消息队列和事件循环:页面是怎么活起来的
前面我们讲到了每个渲染进程都有一个主线程,并且主线程非常繁忙,既要处理 DOM,又要计算样式,还要处理布局,同时还需要处理 JavaScript 任务以及各种输入事件。要让这么多不同类型的任务在主线程中有条不紊地执行,这就需要一个系统来统筹调度这些任务,这个统筹调度系统就是我们今天要讲的消息队列和事件循环系统。
在写这篇文章之前,我翻阅了大量的资料,却发现没有一篇文章能把消息循环系统给讲清楚的,所以我决定用一篇文章来专门介绍页面的事件循环系统。事件循环非常底层且非常重要,学会它能让你理解页面到底是如何运行的,所以在本篇文章中,我们会将页面的事件循环给梳理清楚、讲透彻。
为了能让你更加深刻地理解事件循环机制,我们就从最简单的场景来分析,然后带你一步步了解浏览器页面主线程是如何运作的。
需要说明的是,文章中的代码我会采用 C++ 来示范。如果你不熟悉 C++,也没有关系,这里并没有涉及到任何复杂的知识点,只要你了解 JavaScript 或 Python,你就会看懂
使用单线程处理安排好的任务
我们先从最简单的场景讲起,比如有如下一系列的任务:
- 任务 1:1+2
- 任务 2:20/5
- 任务 3:7*8
- 任务 4:打印出任务 1、任务 2、任务 3 的运算结果
现在要在一个线程中去执行这些任务,通常我们会这样编写代码
void MainThread() {
int num1 = 1+2; // 任务 1
int num2 = 20/5; // 任务 2
int num3 = 7*8; // 任务 3
print(" 最终计算的值为:%d,%d,%d",num, num2, num3); // 任务 4
}在上面的执行代码中,我们把所有任务代码按照顺序写进主线程里,等线程执行时,这些任务会按照顺序在线程中依次被执行;等所有任务执行完成之后,线程会自动退出。可以参考下图来直观地理解下其执行过程:

在线程运行过程中处理新任务
但并不是所有的任务都是在执行之前统一安排好的,大部分情况下,新的任务是在线程运行过程中产生的。比如在线程执行过程中,又接收到了一个新的任务要求计算“10+2”,那上面那种方式就无法处理这种情况了。
要想在线程运行过程中,能接收并执行新的任务,就需要采用事件循环机制。我们可以通过一个 for 循环语句来监听是否有新的任务,如下面的示例代码:
// GetInput
// 等待用户从键盘输入一个数字,并返回该输入的数字
int GetInput() {
int input_number = 0;
cout<<"请输入一个数:";
cin>>input_number;
return input_number;
}
// 主线程(Main Thread)
void MainThread() {
for(;;){
int first_num = GetInput();
int second_num = GetInput();
result_num = first_num + second_num;
print("最终计算的值为:%d",result_num);
}
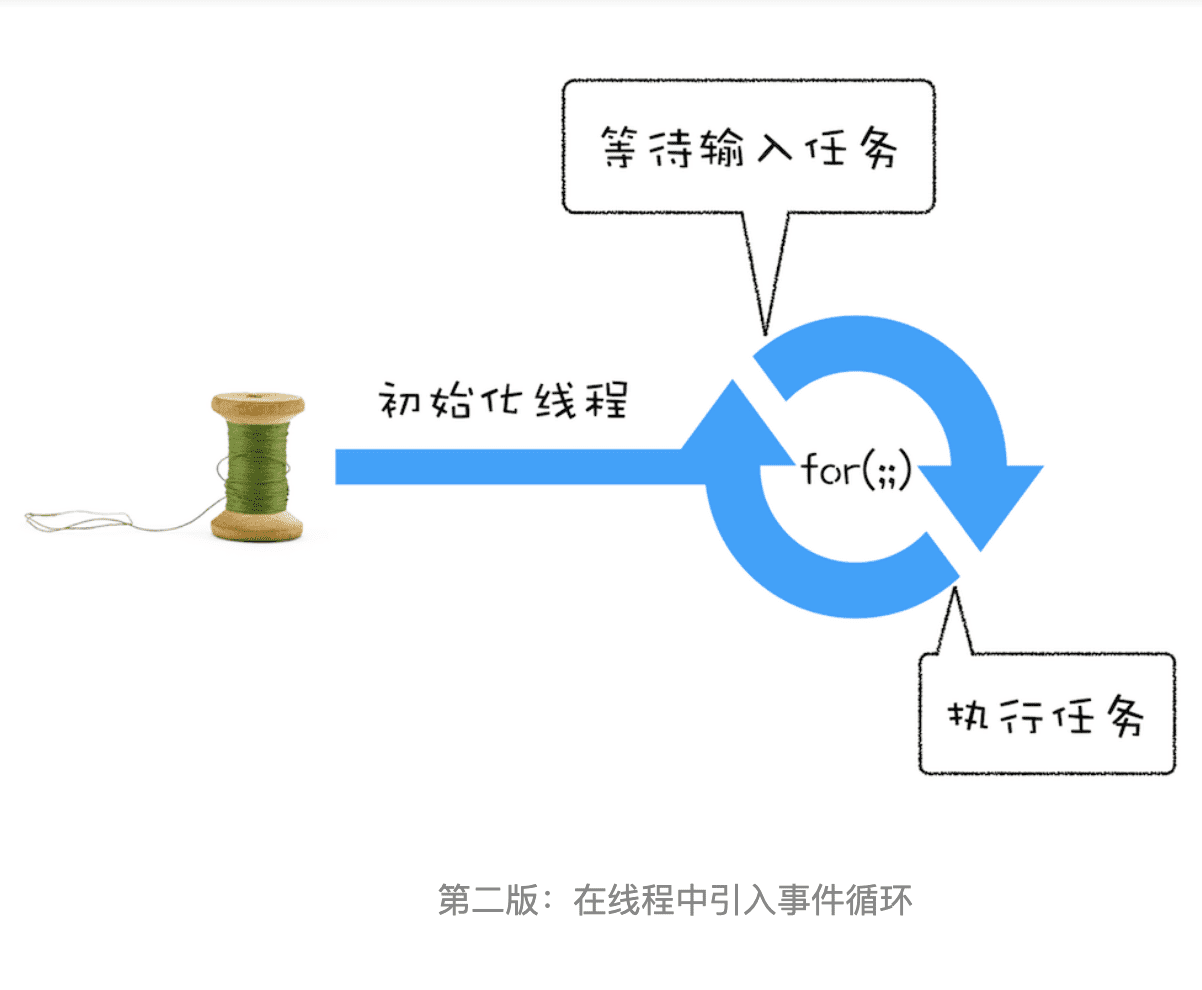
}相较于第一版的线程,这一版的线程做了两点改进。
- 第一点引入了循环机制,具体实现方式是在线程语句最后添加了一个 for 循环语句,线程会一直循环执行。
- 第二点是引入了事件,可以在线程运行过程中,等待用户输入的数字,等待过程中线程处于暂停状态,一旦接收到用户输入的信息,那么线程会被激活,然后执行相加运算,最后输出结果。
通过引入事件循环机制,就可以让该线程“活”起来了,我们每次输入两个数字,都会打印出两数字相加的结果,你可以结合下图来参考下这个改进版的线程:
处理其他线程发送过来的任务
上面我们改进了线程的执行方式,引入了事件循环机制,可以让其在执行过程中接受新的任务。不过在第二版的线程模型中,所有的任务都是来自于线程内部的,如果另外一个线程想让主线程执行一个任务,利用第二版的线程模型是无法做到的。
那下面我们就来看看其他线程是如何发送消息给渲染主线程的,具体形式你可以参考下图:
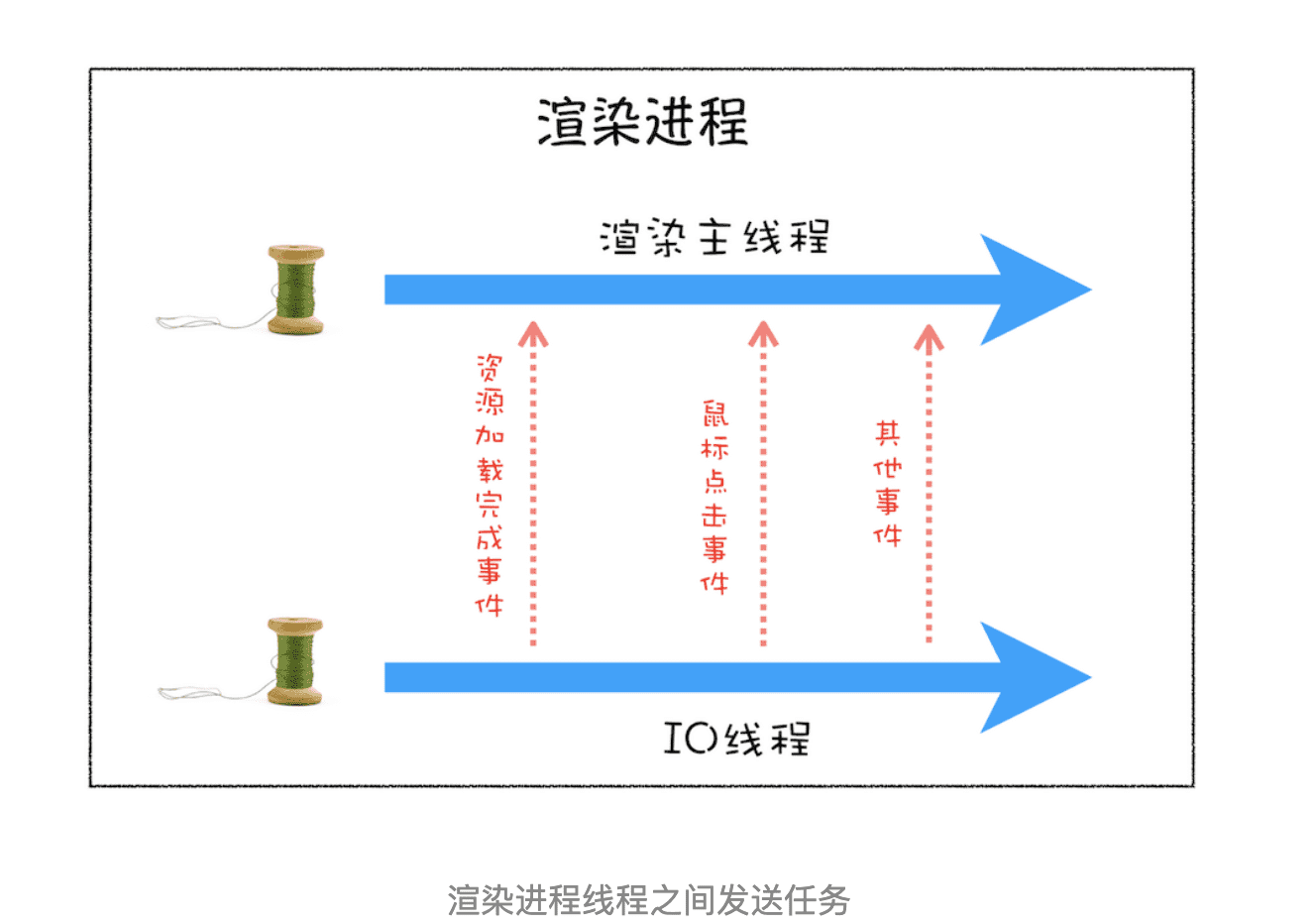
从上图可以看出,渲染主线程会频繁接收到来自于 IO 线程的一些任务,接收到这些任务之后,渲染进程就需要着手处理,比如接收到资源加载完成的消息后,渲染进程就要着手进行 DOM 解析了;接收到鼠标点击的消息后,渲染主线程就要开始执行相应的 JavaScript 脚本来处理该点击事件。
那么如何设计好一个线程模型,能让其能够接收其他线程发送的消息呢?
一个通用模式是使用消息队列。在解释如何实现之前,我们先说说什么是消息队列,可以参考下图:
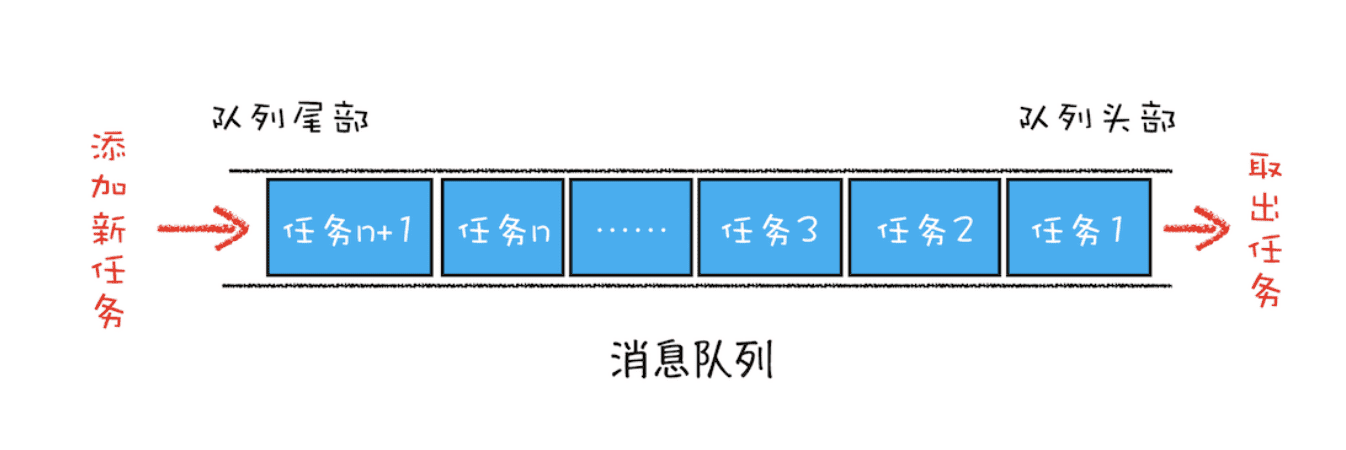
从图中可以看出,消息队列是一种数据结构,可以存放要执行的任务。它符合队列“先进先出”的特点,也就是说要添加任务的话,添加到队列的尾部;要取出任务的话,从队列头部去取。
有了队列之后,我们就可以继续改造线程模型了,改造方案如下图所示:
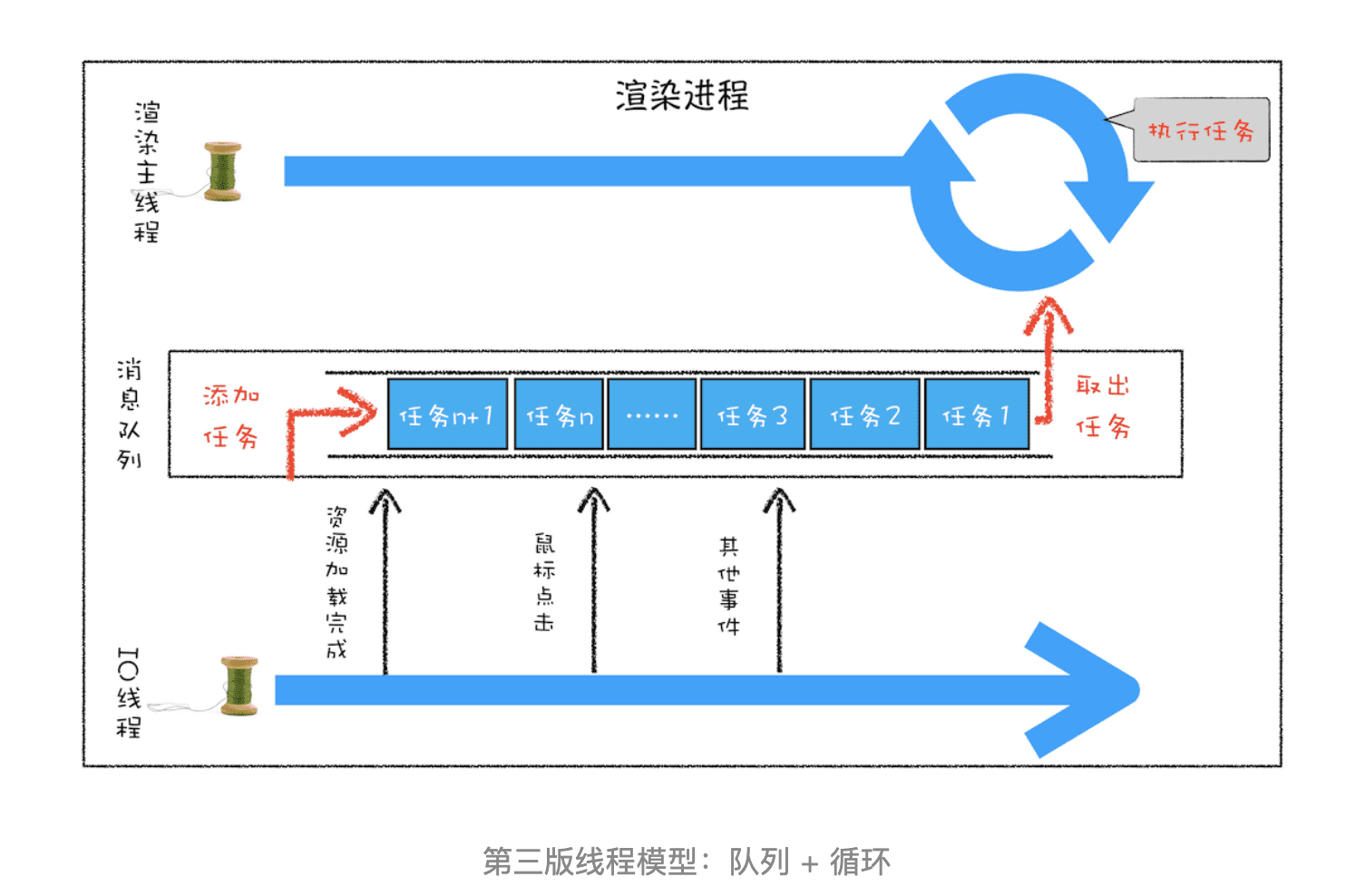
从上图可以看出,我们的改造可以分为下面三个步骤:
- 添加一个消息队列;
- IO 线程中产生的新任务添加进消息队列尾部;
- 渲染主线程会循环地从消息队列头部中读取任务,执行任务。
有了这些步骤之后,那么接下来我们就可以按步骤使用代码来实现第三版的线程模型。
首先,构造一个队列。当然,在本篇文章中我们不需要考虑队列实现的细节,只是构造队列的接口:
class TaskQueue{
public:
Task takeTask(); // 取出队列头部的一个任务
void pushTask(Task task); // 添加一个任务到队列尾部
};接下来,改造主线程,让主线程从队列中读取任务:
TaskQueue task_queue;
void ProcessTask();
void MainThread(){
for(;;){
Task task = task_queue.takeTask();
ProcessTask(task);
}
}在上面的代码中,我们添加了一个消息队列的对象,然后在主线程的 for 循环代码块中,从消息队列中读取一个任务,然后执行该任务,主线程就这样一直循环往下执行,因此只要消息队列中有任务,主线程就会去执行。
主线程的代码就这样改造完成了。这样改造后,主线程执行的任务都全部从消息队列中获取。所以如果有其他线程想要发送任务让主线程去执行,只需要将任务添加到该消息队列中就可以了,添加任务的代码如下:
Task clickTask;
task_queue.pushTask(clickTask)由于是多个线程操作同一个消息队列,所以在添加任务和取出任务时还会加上一个同步锁,这块内容也要注意下。
处理其他进程发送过来的任务
通过使用消息队列,我们实现了线程之间的消息通信。在 Chrome 中,跨进程之间的任务也是频繁发生的,那么如何处理其他进程发送过来的任务?你可以参考下图:
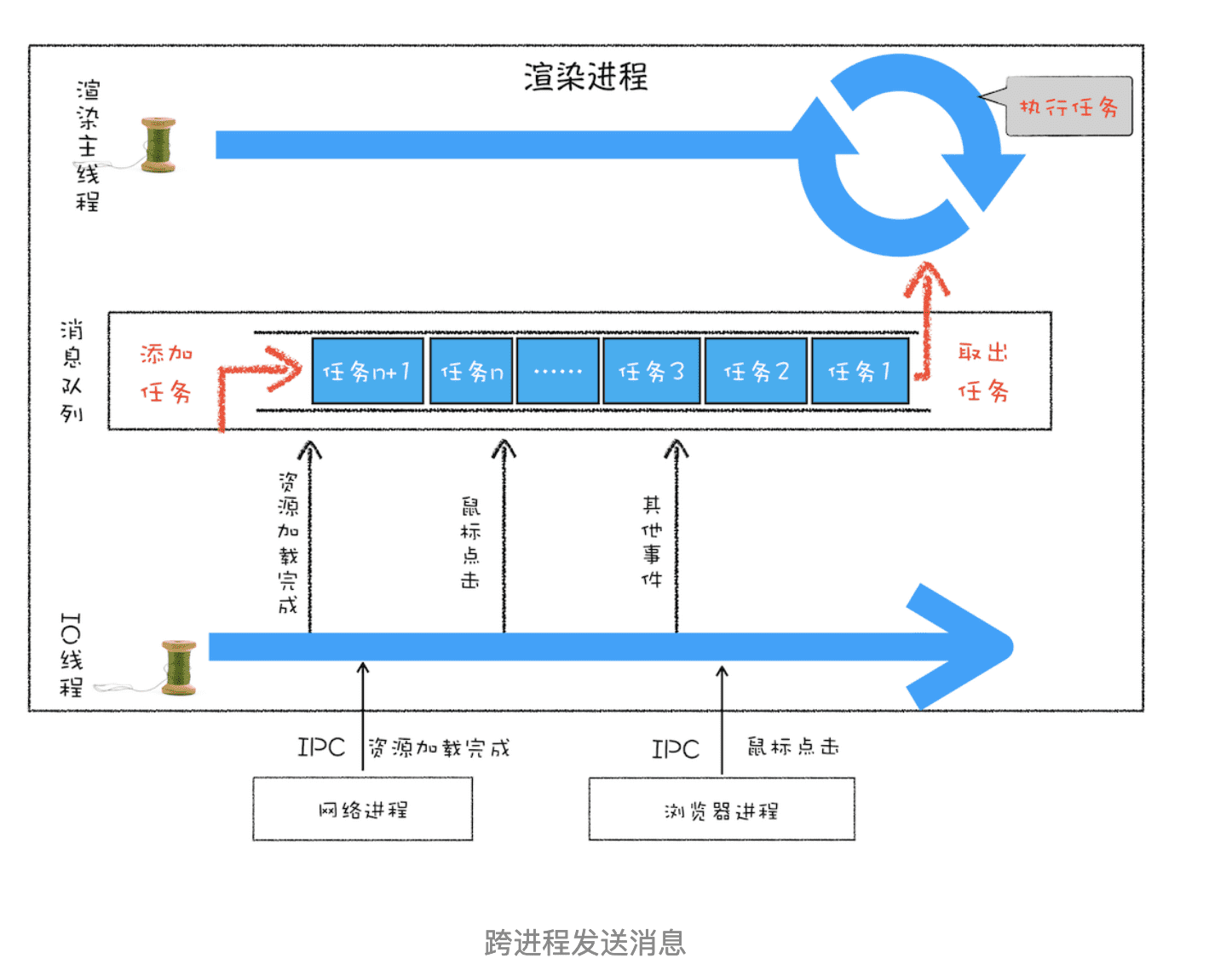
从图中可以看出,渲染进程专门有一个 IO 线程用来接收其他进程传进来的消息,接收到消息之后,会将这些消息组装成任务发送给渲染主线程,后续的步骤就和前面讲解的“处理其他线程发送的任务”一样了,这里就不再重复了。
消息队列中的任务类型
现在你知道页面主线程是如何接收外部任务的了,那接下来我们再来看看消息队列中的任务类型有哪些。你可以参考下 Chromium 的官方源码,这里面包含了很多内部消息类型,如输入事件(鼠标滚动、点击、移动)、微任务、文件读写、WebSocket、JavaScript 定时器等等。
除此之外,消息队列中还包含了很多与页面相关的事件,如 JavaScript 执行、解析 DOM、样式计算、布局计算、CSS 动画等。
以上这些事件都是在主线程中执行的,所以在编写 Web 应用时,你还需要衡量这些事件所占用的时长,并想办法解决单个任务占用主线程过久的问题。
如何安全退出
当页面主线程执行完成之后,又该如何保证页面主线程能够安全退出呢?Chrome 是这样解决的,确定要退出当前页面时,页面主线程会设置一个退出标志的变量,在每次执行完一个任务时,判断是否有设置退出标志。
如果设置了,那么就直接中断当前的所有任务,退出线程,你可以参考下面代码:
TaskQueue task_queue;
void ProcessTask();
bool keep_running = true;
void MainThread() {
for(;;){
Task task = task_queue.takeTask();
ProcessTask(task);
if(!keep_running) // 如果设置了退出标志,那么直接退出线程循环
break;
}
}页面使用单线程的缺点
上面讲述的就是页面线程的循环系统是如何工作的,那接下来,我们继续探讨页面线程的一些特征。
通过上面的介绍,你应该清楚了,页面线程所有执行的任务都来自于消息队列。消息队列是“先进先出”的属性,也就是说放入队列中的任务,需要等待前面的任务被执行完,才会被执行。鉴于这个属性,就有如下两个问题需要解决。
如何处理高优先级的任务
比如一个典型的场景是监控 DOM 节点的变化情况(节点的插入、修改、删除等动态变化),然后根据这些变化来处理相应的业务逻辑。一个通用的设计的是,利用 JavaScript 设计一套监听接口,当变化发生时,渲染引擎同步调用这些接口,这是一个典型的观察者模式。
不过这个模式有个问题,因为 DOM 变化非常频繁,如果每次发生变化的时候,都直接调用相应的 JavaScript 接口,那么这个当前的任务执行时间会被拉长,从而导致执行效率的下降。
如果将这些 DOM 变化做成异步的消息事件,添加到消息队列的尾部,那么又会影响到监控的实时性,因为在添加到消息队列的过程中,可能前面就有很多任务在排队了。
这也就是说,如果 DOM 发生变化,采用同步通知的方式,会影响当前任务的执行效率;如果采用异步方式,又会影响到监控的实时性
那该如何权衡效率和实时性呢?
针对这种情况,微任务就应用而生了,下面我们来看看微任务是如何权衡效率和实时性的。
通常我们把消息队列中的任务称为宏任务,每个宏任务中都包含了一个微任务队列,在执行宏任务的过程中,如果 DOM 有变化,那么就会将该变化添加到微任务列表中,这样就不会影响到宏任务的继续执行,因此也就解决了执行效率的问题。
等宏任务中的主要功能都直接完成之后,这时候,渲染引擎并不着急去执行下一个宏任务,而是执行当前宏任务中的微任务,因为 DOM 变化的事件都保存在这些微任务队列中,这样也就解决了实时性问题。
如何解决单个任务执行时长过久的问题
因为所有的任务都是在单线程中执行的,所以每次只能执行一个任务,而其他任务就都处于等待状态。如果其中一个任务执行时间过久,那么下一个任务就要等待很长时间。可以参考下图:
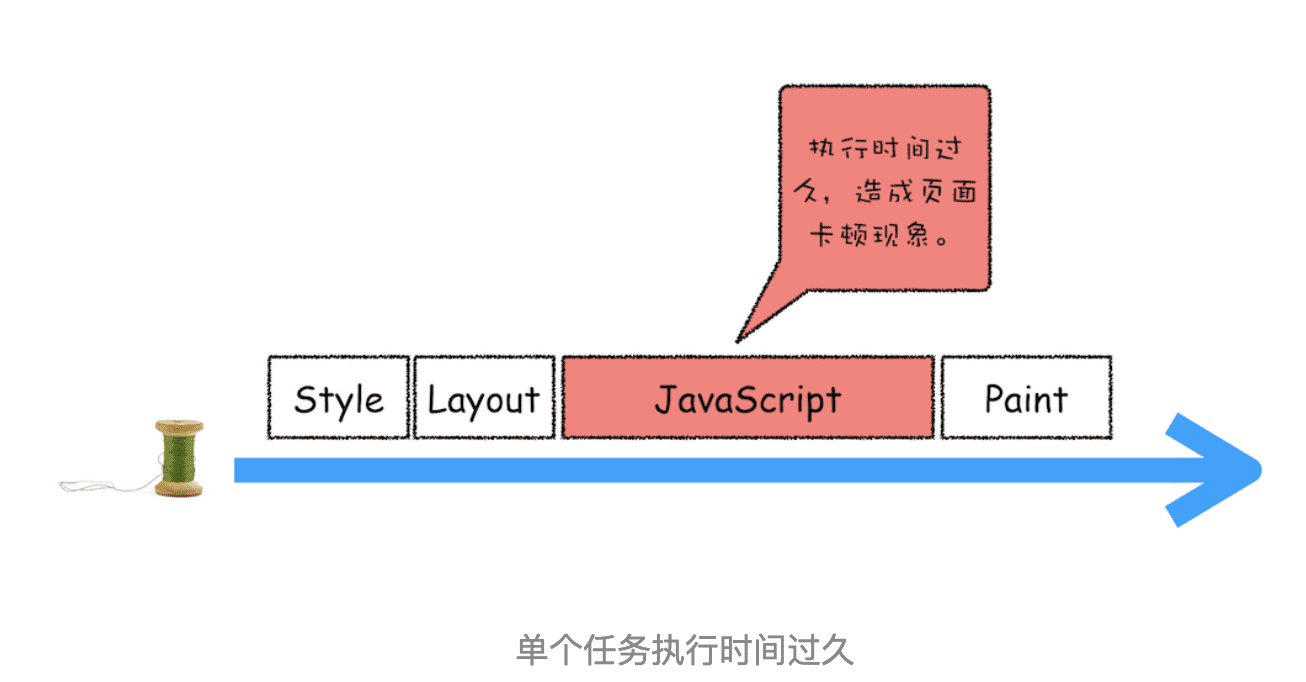
从图中你可以看到,如果在执行动画过程中,其中有个 JavaScript 任务因执行时间过久,占用了动画单帧的时间,这样会给用户制造了卡顿的感觉,这当然是极不好的用户体验。针对这种情况,JavaScript 可以通过回调功能来规避这种问题,也就是让要执行的 JavaScript 任务滞后执行。至于浏览器是如何实现回调功能的,我们在后面的章节中再详细介绍。
实践:浏览器页面是如何运行的
有了上面的基础知识之后,我们最后来看看浏览器的页面是如何运行的。
你可以打开开发者工具,点击“Performance”标签,选择左上角的“start porfiling and load page”来记录整个页面加载过程中的事件执行情况,如下图所示:

从图中可以看出,我们点击展开了 Main 这个项目,其记录了主线程执行过程中的所有任务。图中灰色的就是一个个任务,每个任务下面还有子任务,其中的 Parse HTML 任务,是把 HTML 解析为 DOM 的任务。值得注意的是,在执行 Parse HTML 的时候,如果遇到 JavaScript 脚本,那么会暂停当前的 HTML 解析而去执行 JavaScript 脚本。
至于 Performance 工具,在后面的章节中我们还会详细介绍,在这里你只需要建立一个直观的印象就可以了。
总结
- 如果有一些确定好的任务,可以使用一个单线程来按照顺序处理这些任务,这是第一版线程模型。
- 要在线程执行过程中接收并处理新的任务,就需要引入循环语句和事件系统,这是第二版线程模型。
- 如果要接收其他线程发送过来的任务,就需要引入消息队列,这是第三版线程模型。
- 如果其他进程想要发送任务给页面主线程,那么先通过 IPC 把任务发送给渲染进程的 IO 线程,IO 线程再把任务发送给页面主线程。
- 消息队列机制并不是太灵活,为了适应效率和实时性,引入了微任务
基于消息队列的设计是目前使用最广的消息架构,无论是安卓还是 Chrome 都采用了类似的任务机制,所以理解了本篇文章的内容后,你再理解其他项目的任务机制也会比较轻松。
Webapi:setTimeout 是怎么实现的
本篇文章主要介绍的是 setTimeout。其实说起 setTimeout 方法,从事开发的同学想必都不会陌生,它就是一个定时器,用来指定某个函数在多少毫秒之后执行。它会返回一个整数,表示定时器的编号,同时你还可以通过该编号来取消这个定时器。下面的示例代码就演示了定时器最基础的使用方式:
function showName() {
console.log('极客时间');
}
var timerID = setTimeout(showName, 200);执行上述代码,输出的结果也很明显,通过 setTimeout 指定在 200 毫秒之后调用 showName 函数,并输出“极客时间”四个字。
简单了解了 setTimeout 的使用方法后,那接下来我们就来看看浏览器是如何实现定时器的,然后再介绍下定时器在使用过程中的一些注意事项
浏览器怎么实现 setTimeout
要了解定时器的工作原理,就得先来回顾下之前讲的事件循环系统,我们知道渲染进程中所有运行在主线程上的任务都需要先添加到消息队列,然后事件循环系统再按照顺序执行消息队列中的任务。下面我们来看看那些典型的事件
- 当接收到 HTML 文档数据,渲染引擎就会将“解析 DOM”事件添加到消息队列中,
- 当用户改变了 Web 页面的窗口大小,渲染引擎就会将“重新布局”的事件添加到消息队列中。
- 当触发了 JavaScript 引擎垃圾回收机制,渲染引擎会将“垃圾回收”任务添加到消息队列中。
- 同样,如果要执行一段异步 JavaScript 代码,也是需要将执行任务添加到消息队列中
以上列举的只是一小部分事件,这些事件被添加到消息队列之后,事件循环系统就会按照消息队列中的顺序来执行事件。
所以说要执行一段异步任务,需要先将任务添加到消息队列中。不过通过定时器设置回调函数有点特别,它们需要在指定的时间间隔内被调用,但消息队列中的任务是按照顺序执行的,所以为了保证回调函数能在指定时间内执行,你不能将定时器的回调函数直接添加到消息队列中。
那么该怎么设计才能让定时器设置的回调事件在规定时间内被执行呢?你也可以思考下,如果让你在消息循环系统的基础之上加上定时器的功能,你会如何设计?
在 Chrome 中除了正常使用的消息队列之外,还有另外一个消息队列,这个队列中维护了需要延迟执行的任务列表,包括了定时器和 Chromium 内部一些需要延迟执行的任务。所以当通过 JavaScript 创建一个定时器时,渲染进程会将该定时器的回调任务添加到延迟队列中
源码中延迟执行队列的定义如下所示:
DelayedIncomingQueue delayed_incoming_queue;当通过 JavaScript 调用 setTimeout 设置回调函数的时候,渲染进程将会创建一个回调任务,包含了回调函数 showName、当前发起时间、延迟执行时间,其模拟代码如下所示:
struct DelayTask{
int64 id;
CallBackFunction cbf;
int start_time;
int delay_time;
};
DelayTask timerTask;
timerTask.cbf = showName;
timerTask.start_time = getCurrentTime(); // 获取当前时间
timerTask.delay_time = 200; // 设置延迟执行时间创建好回调任务之后,再将该任务添加到延迟执行队列中,代码如下所示:
delayed_incoming_queue.push(timerTask);现在通过定时器发起的任务就被保存到延迟队列中了,那接下来我们再来看看消息循环系统是怎么触发延迟队列的。
我们可以来完善上一篇文章中消息循环的代码,在其中加入执行延迟队列的代码,如下所示
void ProcessTimerTask(){
// 从 delayed_incoming_queue 中取出已经到期的定时器任务
// 依次执行这些任务
}
TaskQueue task_queue;
void ProcessTask();
bool keep_running = true;
void MainTherad(){
for(;;){
// 执行消息队列中的任务
Task task = task_queue.takeTask();
ProcessTask(task);
// 执行延迟队列中的任务
ProcessDelayTask()
if(!keep_running) // 如果设置了退出标志,那么直接退出线程循环
break;
}
}从上面代码可以看出来,我们添加了一个 ProcessDelayTask 函数,该函数是专门用来处理延迟执行任务的。这里我们要重点关注它的执行时机,在上段代码中,处理完消息队列中的一个任务之后,就开始执行 ProcessDelayTask 函数。ProcessDelayTask 函数会根据发起时间和延迟时间计算出到期的任务,然后依次执行这些到期的任务。等到期的任务执行完成之后,再继续下一个循环过程。通过这样的方式,一个完整的定时器就实现了。
设置一个定时器,JavaScript 引擎会返回一个定时器的 ID。那通常情况下,当一个定时器的任务还没有被执行的时候,也是可以取消的,具体方法是调用 clearTimeout 函数,并传入需要取消的定时器的 ID。如下面代码所示:
clearTimeout(timer_id)其实浏览器内部实现取消定时器的操作也是非常简单的,就是直接从 delayed_incoming_queue 延迟队列中,通过 ID 查找到对应的任务,然后再将其从队列中删除掉就可以了。
使用 setTimeout 的一些注意事项
现在你应该知道在浏览器内部定时器是如何工作的了。不过在使用定时器的过程中,如果你不了解定时器的一些细节,那么很有可能掉进定时器的一些陷阱里。所以接下来,我们就来讲解一下在使用定时器过程中存在的那些陷阱。
如果当前任务执行时间过久,会影延迟到期定时器任务的执行
在使用 setTimeout 的时候,有很多因素会导致回调函数执行比设定的预期值要久,其中一个就是当前任务执行时间过久从而导致定时器设置的任务被延后执行。我们先看下面这段代码:
function bar() {
console.log('bar');
}
function foo() {
setTimeout(bar, 0);
for (let i = 0; i < 5000; i++) {
let i = 5 + 8 + 8 + 8;
console.log(i);
}
}
foo();这段代码中,在执行 foo 函数的时候使用 setTimeout 设置了一个 0 延时的回调任务,设置好回调任务后,foo 函数会继续执行 5000 次 for 循环。
通过 setTimeout 设置的回调任务被放入了消息队列中并且等待下一次执行,这里并不是立即执行的;要执行消息队列中的下个任务,需要等待当前的任务执行完成,由于当前这段代码要执行 5000 次的 for 循环,所以当前这个任务的执行时间会比较久一点。这势必会影响到下个任务的执行时间。
你也可以打开 Performance 来看看其执行过程,如下图所示:
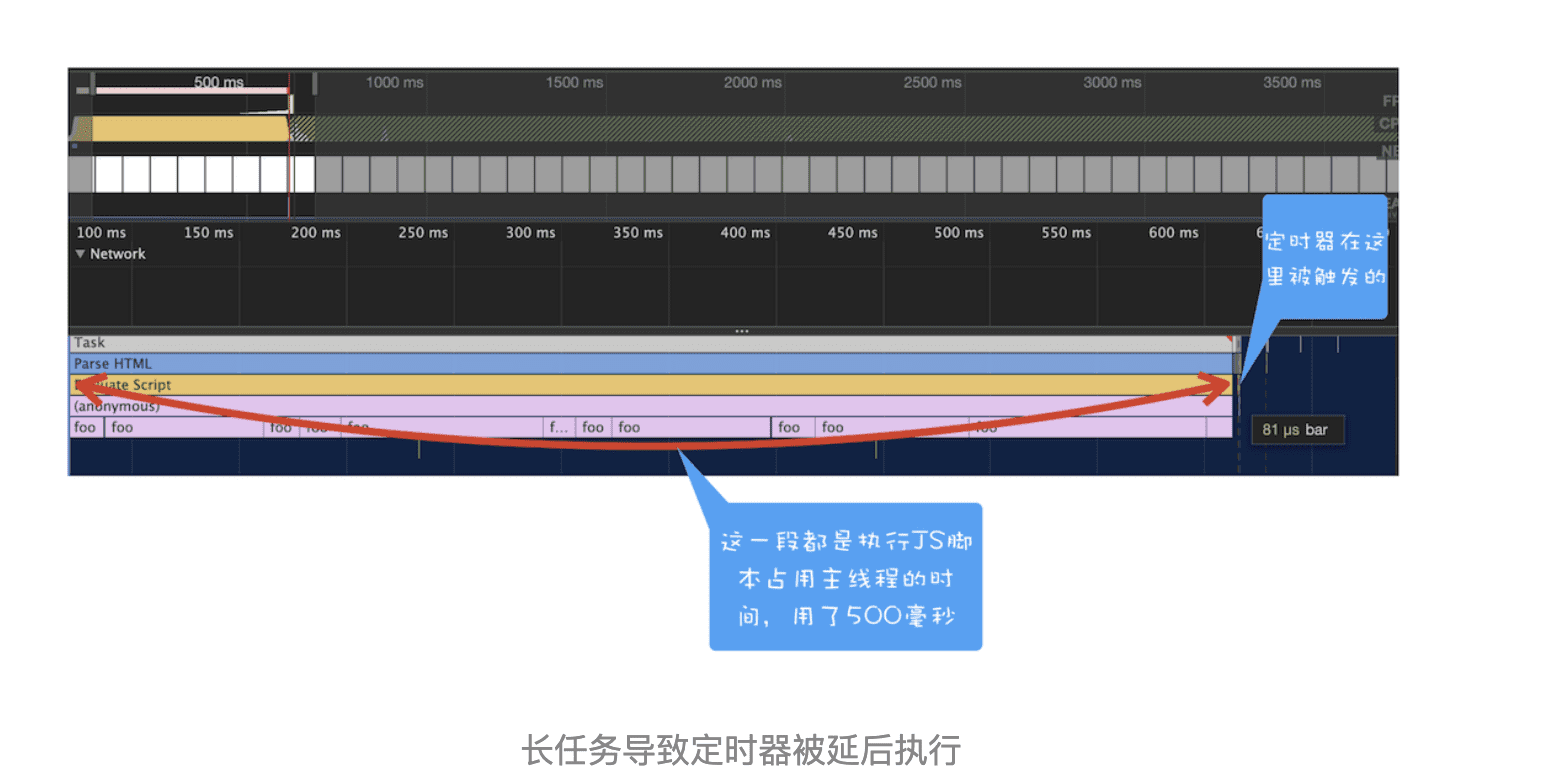
从图中可以看到,执行 foo 函数所消耗的时长是 500 毫秒,这也就意味着通过 setTimeout 设置的任务会被推迟到 500 毫秒以后再去执行,而设置 setTimeout 的回调延迟时间是 0。
如果 setTimeout 存在嵌套调用,那么系统会设置最短时间间隔为 4 毫秒
也就是说在定时器函数里面嵌套调用定时器,也会延长定时器的执行时间,可以先看下面的这段代码:
function cb() {
setTimeout(cb, 0);
}
setTimeout(cb, 0);上述这段代码你有没有看出存在什么问题?
你还是可以通过 Performance 来记录下这段代码的执行过程,如下图所示
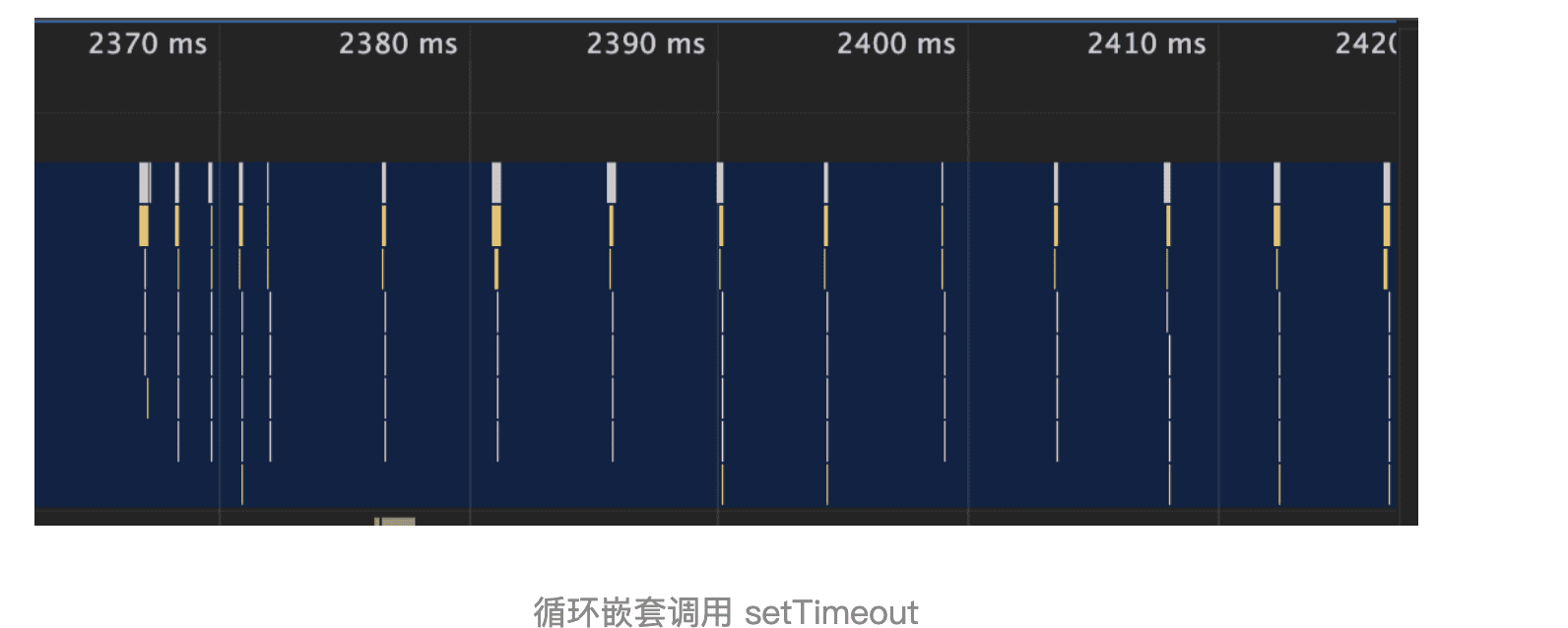
上图中的竖线就是定时器的函数回调过程,从图中可以看出,前面五次调用的时间间隔比较小,嵌套调用超过五次以上,后面每次的调用最小时间间隔是 4 毫秒。之所以出现这样的情况,是因为在 Chrome 中,定时器被嵌套调用 5 次以上,系统会判断该函数方法被阻塞了,如果定时器的调用时间间隔小于 4 毫秒,那么浏览器会将每次调用的时间间隔设置为 4 毫秒。下面是 Chromium 实现 4 毫秒延迟的代码,你可以看下:
static const int kMaxTimerNestingLevel = 5;
// Chromium uses a minimum timer interval of 4ms. We'd like to go
// lower; however, there are poorly coded websites out there which do
// create CPU-spinning loops. Using 4ms prevents the CPU from
// spinning too busily and provides a balance between CPU spinning and
// the smallest possible interval timer.
static constexpr base::TimeDelta kMinimumInterval = base::TimeDelta::FromMilliseconds(4);base::TimeDelta interval_milliseconds =
std::max(base::TimeDelta::FromMilliseconds(1), interval);
if (interval_milliseconds < kMinimumInterval &&
nesting_level_ >= kMaxTimerNestingLevel)
interval_milliseconds = kMinimumInterval;
if (single_shot)
StartOneShot(interval_milliseconds, FROM_HERE);
else
StartRepeating(interval_milliseconds, FROM_HERE);所以,一些实时性较高的需求就不太适合使用 setTimeout 了,比如你用 setTimeout 来实现 JavaScript 动画就不是一个很好的主意。
未激活的页面,setTimeout 执行最小间隔是 1000 毫秒
除了前面的 4 毫秒延迟,还有一个很容易被忽略的地方,那就是未被激活的页面中定时器最小值大于 1000 毫秒,也就是说,如果标签不是当前的激活标签,那么定时器最小的时间间隔是 1000 毫秒,目的是为了优化后台页面的加载损耗以及降低耗电量。这一点你在使用定时器的时候要注意。
延时执行时间有最大值
除了要了解定时器的回调函数时间比实际设定值要延后之外,还有一点需要注意下,那就是 Chrome、Safari、Firefox 都是以 32 个 bit 来存储延时值的,32bit 最大只能存放的数字是 2147483647 毫秒,这就意味着,如果 setTimeout 设置的延迟值大于 2147483647 毫秒(大约 24.8 天)时就会溢出,这导致定时器会被立即执行。你可以运行下面这段代码:
function showName() {
console.log('极客时间');
}
var timerID = setTimeout(showName, 2147483648); // 会被理解调用执行运行后可以看到,这段代码是立即被执行的。但如果将延时值修改为小于 2147483647 毫秒的某个值,那么执行时就没有问题了。
使用 setTimeout 设置的回调函数中的 this 不符合直觉
如果被 setTimeout 推迟执行的回调函数是某个对象的方法,那么该方法中的 this 关键字将指向全局环境,而不是定义时所在的那个对象。这点在前面介绍 this 的时候也提过,你可以看下面这段代码的执行结果:
var name = 1;
var MyObj = {
name: 2,
showName: function() {
console.log(this.name);
}
};
setTimeout(MyObj.showName, 1000);这里输出的是 1,因为这段代码在编译的时候,执行上下文中的 this 会被设置为全局 window,如果是严格模式,会被设置为 undefined。
那么该怎么解决这个问题呢?通常可以使用下面这两种方法。
第一种是将 MyObj.showName 放在匿名函数中执行,如下所示:
// 箭头函数
setTimeout(() => {
MyObj.showName();
}, 1000);
// 或者 function 函数
setTimeout(function() {
MyObj.showName();
}, 1000);第二种是使用 bind 方法,将 showName 绑定在 MyObj 上面,代码如下所示:
setTimeout(MyObj.showName.bind(MyObj), 1000);总结
- 首先,为了支持定时器的实现,浏览器增加了延时队列。
- 其次,由于消息队列排队和一些系统级别的限制,通过 setTimeout 设置的回调任务并非总是可以实时地被执行,这样就不能满足一些实时性要求较高的需求了。
- 最后,在定时器中使用过程中,还存在一些陷阱,需要你多加注意。
通过分析和讲解,你会发现函数 setTimeout 在时效性上面有很多先天的不足,所以对于一些时间精度要求比较高的需求,应该有针对性地采取一些其他的方案
Webapi:XMLHttpRequest 是怎么实现的
自从网页中引入了 JavaScript,我们就可以操作 DOM 树中任意一个节点,例如隐藏/显示节点、改变颜色、获得或改变文本内容、为元素添加事件响应函数等等,几乎可以“为所欲为”了。
不过在 XMLHttpRequest 出现之前,如果服务器数据有更新,依然需要重新刷新整个页面。而 XMLHttpRequest 提供了从 Web 服务器获取数据的能力,如果你想要更新某条数据,只需要通过 XMLHttpRequest 请求服务器提供的接口,就可以获取到服务器的数据,然后再操作 DOM 来更新页面内容,整个过程只需要更新网页的一部分就可以了,而不用像之前那样还得刷新整个页面,这样既有效率又不会打扰到用户。
关于 XMLHttpRequest,本来我是想一带而过的,后来发现这个 WebAPI 用于教学非常好。首先前面讲了那么网络内容,现在可以通过它把 HTTP 协议实践一遍;其次,XMLHttpRequest 是一个非常典型的 WebAPI,通过它来讲解浏览器是如何实现 WebAPI 的很合适,这对于你理解其他 WebAPI 也有非常大的帮助,同时在这个过程中我们还可以把一些安全问题给串起来。
但在深入讲解 XMLHttpRequest 之前,我们得先介绍下同步回调和异步回调这两个概念,这会帮助你更加深刻地理解 WebAPI 是怎么工作的
回调函数 VS 系统调用栈
那什么是回调函数呢(Callback Function)?
将一个函数作为参数传递给另外一个函数,那作为参数的这个函数就是回调函数。简化的代码如下所示:
let callback = function() {
console.log('i am do homework');
};
function doWork(cb) {
console.log('start do work');
cb();
console.log('end do work');
}
doWork(callback);在上面示例代码中,我们将一个匿名函数赋值给变量 callback,同时将 callback 作为参数传递给了 doWork() 函数,这时在函数 doWork() 中 callback 就是回调函数。
上面的回调方法有个特点,就是回调函数 callback 是在主函数 doWork 返回之前执行的,我们把这个回调过程称为同步回调。
既然有同步回调,那肯定也有异步回调。下面我们再来看看异步回调的例子:
let callback = function() {
console.log('i am do homework');
};
function doWork(cb) {
console.log('start do work');
setTimeout(cb, 1000);
console.log('end do work');
}
doWork(callback);在这个例子中,我们使用了 setTimeout 函数让 callback 在 doWork 函数执行结束后,又延时了 1 秒再执行,这次 callback 并没有在主函数 doWork 内部被调用,我们把这种回调函数在主函数外部执行的过程称为异步回调。
现在你应该知道什么是同步回调和异步回调了,那下面我们再深入点,站在消息循环的视角来看看同步回调和异步回调的区别。理解了这些,可以让你从本质上理解什么是回调。
你应该已经知道浏览器页面是通过事件循环机制来驱动的,每个渲染进程都有一个消息队列,页面主线程按照顺序来执行消息队列中的事件,如执行 JavaScript 事件、解析 DOM 事件、计算布局事件、用户输入事件等等,如果页面有新的事件产生,那新的事件将会追加到事件队列的尾部。所以可以说是消息队列和主线程循环机制保证了页面有条不紊地运行。
这里还需要补充一点,那就是当循环系统在执行一个任务的时候,都要为这个任务维护一个系统调用栈。这个系统调用栈类似于 JavaScript 的调用栈,只不过系统调用栈是 Chromium 的开发语言 C++ 来维护的,其完整的调用栈信息你可以通过 chrome://tracing/ 来抓取。当然,你也可以通过 Performance 来抓取它核心的调用信息,如下图所示:
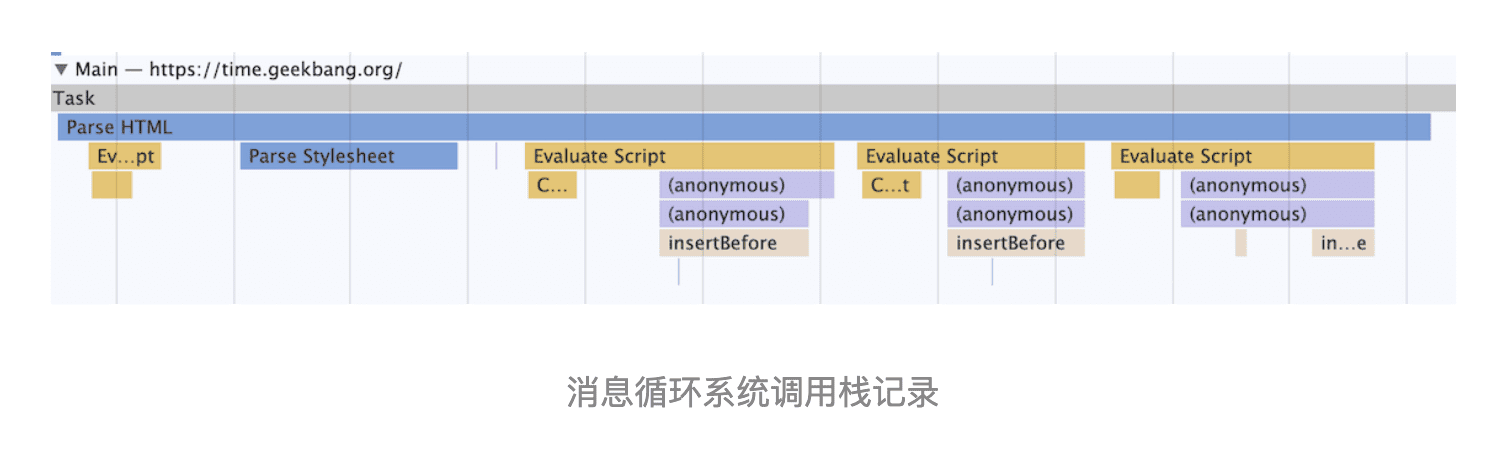
这幅图记录了一个 Parse HTML 的任务执行过程,其中黄色的条目表示执行 JavaScript 的过程,其他颜色的条目表示浏览器内部系统的执行过程。
通过该图你可以看出来,Parse HTML 任务在执行过程中会遇到一系列的子过程,比如在解析页面的过程中遇到了 JavaScript 脚本,那么就暂停解析过程去执行该脚本,等执行完成之后,再恢复解析过程。然后又遇到了样式表,这时候又开始解析样式表……直到整个任务执行完成。
需要说明的是,整个 Parse HTML 是一个完整的任务,在执行过程中的脚本解析、样式表解析都是该任务的子过程,其下拉的长条就是执行过程中调用栈的信息。
每个任务在执行过程中都有自己的调用栈,那么同步回调就是在当前主函数的上下文中执行回调函数,这个没有太多可讲的。下面我们主要来看看异步回调过程,异步回调是指回调函数在主函数之外执行,一般有两种方式
- 第一种是把异步函数做成一个任务,添加到消息队列尾部;
- 第二种是把异步函数添加到微任务队列中,这样就可以在当前任务的末尾处执行微任务了
XMLHttpRequest 运作机制
理解了什么是同步回调和异步回调,接下来我们就来分析 XMLHttpRequest 背后的实现机制,具体工作过程你可以参考下图:
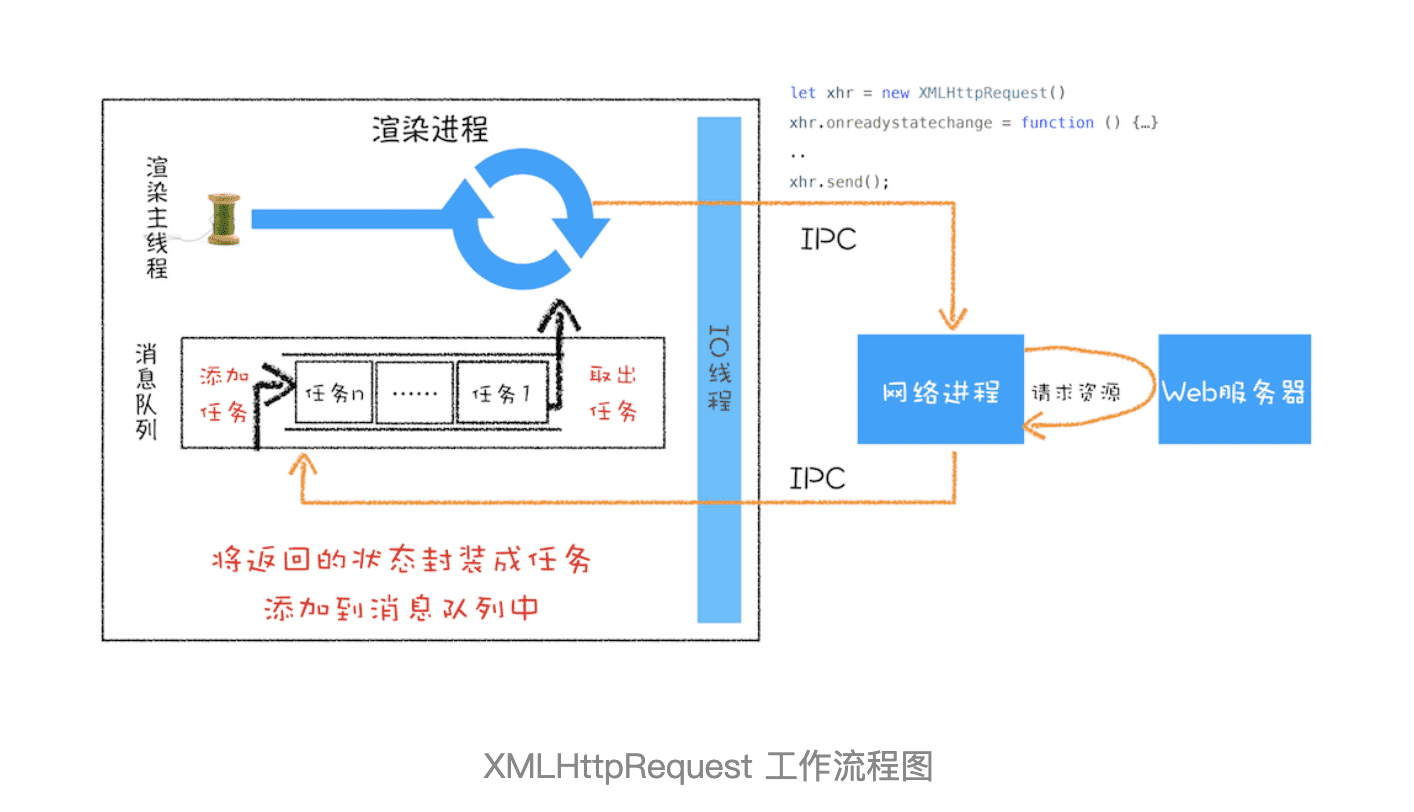
这是 XMLHttpRequest 的总执行流程图,下面我们就来分析从发起请求到接收数据的完整流程。
我们先从 XMLHttpRequest 的用法开始,首先看下面这样一段请求代码:
function GetWebData(URL) {
/**
* 1: 新建 XMLHttpRequest 请求对象
*/
let xhr = new XMLHttpRequest();
/**
* 2: 注册相关事件回调处理函数
*/
xhr.onreadystatechange = function() {
switch (xhr.readyState) {
case 0: // 请求未初始化
console.log('请求未初始化');
break;
case 1: // OPENED
console.log('OPENED');
break;
case 2: // HEADERS_RECEIVED
console.log('HEADERS_RECEIVED');
break;
case 3: // LOADING
console.log('LOADING');
break;
case 4: // DONE
if (this.status == 200 || this.status == 304) {
console.log(this.responseText);
}
console.log('DONE');
break;
}
};
xhr.ontimeout = function(e) {
console.log('ontimeout');
};
xhr.onerror = function(e) {
console.log('onerror');
};
/**
* 3: 打开请求
*/
xhr.open('Get', URL, true); // 创建一个 Get 请求, 采用异步
/**
* 4: 配置参数
*/
xhr.timeout = 3000; // 设置 xhr 请求的超时时间
xhr.responseType = 'text'; // 设置响应返回的数据格式
xhr.setRequestHeader('X_TEST', 'time.geekbang');
/**
* 5: 发送请求
*/
xhr.send();
}上面是一段利用了 XMLHttpRequest 来请求数据的代码,再结合上面的流程图,我们可以分析下这段代码是怎么执行的
创建 XMLHttpRequest 对象
当执行到 let xhr = new XMLHttpRequest() 后,JavaScript 会创建一个 XMLHttpRequest 对象 xhr,用来执行实际的网络请求操作。
为 xhr 对象注册回调函数
因为网络请求比较耗时,所以要注册回调函数,这样后台任务执行完成之后就会通过调用回调函数来告诉其执行结果。
XMLHttpRequest 的回调函数主要有下面几种:
- ontimeout,用来监控超时请求,如果后台请求超时了,该函数会被调用;
- onerror,用来监控出错信息,如果后台请求出错了,该函数会被调用;
- onreadystatechange,用来监控后台请求过程中的状态,比如可以监控到 HTTP 头加载完成的消息、HTTP 响应体消息以及数据加载完成的消息等。
配置基础的请求信息
注册好回调事件之后,接下来就需要配置基础的请求信息了,首先要通过 open 接口配置一些基础的请求信息,包括请求的地址、请求方法(是 get 还是 post)和请求方式(同步还是异步请求)。
然后通过 xhr 内部属性类配置一些其他可选的请求信息,你可以参考文中示例代码,我们通过 xhr.timeout = 3000 来配置超时时间,也就是说如果请求超过 3000 毫秒还没有响应,那么这次请求就被判断为失败了。
我们还可以通过 xhr.responseType = “text” 来配置服务器返回的格式,将服务器返回的数据自动转换为自己想要的格式,如果将 responseType 的值设置为 json,那么系统会自动将服务器返回的数据转换为 JavaScript 对象格式。下面的图表是我列出的一些返回类型的描述:

假如你还需要添加自己专用的请求头属性,可以通过 xhr.setRequestHeader 来添加。
发起请求
一切准备就绪之后,就可以调用 xhr.send 来发起网络请求了。你可以对照上面那张请求流程图,可以看到:渲染进程会将请求发送给网络进程,然后网络进程负责资源的下载,等网络进程接收到数据之后,就会利用 IPC 来通知渲染进程;渲染进程接收到消息之后,会将 xhr 的回调函数封装成任务并添加到消息队列中,等主线程循环系统执行到该任务的时候,就会根据相关的状态来调用对应的回调函数
- 如果网络请求出错了,就会执行 xhr.onerror;
- 如果超时了,就会执行 xhr.ontimeout;
- 如果是正常的数据接收,就会执行 onreadystatechange 来反馈相应的状态。
这就是一个完整的 XMLHttpRequest 请求流程,如果你感兴趣,可以参考下 Chromium 对 XMLHttpRequest 的实现。
XMLHttpRequest 使用过程中的“坑”
上述过程看似简单,但由于浏览器很多安全策略的限制,所以会导致你在使用过程中踩到非常多的“坑”。
浏览器安全问题是前端工程师避不开的一道坎,通常在使用过程中遇到的“坑”,很大一部分都是由安全策略引起的,不管你喜不喜欢,它都在这里。本来很完美的一个方案,正是由于加了安全限制,导致使用起来非常麻烦。
而你要做的就是去正视这各种的安全问题。也就是说要想更加完美地使用 XMLHttpRequest,你就要了解浏览器的安全策略。
下面我们就来看看在使用 XMLHttpRequest 的过程中所遇到的跨域问题和混合内容问题。
跨域问题
比如在极客邦的官网使用 XMLHttpRequest 请求极客时间的页面内容,由于极客邦的官网是 www.geekbang.org,极客时间的官网是 time.geekbang.org,它们不是同一个源,所以就涉及到了跨域(在 A 站点中去访问不同源的 B 站点的内容)。默认情况下,跨域请求是不被允许的,你可以看下面的示例代码:
var xhr = new XMLHttpRequest();
var url = 'https://time.geekbang.org/';
function handler() {
switch (xhr.readyState) {
case 0: // 请求未初始化
console.log(' 请求未初始化 ');
break;
case 1: // OPENED
console.log('OPENED');
break;
case 2: // HEADERS_RECEIVED
console.log('HEADERS_RECEIVED');
break;
case 3: // LOADING
console.log('LOADING');
break;
case 4: // DONE
if (this.status == 200 || this.status == 304) {
console.log(this.responseText);
}
console.log('DONE');
break;
}
}
function callOtherDomain() {
if (xhr) {
xhr.open('GET', url, true);
xhr.onreadystatechange = handler;
xhr.send();
}
}
callOtherDomain();你可以在控制台测试下。首先通过浏览器打开 www.geekbang.org,然后打开控制台,在控制台输入以上示例代码,再执行,会看到请求被 Block 了。控制台的提示信息如下:
Access to XMLHttpRequest at 'https://time.geekbang.org/' from origin 'https://www.geekbang.org' has been blocked by CORS policy: No 'Access-Control-Allow-Origin' header is present on the requested resource.因为 www.geekbang.org 和 time.geekbang.com 不属于一个域,所以以上访问就属于跨域访问了,这次访问失败就是由于跨域问题导致的。
HTTPS 混合内容的问题
了解完跨域问题后,我们再来看看 HTTPS 的混合内容。HTTPS 混合内容是 HTTPS 页面中包含了不符合 HTTPS 安全要求的内容,比如包含了 HTTP 资源,通过 HTTP 加载的图像、视频、样式表、脚本等,都属于混合内容。
通常,如果 HTTPS 请求页面中使用混合内容,浏览器会针对 HTTPS 混合内容显示警告,用来向用户表明此 HTTPS 页面包含不安全的资源。比如打开站点 https://www.iteye.com/groups ,可以通过控制台看到混合内容的警告,参考下图:
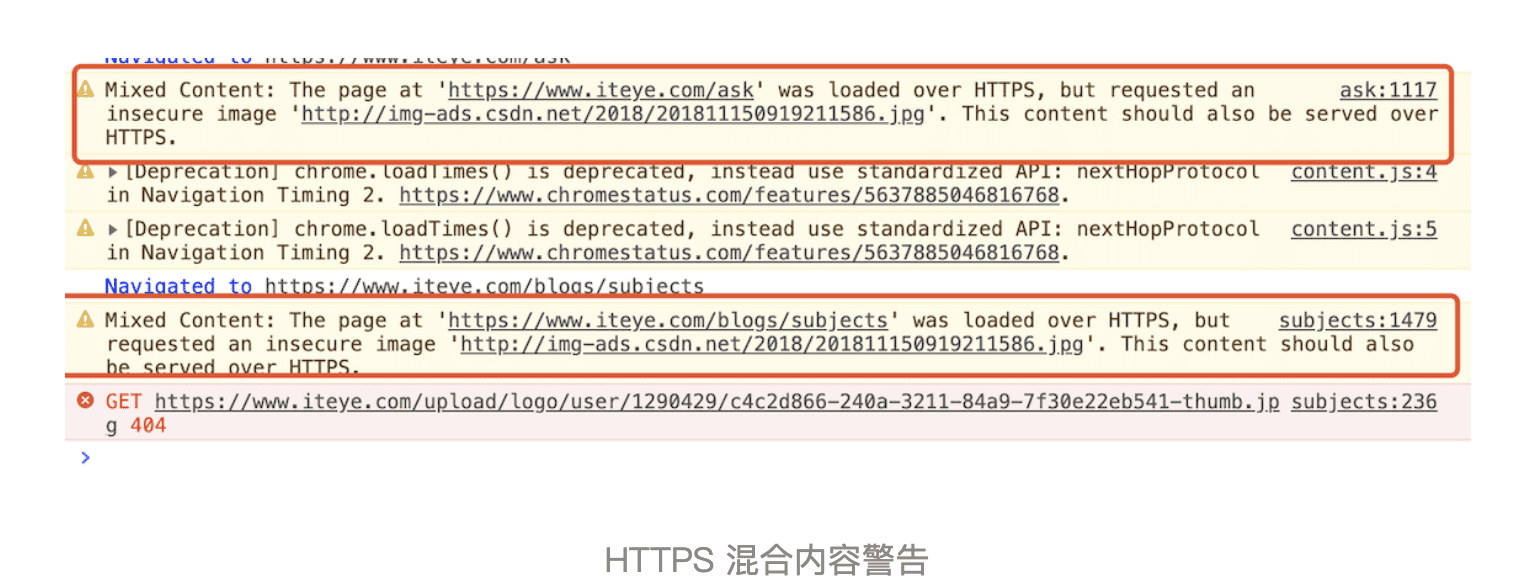
从上图可以看出,通过 HTML 文件加载的混合资源,虽然给出警告,但大部分类型还是能加载的。而使用 XMLHttpRequest 请求时,浏览器认为这种请求可能是攻击者发起的,会阻止此类危险的请求。比如我通过浏览器打开地址 https://www.iteye.com/groups,然后通过控制台,使用 XMLHttpRequest 来请求 http://img-ads.csdn.net/2018/201811150919211586.jpg,这时候请求就会报错,出错信息如下图所示:

总结
首先我们介绍了回调函数和系统调用栈;接下来我们站在循环系统的视角,分析了 XMLHttpRequest 是怎么工作的;最后又说明了由于一些安全因素的限制,在使用 XMLHttpRequest 的过程中会遇到跨域问题和混合内容的问题。
本篇文章跨度比较大,不是单纯地讲一个问题,而是将回调类型、循环系统、网络请求和安全问题“串联”起来了。
对比上一篇文章,setTimeout 是直接将延迟任务添加到延迟队列中,而 XMLHttpRequest 发起请求,是由浏览器的其他进程或者线程去执行,然后再将执行结果利用 IPC 的方式通知渲染进程,之后渲染进程再将对应的消息添加到消息队列中。如果你搞懂了 setTimeout 和 XMLHttpRequest 的工作机制后,再来理解其他 WebAPI 就会轻松很多了,因为大部分 WebAPI 的工作逻辑都是类似的。
宏任务和微任务:不是所有的任务都是一个待遇
在前面几篇文章中,我们介绍了消息队列,并结合消息队列介绍了两种典型的 WebAPI——setTimeout 和 XMLHttpRequest,通过这两个 WebAPI 我们搞清楚了浏览器的消息循环系统是怎么工作的。不过随着浏览器的应用领域越来越广泛,消息队列中这种粗时间颗粒度的任务已经不能胜任部分领域的需求,所以又出现了一种新的技术——微任务。微任务可以在实时性和效率之间做一个有效的权衡。
从目前的情况来看,微任务已经被广泛地应用,基于微任务的技术有 MutationObserver、Promise 以及以 Promise 为基础开发出来的很多其他的技术。所以微任务的重要性也与日俱增,了解其底层的工作原理对于你读懂别人的代码,以及写出更高效、更具现代的代码有着决定性的作用。
有微任务,也就有宏任务,那这二者到底有什么区别?它们又是如何相互取长补短的?
宏任务
前面我们已经介绍过了,页面中的大部分任务都是在主线程上执行的,这些任务包括了:
- 渲染事件(如解析 DOM、计算布局、绘制);
- 用户交互事件(如鼠标点击、滚动页面、放大缩小等);
- JavaScript 脚本执行事件;
- 网络请求完成、文件读写完成事件。
为了协调这些任务有条不紊地在主线程上执行,页面进程引入了消息队列和事件循环机制,渲染进程内部会维护多个消息队列,比如延迟执行队列和普通的消息队列。然后主线程采用一个 for 循环,不断地从这些任务队列中取出任务并执行任务。我们把这些消息队列中的任务称为宏任务。
消息队列中的任务是通过事件循环系统来执行的,这里我们可以看看在 WHATWG 规范中是怎么定义事件循环机制的。
由于规范需要支持语义上的完备性,所以通常写得都会比较啰嗦,这里我就大致总结了下 WHATWG 规范定义的大致流程:
- 先从多个消息队列中选出一个最老的任务,这个任务称为 oldestTask;
- 然后循环系统记录任务开始执行的时间,并把这个 oldestTask 设置为当前正在执行的任务;
- 当任务执行完成之后,删除当前正在执行的任务,并从对应的消息队列中删除掉这个 oldestTask;
- 最后统计执行完成的时长等信息。
以上就是消息队列中宏任务的执行过程,通过前面的学习,相信你也很熟悉这套执行流程了。
宏任务可以满足我们大部分的日常需求,不过如果有对时间精度要求较高的需求,宏任务就难以胜任了,下面我们就来分析下为什么宏任务难以满足对时间精度要求较高的任务。
前面我们说过,页面的渲染事件、各种 IO 的完成事件、执行 JavaScript 脚本的事件、用户交互的事件等都随时有可能被添加到消息队列中,而且添加事件是由系统操作的,JavaScript 代码不能准确掌控任务要添加到队列中的位置,控制不了任务在消息队列中的位置,所以很难控制开始执行任务的时间。为了直观理解,你可以看下面这段代码:
<!DOCTYPE html>
<html>
<body>
<div id="demo">
<ol>
<li>test</li>
</ol>
</div>
</body>
<script type="text/javascript">
function timerCallback2() {
console.log(2);
}
function timerCallback() {
console.log(1);
setTimeout(timerCallback2, 0);
}
setTimeout(timerCallback, 0);
</script>
</html>在这段代码中,我的目的是想通过 setTimeout 来设置两个回调任务,并让它们按照前后顺序来执行,中间也不要再插入其他的任务,因为如果这两个任务的中间插入了其他的任务,就很有可能会影响到第二个定时器的执行时间了。
但实际情况是我们不能控制的,比如在你调用 setTimeout 来设置回调任务的间隙,消息队列中就有可能被插入很多系统级的任务。你可以打开 Performance 工具,来记录下这段任务的执行过程,也可参考文中我记录的图片:
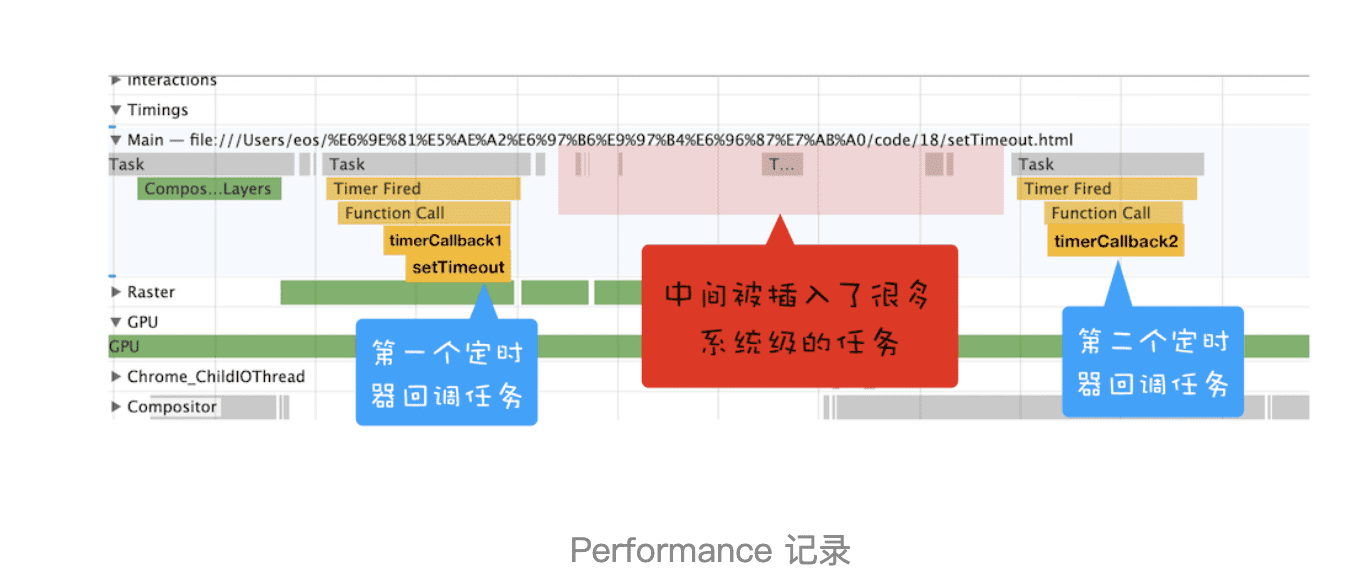
setTimeout 函数触发的回调函数都是宏任务,如图中,左右两个黄色块就是 setTimeout 触发的两个定时器任务。
现在你可以重点观察上图中间浅红色区域,这里有很多一段一段的任务,这些是被渲染引擎插在两个定时器任务中间的任务。试想一下,如果中间被插入的任务执行时间过久的话,那么就会影响到后面任务的执行了。
所以说宏任务的时间粒度比较大,执行的时间间隔是不能精确控制的,对一些高实时性的需求就不太符合了,比如后面要介绍的监听 DOM 变化的需求。
微任务
在理解了宏任务之后,下面我们就可以来看看什么是微任务了。在上一篇文章中,我们介绍过异步回调的概念,其主要有两种方式。
第一种是把异步回调函数封装成一个宏任务,添加到消息队列尾部,当循环系统执行到该任务的时候执行回调函数。这种比较好理解,我们前面介绍的 setTimeout 和 XMLHttpRequest 的回调函数都是通过这种方式来实现的。
第二种方式的执行时机是在主函数执行结束之后、当前宏任务结束之前执行回调函数,这通常都是以微任务形式体现的。
那这里说的微任务到底是什么呢?
微任务就是一个需要异步执行的函数,执行时机是在主函数执行结束之后、当前宏任务结束之前。
不过要搞清楚微任务系统是怎么运转起来的,就得站在 V8 引擎的层面来分析下。
我们知道当 JavaScript 执行一段脚本的时候,V8 会为其创建一个全局执行上下文,在创建全局执行上下文的同时,V8 引擎也会在内部创建一个微任务队列。顾名思义,这个微任务队列就是用来存放微任务的,因为在当前宏任务执行的过程中,有时候会产生多个微任务,这时候就需要使用这个微任务队列来保存这些微任务了。不过这个微任务队列是给 V8 引擎内部使用的,所以你是无法通过 JavaScript 直接访问的。
也就是说每个宏任务都关联了一个微任务队列。那么接下来,我们就需要分析两个重要的时间点——微任务产生的时机和执行微任务队列的时机。
我们先来看看微任务是怎么产生的?在现代浏览器里面,产生微任务有两种方式。
第一种方式是使用 MutationObserver 监控某个 DOM 节点,然后再通过 JavaScript 来修改这个节点,或者为这个节点添加、删除部分子节点,当 DOM 节点发生变化时,就会产生 DOM 变化记录的微任务。
第二种方式是使用 Promise,当调用 Promise.resolve() 或者 Promise.reject() 的时候,也会产生微任务。
通过 DOM 节点变化产生的微任务或者使用 Promise 产生的微任务都会被 JavaScript 引擎按照顺序保存到微任务队列中。
好了,现在微任务队列中有了微任务了,那接下来就要看看微任务队列是何时被执行的。
通常情况下,在当前宏任务中的 JavaScript 快执行完成时,也就在 JavaScript 引擎准备退出全局执行上下文并清空调用栈的时候,JavaScript 引擎会检查全局执行上下文中的微任务队列,然后按照顺序执行队列中的微任务。WHATWG 把执行微任务的时间点称为检查点。当然除了在退出全局执行上下文式这个检查点之外,还有其他的检查点,不过不是太重要,这里就不做介绍了。
如果在执行微任务的过程中,产生了新的微任务,同样会将该微任务添加到微任务队列中,V8 引擎一直循环执行微任务队列中的任务,直到队列为空才算执行结束。也就是说在执行微任务过程中产生的新的微任务并不会推迟到下个宏任务中执行,而是在当前的宏任务中继续执行。
为了直观地理解什么是微任务,你可以参考下面我画的示意图(由于内容比较多,我将其分为了两张):
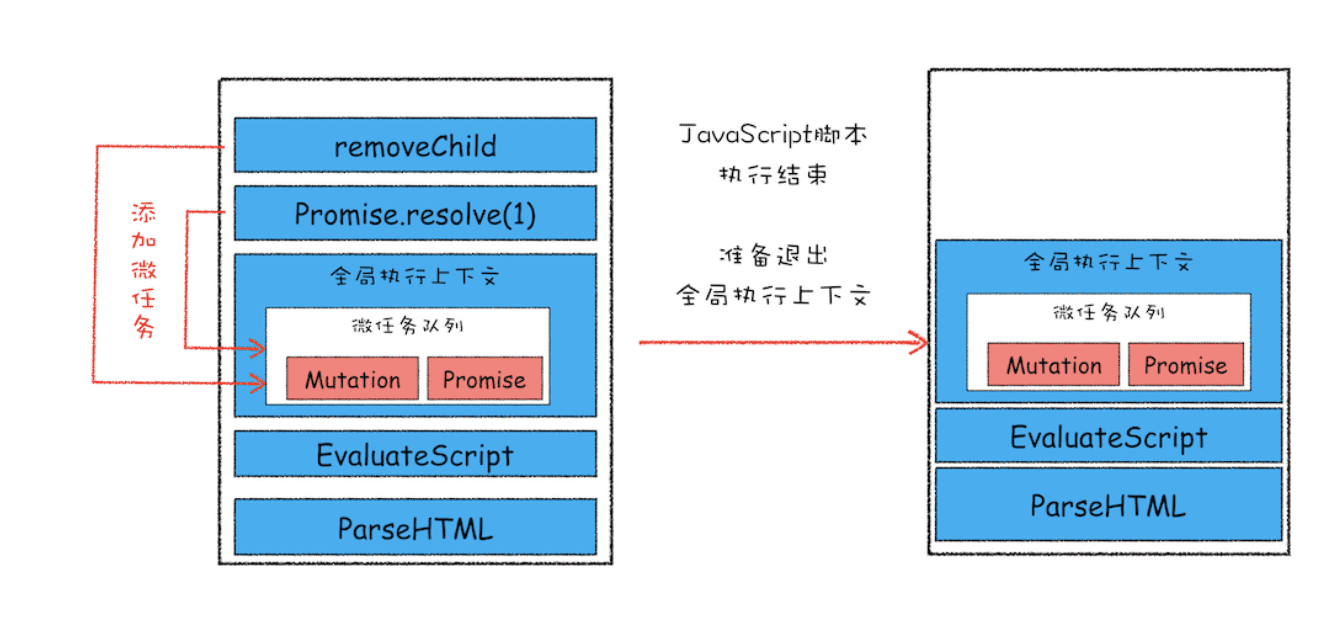
该示意图是在执行一个 ParseHTML 的宏任务,在执行过程中,遇到了 JavaScript 脚本,那么就暂停解析流程,进入到 JavaScript 的执行环境。从图中可以看到,全局上下文中包含了微任务列表。
在 JavaScript 脚本的后续执行过程中,分别通过 Promise 和 removeChild 创建了两个微任务,并被添加到微任务列表中。接着 JavaScript 执行结束,准备退出全局执行上下文,这时候就到了检查点了,JavaScript 引擎会检查微任务列表,发现微任务列表中有微任务,那么接下来,依次执行这两个微任务。等微任务队列清空之后,就退出全局执行上下文。
以上就是微任务的工作流程,从上面分析我们可以得出如下几个结论:
- 微任务和宏任务是绑定的,每个宏任务在执行时,会创建自己的微任务队列。
- 微任务的执行时长会影响到当前宏任务的时长。比如一个宏任务在执行过程中,产生了 100 个微任务,执行每个微任务的时间是 10 毫秒,那么执行这 100 个微任务的时间就是 1000 毫秒,也可以说这 100 个微任务让宏任务的执行时间延长了 1000 毫秒。所以你在写代码的时候一定要注意控制微任务的执行时长。
- 在一个宏任务中,分别创建一个用于回调的宏任务和微任务,无论什么情况下,微任务都早于宏任务执行。
监听 DOM 变化方法演变
现在知道了微任务是怎么工作的,那接下来我们再来看看微任务是如何应用在 MutationObserver 中的。MutationObserver 是用来监听 DOM 变化的一套方法,而监听 DOM 变化一直是前端工程师一项非常核心的需求。
比如许多 Web 应用都利用 HTML 与 JavaScript 构建其自定义控件,与一些内置控件不同,这些控件不是固有的。为了与内置控件一起良好地工作,这些控件必须能够适应内容更改、响应事件和用户交互。因此,Web 应用需要监视 DOM 变化并及时地做出响应。
虽然监听 DOM 的需求是如此重要,不过早期页面并没有提供对监听的支持,所以那时要观察 DOM 是否变化,唯一能做的就是轮询检测,比如使用 setTimeout 或者 setInterval 来定时检测 DOM 是否有改变。这种方式简单粗暴,但是会遇到两个问题:如果时间间隔设置过长,DOM 变化响应不够及时;反过来如果时间间隔设置过短,又会浪费很多无用的工作量去检查 DOM,会让页面变得低效。
直到 2000 年的时候引入了 Mutation Event,Mutation Event 采用了观察者的设计模式,当 DOM 有变动时就会立刻触发相应的事件,这种方式属于同步回调。
采用 Mutation Event 解决了实时性的问题,因为 DOM 一旦发生变化,就会立即调用 JavaScript 接口。但也正是这种实时性造成了严重的性能问题,因为每次 DOM 变动,渲染引擎都会去调用 JavaScript,这样会产生较大的性能开销。比如利用 JavaScript 动态创建或动态修改 50 个节点内容,就会触发 50 次回调,而且每个回调函数都需要一定的执行时间,这里我们假设每次回调的执行时间是 4 毫秒,那么 50 次回调的执行时间就是 200 毫秒,若此时浏览器正在执行一个动画效果,由于 Mutation Event 触发回调事件,就会导致动画的卡顿。
也正是因为使用 Mutation Event 会导致页面性能问题,所以 Mutation Event 被反对使用,并逐步从 Web 标准事件中删除了。
为了解决了 Mutation Event 由于同步调用 JavaScript 而造成的性能问题,从 DOM4 开始,推荐使用 MutationObserver 来代替 Mutation Event。MutationObserver API 可以用来监视 DOM 的变化,包括属性的变化、节点的增减、内容的变化等。
那么相比较 Mutation Event,MutationObserver 到底做了哪些改进呢?
首先,MutationObserver 将响应函数改成异步调用,可以不用在每次 DOM 变化都触发异步调用,而是等多次 DOM 变化后,一次触发异步调用,并且还会使用一个数据结构来记录这期间所有的 DOM 变化。这样即使频繁地操纵 DOM,也不会对性能造成太大的影响。
我们通过异步调用和减少触发次数来缓解了性能问题,那么如何保持消息通知的及时性呢?如果采用 setTimeout 创建宏任务来触发回调的话,那么实时性就会大打折扣,因为上面我们分析过,在两个任务之间,可能会被渲染进程插入其他的事件,从而影响到响应的实时性。
这时候,微任务就可以上场了,在每次 DOM 节点发生变化的时候,渲染引擎将变化记录封装成微任务,并将微任务添加进当前的微任务队列中。这样当执行到检查点的时候,V8 引擎就会按照顺序执行微任务了。
综上所述, MutationObserver 采用了“异步 + 微任务”的策略。
- 通过异步操作解决了同步操作的性能问题;
- 通过微任务解决了实时性的问题。
总结
首先我们回顾了宏任务,然后在宏任务的基础之上,我们分析了异步回调函数的两种形式,其中最后一种回调的方式就是通过微任务来实现的。
接下来我们详细分析了浏览器是如何实现微任务的,包括微任务队列、检查点等概念。
最后我们介绍了监听 DOM 变化技术方案的演化史,从轮询到 Mutation Event 再到最新使用的 MutationObserver。MutationObserver 方案的核心就是采用了微任务机制,有效地权衡了实时性和执行效率的问题。
使用 Promise 告别回调函数
在上一篇文章中我们聊到了微任务是如何工作的,并介绍了 MutationObserver 是如何利用微任务来权衡性能和效率的。今天我们就接着来聊聊微任务的另外一个应用 Promise,DOM/BOM API 中新加入的 API 大多数都是建立在 Promise 上的,而且新的前端框架也使用了大量的 Promise。可以这么说,Promise 已经成为现代前端的“水”和“电”,很是关键,所以深入学习 Promise 势在必行。
不过,Promise 的知识点有那么多,而我们只有一篇文章来介绍,那应该怎么讲解呢?具体讲解思路是怎样的呢?
如果你想要学习一门新技术,最好的方式是先了解这门技术是如何诞生的,以及它所解决的问题是什么。了解了这些后,你才能抓住这门技术的本质。所以本文我们就来重点聊聊 JavaScript 引入 Promise 的动机,以及解决问题的几个核心关键点。
要谈动机,我们一般都是先从问题切入,那么 Promise 到底解决了什么问题呢?在正式开始介绍之前,我想有必要明确下,Promise 解决的是异步编码风格的问题,而不是一些其他的问题,所以接下来我们聊的话题都是围绕编码风格展开的
异步编程的问题:代码逻辑不连续
首先我们来回顾下 JavaScript 的异步编程模型,你应该已经非常熟悉页面的事件循环系统了,也知道页面中任务都是执行在主线程之上的,相对于页面来说,主线程就是它整个的世界,所以在执行一项耗时的任务时,比如下载网络文件任务、获取摄像头等设备信息任务,这些任务都会放到页面主线程之外的进程或者线程中去执行,这样就避免了耗时任务“霸占”页面主线程的情况。你可以结合下图来看看这个处理过程:
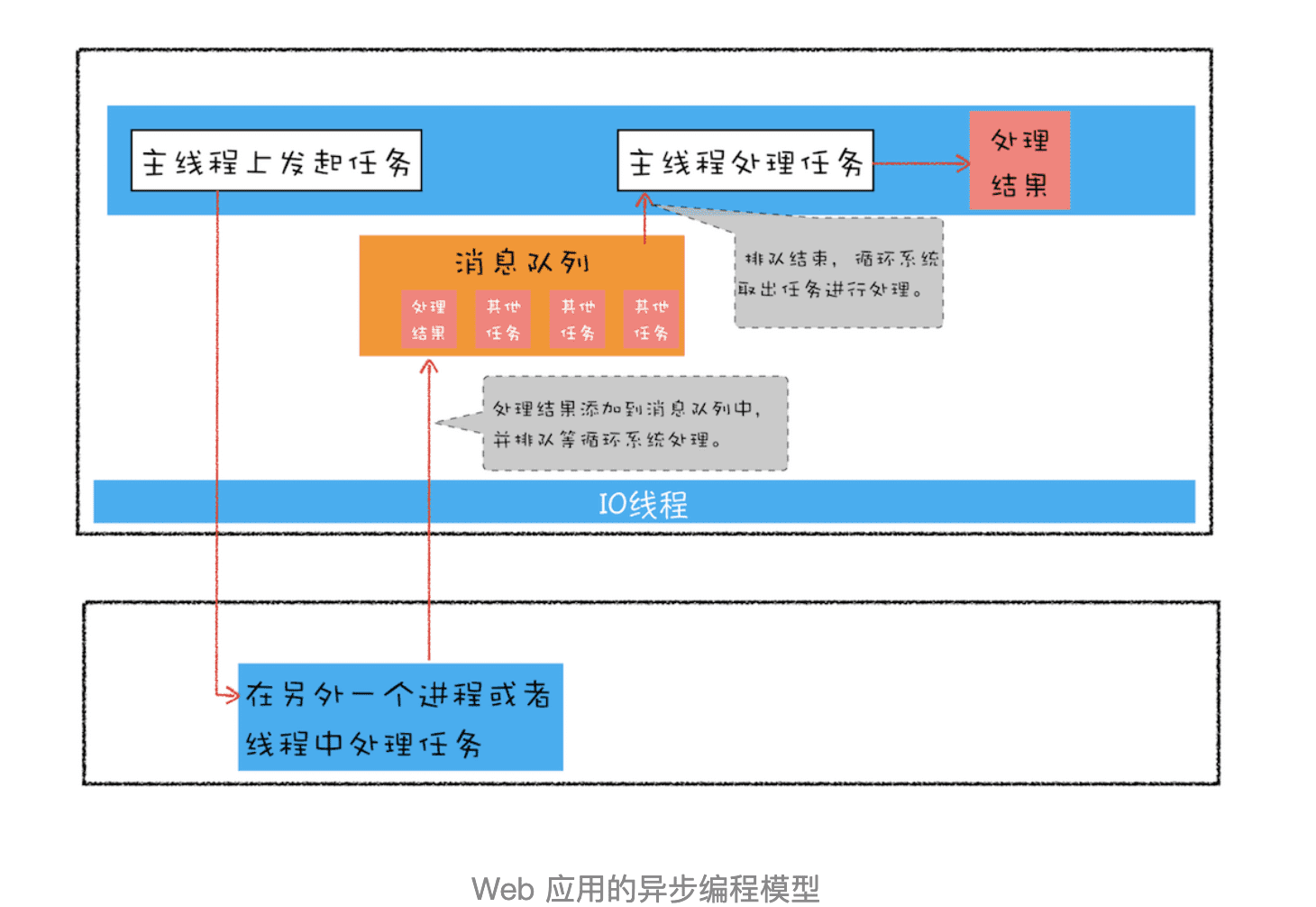
上图展示的是一个标准的异步编程模型,页面主线程发起了一个耗时的任务,并将任务交给另外一个进程去处理,这时页面主线程会继续执行消息队列中的任务。等该进程处理完这个任务后,会将该任务添加到渲染进程的消息队列中,并排队等待循环系统的处理。排队结束之后,循环系统会取出消息队列中的任务进行处理,并触发相关的回调操作。
这就是页面编程的一大特点:异步回调。
Web 页面的单线程架构决定了异步回调,而异步回调影响到了我们的编码方式,到底是如何影响的呢?
假设有一个下载的需求,使用 XMLHttpRequest 来实现,具体的实现方式你可以参考下面这段代码:
// 执行状态
function onResolve(response) {
console.log(response);
}
function onReject(error) {
console.log(error);
}
let xhr = new XMLHttpRequest();
xhr.ontimeout = function(e) {
onReject(e);
};
xhr.onerror = function(e) {
onReject(e);
};
xhr.onreadystatechange = function() {
onResolve(xhr.response);
};
// 设置请求类型,请求 URL,是否同步信息
let URL = 'https://time.geekbang.com';
xhr.open('Get', URL, true);
// 设置参数
xhr.timeout = 3000; // 设置 xhr 请求的超时时间
xhr.responseType = 'text'; // 设置响应返回的数据格式
xhr.setRequestHeader('X_TEST', 'time.geekbang');
// 发出请求
xhr.send();我们执行上面这段代码,可以正常输出结果的。但是,这短短的一段代码里面竟然出现了五次回调,这么多的回调会导致代码的逻辑不连贯、不线性,非常不符合人的直觉,这就是异步回调影响到我们的编码方式。
那有什么方法可以解决这个问题吗?当然有,我们可以封装这堆凌乱的代码,降低处理异步回调的次数。
封装异步代码,让处理流程变得线性
由于我们重点关注的是输入内容(请求信息)和输出内容(回复信息),至于中间的异步请求过程,我们不想在代码里面体现太多,因为这会干扰核心的代码逻辑。整体思路如下图所示:
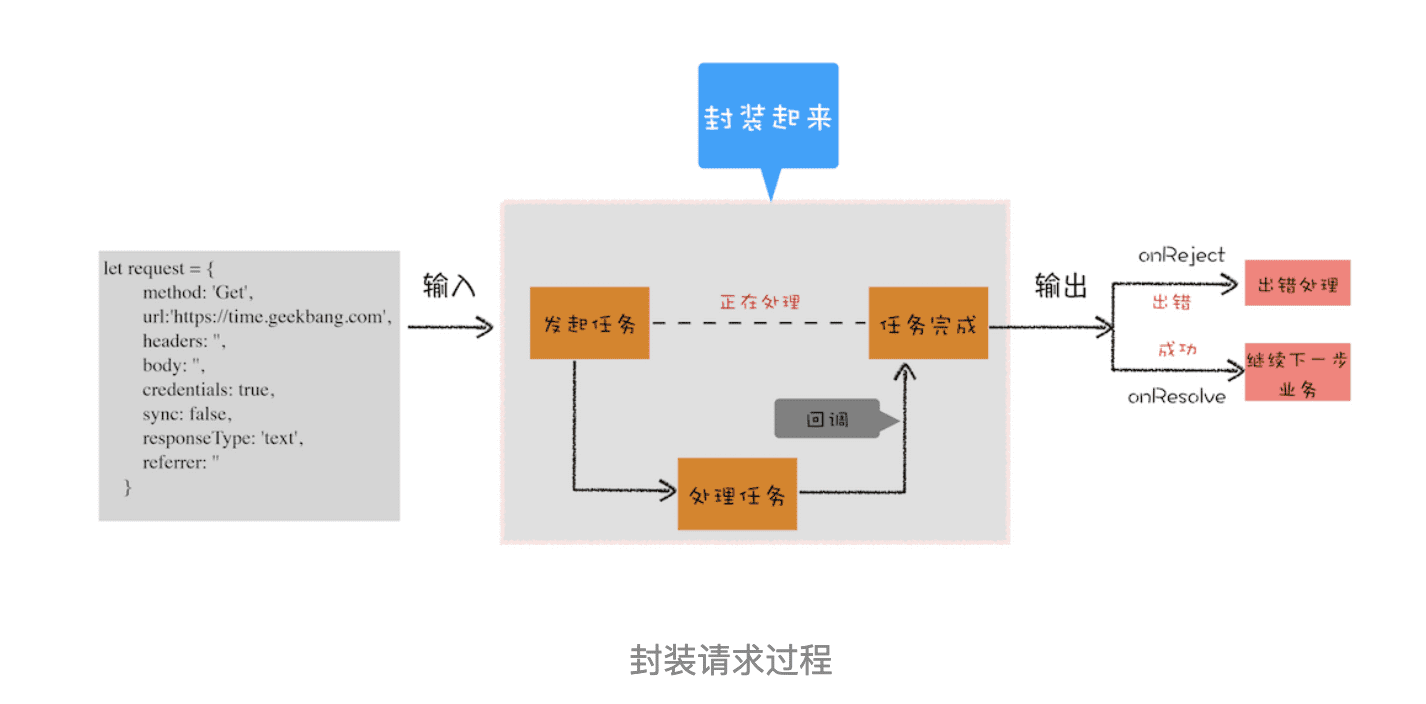
从图中你可以看到,我们将 XMLHttpRequest 请求过程的代码封装起来了,重点关注输入数据和输出结果。
那我们就按照这个思路来改造代码。首先,我们把输入的 HTTP 请求信息全部保存到一个 request 的结构中,包括请求地址、请求头、请求方式、引用地址、同步请求还是异步请求、安全设置等信息。request 结构如下所示:
//makeRequest 用来构造 request 对象
function makeRequest(request_url) {
let request = {
method: 'Get',
url: request_url,
headers: '',
body: '',
credentials: false,
sync: true,
responseType: 'text',
referrer: ''
};
return request;
}然后就可以封装请求过程了,这里我们将所有的请求细节封装进 XFetch 函数,XFetch 代码如下所示:
//[in] request,请求信息,请求头,延时值,返回类型等
//[out] resolve, 执行成功,回调该函数
//[out] reject 执行失败,回调该函数
function XFetch(request, resolve, reject) {
let xhr = new XMLHttpRequest();
xhr.ontimeout = function(e) {
reject(e);
};
xhr.onerror = function(e) {
reject(e);
};
xhr.onreadystatechange = function() {
if ((xhr.status = 200)) resolve(xhr.response);
};
xhr.open(request.method, URL, request.sync);
xhr.timeout = request.timeout;
xhr.responseType = request.responseType;
// 补充其他请求信息
//...
xhr.send();
}这个 XFetch 函数需要一个 request 作为输入,然后还需要两个回调函数 resolve 和 reject,当请求成功时回调 resolve 函数,当请求出现问题时回调 reject 函数。
有了这些后,我们就可以来实现业务代码了,具体的实现方式如下所示:
XFetch(
makeRequest('https://time.geekbang.org'),
function resolve(data) {
console.log(data);
},
function reject(e) {
console.log(e);
}
);新的问题:回调地狱
上面的示例代码已经比较符合人的线性思维了,在一些简单的场景下运行效果也是非常好的,不过一旦接触到稍微复杂点的项目时,你就会发现,如果嵌套了太多的回调函数就很容易使得自己陷入了回调地狱,不能自拔。你可以参考下面这段让人凌乱的代码:
XFetch(makeRequest('https://time.geekbang.org/?category'),
function resolve(response) {
console.log(response)
XFetch(makeRequest('https://time.geekbang.org/column'),
function resolve(response) {
console.log(response)
XFetch(makeRequest('https://time.geekbang.org')
function resolve(response) {
console.log(response)
}, function reject(e) {
console.log(e)
})
}, function reject(e) {
console.log(e)
})
}, function reject(e) {
console.log(e)
})这段代码是先请求 time.geekbang.org/?category,如果请求成功的话,那么再请求 time.geekbang.org/column,如果再次请求成功的话,就继续请求 time.geekbang.org。也就是说这段代码用了三层嵌套请求,就已经让代码变得混乱不堪,所以,我们还需要解决这种嵌套调用后混乱的代码结构。
这段代码之所以看上去很乱,归结其原因有两点:
- 第一是嵌套调用,下面的任务依赖上个任务的请求结果,并在上个任务的回调函数内部执行新的业务逻辑,这样当嵌套层次多了之后,代码的可读性就变得非常差了。
- 第二是任务的不确定性,执行每个任务都有两种可能的结果(成功或者失败),所以体现在代码中就需要对每个任务的执行结果做两次判断,这种对每个任务都要进行一次额外的错误处理的方式,明显增加了代码的混乱程度。
原因分析出来后,那么问题的解决思路就很清晰了:
- 第一是消灭嵌套调用;
- 第二是合并多个任务的错误处理。
这么讲可能有点抽象,不过 Promise 已经帮助我们解决了这两个问题。那么接下来我们就来看看 Promise 是怎么消灭嵌套调用和合并多个任务的错误处理的。
Promise:消灭嵌套调用和多次错误处理
首先,我们使用 Promise 来重构 XFetch 的代码,示例代码如下所示:
function XFetch(request) {
function executor(resolve, reject) {
let xhr = new XMLHttpRequest();
xhr.open('GET', request.url, true);
xhr.ontimeout = function(e) {
reject(e);
};
xhr.onerror = function(e) {
reject(e);
};
xhr.onreadystatechange = function() {
if (this.readyState === 4) {
if (this.status === 200) {
resolve(this.responseText, this);
} else {
let error = {
code: this.status,
response: this.response
};
reject(error, this);
}
}
};
xhr.send();
}
return new Promise(executor);
}接下来,我们再利用 XFetch 来构造请求流程,代码如下:
var x1 = XFetch(makeRequest('https://time.geekbang.org/?category'));
var x2 = x1.then((value) => {
console.log(value);
return XFetch(makeRequest('https://www.geekbang.org/column'));
});
var x3 = x2.then((value) => {
console.log(value);
return XFetch(makeRequest('https://time.geekbang.org'));
});
x3.catch((error) => {
console.log(error);
});你可以观察上面这两段代码,重点关注下 Promise 的使用方式。
- 首先我们引入了 Promise,在调用 XFetch 时,会返回一个 Promise 对象。
- 构建 Promise 对象时,需要传入一个 executor 函数,XFetch 的主要业务流程都在 executor 函数中执行。
- 如果运行在 excutor 函数中的业务执行成功了,会调用 resolve 函数;如果执行失败了,则调用 reject 函数。
- 在 excutor 函数中调用 resolve 函数时,会触发 promise.then 设置的回调函数;而调用 reject 函数时,会触发 promise.catch 设置的回调函数
以上简单介绍了 Promise 一些主要的使用方法,通过引入 Promise,上面这段代码看起来就非常线性了,也非常符合人的直觉,是不是很酷?基于这段代码,我们就可以来分析 Promise 是如何消灭嵌套回调和合并多个错误处理了。
我们先来看看 Promise 是怎么消灭嵌套回调的。产生嵌套函数的一个主要原因是在发起任务请求时会带上回调函数,这样当任务处理结束之后,下个任务就只能在回调函数中来处理了。
Promise 主要通过下面两步解决嵌套回调问题的。
首先,Promise 实现了回调函数的延时绑定。回调函数的延时绑定在代码上体现就是先创建 Promise 对象 x1,通过 Promise 的构造函数 executor 来执行业务逻辑;创建好 Promise 对象 x1 之后,再使用 x1.then 来设置回调函数。示范代码如下:
// 创建 Promise 对象 x1,并在 executor 函数中执行业务逻辑
function executor(resolve, reject) {
resolve(100);
}
let x1 = new Promise(executor);
//x1 延迟绑定回调函数 onResolve
function onResolve(value) {
console.log(value);
}
x1.then(onResolve);其次,需要将回调函数 onResolve 的返回值穿透到最外层。因为我们会根据 onResolve 函数的传入值来决定创建什么类型的 Promise 任务,创建好的 Promise 对象需要返回到最外层,这样就可以摆脱嵌套循环了。你可以先看下面的代码:

现在我们知道了 Promise 通过回调函数延迟绑定和回调函数返回值穿透的技术,解决了循环嵌套。
那接下来我们再来看看 Promise 是怎么处理异常的,你可以回顾上篇文章思考题留的那段代码,我把这段代码也贴在文中了,如下所示:
function executor(resolve, reject) {
let rand = Math.random();
console.log(1);
console.log(rand);
if (rand > 0.5) resolve();
else reject();
}
var p0 = new Promise(executor);
var p1 = p0.then((value) => {
console.log('succeed-1');
return new Promise(executor);
});
var p3 = p1.then((value) => {
console.log('succeed-2');
return new Promise(executor);
});
var p4 = p3.then((value) => {
console.log('succeed-3');
return new Promise(executor);
});
p4.catch((error) => {
console.log('error');
});
console.log(2);这段代码有四个 Promise 对象:p0 ~ p4。无论哪个对象里面抛出异常,都可以通过最后一个对象 p4.catch 来捕获异常,通过这种方式可以将所有 Promise 对象的错误合并到一个函数来处理,这样就解决了每个任务都需要单独处理异常的问题。
之所以可以使用最后一个对象来捕获所有异常,是因为 Promise 对象的错误具有“冒泡”性质,会一直向后传递,直到被 onReject 函数处理或 catch 语句捕获为止。具备了这样“冒泡”的特性后,就不需要在每个 Promise 对象中单独捕获异常了。至于 Promise 错误的“冒泡”性质是怎么实现的,就留给你课后思考了。
通过这种方式,我们就消灭了嵌套调用和频繁的错误处理,这样使得我们写出来的代码更加优雅,更加符合人的线性思维。
Promise 与微任务
讲了这么多,我们似乎还没有将微任务和 Promise 关联起来,那么 Promise 和微任务的关系到底体现哪里呢?
我们可以结合下面这个简单的 Promise 代码来回答这个问题:
function executor(resolve, reject) {
resolve(100);
}
let demo = new Promise(executor);
function onResolve(value) {
console.log(value);
}
demo.then(onResolve);对于上面这段代码,我们需要重点关注下它的执行顺序。
首先执行 new Promise 时,Promise 的构造函数会被执行,不过由于 Promise 是 V8 引擎提供的,所以暂时看不到 Promise 构造函数的细节。
接下来,Promise 的构造函数会调用 Promise 的参数 executor 函数。然后在 executor 中执行了 resolve,resolve 函数也是在 V8 内部实现的,那么 resolve 函数到底做了什么呢?我们知道,执行 resolve 函数,会触发 demo.then 设置的回调函数 onResolve,所以可以推测,resolve 函数内部调用了通过 demo.then 设置的 onResolve 函数。
不过这里需要注意一下,由于 Promise 采用了回调函数延迟绑定技术,所以在执行 resolve 函数的时候,回调函数还没有绑定,那么只能推迟回调函数的执行。
这样按顺序陈述可能把你绕晕了,下面来模拟实现一个 Promise,我们会实现它的构造函数、resolve 方法以及 then 方法,以方便你能看清楚 Promise 的背后都发生了什么。这里我们就把这个对象称为 Bromise,下面就是 Bromise 的实现代码:
function Bromise(executor) {
var onResolve_ = null;
var onReject_ = null;
// 模拟实现 resolve 和 then,暂不支持 rejcet
this.then = function(onResolve, onReject) {
onResolve_ = onResolve;
};
function resolve(value) {
//setTimeout(()=>{
onResolve_(value);
// },0)
}
executor(resolve, null);
}观察上面这段代码,我们实现了自己的构造函数、resolve、then 方法。接下来我们使用 Bromise 来实现我们的业务代码,实现后的代码如下所示:
function executor(resolve, reject) {
resolve(100);
}
// 将 Promise 改成我们自己的 Bromsie
let demo = new Bromise(executor);
function onResolve(value) {
console.log(value);
}
demo.then(onResolve);执行这段代码,我们发现执行出错,输出的内容是:
Uncaught TypeError: onResolve_ is not a function
at resolve (<anonymous>:10:13)
at executor (<anonymous>:17:5)
at new Bromise (<anonymous>:13:5)
at <anonymous>:19:12之所以出现这个错误,是由于 Bromise 的延迟绑定导致的,在调用到 onResolve* 函数的时候,Bromise.then 还没有执行,所以执行上述代码的时候,当然会报“onResolve* is not a function“的错误了。
也正是因为此,我们要改造 Bromise 中的 resolve 方法,让 resolve 延迟调用 onResolve_。
要让 resolve 中的 onResolve* 函数延后执行,可以在 resolve 函数里面加上一个定时器,让其延时执行 onResolve* 函数,你可以参考下面改造后的代码:
function resolve(value) {
setTimeout(() => {
onResolve_(value);
}, 0);
}上面采用了定时器来推迟 onResolve 的执行,不过使用定时器的效率并不是太高,好在我们有微任务,所以 Promise 又把这个定时器改造成了微任务了,这样既可以让 onResolve_ 延时被调用,又提升了代码的执行效率。这就是 Promise 中使用微任务的原因了
总结
首先,我们回顾了 Web 页面是单线程架构模型,这种模型决定了我们编写代码的形式——异步编程。基于异步编程模型写出来的代码会把一些关键的逻辑点打乱,所以这种风格的代码不符合人的线性思维方式。接下来我们试着把一些不必要的回调接口封装起来,简单封装取得了一定的效果,不过,在稍微复杂点的场景下依然存在着回调地狱的问题。然后我们分析了产生回调地狱的原因:
- 多层嵌套的问题;
- 每种任务的处理结果存在两种可能性(成功或失败),那么需要在每种任务执行结束后分别处理这两种可能性。
Promise 通过回调函数延迟绑定、回调函数返回值穿透和错误“冒泡”技术解决了上面的两个问题。
最后,我们还分析了 Promise 之所以要使用微任务是由 Promise 回调函数延迟绑定技术导致的。
async await 使用同步方式写异步代码
在上篇文章中,我们介绍了怎么使用 Promise 来实现回调操作,使用 Promise 能很好地解决回调地狱的问题,但是这种方式充满了 Promise 的 then() 方法,如果处理流程比较复杂的话,那么整段代码将充斥着 then,语义化不明显,代码不能很好地表示执行流程。
比如下面这样一个实际的使用场景:我先请求极客邦的内容,等返回信息之后,我再请求极客邦的另外一个资源。下面代码展示的是使用 fetch 来实现这样的需求,fetch 被定义在 window 对象中,可以用它来发起对远程资源的请求,该方法返回的是一个 Promise 对象,这和我们上篇文章中讲的 XFetch 很像,只不过 fetch 是浏览器原生支持的,没有利用 XMLHttpRequest 来封装。
fetch('https://www.geekbang.org')
.then((response) => {
console.log(response);
return fetch('https://www.geekbang.org/test');
})
.then((response) => {
console.log(response);
})
.catch((error) => {
console.log(error);
});从这段 Promise 代码可以看出来,使用 promise.then 也是相当复杂,虽然整个请求流程已经线性化了,但是代码里面包含了大量的 then 函数,使得代码依然不是太容易阅读。基于这个原因,ES7 引入了 async/await,这是 JavaScript 异步编程的一个重大改进,提供了在不阻塞主线程的情况下使用同步代码实现异步访问资源的能力,并且使得代码逻辑更加清晰。你可以参考下面这段代码:
async function foo() {
try {
let response1 = await fetch('https://www.geekbang.org');
console.log('response1');
console.log(response1);
let response2 = await fetch('https://www.geekbang.org/test');
console.log('response2');
console.log(response2);
} catch (err) {
console.error(err);
}
}
foo();通过上面代码,你会发现整个异步处理的逻辑都是使用同步代码的方式来实现的,而且还支持 try catch 来捕获异常,这就是完全在写同步代码,所以是非常符合人的线性思维的。但是很多人都习惯了异步回调的编程思维,对于这种采用同步代码实现异步逻辑的方式,还需要一个转换的过程,因为这中间隐藏了一些容易让人迷惑的细节。
那么本篇文章我们继续深入,看看 JavaScript 引擎是如何实现 async/await 的。如果上来直接介绍 async/await 的使用方式的话,那么你可能会有点懵,所以我们就从其最底层的技术点一步步往上讲解,从而带你彻底弄清楚 async 和 await 到底是怎么工作的。
本文我们首先介绍生成器(Generator)是如何工作的,接着讲解 Generator 的底层实现机制——协程(Coroutine);又因为 async/await 使用了 Generator 和 Promise 两种技术,所以紧接着我们就通过 Generator 和 Promise 来分析 async/await 到底是如何以同步的方式来编写异步代码的。
生成器 VS 协程
我们先来看看什么是生成器函数?
生成器函数是一个带星号函数,而且是可以暂停执行和恢复执行的。我们可以看下面这段代码:
function* genDemo() {
console.log(' 开始执行第一段 ');
yield 'generator 2';
console.log(' 开始执行第二段 ');
yield 'generator 2';
console.log(' 开始执行第三段 ');
yield 'generator 2';
console.log(' 执行结束 ');
return 'generator 2';
}
console.log('main 0');
let gen = genDemo();
console.log(gen.next().value);
console.log('main 1');
console.log(gen.next().value);
console.log('main 2');
console.log(gen.next().value);
console.log('main 3');
console.log(gen.next().value);
console.log('main 4');执行上面这段代码,观察输出结果,你会发现函数 genDemo 并不是一次执行完的,全局代码和 genDemo 函数交替执行。其实这就是生成器函数的特性,可以暂停执行,也可以恢复执行。下面我们就来看看生成器函数的具体使用方式:
- 在生成器函数内部执行一段代码,如果遇到 yield 关键字,那么 JavaScript 引擎将返回关键字后面的内容给外部,并暂停该函数的执行。
- 外部函数可以通过 next 方法恢复函数的执行
关于函数的暂停和恢复,相信你一定很好奇这其中的原理,那么接下来我们就来简单介绍下 JavaScript 引擎 V8 是如何实现一个函数的暂停和恢复的,这也会有助于你理解后面要介绍的 async/await。
要搞懂函数为何能暂停和恢复,那你首先要了解协程的概念。协程是一种比线程更加轻量级的存在。你可以把协程看成是跑在线程上的任务,一个线程上可以存在多个协程,但是在线程上同时只能执行一个协程,比如当前执行的是 A 协程,要启动 B 协程,那么 A 协程就需要将主线程的控制权交给 B 协程,这就体现在 A 协程暂停执行,B 协程恢复执行;同样,也可以从 B 协程中启动 A 协程。通常,如果从 A 协程启动 B 协程,我们就把 A 协程称为 B 协程的父协程。
正如一个进程可以拥有多个线程一样,一个线程也可以拥有多个协程。最重要的是,协程不是被操作系统内核所管理,而完全是由程序所控制(也就是在用户态执行)。这样带来的好处就是性能得到了很大的提升,不会像线程切换那样消耗资源。
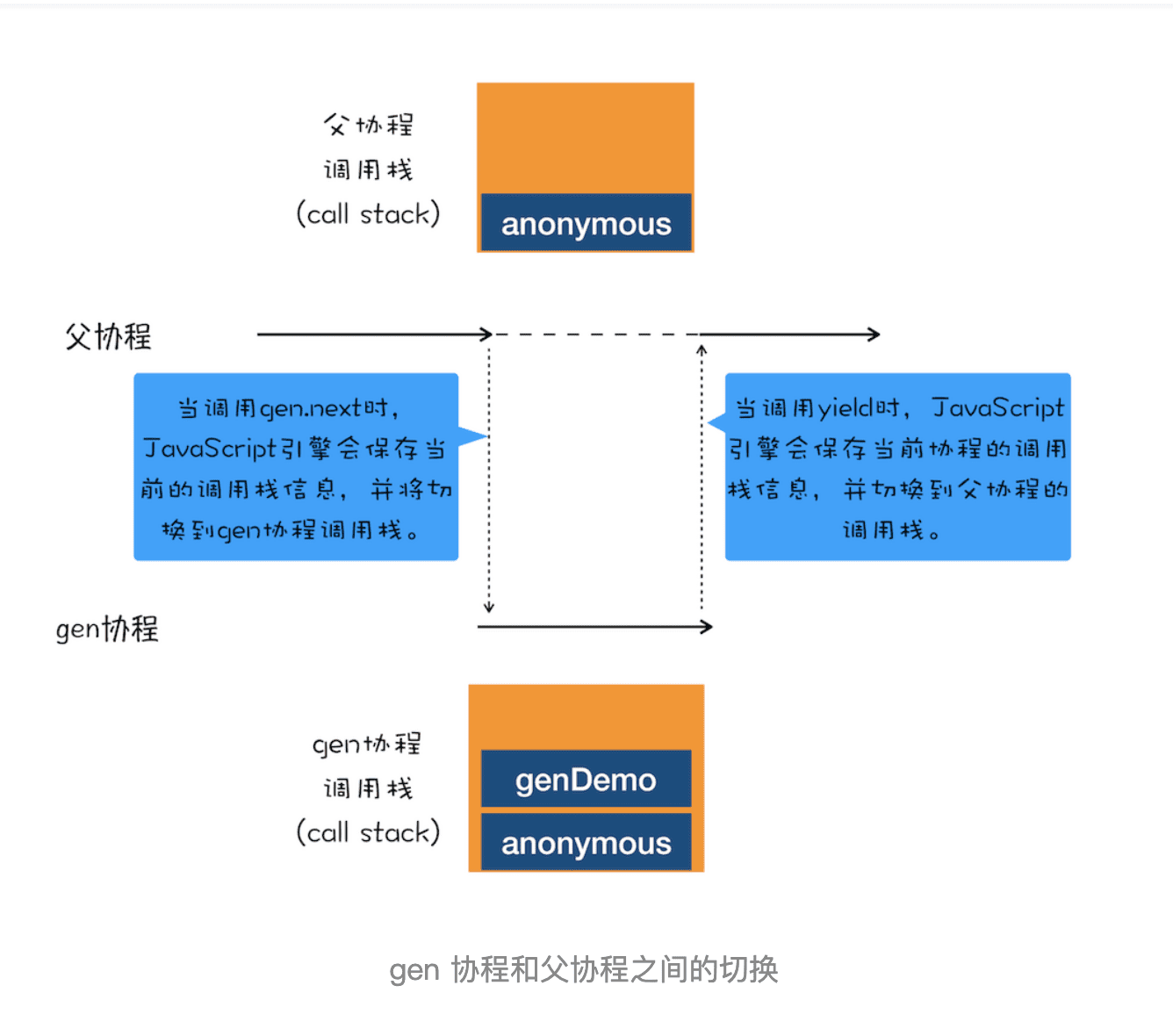
为了让你更好地理解协程是怎么执行的,我结合上面那段代码的执行过程,画出了下面的“协程执行流程图”,你可以对照着代码来分析:
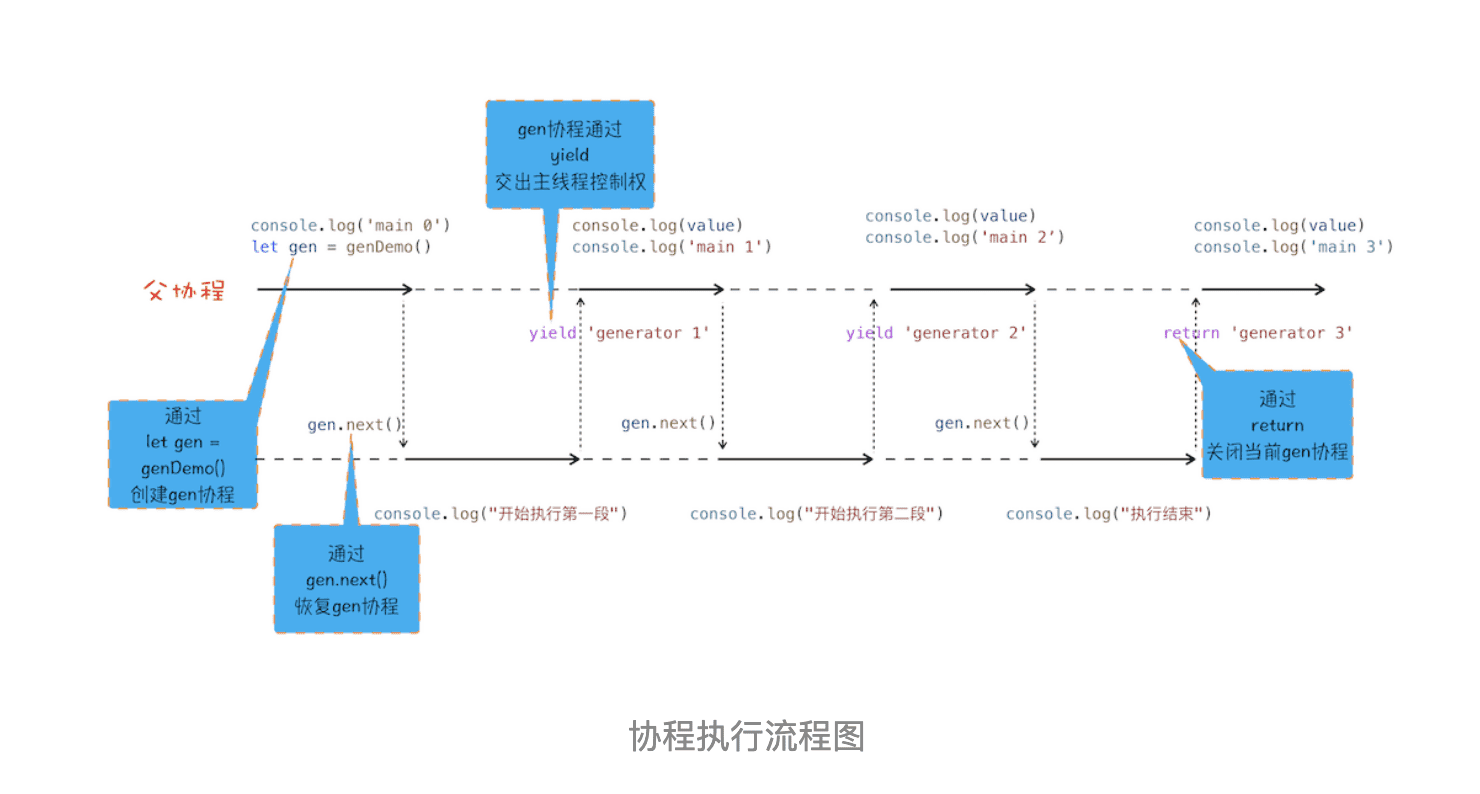
从图中可以看出来协程的四点规则:
- 通过调用生成器函数 genDemo 来创建一个协程 gen,创建之后,gen 协程并没有立即执行。
- 要让 gen 协程执行,需要通过调用 gen.next。
- 当协程正在执行的时候,可以通过 yield 关键字来暂停 gen 协程的执行,并返回主要信息给父协程。
- 如果协程在执行期间,遇到了 return 关键字,那么 JavaScript 引擎会结束当前协程,并将 return 后面的内容返回给父协程。
不过,对于上面这段代码,你可能又有这样疑问:父协程有自己的调用栈,gen 协程时也有自己的调用栈,当 gen 协程通过 yield 把控制权交给父协程时,V8 是如何切换到父协程的调用栈?当父协程通过 gen.next 恢复 gen 协程时,又是如何切换 gen 协程的调用栈?
要搞清楚上面的问题,你需要关注以下两点内容。
第一点:gen 协程和父协程是在主线程上交互执行的,并不是并发执行的,它们之前的切换是通过 yield 和 gen.next 来配合完成的。
第二点:当在 gen 协程中调用了 yield 方法时,JavaScript 引擎会保存 gen 协程当前的调用栈信息,并恢复父协程的调用栈信息。同样,当在父协程中执行 gen.next 时,JavaScript 引擎会保存父协程的调用栈信息,并恢复 gen 协程的调用栈信息。
为了直观理解父协程和 gen 协程是如何切换调用栈的,你可以参考下图
到这里相信你已经弄清楚了协程是怎么工作的,其实在 JavaScript 中,生成器就是协程的一种实现方式,这样相信你也就理解什么是生成器了。那么接下来,我们使用生成器和 Promise 来改造开头的那段 Promise 代码。改造后的代码如下所示:
//foo 函数
function* foo() {
let response1 = yield fetch('https://www.geekbang.org');
console.log('response1');
console.log(response1);
let response2 = yield fetch('https://www.geekbang.org/test');
console.log('response2');
console.log(response2);
}
// 执行 foo 函数的代码
let gen = foo();
function getGenPromise(gen) {
return gen.next().value;
}
getGenPromise(gen)
.then((response) => {
console.log('response1');
console.log(response);
return getGenPromise(gen);
})
.then((response) => {
console.log('response2');
console.log(response);
});从图中可以看到,foo 函数是一个生成器函数,在 foo 函数里面实现了用同步代码形式来实现异步操作;但是在 foo 函数外部,我们还需要写一段执行 foo 函数的代码,如上述代码的后半部分所示,那下面我们就来分析下这段代码是如何工作的。
- 首先执行的是 let gen = foo(),创建了 gen 协程。
- 然后在父协程中通过执行 gen.next 把主线程的控制权交给 gen 协程。
- gen 协程获取到主线程的控制权后,就调用 fetch 函数创建了一个 Promise 对象 response1,然后通过 yield 暂停 gen 协程的执行,并将 response1 返回给父协程。
- 父协程恢复执行后,调用 response1.then 方法等待请求结果。
- 等通过 fetch 发起的请求完成之后,会调用 then 中的回调函数,then 中的回调函数拿到结果之后,通过调用 gen.next 放弃主线程的控制权,将控制权交 gen 协程继续执行下个请求。
以上就是协程和 Promise 相互配合执行的一个大致流程。不过通常,我们把执行生成器的代码封装成一个函数,并把这个执行生成器代码的函数称为执行器(可参考著名的 co 框架),如下面这种方式:
function* foo() {
let response1 = yield fetch('https://www.geekbang.org');
console.log('response1');
console.log(response1);
let response2 = yield fetch('https://www.geekbang.org/test');
console.log('response2');
console.log(response2);
}
co(foo());通过使用生成器配合执行器,就能实现使用同步的方式写出异步代码了,这样也大大加强了代码的可读性。
async/await
虽然生成器已经能很好地满足我们的需求了,但是程序员的追求是无止境的,这不又在 ES7 中引入了 async/await,这种方式能够彻底告别执行器和生成器,实现更加直观简洁的代码。其实 async/await 技术背后的秘密就是 Promise 和生成器应用,往底层说就是微任务和协程应用。要搞清楚 async 和 await 的工作原理,我们就得对 async 和 await 分开分析。
async
我们先来看看 async 到底是什么?根据 MDN 定义,async 是一个通过异步执行并隐式返回 Promise 作为结果的函数。
对 async 函数的理解,这里需要重点关注两个词:异步执行和隐式返回 Promise。
关于异步执行的原因,我们一会儿再分析。这里我们先来看看是如何隐式返回 Promise 的,你可以参考下面的代码:
async function foo() {
return 2;
}
console.log(foo()); // Promise {<resolved>: 2}执行这段代码,我们可以看到调用 async 声明的 foo 函数返回了一个 Promise 对象,状态是 resolved,返回结果如下所示:
Promise {<resolved>: 2}await
我们知道了 async 函数返回的是一个 Promise 对象,那下面我们再结合文中这段代码来看看 await 到底是什么。
async function foo() {
console.log(1);
let a = await 100;
console.log(a);
console.log(2);
}
console.log(0);
foo();
console.log(3);观察上面这段代码,你能判断出打印出来的内容是什么吗?这得先来分析 async 结合 await 到底会发生什么。在详细介绍之前,我们先站在协程的视角来看看这段代码的整体执行流程图:
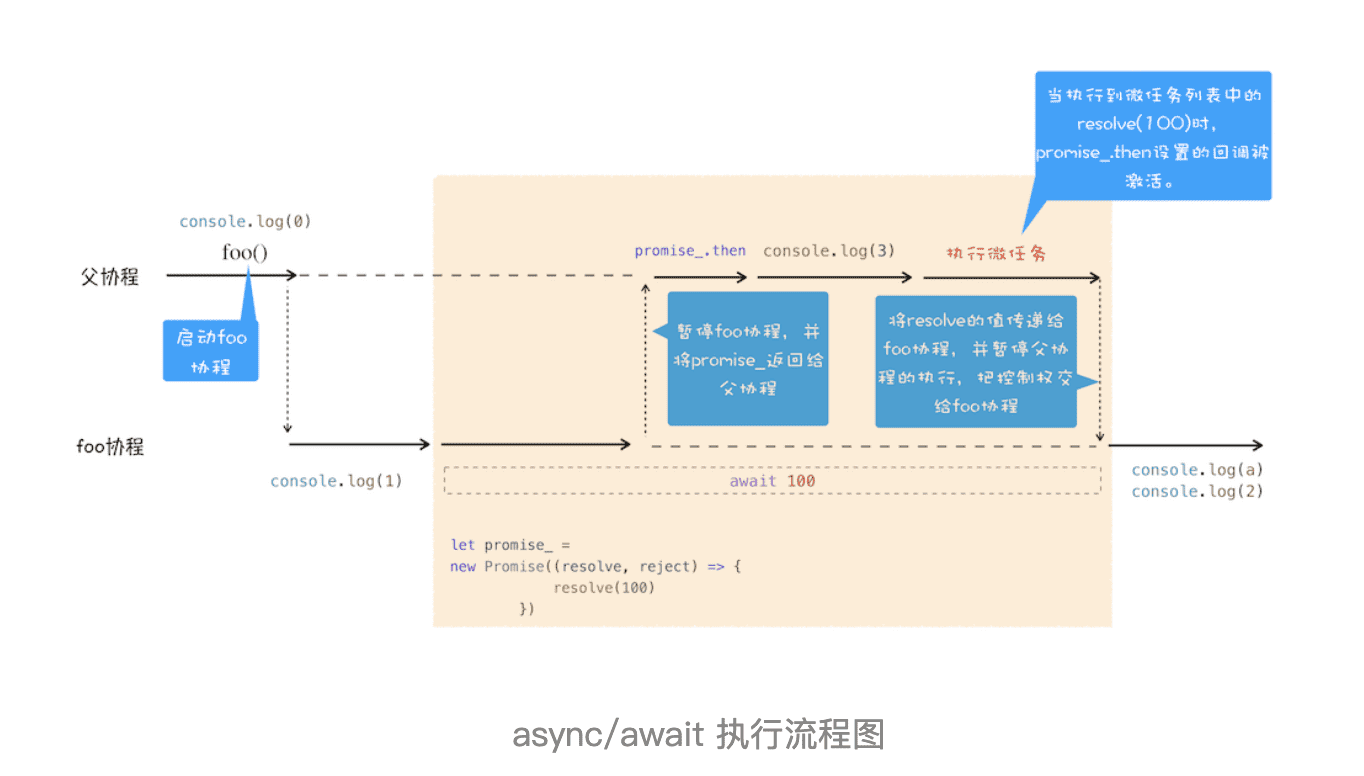
结合上图,我们来一起分析下 async/await 的执行流程。
首先,执行 console.log(0)这个语句,打印出来 0。
紧接着就是执行 foo 函数,由于 foo 函数是被 async 标记过的,所以当进入该函数的时候,JavaScript 引擎会保存当前的调用栈等信息,然后执行 foo 函数中的 console.log(1)语句,并打印出 1。
接下来就执行到 foo 函数中的 await 100 这个语句了,这里是我们分析的重点,因为在执行 await 100 这个语句时,JavaScript 引擎在背后为我们默默做了太多的事情,那么下面我们就把这个语句拆开,来看看 JavaScript 到底都做了哪些事情。
当执行到 await 100 时,会默认创建一个 Promise 对象,代码如下所示:
let promise_ = new Promise((resolve,reject){
resolve(100)
})在这个 promise_ 对象创建的过程中,我们可以看到在 executor 函数中调用了 resolve 函数,JavaScript 引擎会将该任务提交给微任务队列(上一篇文章中我们讲解过)。
然后 JavaScript 引擎会暂停当前协程的执行,将主线程的控制权转交给父协程执行,同时会将 promise_ 对象返回给父协程。
主线程的控制权已经交给父协程了,这时候父协程要做的一件事是调用 promise_.then 来监控 promise 状态的改变。
接下来继续执行父协程的流程,这里我们执行 console.log(3),并打印出来 3。随后父协程将执行结束,在结束之前,会进入微任务的检查点,然后执行微任务队列,微任务队列中有 resolve(100)的任务等待执行,执行到这里的时候,会触发 promise_.then 中的回调函数,如下所示:
promise_.then((value) => {
// 回调函数被激活后
// 将主线程控制权交给 foo 协程,并将 value 值传给协程
});该回调函数被激活以后,会将主线程的控制权交给 foo 函数的协程,并同时将 value 值传给该协程。
foo 协程激活之后,会把刚才的 value 值赋给了变量 a,然后 foo 协程继续执行后续语句,执行完成之后,将控制权归还给父协程。
以上就是 await/async 的执行流程。正是因为 async 和 await 在背后为我们做了大量的工作,所以我们才能用同步的方式写出异步代码来
总结
- Promise 的编程模型依然充斥着大量的 then 方法,虽然解决了回调地狱的问题,但是在语义方面依然存在缺陷,代码中充斥着大量的 then 函数,这就是 async/await 出现的原因。
- 使用 async/await 可以实现用同步代码的风格来编写异步代码,这是因为 async/await 的基础技术使用了生成器和 Promise,生成器是协程的实现,利用生成器能实现生成器函数的暂停和恢复。
- 另外,V8 引擎还为 async/await 做了大量的语法层面包装,所以了解隐藏在背后的代码有助于加深你对 async/await 的理解。
- async/await 无疑是异步编程领域非常大的一个革新,也是未来的一个主流的编程风格。其实,除了 JavaScript,Python、Dart、C# 等语言也都引入了 async/await,使用它不仅能让代码更加整洁美观,而且还能确保该函数始终都能返回 Promise