包含了的所有扩展点,我们可以整合所有工程中 META-INF/dubbo/internal/ 目录下的配置文件来进行获取。下图展示了 Dubbo 扩展点分层图:
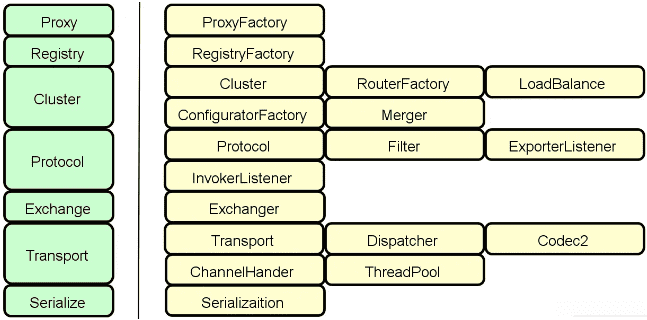
我们无意对上图中所有的扩展点都做详细展开,在这里,我们选择 LoadBalance 作为我们的扩展点示例,以此介绍 Dubbo 中扩展点的具体实现方法。
首先,让我们来看看 LoadBalance 接口的定义,如下所示:
@SPI(RandomLoadBalance.NAME)
public interface LoadBalance {
<T> Invoker<T> select(List<Invoker<T>> invokers, URL url, Invocation invocation) throws RpcException;
}如果我们在 dubbo-cluster 工程中找到 META-INF/dubbo/internal/org.apache.dubbo.rpc.cluster.LoadBalance 配置文件,不难想象该文件中定义了我们已知的四个 LoadBalance 扩展实现,如下所示:
random=org.apache.dubbo.rpc.cluster.loadbalance.RandomLoadBalance
roundrobin=org.apache.dubbo.rpc.cluster.loadbalance.RoundRobinLoadBalance
leastactive=org.apache.dubbo.rpc.cluster.loadbalance.LeastActiveLoadBalance
consistenthash=org.apache.dubbo.rpc.cluster.loadbalance.ConsistentHashLoadBalance可以看到,在 LoadBalance 接口上存在 @SPI 注解,代表它是一个扩展点。而该解中的参数 RandomLoadBalance.NAME 表示该扩展点的默认实现是随机(random)算法,关于 Dubbo 中负载均衡算法,你可以结合之前做一些回顾。
解题要点
对于微内核架构而言,我们首先需要明确它的组成作用。面试官会考查候选人对微内核架构基本概念的理解程度,该架构的作用还是提供了一个可以高度扩展的实现机制,是很多开源框架中实现系统扩展性的首选架构模式。从知识体系上讲,关于微内核架构的基本概念本讲都做了详细的介绍,回答时只要有条理地进行说明即可。
回答这类问题时的一个建议是,可以把设计思想拔高到架构层次,从扩展性角度进行切入。同时,微内核架构确实应用非常广泛,像 Dubbo 框架以及主流的分库分表中间件 ShardingSphere 等开源框架都用到了这个架构模式。如果能够有所发散,展示一些自己的知识面,是一种加分策略。
关于 SPI 机制也是常见的考查点。我们首先要明白 API 和 SPI 的区别,API 面向的是框架的用户,而 SPI 面向的是框架的开发人员。SPI 在本质上是提供给服务提供商与扩展框架功能的开发者使用的接口。
回答这个问题时,我们可以先围绕 SPI 的定义,即服务提供接口 Service Provider Interface 来进行展开。然后,结合微内核架构的设计思想给出进一步的说明。本讲介绍了 SPI 机制的一种具体实现,即基于 JDK 的 ServiceLoader 类完成 SPI 实现的加载和管理,并给出了基于 ServiceLoader 类的具体使用案例。这也是理论联系实践的一种介绍方法,即先阐述理论知识,然后再给出案例的说明即可。当然,如果你对 JDK 的 ServiceLoader 类的实现原理有兴趣,也可以进行进一步的深入学习,我们在本讲内容中也基于 Dubbo 框架再次对微内核模式以及 ServiceLoader 类进行讨论。
结合 SPI 和 Dubbo 框架,面试官会考查 Dubbo 中实现的 SPI 机制与 JDK 中默认的方式的不同点。这个问题也比较典型,在实际面试过程中经常被问到。针对这个问题,我们也需要明确,所谓的 SPI 机制只是一种设计理念,而具体的实现策略视框架的不同会有所差别。虽然 Dubbo 也采用了 SPI 机制,也是从 JAR 中加载对应的扩展类,但它的实现方式与 JDK 中基于 ServiceLoader 是不一样的。我们需要从这两方面的差异点出发来梳理这个问题的解答思路。
基于本讲中给出的内容,就加载 SPI 实例的配置文件位置而言,Dubbo 支持更多的加载路径。同时,Dubbo 采用的是直接通过名称对应的 Key 值来定位具体的实现类,而 ServiceLoader 内部使用的是一个迭代器,在获取目标接口的实现类时只能通过遍历的方式把配置文件中的类全部加载并实例化,显然效率比较低下。Dubbo 中专门采用了与 JDK 不同的 SPI 实现机制,主要目的就是克服这种效率低下的情况,并提供更多的灵活性。
小结与预告
本讲内容我们剖析分布式主流开源框架中所采用的一种常见架构模式,即微内核架构模式。对于微内核架构模式,我们关注它的基本概念以及 JDK 中所提供的 SPI 实现方式。而结合具体的开源框架,我们发现 Dubbo 中实现微内核架构采用了与 JDK 所提供的这套机制类似的设计思路,但并没有直接照搬而是重新提供了一套自己的实现机制。
下一讲,我们继续讨论分布式系统构建过程中另一种具体代表性的架构模式,即管道-过滤器模式。可以说,管道-过滤器是所有请求-响应类框架中的标准组件。那么,为什么它会应用如此广泛?这个架构模式到底能用来解决什么问题呢?我们下一讲中再聊。
流程定制:管道-过滤器架构能用来解决什么问题?
在上一讲中,我们基于微内核架构模式讨论了系统扩展性的实现方式。掌握架构模式的难度在于每个模式看上去都能够理解但就是不知道如何应用,固然在日常开发过程中多尝试应用这些模式有助于提高自身的设计能力,但通过阅读源代码来加深对架构模式的理解和掌握是一条捷径。
在本讲内容中,我们将继续引出另一种可以用来实现系统扩展性的架构模式,这就是管道-过滤器模式。和微内核架构相比,管道-过滤器模式更加通用,几乎所有请求-响应式的系统中都可以用到这种架构模式。也正是因为这一点,管道-过滤器模式也经常出现在各大公司的面试环节。
那么,什么是管道-过滤器架构?它究竟能用来解决什么问题?本讲内容将给出答案。
问题背景
很多系统都存在固定的主流程,执行该主流程就能完成系统的核心功能。但在现实开发过程中,我们往往希望在主流程中添加一些附加流程,一方面确保主流程的执行不受影响,另一方面又可以通过这些额外流程来完成一些定制化需求。通常,这里的主流程面向业务核心功能,而附加流程则更多关注非功能性需求或扩展性需求。管道-过滤器模式就是用来应对这类场景。
下图展示了这一层抽象概念:
可以看到,我们在请求和响应的前后添加一组定制化组件。上图看上去比较简单,但实现过程其实是很有难度的,我们需要考虑的点有很多,包括:
- 如何在主流程中找到合适的切入点来添加定制化组件?
- 这些定制化组件如何不影响到主流程的执行过程?
- 有多个定制化组件时,我们如何管理它们的执行顺序?
- 如何确保上一个定制化组件的输出能够成为下一个定制化组件的输入?
- 这些定制化组件之间如何确保足够的解耦?
围绕这些问题,我们可以采用很多不同的实现策略。而管道-过滤器架构天生就为我们管理上图中的各种定制化组件提供了解决方案。围绕管道-过滤器架构,我们也可以引出一些常见的面试题,如下所示:
- 你所知道的管道-过滤器架构的应用场景有哪些?
- 管道-过滤器架构的基本组成结构是怎么样的?
- 如何管理多个过滤器之间的协作关系?
- 如何高效构建一个过滤器链?
- Dubbo 中是如何实现管道-过滤器架构的?
- 如果想要在 Dubbo 中实现一个自定义的过滤器,你会怎么做?
- Mybatis 中是如何实现管道-过滤器架构的?
- 如果想要在 Mybatis 中实现一个自定义的过滤器,你会怎么做?
针对不同的框架,类似上面所示的这些面试题还可以罗列很多。这些面试题既有概念,又有实践,有些还和日常开发过程中的一些需求息息相关,需要我们对这些问题背后的考点做细化分析。
问题分析
我们先来把管道-过滤器架构与上一讲中介绍的微内核架构做一个对比。
本质上,微内核架构使用了一种插件化机制来对系统中组件与组件之间的调用关系进行扩展,从而增强系统构建的灵活性。而在请求-响应式的系统中,管道-过滤器实现扩展性采用的是类似切面(Aspect)的设计理念。基于这一架构模式,我们可以在请求流程中嵌入那些非功能的处理逻辑,这些处理逻辑的添加和删除过程相互独立,而且对于请求流程而言是无感知的。这是我们回答这类问题的第一个要点,即管道-过滤器模式能够解决的问题以及适用的具体场景。
第二个需要考虑的要点是,如何动态把握请求的处理流程?我们首先想到的是诸如适配器模式等常见的设计模式,但设计模式主要关注细粒度的微观设计,并不适合高层次的体系结构设计。从结构上讲,管道-过滤器是一种组合行为,主功能是以切面的方式实现。管道-过滤器具有高度抽象化的通用结构和功能特性。
最后,不可否认,在分布式系统构建过程中,管道-过滤器可以说是不可缺少的一种技术组件。当我们在阅读一些开源框架的源码时,看到 Filter(过滤器)或 Interceptor(拦截器)等名词时(如 Dubbo 用的是 Filter,而 Mybatis 用的是 Interceptor),往往就是碰上了管道-过滤器模式。因此,应对这类问题的第三个要点就是掌握管道-过滤器模式在主流开源框架中的应用方式和实现原理。
技术体系
管道-过滤器架构模式是用于解决适配和扩展性问题的代表性架构模式,结构上主要包括过滤器和管道两种元素,如下图所示:
在管道-过滤器结构中,执行定制化功能的组件被称为过滤器,负责执行具体的业务逻辑。每个过滤器都会接收来自主流程的请求,并返回一个响应结果到主流程中。而另一方面,管道用来获取来自过滤器的请求和响应,并把它们传递到后续的过滤器中,相当于是一种通道。同时,在管道-过滤器模式中,一般都会存在一个过滤器链(Filter Chain) 的概念。过滤器链带有多个过滤器,并按照链中的顺序执行过滤器。
管道-过滤器风格的一个典型应用是 Web 容器的过滤器机制。例如,下图所示的就是 Nginx 中对 HTTP 请求的响应过程,可以看到在生成最终的 HTTP 响应之前,可以通过添加多个 Filter 对由处理器所产生的输出内容进行处理。
从上图中,我们可以看到管道-过滤器模式的特点在于把一系列的定制化需求转换成一种类似数据流的处理方式,数据通过管道流经一系列的过滤器,在每个过滤器中完成特定的业务逻辑。显然,每个过滤器能够独立完成自身的职责而不需要依赖于其他过滤器。这种特性使得系统的扩展性得到了巨大的提升,因为过滤器之间没有耦合度,所以我们可以很容易对现有的过滤器进行替换,而动态添加和删除过滤器也不会对整个处理流程产生任何影响。
在 Dubbo 和 Mybaits 框架中都应用了管道-过滤器模式,而且也都提供了基于过滤器链的实现方式,让我们先来看看它在 Dubbo 中的应用。
源码解析
管道-过滤器模式在 Dubbo 中的应用
Dubbo 中的过滤器概念基本上符合我们对管道-过滤器模式的理解。在接下来的内容中,我们先来看一下 Dubbo 中过滤器链的构建过程,然后介绍 Dubbo 中现有过滤器的实现方法。
Dubbo 的过滤器实现入口是在 ProtocolFilterWrapper 类中,在服务暴露和服务引用时都会使用到过滤器链。所谓的 Wrapper,顾名思义,是对扩展类的一种包装,如下图所示:
Dubbo 中的包装类同样实现扩展点接口,具有与扩展点一样的方法。目前,纵观整个 Dubbo 框架,只存在一个 Wrapper,即 ProtocolFilterWrapper。ProtocolFilterWrapper 类实现了 Protocol 接口,并具有如下所示的 export 和 refer 方法实现。
public <T> Exporter<T> export(Invoker<T> invoker) throws RpcException {
if (Constants.REGISTRY_PROTOCOL.equals(invoker.getUrl().getProtocol())) {
return protocol.export(invoker);
}
return protocol.export(buildInvokerChain(invoker, Constants.SERVICE_FILTER_KEY, Constants.PROVIDER));
}
public <T> Invoker<T> refer(Class<T> type, URL url) throws RpcException {
if (Constants.REGISTRY_PROTOCOL.equals(url.getProtocol())) {
return protocol.refer(type, url);
}
return buildInvokerChain(protocol.refer(type, url), Constants.REFERENCE_FILTER_KEY, Constants.CONSUMER);
}可以看到这两个方法都使用了一个名为 buildInvokerChain 的方法,从命名上看,该方法就是用来构建调用链,如下所示:
private static <T> Invoker<T> buildInvokerChain(final Invoker<T> invoker, String key, String group) {
Invoker<T> last = invoker;
List<Filter> filters = ExtensionLoader.getExtensionLoader(Filter.class).getActivateExtension(invoker.getUrl(), key, group);
if (filters.size() > 0) {
for (int i = filters.size() - 1; i >= 0; i--) {
final Filter filter = filters.get(i);
final Invoker<T> next = last;
last = new Invoker<T>() {
// 这里构造一个最简化的 Invoker 作为调用链的载体 Invoker
};
}
}
return last;
}我们在这里看到了用于获取扩展点的 ExtensionLoader。注意,这里对通过扩展点加载的过滤器进行了排序,从而确保过滤器链按设想的顺序进行执行。
看完过滤器链,我们反过来看一下过滤器。Dubbo 中的 Filter 接口定义如下所示:
@SPI
public interface Filter {
Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException;
}可以看到 Filter 接口能够获取传入的 Invoker,从而对其进行拦截和处理。针对 Filter 接口,Dubbo 中一共存在 21 个实现类,我们无意对所有这些过滤器组件做详细展开,而是挑选一个代表性的 Filter 进行介绍,这里我们选择 TokenFilter。
TokenFilter 的作用很明确,即通过 Token 进行访问鉴权,通过比对 Invoker 中的 Token 和输入参数中的 Token 来判断请求是否合法,其代码实现如下所示:
public class TokenFilter implements Filter {
public Result invoke(Invoker<?> invoker, Invocation inv) throws RpcException {
String token = invoker.getUrl().getParameter(Constants.TOKEN_KEY);
if (ConfigUtils.isNotEmpty(token)) {
Class<?> serviceType = invoker.getInterface();
Map<String, String> attachments = inv.getAttachments();
String remoteToken = attachments == null ? null : attachments.get(Constants.TOKEN_KEY);
// 比对 Token
if (!token.equals(remoteToken)) {
// ...
}
}
return invoker.invoke(inv);
}
}上述代码中,我们关注两点。首先我们看到可以通过 invoker.getUrl 方法获取 Invoker 中的 URL 对象,而我们知道 Dubbo 中的 URL 作为统一数据模型,以 Key-Value 对的形式包含了所有服务调用过程中的参数。同时,我们看到了 Invocation 对象,该对象可以理解为是一种 DTO(Data Transfer Object,数据传输对象),用来封装所需要传递的数据。这样,一方面我们通过 URL 对象获取本地 token 参数,另一方面,我们通过 Invocation 也获取了 remoteToken,从而可以执行对比和校验操作。这也是 Dubbo 中处理调用信息传递的非常常见的一种做法,我们可以在很多地方看到类似的代码。
最后,让我们基于对 Dubbo 中过滤器机制的理解来实现一个自定义的过滤器组件。这个过滤器非常简单,就是记录一下 invoke 调用所使用的时间,如下所示:
public class TimeLogFilter implements Filter {
private static Logger log = LoggerFactory.getLogger(TimeLogFilter.class);
@Override
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
long start = System.currentTimeMillis();
Result result = invoker.invoke(invocation);
long elapsed = System.currentTimeMillis() - start;
if (invoker.getUrl() != null) {
log.info("[{}], [{}], {}, [{}], [{}], [{}]", invoker.getInterface(), invocation.getMethodName(), Arrays.toString(invocation.getArguments()), result.getValue(), result.getException(), elapsed);
}
return result;
}
}可以看到,在 Dubbo 中,我们通过实现 Filter 接口并传入 Invoker 和 Invocation 对象就可以完成一个自定义过滤器的开发工作。
管道-过滤器模式在 Mybatis 中的应用
在 Mybatis 中,管道-过滤器模式通过拦截器的概念进行体现。而对外进行暴露时,则用到了 Plugin 配置项。想要在 Mybatis 中使用管道-过滤器模式,那就需要在配置文件中添加类似如下所示的配置项,可以看到在 <plugin> 配置段中可以添加一个自定义的 interceptor 配置项。
<configuration>
<plugins>
<plugin interceptor="com.tianyalan.mybatis.interceptor.MyInterceptor">
<property name="prop1" value="prop1"/>
<property name="prop2" value="prop2"/>
</plugin>
</plugins>
</configuration>然后,在解析 XML 配置文件的 XMLConfigBuilder 类中,我们找到了解析 <plugin> 配置段的代码,如下所示:
private void pluginElement(XNode parent) throws Exception {
if (parent != null) {
for (XNode child : parent.getChildren()) {
String interceptor = child.getStringAttribute("interceptor");
Properties properties = child.getChildrenAsProperties();
Interceptor interceptorInstance = (Interceptor) resolveClass(interceptor).newInstance();
interceptorInstance.setProperties(properties);
configuration.addInterceptor(interceptorInstance);
}
}
}在上述代码中,我们看到了 Mybatis 中代表过滤器的 Interceptor 接口。我们根据配置的 interceptor 属性实例化 Interceptor 对象,然后通过 configuration.addInterceptor 方法添加新的 Interceptor 实例。我们跟踪代码,发现 Configuration 中定义了一个如下所示的 InterceptorChain 对象,该方法就是将 Interceptor 实例添加到了 InterceptorChain 中。
protected final InterceptorChain interceptorChain = new InterceptorChain();这样,管道-过滤器模式中代表过滤器(Interceptor)和过滤器链(InterceptorChain)的相关对象都出现了,让我们首先从这些对象的定义和实现入手探究 Mybatis 的内部原理。
在 Mybatis 中,Interceptor 和 InterceptorChain 都位于 org.apache.ibatis.plugin 包中,其中 Interceptor 是个接口,InterceptorChain 是个实体类,它们的代码看上去都不多。让我们先来看一下 InterceptorChain 类,如下所示:
public class InterceptorChain {
private final List<Interceptor> interceptors = new ArrayList<>();
public Object pluginAll(Object target) {
for (Interceptor interceptor : interceptors) {
target = interceptor.plugin(target);
}
return target;
}
public void addInterceptor(Interceptor interceptor) {
interceptors.add(interceptor);
}
public List<Interceptor> getInterceptors() {
return Collections.unmodifiableList(interceptors);
}
}可以看到,这个 InterceptorChain 同样提供了 addInterceptor 方法用于将拦截器添加到链中。不同之处在于,它在这里持有一个 interceptors 数组用于把新加入的 Interceptor 添加到这个数组中。通过这种方式,在 pluginAll 方法中就可以直接遍历 interceptors 数组并基于每个 interceptor 执行拦截逻辑。
在 InterceptorChain 中,我们尚不明确的就是 interceptor.plugin(target) 方法的逻辑,让我们把思路跳转到 Interceptor 接口,该接口定义如下所示:
public interface Interceptor {
Object intercept(Invocation invocation) throws Throwable;
default Object plugin(Object target) {
return Plugin.wrap(target, this);
}
default void setProperties(Properties properties) {
// NOP
}
}可以看到,Interceptor 接口中的 plugin 方法实际上存在一个默认实现,这里它通过 Plugin.wrap 方法完成对目标对象的拦截。Plugin.wrap 是一个静态方法,位于 Plugin 类中,Plugin 类的核心代码如下所示:
public class Plugin implements InvocationHandler {
// 省略变量定义和构造函数
public static Object wrap(Object target, Interceptor interceptor) {
Map<Class<?>, Set<Method>> signatureMap = getSignatureMap(interceptor);
Class<?> type = target.getClass();
Class<?>[] interfaces = getAllInterfaces(type, signatureMap);
if (interfaces.length > 0) {
return Proxy.newProxyInstance(type.getClassLoader(), interfaces, new Plugin(target, interceptor, signatureMap));
}
return target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
Set<Method> methods = signatureMap.get(method.getDeclaringClass());
if (methods != null && methods.contains(method)) {
return interceptor.intercept(new Invocation(target, method, args));
}
return method.invoke(target, args);
} catch (Exception e) {
throw ExceptionUtil.unwrapThrowable(e);
}
}
// 省略 getSignatureMap 方法和 getAllInterfaces 辅助方法
}显然,我们看到了熟悉的 InvocationHandler 接口和 Proxy.newProxyInstance 方法,从而明白原来用到了 JDK 的动态代理机制。
这里我们分别通过 getSignatureMap 和 getAllInterfaces 方法获取接口和方法定义的元数据,并通过动态代理机制产生代理。另一方面,我们实现了 InvocationHandler 接口的 invoke 方法,并判断是否需要对目标方法进行拦截。如果是,则调用 Interceptor.intercept 方法,在该方法中我们就可以加入任何想要加入的业务逻辑;如果不是,则调用 method.invoke 方法执行原来逻辑。
这里有一点要注意,在 Mybatis 中,拦截器只能拦截 ParameterHandler、StatementHandler、ResultSetHandler 和 Executor 这四种类型的接口,这点在 Configuration 类中是通过代码预先定义好的。如果我们想要自定义拦截器,也只能围绕上述四种接口添加逻辑。
解题要点
在回答与管道-过滤器模式相关的面试题是,常见会碰到一些概念类问题,例如“管道-过滤器模式的应用场景有哪些?列举你知道的用到管道过滤器模式的开源框架?”这种,这些问题看上去有点复杂,实际上就是考查你对管道过滤器模式相关基本概念的理解,从考点上讲是比较明确的。我们明确,管道过滤器模式的主要应用场景在于请求-响应型的处理过程,尤其适用于处理 Web 请求。只要具备这一思路,这道题的答案也是自然而然就能得出的。在日常能够接触到的开源框架中,处理 Web 请求的框架基本上都会或多或少采用了管道过滤器模式,包括但不限于我们将要介绍的 Dubbo,以及诸如 Netty、Spring MVC、Tomcat 等常见框架。
另一方面,针对具体的开源框架,面试官的提问方式可以围绕 Mybatis 等框架中的某一个功能特性展开讨论,例如“Mybatis 中的拦截器如何对执行过程进行拦截?”。针对这类问题,我们首先需要明确背后的考点实际上就是代理机制。在主流的开源框架中,涉及到过滤、拦截等常见下的实现原理往往都有代理模式相关。只要掌握动态代理机制,不同的问法都是类似的解答思路。事实上,Mybatis 中实现拦截的基本原理还是基于动态代理机制,通过获取对应方法的签名信息以及输入的接口和参数来生成代理。Mybatis 中的代理机制实现方式就是采用的 JDK 动态代理,你可以结合第 21 讲内容做一些回顾。掌握了该类的实现过程,都可以结合自己的理解对代理机制进行展开。
小结与预告
在本讲中,对于管道-过滤器架构模式,我们详细给出了该模式的基本概念和组成结构。现实中,管道-过滤器在实现上也有很多变种,我们分别基于 Dubbo 和 Mybatis 这两款主流开源框架来分析这一架构模式的具体实现方式和技巧。
管道-过滤器是我们通用技术组件部分的最后一个技术组件。介绍完通用技术组件之后,我们将进入到一个扩展模块,专门讨论剖析开源框架代码结构的系统方法。在下一讲中,我们将讨论“如何基于组件设计原则剖析开源框架代码结构?”这一话题。
// TODO https://juejin.cn/book/7106442254533066787/section/7107604658914328588